|
BAB 2
LANDASAN TEORI
2.1 Pengertian Basis Data
Menurut Connolly
(2002,
p14),
basis
data
adalah
kumpulan data
yang
saling
terhubung secara logis, yang dapat digunakan secara bersama, dan deskripsi dari data ini
dirancang
untuk
memenuhi kebutuhan. Menurut Date
(2000,
p10),
basis
data
adalah
kumpulan data
tetap
yang
digunakan oleh
beberapa
sistem
aplikasi.
Menurut
Atzeni
(2003, p3), basis data adalah kumpulan data yang dikelola oleh sebuah DBMS.
Jadi basis data adalah kumpulan data tetap yang tersimpan dan saling terhubung
secara
logis
yang digunakan oleh beberapa sistem aplikasi
untuk
memenuhi kebutuhan
informasi sebuah perusahaan atau organisasi.
Dalam subbab 2.2 akan dicantumkan beberapa teori model relasional menurut Connoly
(2002).
2.2 Model Relasional
Model
relasional
adalah
model
data
yang
didasarkan pada
konsep
matematika
dari
relasi,
yang
secara
fisik
direpresentasikan sebagai
tabel.
Codd
menggunakan
terminologi yang diambil dari matematika, terutama teori set dan logika predikat.
6
|
|
7
Dalam
model
relasional, semua
data
terstruktur secara
logis
dalam
sejumlah
relasi. Setiap relasi memiliki nama, dan terdiri dari sejumlah atribut data. Kelebihan dari
model relasional adalah struktur logis datanya yang sederhana.
Relasi
:
sebuah tabel dengan kolom dan baris.
Atribut/Field
:
nama kolom dalam sebuah relasi.
Domain :
sekumpulan nilai yang diijinkan untuk satu atau lebih
atribut.
Tuple/Record
:
baris dari sebuah relasi.
Degree
:
jumlah atribut pada sebuah relasi.
Cardinality
:
jumlah tuple pada sebuah relasi.
Database relasional
:
kumpulan relasi yang telah dinormalisasi dengan nama
relasi yang berbeda.
Skema relasi :
set terbatas dari kumpulan atribut. Contoh: skema
relasi
R
memiliki atribut-atribut: A,
B,
dan
C,
maka
ditulis R = A B C.
Skema database relasional
:
kumpulan skema relasi yang masing-masing memiliki
nama yang berbeda.
Superkey
:
sebuah atribut atau serangkaian
atribut yang secara
unik mengidentifikasi tuple-tuple pada suatu relasi.
Candidate key
:
sebuah superkey sedemikian sehingga tidak ada subset
yang merupakan superkey dalam relasi tersebut.
Primary key
:
candidate key yang dipilih
untuk
mengidentifikasi
tuple-tuple secara unik dalam sebuah relasi.
|
|
8
Foreign key
:
sebuah atribut atau serangkaian atribut dalam satu
relasi yang sama dengan candidate
key pada relasi
yang lain.
Null
:
representasi
nilai
sebuah
atribut
yang
tidak
diketahui
nilainya atau tidak dapat dipakai untuk sebuah tuple.
2.3 Normalisasi
Normalisasi
adalah suatu
teknik
formal
untuk
menganalisis relasi
berdasarkan
primary
key
(candidate
key)
dan
ketergantungan fungsional
(Connolly, 2002,
p386).
Teknik
tersebut
mencakup
serangkaian
aturan
yang
dapat
digunakan
untuk
menguji
relasi
individu
sehingga
basis
data
dapat
dinormalisasi
pada
derajat
tertentu.
Ketika
syarat tidak terpenuhi, relasi yang tidak sesuai syarat harus diuraikan ke dalam beberapa
relasi dimana
secara
individu
memenuhi
syarat-syarat
normalisasi.
Proses
normalisasi
merupakan
metode
formal
yang
mengidentifikasi beberapa
relasi berdasarkan primary
atau
candidate
key
dan ketergantungan
fungsional
pada atribut-atributnya (Connolly,
2002,
p377).
Tujuan
dari
proses
normalisasi
adalah
untuk
menghilangkan
redundansi
data
(menyimpan data
yang
sama
di
beberapa
tabel)
dan
memastikan
ketergantungan
data yang ada sudah benar (hanya menyimpan data
yang berhubungan ke dalam sebuah
tabel).
Normalisasi
mendukung
para
perancang basis
data
dengan
memberikan
serangkaian
percobaan
yang
dapat
digunakan dalam
relasi
individual sehingga
skema
relasi
tersebut
dapat
dinormalisasi ke
dalam
bentuk
yang
lebih
spesifik
untuk
menghindari kejadian yang memungkinkan terjadinya update anomaly (Connolly, 2002,
p377).
Normalisasi
biasanya
dilakukan
dalam
beberapa
tahap.
Masing-masing
tahap
|
 9
berkaitan dengan
bentuk
normal
tertentu
yang
telah
diketahui
sifat-sifatnya. Dalam
pemodelan data, sangatlah penting untuk mengenal bentuk normal pertama (1NF)
yang
merupakan
kondisi kritis untuk
membuat relasi-relasi yang diperlukan. Bagian
bentuk
normal yang lain hanya
merupakan pilihan (optional). Akan
tetapi,
untuk
menghindari
terjadinya
update
anomaly,
maka
dalam
proses
normalisasi
setidaknya
harus
sampai
pada bentuk normal ketiga (3NF) (Connolly, 2002, p386). Kemudian, oleh R. Boyce dan
E. F. Codd
memperkenalkan definisi
yang
lebih kuat
dari
bentuk
normal
ketiga
yaitu
Boyce-Codd Normal
Form
(BCNF).
Bentuk
normal
form
yang
lebih
tinggi
lagi
diperkenalkan kemudian
sebagai
bentuk
normal
keempat
(4NF)
dan
kelima
(5NF).
Namun,
bentuk
normal
ini
jarang
digunakan pada
beberapa
situasi
sekarang
ini
(Connolly, 2002, p376).
2.3.1 Redundansi Data dan Update Anomaly
Tujuan utama perancangan basis data relasional adalah untuk
mengelompokkan
atribut-atribut ke
dalam
relasi
agar
supaya
redundansi
data
minimal
sehingga
dapat
mengurangi kapasitas
penyimpanan
file
yang
dibutuhkan
oleh
relasi
yang
diimplementasikan (Connolly,
2002,
p377).
Relasi
yang
mempunyai
redundansi
data
akan menimbulkan masalah yang disebut update anomaly, yang
dikelompokkan
menjadi insertion, deletion, dan modification anomaly (Connolly, 2002, p378).
Staff
staffNo
sName
position
salary
branchNo
SL21
John White
Manager
30000
B005
SG37
Ann Beach
Assistant
12000
B003
SG14
David Ford
Supervisor
18000
B003
SA9
Mary Howe
Assistant
9000
B007
|
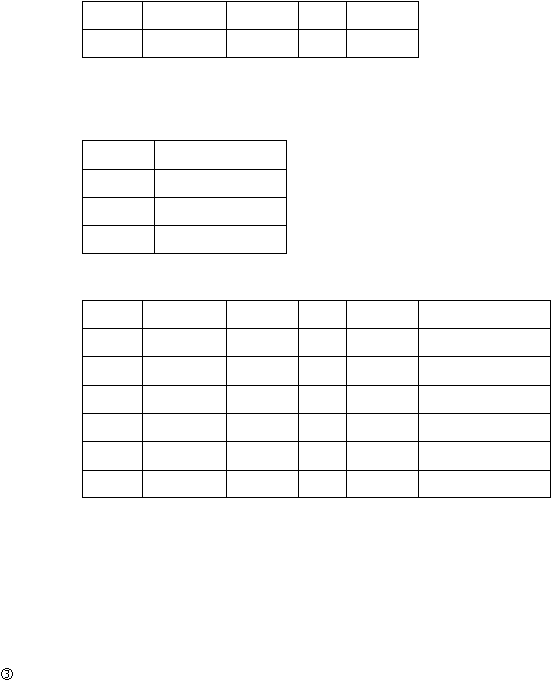 10
SG5
Susan Brand
Manager
24000
B003
SL41
Julie Lee
Assistant
9000
B005
Branch
branchNo
bAddress
B005
22 Deer Rd, London
B007
16 Argyll St, Aberdeen
B003
163 Main St, Glasgow
StaffBranch
Tabel 2.1 Relasi Staff dan Branch
staffNo
sName
position
salary
branchNo
bAddress
SL21
John White
Manager
30000
B005
22 Deer Rd, London
SG37
Ann Beach
Assistant
12000
B003
163 Main St, Glasgow
SG14
David Ford
Supervisor
18000
B003
163 Main St, Glasgow
SA9
Mary Howe
Assistant
9000
B007
16 Argyll St, Aberdeen
SG5
Susan Brand
Manager
24000
B003
163 Main St, Glasgow
SL41
Julie Lee
Assistant
9000
B005
22 Deer Rd, London
Tabel 2.2 Relasi StaffBranch
2.3.1.1 Insertion Anomaly
Menurut Connolly (2002, p378), ada 2 jenis utama insertion anomaly, dimana
dapat digambarkan dengan menggunakan relasi StaffBranch pada Tabel 2.2 di atas.
Memasukkan anggota baru staf ke dalam relasi StaffBranch, perincian cabang
dimana
staf
ditempatkan
perlu
dimasukkan.
Sebagai
contoh,
memasukkan
rincian
staf baru yang akan ditempatkan pada cabang nomor B007, perincian cabang nomor
B007 perlu dimasukkan dengan benar, sehingga perincian cabang konsisten dengan
nilai cabang B007 di tuple
lain dalam relasi StaffBranch. Relasi
yang ditunjukkan
|
|
11
pada tabel 2.1 tidak mengalami data yang tidak konsisten, sebab hanya memasukkan
nomor cabang dengan tepat untuk masing-masing staf dalam relasi Staff. Sedangkan
rincian
cabang
nomor
B007
disimpan dalam
basis
data sebagai
single tuple
dalam
relasi Branch.
Memasukkan rincian cabang baru yang tidak memiliki nomor anggota staf ke dalam
relasi StaffBranch, perlu memasukkan nilai null ke dalam atribut staf, seperti staffNo.
Akan
tetapi,
staffNo
adalah
primary
key
dari
relasi
StaffBranch, sehingga dengan
memasukkan nilai null pada staffNo akan
melanggar konsep
integritas data, dan hal
ini
tidak dibolehkan. Oleh karena itu, nilai null tidak bisa dimasukkan pada stafNo
ke dalam cabang baru pada relasi StaffBranch. Perancangan yang ditunjukkan pada
tabel 2.1
mencegah masalah ini karena rincian cabang yang dimasukkan pada relasi
Branch terpisah dari perincian staf.
2.3.1.2 Deletion Anomaly
Jika
menghapus
sebuah tuple
dari
relasi
StaffBranch yang
merepresentasikan
anggota
lama
staf
yang
dilokasikan
pada
sebuah
cabang,
perincian
mengenai
cabang
juga
akan
terhapus
dari
basis
data.
Sebagai
contoh,
jika
menghapus
tuple
dari
staf
dengan
nomor SA9 (Mary Howe) dari
relasi StaffBranch, perincian
yang berhubungan
dengan nomor cabang B007 juga akan terhapus dari basis data. Perancangan pada relasi
yang
ditunjukkan pada
tabel
2.1
mencegah
masalah
ini,
sebab
tuple
cabang
disimpan
secara
terpisah
dari
tuple
staf
dan
hanya atribut branchNo
yang
berhubungan dengan
kedua relasi tersebut. Jika
menghapus tuple nomor staf SA9
dari
relasi Staff, perincian
pada nomor cabang B007 tetap tidak berdampak dalam relasi Branch (Connolly, 2002,
p378).
|
|
12
2.3.1.3 Modification Anomaly
Jika
ingin
mengubah nilai
dari
satu
atribut
untuk
cabang
tertentu
pada
relasi
StaffBranch,
sebagai contoh
alamat
untuk
nomor
cabang
B003,
tuple
dari
semua
staf
yang ditempatkan pada cabang tersebut perlu diubah (update). Jika perubahan ini tidak
mengubah
semua
tuple
pada
relasi
StaffBranch dengan
tepat,
maka
basis
data
akan
menjadi tidak konsisten. Pada contoh ini, cabang nomor B003 akan mempunyai alamat
yang berbeda untuk tuple staf yang berbeda (Connolly, 2002, p379).
2.3.2 Ketergantungan Fungsional
Salah satu konsep
utama dalam normalisasi adalah functional dependency
(ketergantungan fungsional), yang menggambarkan hubungan antara atribut-atributnya.
2.3.2.1 Definisi Ketergantungan Fungsional
Menurut
Silberschatz
(2002,
p260),
ketergantungan fungsional
memegang
peranan penting dalam membedakan perancangan basis data yang baik dengan basis data
yang
buruk.
Ketergantungan fungsional
merupakan
sebuah
jenis
batasan
yang
menggeneralisasikan key.
Menurut
Connolly
(2002,
p379),
ketergantungan fungsional
mendeskripsikan
hubungan antar atribut dalam sebuah relasi. Sebagai contoh, jika A dan B adalah atribut
dari relasi R, maka B secara fungsional tergantung pada A (ditulis A
B), jika masing-
masing
nilai
dari
A
diasosiasikan
dengan
tepat
satu
nilai
dari
B
(di
mana
A
dan
B
masing-masing terdiri dari satu atau lebih atribut).
Ketergantungan fungsional merupakan semantik dari atribut dalam sebuah relasi.
Semantik menunjukkan bagaimana atribut-atribut berelasi satu sama lain, dan
|
 13
menspesifikasikan saling ketergantungan antar atribut. Ketika ketergantungan fungsional
dilakukan,
maka
ketergantungan
dikenal
sebagai
constraint/batasan di
antara
atribut.
Relasi dengan atribut
A
dan B di mana atribut B tergantung
dengan atribut A dapat
ditulis A
B.
Jika ingin mengetahui nilai
A
dan
mengamati relasi tersebut,
maka
hanya
akan
ditemukan satu
nilai B
pada
semua tuple dari
nilai
A
yang
diberikan. Oleh karena itu
ketika
dua
tuple
mempunyai
nilai
yang
sama
pada A,
B
juga
mempunyai
nilai
yang
sama. Pada contoh di
atas A
merupakan determinant dari B. Determinant menunjukkan
atribut
atau
kumpulan atribut
yang
berada
di
sebelah
kiri
tanda
panah
dalam
ketergantungan fungsional.
Contoh relasi R sebagai berikut (Silberschatz, 2002, p262):
A
B
C
D
a1
b1
c1
d1
a1
b2
c1
d2
a2
b2
c2
d2
a2
b2
c2
d3
a3
b3
c2
d
4
Dapat
dilihat
ketergantungan fungsional
mana
saja
yang
memenuhi
relasi
r
tersebut.
Ketergantungan fungsional
A
C
terpenuhi,
di
mana
dua
tuple
yang
mempunyai nilai
a1
pada
A
mempunyai nilai C
yang
sama
yaitu
c1
,
dua
tuple
yang
mempunyai
nilai
a2 pada
A
mempunyai
nilai
C
yang
sama
juga
yaitu
c
2
dan
tidak
terdapat pasangan
lain dari tuple berbeda yang mempunyai nilai A yang sama.
Sedangkan ketergantungan fungsional C
A
tidak
terpenuhi, di
mana dua tuple
yang
mempunyai
nilai
C
yang sama (c2
)
mempunyai
nilai
A
yang
berbeda
yaitu a2
dan a3.
Dengan
demikian,
telah
ditemukan
dua
tuple
t1
dan
t2
dengan
t1[C]
=
t2[C]
tetapi
t1
[A] ? t2
[A].
|
 14
2.3.2.2 Inference Rule untuk Ketergantungan Fungsional
Dalam
mengidentifikasi
ketergantungan
fungsional
pada
suatu
relasi, biasanya
perancang basis data memulai dengan menspesifikasikan saling ketergantungan tersebut
secara
nyata,
namun
ada
banyak
ketergantungan
fungsional
lainnya.
Akhirnya,
untuk
menspesifikasi semua ketergantungan yang mungkin untuk proyek basis data merupakan
hal
yang
tidak
praktis.
Oleh
karena
itu,
ada
sebuah
pendekatan yang
membantu
mengidentifikasi ketergantungan fungsional secara menyeluruh dalam suatu relasi, yang
dikenal
dengan
sejumlah inference
rule
yang
dapat
digunakan untuk
mengambil
ketergantungan baru dari
sejumlah
ketergantungan
yang diberikan.
Tujuh
aturan
yang
dikenal
sebagai inference
rule
untuk
ketergantungan fungsional
adalah
sebagai berikut
(Connolly, 2002, p384):
1. Reflektif
:
jika B bagian dari A, maka A
B
2. Augmentasi
:
jika A
B, maka A,C
B,C
3. Transitif
:
jika A
B dan B
C, maka A
C
4. Self-Determination
:
A
A
5. Dekomposisi
:
jika A
B,C, maka A
B dan A
C
6. Union
:
jika A
B dan A
C, maka A
B,C
7. Composisi
:
jika A
B dan C
D, maka A,C
B,D
2.3.2.3 Minimal Set dari Ketergantungan Fungsional
Sejumlah ketergantungan fungsional X minimal jika
memenuhi kondisi berikut
(Connolly, 2002, p385):
1. Setiap ketergantungan X mempunyai atribut tunggal dari right-hand side.
|
|
15
2. Ketergantungan A
B
pada X tidak dapat diganti dengan ketergantungan C
B,
di
mana
C
adalah bagian dari
A
dan
masih
mempunyai sejumlah
ketergantungan
yang ekuivalen dengan X.
3.
Tidak
dapat
menghilangkan ketergantungan
X
dan
masih
mempunyai
sejumlah
ketergantungan yang ekuivalen dengan X.
2.3.3 Bentuk Normal Pertama (1NF)
Menurut Connolly (2002,
p388),
bentuk
normal
pertama
(1NF)
adalah
sebuah
relasi dimana irisan tiap baris dan kolom mengandung satu dan
hanya satu nilai. Proses
normalisasi awalnya dimulai dari
memindahkan data
ke dalam tabel
dengan baris
dan
kolom, dimana
tabel tersebut masih dalam bentuk
tidak
normal (UNF).
Tujuan bentuk
normal pertama (1NF) adalah untuk menghilangkan bentuk tidak normal (UNF) dengan
mengidentifikasi dan
menghilangkan grup
yang
berulang
(repeating groups)
di
dalam
tabel. Grup yang berulang (repeating groups)merupakan sebuah atribut atau sekumpulan
atribut dalam tabel yang mengandung beberapa nilai untuk satu kejadian.
Menurut
Connolly
(2002,
p388),
ada
dua
pendekatan umum
untuk
menghilangkan grup yang berulang dari tabel yang tidak normal:
a. Pendekatan yang pertama, menghilangkan grup yang berulang dengan
memasukkan
data yang tepat pada kolom kosong dari baris yang mengandung data yang berulang.
Dengan kata
lain,
kolom
yang kosong diisi
dengan menggandakan data
yang
tidak
berulang,
jika
diperlukan. Tabel
yang
dihasilkan, merupakan suatu
relasi
yang
mengandung nilai
tunggal pada
irisan dari
tiap baris dan kolom dan tabel
ini sudah
dalam bentuk normal pertama.
|
 16
b. Pendekatan
yang kedua,
menghilangkan grup
yang berulang dengan
menempatkan
data
yang
berulang bersamaan dengan
salinan
atribut key
yang asli.
Primary
key
diidentifikasikan untuk
relasi
yang
baru.
Terkadang
tabel
yang
tidak
normal
mengandung lebih dari satu
grup yang berulang, atau
grup berulang di dalam
grup
yang berulang juga. Dalam kasus
tersebut, pendekatan ini
digunakan berulang kali
sampai
tidak
ada
grup
yang
berulang lagi.
Apabila sudah
tidak
ada
grup
yang
berulang lagi, maka sudah berada dalam bentuk normal pertama.
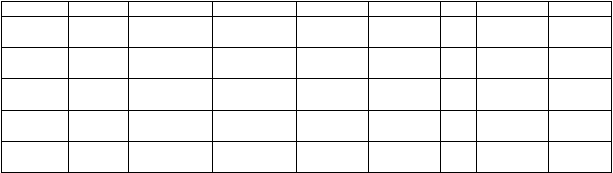
ClientRental
clientNo
cName
propertyNo
pAddress
rentStart
rentFinish
rent
ownerNo
oName
CR76
John
Kay
PG4
6 Lawrence
St, Glasgow
1-Jul-00
31–Aug -
01
350
CO40
Tina
Murphy
PG16
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony
Shaw
CR65
Aline
Stewart
PG4
6 Lawrence
St, Glasgow
1-Jul-00
31 – Aug -
01
350
CO40
Tina
Murphy
PG36
2
Manor
Rd
Glasgow
10-Oct-00
1-Dec-01
375
CO93
Tony
Shaw
PG16
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony
Shaw
Tabel 2.3 Tabel ClientRental yang belum dinormalisasi
clientNo dalam tabel ClientRental diidentifikasi sebagai atribut key. Struktur dari
grup
yang berulang
yaitu
(propertyNo, pAddress,
rentStart, rentFinish, rent, ownerNo,
oName).
Akibatnya,
terdapat
beberapa
nilai
pada
irisan
untuk
baris
dan
kolom
tertentu.
Sebagai
contoh,
ada
dua
nilai
untuk
propertyNo (PG4
dan
PG16)
untuk
klien
yang
bernama John Kay. Untuk mengubah tabel yang tidak normal ke dalam 1NF, dipastikan
hanya
ada
nilai tunggal pada
irisan
tiap
baris
dan
kolom.
Oleh
karena
itu
grup
yang
berulang harus dihilangkan.
|
 17
ClientRental
clientNo
propertyNo
cName
pAddress
rentStart
rentFinish
rent
ownerNo
oName
CR76
PG4
John
Kay
6 Lawrence
St, Glasgow
1-Jul-00
31 – Aug -
01
350
CO40
Tina
Murphy
CR76
PG16
John
Kay
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony
Shaw
CR65
PG4
Aline
Stewart
6 Lawrence
St, Glasgow
1-Jul-00
31 – Aug -
01
350
CO40
Tina
Murphy
CR65
PG36
Aline
Stewart
2
Manor
Rd
Glasgow
10-Oct-00
1-Dec-01
375
CO93
Tony
Shaw
CR65
PG16
Aline
Stewart
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony
Shaw
Tabel 2.4 Relasi ClientRental pada bentuk normal pertama (1NF)
Dengan
menggunakan pendekatan
pertama,
grup
yang
berulang
dihilangkan
dengan
memasukkan
data
klien
yang
tepat
ke
dalam
masing-masing
baris.
Hasil dari
bentuk normal pertama dari relasi ClientRental dapat
dilihat pada
tabel 2.4. Candidate
key untuk relasi ClientRental diidentifikasi sebagai key gabungan (composite key) yang
terdiri
dari
(clientNo,
propertyNo), (clientNo,
rentStart)
dan
(propertyNo,
rentStart).
Primary key yang
dipilih
pada relasi
ini
adalah
(clientNo,
propertyNo) dan agar
lebih
jelas
atribut
yang
dipilih
sebagai primary
key diletakkan di
sebelah kiri pada
relasi.
Atribut
rentFinish tidak
tepat
sebagai
sebuah
komponen dari
candidate
key
karena
mengandung nilai null.
Relasi ClientRental dapat didefinisikan sebagai berikut : ClientRental (clientNo,
propertyNo, cName,
pAddress,
rentStart,
rentFinish,
rent,
ownerNo,
oName).
Relasi
ClientRental berada dalam bentuk normal pertama bila terdapat nilai tunggal pada irisan
untuk tiap baris dan kolom. Relasi mengandung
data yang menggambarkan
klien,
properti
yang disewakan, dan pemilik properti, dimana diulang beberapa kali. Sebagai
hasil,
relasi
ClientRental
mengandung redundansi
data
yang
signifikan.
Jika
diimplementasikan, maka
relasi
1NF
tersebut
akan
terjadi
update
anomaly.
Untuk
mengatasi hal tersebut, maka relasi harus diubah ke dalam bentuk normal kedua.
|
 18
Dengan menggunakan pendekatan kedua, grup
yang berulang dihilangkan
dengan menempatkan data yang berulang bersamaan dengan salinan atribut key yang asli
(clientNo) dalam relasi yang terpisah, seperti yang ditunjukkan pada tabel 2.5. Primary
key diidentifikasi
untuk
relasi
yang
baru,
dan
hasil
dari relasi
1NF adalah
sebagai
berikut:
Client
(clientNo, cName)
PropertyRentalOwner
(clientNo,
propertyNo, pAddress,
rentStart,
rentFinish, rent,
ownerNo, oName)
Kedua
relasi
Client
dan
PropertyRentalOwner
berada
dalam
bentuk
1NF
bila
terdapat nilai tunggal pada irisan untuk tiap baris dan kolom. Relasi Client mengandung
data
yang
menggambarkan
klien
dan
relasi
PropertyRentalOwner
mengandung
data
yang menggambarkan properti yang disewa oleh klien dan pemilik properti. Akan tetapi,
relasi
yang
ditunjukkan
pada
tabel
2.5
mengandung beberapa
redundansi
data
yang
menyebabkan update anomaly (Connolly, 2002, p390).
Client
clientNo
cName
CR76
John Kay
CR56
Aline Stewart
PropertyRentalOwner
clientNo
propertyNo
pAddress
rentStart
rentFinish
rent
ownerNo
oName
CR76
PG4
6
Lawrence
St,
Glasgow
1-Jul-00
31 – Aug
–
01
350
CO40
Tina
Murphy
CR76
PG16
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony Shaw
CR65
PG4
6
Lawrence
St,
Glasgow
1-Jul-00
31 – Aug
–
01
350
CO40
Tina
Murphy
CR65
PG36
2
Manor
Rd,
Glasgow
10-Oct-00
1-Dec-01
375
CO93
Tony Shaw
CR65
PG16
5
Novar
Dr,
Glasgow
1-Sep-01
1-Sep-02
450
CO93
Tony Shaw
Tabel 2.5 Relasi Client dan PropertyRentalOwner pada 1NF
|
 19
2.3.4 Bentuk Normal Kedua (2NF)
Menurut
Connolly
(2002, p392), bentuk
normal
kedua
(2NF) adalah
sebuah
relasi yang berada dalam bentuk normal pertama dimana setiap atribut non-primary key
bergantung
fungsional
secara penuh pada primary key. Sebuah
ketergantungan
fungsional A
B
dikatakan bergantung fungsional secara penuh
apabila
pemindahan
beberapa
atribut
dari
A
menyebabkan
tidak
adanya
ketergantungan lagi.
Sebuah
ketergantungan
fungsional
A
B
dikatakan tergantung
sebagian
(partial
dependent)
jika terdapat beberapa atribut yang bisa dihilangkan dari A dan ketergantungan.yang ada
masih terjaga. Sebagai contoh, ketergantungan fungsional berikut:
staffNo, sName
branchNo
Ketergantungan fungsional
dikatakan
benar
bila
tiap
nilai
(staffNo,
sName)
dihubungkan dengan
nilai
tunggal
dari
branchNo.
Akan
tetapi,
tidak
bisa
dikatakan
mempunyai ketergantungan fungsional secara penuh, karena branchNo juga mempunyai
ketergantungan fungsional terhadap bagian dari (staffNo, sName), yaitu staffNo.
Proses
normalisasi dari
relasi
1NF
ke
2NF
yaitu
dengan
menghilangkan
ketergantungan
sebagian
dalam
relasi
seperti
yang
ditunjukkan
pada
tabel
2.4. Jika
masih ada ketergantungan sebagian, atribut yang bergantung fungsional dari suatu relasi
dihilangkan dengan menempatkan atribut tersebut ke dalam relasi
yang baru bersamaan
dengan
salinan
determinant
atribut-atributnya. Proses
normalisasi
dari
relasi
bentuk
normal
pertama ke
bentuk
normal
kedua
dapat
dilihat
pada
contoh
berikut
dengan
menggunakan relasi ClientRental pada tabel 2.4.
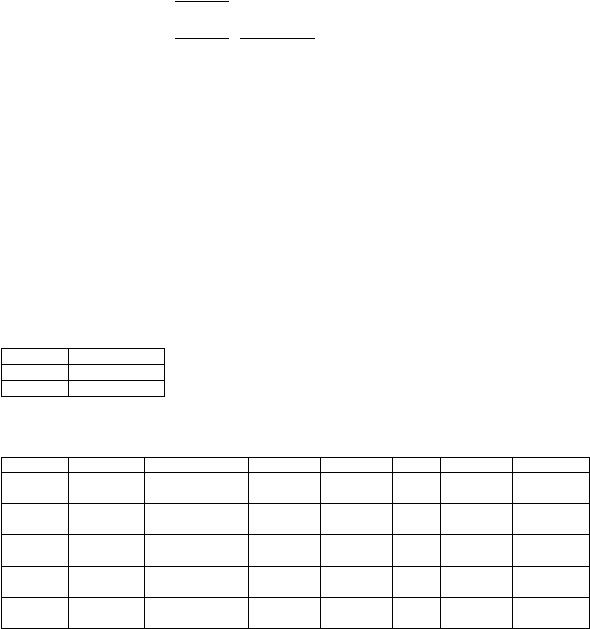
Pada
gambar 2.1
ditunjukkan ketergantungan
fungsional
(fd1
sampai
fd6) dari
relasi ClientRental dengan (clientNo, propertyNo) sebagai primary key. Walaupun relasi
|
 20
ClientRental mempunyai tiga candidate key, namun yang diperhatikan adalah hubungan
di antara ketergantungan tertentu terhadap primary key, karena definisi bentuk normal
kedua hanya menyatakan hubungan terhadap primary key dari sebuah relasi.
clientNo
propertyNo
cName
pAddress
rentStart
rentFinish
rent
ownerNo
oName
fd1
(Primary key
)
fd2
(
Ketergantungan Parsial
)
fd3
fd4
fd5
(Candidate
key)
fd6
(Candidate key)
Gambar 2.1 Ketergantungan Fungsional pada relasi ClientRental
Relasi ClientRental mempunyai ketergantungan fungsional sebagai berikut:
fd1
clientNo, propertyNo
rentStart, rentFinish
(Primary Key)
fd2
clientNo
cName
(Partial dependency)
fd3
propertyNo
pAddress, rent, ownerNo, oName
(Partial dependency)
fd4
ownerNo
oName
(Transitive dependency)
fd5
clientNo, rentStart
propertyNo, pAddress,
rentFinish, rent, ownerNo, oName
(Candidate key)
fd6
propertyNo, rentStart
clientNo, cName, rentFinish
(Candidate key)
Proses
normalisasi
pada
relasi
ClientRental dimulai
dengan
mengecek apakah
relasi tersebut berada dalam bentuk normal kedua dengan mengidentifikasi keberadaan
ketergantungan sebagian terhadap primary key. Atribut Klien (cName) bergantung
|
|
21
sebagian
pada primary
key, yaitu
hanya
pada atribut clientNo (ditunjukkan pada
fd2).
Atribut properti (pAddress,
rent, ownerNo, oName)
bergantung sebagian pada primary
key, yaitu hanya pada atribut propertyNo (ditunjukkan pada fd3). Atribut sewa properti
(rentStart
dan
rentFinish)
bergantung penuh
pada
semua
primary
key,
yaitu
atribut
clientNo dan propertyNo (ditunjukkan pada fd1).
Gambar
2.1
menunjukkan
adanya
ketergantungan transitif
pada
primary
key
(ditunjukkan
pada
fd4).
Walaupun
ketergantungan transitif
dapat
juga
menyebabkan
update
anomaly,
tetapi
keberadaanya
tidak
mempengaruhi sebuah
relasi
dalam
2NF.
Ketergantungan seperti ini akan dihilangkan pada bentuk normal ketiga (3NF).
Identifikasi
ketergantungan sebagian
dalam
relasi
ClientRental
menunjukkan
bahwa relasi tersebut tidak berada dalam bentuk normal kedua. Untuk mengubah relasi
ClientRental
ke bentuk normal kedua perlu dibuat relasi baru dimana
atribut
non-
primary
key
dihilangkan bersamaan
dengan
salinan
dari
bagian
primary
key
yang
memiliki
ketergantungan fungsional
secara
penuh.
Hasil
dari
pembuatan
relasi
baru
adalah
Client,
Rental,
dan
PropertyOwner, seperti
yang
ditunjukkan
pada
tabel
2.6.
Ketiga
relasi
ini
sudah
dalam bentuk
normal
kedua dimana
setiap
atribut non-primary
key bergantung
fungsional
secara
penuh
terhadap
primary key pada relasi
tersebut.
Relasi yang dibentuk adalah sebagai berikut:
Client
(clientNo, cName)
Rental
(clientNo, propertyNo, rentStart, rentFinish)
PropertyOwner
(propertyNo, pAddress, rent, ownerNo, oName)
Client
clienNo
cName
CR76
John Kay
CR56
Aline Stewart
|
 22
Rental
clientNo
propertyNo
rentStart
rentFinish
CR76
PG4
1-Jul-00
31- Aug - 01
CR76
PG16
1-Sep-01
1-Sep-02
CR65
PG4
1-Jul-00
31- Aug - 01
CR65
PG36
10-Oct-00
1-Dec-01
CR65
PG16
1-Sep-01
1-Sep-02
PropertyOwner
propertyNo
pAddress
rent
ownerNo
oName
PG4
6
Lawrence St, Glasgow
350
CO40
Tina Murphy
PG16
5 Novar Dr, Glasgow
450
CO93
Tony Shaw
PG4
6
Lawrence St, Glasgow
350
CO40
Tina Murphy
PG36
2
Manor Rd, Glasgow
375
CO93
Tony Shaw
PG16
5 Novar Dr, Glasgow
450
CO93
Tony Shaw
Tabel 2.6 Relasi dalam 2NF yang diperoleh dari relasi ClientRental
2.3.5 Bentuk Normal Ketiga (3NF)
Menurut Connolly
(2002, p394), bentuk
normal
ketiga
(3NF) adalah
sebuah
relasi
yang
berada
dalam
bentuk
pertama dan
kedua
dimana
tidak
ada
atribut non-
primary key yang bergantung secara
transitif terhadap primary key atau candidate key.
Meskipun relasi bentuk normal kedua memiliki redundansi yang lebih sedikit dibanding
dengan
bentuk
normal pertama,
namun
masih
memungkinkan terjadinya
update
anomaly. Update anomaly disebabkan karena sebuah ketergantungan
transitif, oleh
sebab
itu
perlu
dihilangkan
ketergantungan tersebut
dengan
bentuk
normal
ketiga.
Ketergantungan transitif adalah suatu kondisi dimana A, B, C merupakan atribut-atribut
dari sebuah relasi yang bila A
B dan B
C, sehingga C bergantung transitif terhadap
A melalui B (dengan syarat
A tidak bergantung fungsional terhadap B atau C).
Proses
normalisasi
dari
2NF
ke
3NF
adalah
untuk
menghilangkan
ketergantungan transitif.
Apabila
ketergantungan transitif
masih
ada, perlu dihilangkan
atribut sebuah relasi yang memiliki ketergantungan transitif dengan menempatkan
|
 23
atribut
tersebut
pada
sebuah
relasi
baru
bersama
dengan
salinan
determinant.
Untuk
lebih jelasnya dapat dilihat pada contoh berikut. Ketergantungan fungsional untuk relasi
Client,
Rental,
dan
PropertyOwner diperoleh
dari
contoh
sebelumnya
(seperti
yang
ditunjukkan pada tabel 2.6):
Client
fd2
clientNo
cName (primary key)
Rental
fd1
clientNo, propertyNo
rentStart, rentFinish
(primary key)
fd5’
clientNo, rentStart
propertyNo, rentFinish
(candidate key)
fd6’
propertyNo, rentStart
clientNo, rentFinish
(candidate key)
PropertyOwner
fd3
propertyNo
pAddress, rent, ownerNo, oName
(partial dependency)
fd4
ownerNo
oName
(transitive dependency)
Semua atribut
non-primary
key dalam relasi
Client
dan
Rental
memiliki
ketergantungan fungsional hanya pada primary key dan kedua relasi
ini tidak memiliki
ketergantungan
transitif,
sehingga kedua
relasi
ini
sudah
berada
dalam bentuk normal
ketiga
(3NF).
Ketergantungan fungsional
(fd)
yang
diberi
tanda
petik
(seperti
fd5’),
menunjukkan
bahwa
ketergantungan tersebut
telah
diubah
dengan
membandingkan
ketergantungan fungsional
yang
aslinya.
Semua
atribut
non-primary
key
dalam relasi
PropertyOwner bergantung fungsional terhadap primary key, kecuali oName, yang juga
tergantung pada ownerNo (seperti ditunjukkan pada fd4).
Hal
ini
merupakan salah satu
contoh
ketergantungan transitif,
yang
terjadi
ketika
atribut
non-primary
key
(oName)
tergantung pada
satu
atau
lebih
atribut
non-primary
key
(ownerNo).
Ketergantungan
transitif telah diidentifikasi sebelumnya pada gambar 2.1. Untuk mengubah relasi
|
 24
PropertyOwner ke bentuk
normal ketiga, perlu dihilangkan ketergantungan transitif ini
dengan
membuat
dua
relasi
baru
yaitu
PropertyForRent dan
Owner,
seperti
yang
ditunjukkan pada tabel 2.7. Relasi baru yang terbentuk tersebut adalah:
PropertyForRent
(propertyNo, pAddress, rent, ownerNo)
Owner
(ownerNo, oName)
PropertyForRent
propertyNo
pAddress
rent
ownerNo
PG4
6
Lawrence St, Glasgow
350
CO40
PG16
5 Novar Dr, Glasgow
450
CO93
PG36
2
Manor Rd, Glasgow
375
CO93
Owner
ownerNo
oName
CO40
Tina Murphy
CO93
Tony Shaw
Tabel 2.7 Relasi 3NF yang diperoleh dari relasi PropertyOwner
Relasi
PropertyForRent dan Owner sudah
dalam bentuk
normal
ketiga dimana
sudah
tidak ada lagi ketergantungan transitif terhadap primary key. Relasi ClientRental
pada
tabel
2.4 telah
diubah
dengan
proses
normalisasi
menjadi
empat
relasi
dalam
bentuk
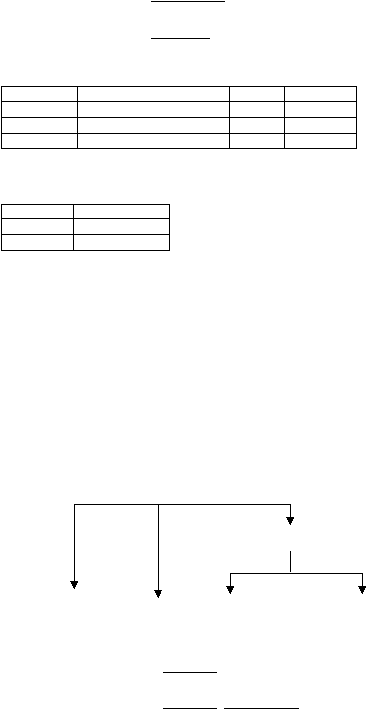
normal ketiga. Gambar 2.2
menunjukkan proses
dimana relasi asli 1NF
didekomposisikan menjadi relasi 3NF. Hasil dari relasi 3NF yang terbentuk adalah:
ClientRental
PropertyOwner
1NF
2NF
Client
Rental
PropertyForRent
Owner
3NF
Client
(clientNo, cName)
Rental
(clientNo, propertyNo, rentStart, rentFinish)
|
 25
PropertyForRent
(propertyNo, pAddress, rent, ownerNo)
Owner
(ownerNo, oName)
Gambar 2.2 Dekomposisi relasi ClientRental dari 1NF menjadi 3NF
Relasi asli ClientRental ditunjukkan pada tabel 2.4 dapat dibuat kembali dengan
menggabungkan
relasi
Client,
Rental,
PropertyForRent, dan
Owner.
Hal
ini
dapat
dilakukan
dengan
mekanisme primary
key
atau
foreign
key.
Sebagai
contoh,
atribut
ownerNo adalah
primary
key
pada
relasi
Owner,
dan
juga
ada
pada
relasi
PropertyForRent sebagai foreign key. Atribut ownerNo bertindak sebagai primary key /
foreign key mengijinkan penggabungan antara relasi PropertyForRent dan Owner untuk
mengidentifikasi nama dari PropertyOwner.
Atribut clientNo adalah primary
key dari relasi Client dan
juga ada pada relasi
Rental sebagai foreign key. Perlu diketahui, atribut clientNo pada relasi Rental memiliki
dua
peran
sebagai
foreign
key
dan
sebagai
bagian
primary
key
dari
relasi
ini.
Sama
halnya dengan atribut propertyNo adalah primary key dari
relasi PropertyForRent, dan
juga berada pada relasi Rental
yang bertindak sebagai foreign key
dan
bagian primary
key untuk relasi
ini. Relasi Client, Rental, PropertyForRent dan Owner dapat dilihat
pada tabel 2.8.
Client
clientNo
cName
CR76
John Kay
CR56
Aline Stewart
Rental
clientNo
propertyNo
rentStart
rentFinish
CR76
PG4
1-Jul-00
31- Aug – 01
CR76
PG16
1-Sep-01
1-Sep-02
CR65
PG4
1-Jul-00
31- Aug – 01
CR65
PG36
10-Oct-00
1-Dec-01
CR65
PG16
1-Sep-01
1-Sep-02
|
 26
PropertyForRent
PropertyNo
pAddress
rent
ownerNo
PG4
6
Lawrence St, Glasgow
350
CO40
PG16
5 Novar Dr, Glasgow
450
CO93
PG36
2
Manor Rd, Glasgow
375
CO93
Owner
ownerNo
oName
CO40
Tina Murphy
CO93
Tony Shaw
Tabel 2.8 Relasi keseluruhan 3NF yang diperoleh dari relasi ClientRental
2.4 Algoritma-Algoritma Normalisasi dalam Perancangan Basis Data Relasional
2.4.1 Normalisasi dengan Algoritma Dekomposisi
Dekomposisi
adalah
sebuah
alat
yang
membolehkan untuk
menghilangkan
redundansi. Akan
tetapi,
sangat
penting
untuk
mengecek apakah
dekomposisi
tersebut
tidak menimbulkan
masalah.
Faktanya
perlu diperiksa
apakah
dekomposisi
tersebut
dapat mengembalikan relasi aslinya dan juga dapat memeriksa batasan-batasan integritas
secara efisien (Ramakrishnan,
2003, p619). Algoritma dekomposisi itu sendiri
sebenarnya merupakan algoritma
dalam
normalisasi yang
pada
umumnya
sering
digunakan dalam normalisasi yang terdiri dari tiga tahap antara lain 1NF, 2NF, dan 3NF.
Algoritma
dekomposisi
memiliki
dua
sifat
yaitu
sifat
dependency
preservation dan
lossless(nonadditive) join (Elmasri, 2004, p334).
2.4.1.1 Dependency Preservation Property
Akan sangat berguna apabila setiap ketergantungan fungsional X
Y ditentukan
dalam
F
dan
juga
secara
langsung muncul
pada
salah
satu
skema
relasi
R
i
dalam
penguraian
D
atau dapat diambil
dari
ketergantungan
yang
muncul
pada
beberapa R
i
.
Secara
informal,
inilah
yang
disebut kondisi
dari
dependency
preservation.
|
|
27
Ketergantungan perlu dijaga karena tiap ketergantungan pada F menggambarkan batasan
dalam basis data. Jika
salah
satu
dari
ketergantungan tidak ditampilkan pada beberapa
relasi individu R
i
dari suatu penguraian, batasan ini tidak dapat dijalankan. Oleh karena
itu
perlu digabungkan dua atau
lebih
relasi dalam penguraian dan
kemudian diperiksa
bilamana
ketergantungan
fungsional
dapat
mempertahankan hasil
dari
operasi
join
tersebut (Elmasri, 2004, p335).
Jika
dekomposisi
tidak
dependency-preserving,
beberapa
ketergantungan
akan
hilang dalam proses dekomposisi tersebut. Untuk memeriksa keberadaan ketergantungan
yang
hilang,
dua
atau
lebih
relasi
dalam
penguraian
harus
digabungkan untuk
mendapatkan relasi
yang
mencakup
semua
atribut
sebelah
kiri
dan
kanan
dari
ketergantungan yang
hilang,
dan
kemudian
memeriksa
ketergantungan ada
dari
hasil
penggabungan – sebuah pilihan yang tidak praktis.
Penguraian D = { R1,R2,....,R
m
}
dari R disebut dependency-preserving terhadap
F jika penyatuan proyeksi F pada R
i
dalam D ekuivalen terhadap F, yaitu:
((pR
1
(F)) ?...? ((pR
m
(F))
+
=
F
+
2.4.1.2 Lossless (Nonadditive) Join Property
Sifat
penguraian
D
yang
lain
adalah
loseless join
atau
nonadditive join,
yang
menjamin tidak ada tuple palsu
yang dihasilkan ketika operasi natural join diterapkan
pada relasi dalam penguraian. Sifat loseless join selalu ditentukan
menjadi sekumpulan
ketergantungan F
yang
spesifik.
Sebuah
penguraian
D
=
{
R1,R2,....,R
m
}
dari
R
mempunyai sifat
loseless
(nonadditive)
join
berkenaan
dengan
sekumpulan
ketergantungan F pada R jika, untuk setiap keadaan relasi r dari R memenuhi F, dimana
* adalah natural join dari tiap relasi dalam D:
|
|
28
* p
(p
R1
(
r ,K,
),K,
p
Rm
(® )
))
=
®
Algoritma untuk menguji lossless (nonadditive) join property
Input : relasi universal R, dekomposisi D = { R1,R2,....,R
m
}
dari R dan sekumpulan F
dari Ketergantungan fungsional
“1. create an initial matrix S with one row i for each relation R
i
in D and one column j
for each attribute A
j
in R.
2. Set S(i,j) := b
ij
for all matrix entries.
(* each
b
ij
is a distinct symbol associated with indices (i,j) *)
3. For each row representing relation schema Ri
{
for each column j representing attribute Aj
{if ( relation R
i
includes attribute A
j
)
then set S(i,j):= a
j
;};};
(* each aj is a distinct symbol associated with index (j) *)
4. Repeat the following loop until a complete loop execution results in no changes to S
{for each functional dependency X
Y in F
{for all rows in S which have the same symbols in the columns
corresponding to attributes in X
{make the
symbols
in
each
column
that
correspond
to
an
attribute in Y be the same in all these rows as follows: if any of
the rows has
an “a”
symbol
for the column, if no “a”
symbol
exists for the attribute in any of the rows, choose one of the “b”
symbol that appear in one of the rows for the attribute and set
the rows to that same “b” symbol in the column ;};};};
|
 29
R1
R2
5. If a row is made up entirely of “a” symbols, then the decomposition has the lossless
join property; otherwise it does not.”( Elmasri, 2004, p337-p338).
2.4.2 Normalisasi dengan Algoritma Sintesis
Masalah dasar
dalam algoritma sintesis
adalah
mencari skema
database
3NF
untuk
mewakili skema
relasi
yang
tidak
muncul di 3NF
pada
algoritma dekomposisi.
Dengan masukan berupa skema relasi R dan F = himpunan FD terhadap R, maka dapat
dibuat skema database R = {R1
,
R2
,
…, R
p
}
dengan syarat sebagai berikut:
1. Semua F digolongkan berdasarkan R, F = {K
R
i
|
R
i
ada dalam R dan K adalah key
yang ditunjuk untuk R
i
}.
2. Setiap R
i
dalam R ada pada bentuk 3NF berdasarkan F.
3. Tidak ada skema database dengan skema relasi lebih sedikit daripada R yang
memenuhi syarat 1 dan 2.
4. Untuk semua relasi r(R) yang memenuhi F,
r =
p
(
r
)
p
(
r
)
…
p
R
p
(r)
.
Kompleksitas waktu yang dibutuhkan untuk melakukan normalisasi dengan
menggunakan algoritma sintesis adalah ?(n²) (Maier, 1983, p107).
Algoritma Sintesis Relasional dengan dependency preservation
Masukan
:
relasi
universal R dan kumpulan ketergantungan fungsional F pada atribut
dari R.
“1. Find a minimal cover G for F ;
2. For each left-hand side X of Functional Dependency that appears in G, create a
relation schema in D with attributes { X
?
{A1
} ?
{A2}.....
?
{A
k
}}, where X
A1, X
|
 30
A2
,
...., X
A
k
are the only dependencies in G with X as left-hand side (X is the
key of this relation) ;
3. Place any remaining atributes (that have not been placed in any relation) in a single
relation schema to ensure the attribute preservation property.” (Elmasri, 2004,
p341).
2.5 Analisis Algoritma
2.5.1 Definisi Algoritma
Algoritma berasal dari kata Algoris dan Ritmis yang pertama kali diungkapkan oleh Abu
Ja’far
Mohammad Ibn
Musa
Al
Khowarizmi
dalam
buku
Al-Jbr
w’almuqabala
(Horowitz, Ellis,
dan
Sartaj
Sahni,
1978,
p1).
Ada
beberapa definisi
yang
diberikan
mengenai pengertian algoritma (Horowitz, Ellis, dan Sartaj Sahni, 1978, p1), antara lain
sebagai berikut:
1. Menurut Abu Ja’far Mohammad Ibn Musa Al Khowarizmi
Algoritma adalah suatu metode khusus untuk menyelesaikan suatu permasalahan.
2. Menurut Goodman Hedetniemi
Algoritma adalah urut-urutan terbatas dari operasi – operasi yang terdefinisi dengan
baik,
yang
masing-masing
membutuhkan memori
dan
waktu
yang
terbatas
untuk
menyelesaikan suatu permasalahan.
3. Dalam Ilmu Komputer
Algoritma adalah suatu
metode
yang
terdiri dari serangkaian langkah-langkah yang
terstruktur dan
dituliskan
secara
sistematis
yang
akan
dikerjakan
untuk
menyelesaikan masalah dengan bantuan computer.
Masalah
Algoritma
Solusi
|
|
31
Ada
banyak
kriteria
dimana
kita
dapat
menilai
sebuah
algoritma,
antara
lain
(Horowitz, Sartaj Sahni, Sanguthevar Rajasekaran, 1978,p11):
1. Apakah algoritma itu mengerjakan apa yang kita harapkan?
2. Apakah algoritma itu berjalan dengan benar menurut spesifikasi asli dari tugas itu?
3. Apakah ada
dokumentasi yang
menjelaskan bagaimana menggunakannya dan
bagaimana algoritma itu bekerja?
4. Apakah prosedur dibuat sedemikian rupa seperti mereka menampilkan bagian fungsi
logikal?
5. Apakah kode algoritma dapat dibaca?
2.5.2 Definisi Analisis Algoritma
Algoritma tidak selalu memberikan hasil
terbaik yang mungkin diperoleh, maka
diharapkan adanya suatu evaluasi
mutu
hasil dari
algoritma
tersebut (Liu,
C.L,
1995
p271). Sekali sebuah algoritma diberikan kepada sebuah permasalahan dan dijamin akan
memberikan hasil
yang
diharapkan,
maka
langkah
penting
selanjutnya
adalah
permasalahan sebanding
dengan
jumlah
inputan
yang
diberikan
untuk
permasalahan
tersebut.
Semakin
besar
data
maka
semakin
besar
waktu
yang
diperlukan. Sebagai
contoh,
diperlukan
waktu
yang
lebih
besar
untuk
mengurutkan 10000
buah
data
dibandingkan
dengan
10
buah
data.
Akan
tetapi,
pada
keadaan
sebenarnya,
nilai dari
suatu
algoritma ditentukan dari
banyak
faktor,
misalnya
kecepatan
komputer
yang
dipakai,
kualitas
kompiler,
dan dalam
beberapa
kasus
kualitas
program itu
sendiri
(Weiss, 1996, p149).
|
|
32
Maksud dilakukannya
analisis
algoritma
adalah
untuk
(Horowittz,
Ellis,
dan
Sartaz Sahni, 1978, p1):
1. Memenuhi aktivitas intelektual.
2. Meramalkan sesuatu yang akan terjadi atau yang akan didapat dari algoritma
tersebut.
3. Mengetahui
efektifitas
suatu
algoritma
dibandingkan
dengan
algoritma
yang
lain
untuk persoalan yang sama
Dua buah algoritma
yang
berbeda dapat
digunakan
memecahkan permasalahan
yang
sama
dan
mungkin
saja
mempunyai
kompleksitas
waktu
(time
complexity)
yang
sangat
berbeda
(Liu,
CL,
1995,
p274).
Kompleksitas
waktu
algoritma terbaik
untuk
memecahkan
permasalahan tersebut
dinamakan
sebagai
kompleksitas
waktu
suatu
masalah (time complexity of a problem) (Liu, CL, 1995, p277).
2.5.3 Kompleksitas Tempat dan Kompleksitas Waktu Algoritma
Ada
juga
kriteria
lain
untuk
menilai algoritma
yang
mempunyai sebuah
hubungan langsung
dengan
performa.
Antara
lain
harus
mengerti
mengenai
waktu
perhitungan (computing
time)
dan
storage
yang
dibutuhkan.
Ukuran
biaya
dalam
pengeksekusian sebuah algoritma adalah besarnya space complexity dan time
complexity.
Kompleksitas
Tempat (Space
complexity) sebuah algoritma adalah jumlah
memori
yang dibutuhkan komputer untuk mengeksekusi suatu algoritma. Kompleksitas
waktu
(Time
complexity)
adalah jumlah
dari
waktu
yang dibutuhkan komputer
untuk
mengeksekusi suatu algoritma. (Horowitz, Sartaj Sahni, Sanguthevar Rajasekaran,
1997,p11). Besarnya waktu yang dibutuhkan suatu algoritma untuk menyelesaikan
|
|
33
sebuah masalah sebanding dengan jumlah inputan yang diberikan untuk permasalahan
tersebut. Semakin besar data maka semakin besar waktu yang diperlukan.
Ada
beberapa
definisi
yang
diberikan
untuk
mengukur
kompleksitas suatu
masalah
(Horowitz,
Sartaj
Sahni,
Sanguthevar Rajasekaran, 1997,p26),
yaitu
sebagai
berikut :
1.
Big “oh”
Definisi :
f(n) = O(g(n)), jika ada konstanta positif c dan n
o
dimana f(n) = c * g(n)
untuk
semua n, n = n
o
2.
Big-Omega
Definisi :
f(n) = ? (g(n)), jika ada konstanta positif c dan n
o
dimana f(n) = c * g(n) untuk
semua n, n = n
o
3.
Big-Theta
Definisi :
f(n) = T (g(n)), jika dan hanya jika ada konstanta positif c1, c
2
,
dan n
o
dimana
c1
g(n) = f(n) = c
2
g(n) untuk semua n, n = n
o.
4.
Little “oh”
Definisi :
f(n) = o(g(n)), jika dan hanya jika f(n) = O(g(n)) dan f(n) ? T (g(n)) atau jika
dan hanya jika
Lim
f(n)
=
0
n?8
g(n)
|
 34
5.
Little “omega”
Definisi :
f(n) = ?(g(n)) jika dan hanya jika.
Lim
g(n)
=
0
n?8
f(n)
Dari keempat definisi yang diberikan di atas, definisi pertama yang sering
digunakan dalam mengukur kompleksitas suatu permasalahan (Weiss, 1996, p161).
Fungsi
Nama
C
Konstanta
log n
Logaritma
log² n
Logaritma Quardrat
N
Linear
n log n
N Logaritma N
N²
Kuardatis
N³
Kubik
2
n
Eksponensial
Tabel 2.9 Tabel Fungsi Kompleksitas Suatu Algoritma
Jika
sebuah
algoritma
membutuhkan waktu
O(log
n),
maka
itu
lebih
cepat,
daripada O(n). Hampir sama, O(n log n) lebih baik daripada O(n²
)
,
tetapi tidak sebaik
O(n). Urutan waktu
hitung mulai dari
yang terbaik sampai
yang terburuk O(1) = O(log
n) = O (log
2
n) = O(n) = O(n log n) = O(n2
)
=
O(n³) = O(2
n
).
|
|
35
2.6 Alat Bantu Perancangan Sistem
2.6.1 Use Case Diagram
Use Case Diagram adalah diagram yang menggambarkan interaksi antara sistem
dengan sistem luar dan user. Dengan kata lain, secara grafik menggambarkan siapa yang
akan
menggunakan
sistem
dan
dengan
cara
bagaimana
user
bisa
berinteraksi dengan
sistem. Diagram
ini
secara
grafik
menggambarkan sistem sebagai
kumpulan
use
case,
actor (user) dan hubungan yang terjadi (Whitten, 2004, p271).
2.6.1.1 Use Case
Use case adalah alat untuk menggambarkan fungsi-fungsi sistem dari perspektif
pengguna luar dan dalam cara dan istilah yang mereka mengerti (Whitten, 2004, p272).
Use
case
digambarkan secara
grafik oleh
sebuah
elips
horizontal
dengan
nama
yang
muncul di atas, di bawah atau di dalam elips. Sebuah use case
menggambarkan tujuan
sistem dan rangkaian kegiatan dan interaksi yang dilakukan user dalam mencapai tujuan
tersebut. Use case
merupakan hasil penguraian batasan-batasan fungsionalitas sistem ke
dalam pernyataan – pernyataan yang lebih pendek.
2.6.1.2 Actor
Actor
adalah
segala
sesuatu
yang
perlu
berinteraksi dengan
sistem
untuk
pertukaran informasi (Whitten, 2004, p273).
|
|
36
2.6.1.3 Relationship
Relationship
digambarkan dengan
garis di
antara dua simbol di
dalam diagram
use
case.
Arti
hubungan
yang
terjadi
bisa
bervariasi
tergantung bagaimana
garis
digambarkan dan tipe simbol apa yang mereka hubungkan (Whitten, 2004, p273).
Jenis – jenis hubungan yang terjadi ada lima, antara lain:
•
Association
Sebuah
hubungan antara
sebuah
actor
dengan
sebuah
use
case
dimana
interaksi
terjadi di antara mereka (Whitten, 2004, p274).
•
Extend
Sebuah use case yang terdiri dari langkah-langkah yang dikutip dari use case
yang
lebih
kompleks untuk
menyederhanakan
use
case
asli
dan
memperluas
fungsionalitasnya. Biasanya
ditandai
dengan
label
“<<extend>>”
(Whitten,
2004,
p274).
•
Include
Sebuah
use
case
yang
mengurangi redundansi di
antara
dua
atau
lebih
use
case
dengan
menggabungkan langkah-langkah yang
sering
ditemukan.
Hubungannya
digambarkan dengan “<<uses>>” (Whitten, 2004, p274).
•
Depends on
Hubungan yang menggambarkan ketergantungan antar use case. Jenis hubungan ini
digambarkan dengan
garis
yang berpanah dimulai
dari
satu
use
case
menunjuk ke
use
case
tempat
ia
bergantung. Garis
hubungan ditandai
dengan
label
“<<depends
on>>” (Whitten, 2004, p275).
|
 37
•
Inheritance
Hubungan yang terjadi jika terdapat dua atau lebih actor yang memiliki sifat
yang
sama (Whitten, 2004, p275).
2.6.2 Diagram Alir (FlowChart)
Menurut O’Brien (2003, pG-8), diagram alir merupakan suatu representasi grafis
di
mana simbol-simbol digunakan untuk merepresentasikan operasi, data, aliran, logika,
perlengkapan, dan seterusnya. Suatu diagram alir program mengilustrasikan struktur dan
bagian
dari
operasi
program tersebut,
sementara sebuah
diagram alir
sistem
mengilustrasikan komponen-komponen dan aliran sistem informasi.
Tiga
konsep
utama
dalam
pemrograman terstruktur
yaitu
sekuensial,
kondisi
(condition),
dan
pengulangan (repetition)
(Pressman,
2001,
p424-425).
Sekuensial
mengimplementasikan langkah-langkah
proses
yang
penting
dalam
spesifikasi
algoritma-algoritma.
Kondisi
menyediakan
kemudahan
untuk
memilih
proses
berdasarkan logika, dan pengulangan untuk melakukan proses perulangan.
Gambar 2.3 Konsep Diagram Alir
|
|
38
2.7 Perancangan Basis Data
Menurut
Connolly
(2002,
p279),
perancangan basis
data
(database
design)
merupakan proses
pembuatan suatu
desain
untuk
sebuah
basis
data
yang
mendukung
operasional
dan
sasaran
suatu
perusahaan.Ada
2
pendekatan
untuk
mendesain
suatu
basis data, antara lain:
1. Pendekatan bottom-up
Yang
dimulai
pada
tingkat awal
dari
attribut, yaitu
properti dari
entity
dan
relationship,
yang mana melalui analisis dari asosiasi antar atribut, dikelompokkan
menjadi
relasi
yang
merepresentasikan jenis-jenis
entity
dan
relasi
antar
entity.
Pendekatan ini
cocok
untuk
mendesain
basis
data
yang
sederhana
dengan
jumlah
attribut yang tidak banyak.
2. Pendekatan top-down
Digunakan
pada
basis
data
yang
lebih
kompleks, yang
dimulai
dengan
pengembangan dari
model data yang mengandung beberapa entity dan relasi
tingkat
tinggi
dan
kemudian
memakai
perbaikan
top-down
berturut-turut untuk
mengidentifikasi entity,
relasi
dan
attribut
berkaitan
tingkat
rendah. Pendekatan ini
biasanya digambarkan melalui Entity Relationship (ER).
2.7.1 Perancangan Basis Data Konseptual
Menurut
Connoly
(2002,
p419),
proses
perancangan basis
data
konseptual
merupakan proses
pembuatan sebuah
model
informasi
yang digunakan
dalam
sebuah
perusahaan,
yang tidak tergantung
pada
semua
masalah
fisik. Awal
tahap
ini
dimulai
dengan
pembuatan konseptual
data
model perusahaan
yang
secara
keseluruhan bebas
dari detil
implementasi seperti DBMS yang digunakan, program aplikasi, bahasa
|
|
39
pemograman, platform
untuk
hardware, tingkat kinerja,
maupun bentuk masalah fisik
lainnya.
Model data konseptual didukung dengan dokumentasi, termasuk sebuah kamus
data,
yang
dihasilkan
melalui
pengembangan model.
Berikut
ini
merupakan
langkah-
langkah dalam merancang basis data konseptual, antara lain (Connolly, 2002, p422):
1. Identifikasi tipe entity
Ada satu metode dalam pengidentifikasian entity yaitu dengan mengambil spesifikasi
kebutuhan user. Dari spesifikasi ini, tentukan kata benda atau frase kata benda yang
disebutkan,
misalnya
noStaf,
NmStaf,
noProperti,
AlamatProperti, sewa,
jumlahKamar. Perlu
untuk
mencari objek
utama seperti orang,
tempat, atau konsep
menarik,
memisahkan kata
benda
tersebut
dengan objek
yang
lainnya.
Misalnya,
noStaf, NmStaf dikelompokkan dengan sebuah objek
atau
entity yang
disebut Staf
dan
noProperti,
AlamatProperti, sewa,
dan
jumlahKamar
dikelompokkan
dengan
sebuah entity yang disebut PropertiSewa.
2. Identifikasi tipe relationship
Tujuannya adalah
untuk
mengidentifikasi
hubungan penting
yang
berada
diantara
tipe
entity yang telah diidentifikasi. Secara khusus, hubungan diindikasikan dengan
kata kerja atau verbal expression, sebagai contoh:
•
Staf mengatur PropertiSewa
•
PemilikPribadi memiliki PropertiSewa
•
PropertiSewa berhubungan dengan Sewa
|
|
40
3. Identifikasi dan hubungkan atribut-atribut dengan tipe entity atau relationship
Tujuannya
adalah
untuk
mengasosiasikan
atribut-atribut dengan
entity yang
tepat
atau tipe relationship. Misalnya pada entity Staf, atribut nama dapat dikomposisikan
lagi menjadi lebih rinci yaitu fNama, lNama. Begitu pun dengan entity PropertiSewa,
atribut alamat dapat dikomposisikan menjadi jalan, kota, dan kode pos.
4. Menentukan domain atribut
Tujuan dari
tahap
ini adalah
untuk menentukan domain untuk
atribut-atribut dalam
model data
konseptual lokal. Domain adalah sekelompok
nilai
dari
yang
satu atau
lebih atribut yang mengambil nilai mereka. Sebagai contoh, antara lain:
•
Domain atribut
yang valid dari noStaf adalah panjangnya 5 karakter string,
dimana
dua
karakter
pertama
sebagai
huruf dan
karakter
berikutnya
bisa
berupa angka dari 1-999.
•
Nilai yang mungkin untuk atribut JenisKelamin yaitu bisa berupa “M” atau
“F”.
5. Menentukan atribut candidate dan primary key
Candidate
key
adalah
sekumpulan atribut
dari
sebuah
entity
yang
secara
unik
mengidentifikasi setiap
kejadian
dari
entity
tersebut.
Pada
saat
memilih
sebuah
primary
key
diantara beberapa
candidate
key,
perlu
mengikuti aturan
yang dapat
membantu dalam pemilihan, antara lain:
•
Candidate key dengan kumpulan atribut yang minim
•
Candidate key yang perubahan nilainya kecil
•
Candidate key dengan karakter yang paling sedikit
•
Candidate key dengan nilai maximum terkecil
|
|
41
•
Candidate key yang paling mudah digunakan dari sisi user
6. Mempertimbangkan penggunaan dari konsep pemodelan perluasan
Tujuan
dari
tahap
ini
adalah
untuk
mempertimbangkan penggunaan
dari
konsep
pemodelan perluasan,
seperti
specialization/generalization,
aggregation,
dan
composition.
Jika
menggunakan pendekatan specialization,
perlu
membedakan
antara entity
dengan
medefinisikan satu
atau
lebih
subclass
dari
sebuah superclass
entity. Jika
menggunakan pendekatan generalization, dengan
mengidentifikasi fitur
yang umum diantara entity. Aggregation diperlukan apabila adanya hubungan “has–
a” atau
“is-part-of” diantara tipe entity, dimana satu merepresentasikan “whole” dan
“the
part”
lainnya.
Composition
(tipe khusus dari
aggregation)
diperlukan apabila
ada
sebuah
hubungan
diantara
tipe
entity
dimana
terdapat
suatu
kepemilikan
yang
kuat diantara “whole” dan “part”.
7. Pengecekkan model untuk redundansi
Pada
tahap
ini, ada dua
aktivitas yang
digunakan untuk
menghilangkan redudansi,
antara lain:
•
Memeriksa kembali hubungan one-to-one (1:1)
Identifikasi dua entity yang memiliki kesamaan objek dalam suatu
perusahaan. Sebagai contoh, dua entity Klien dan Penyewa merupakan entity
yang
memiliki
kesamaan, sehingga
kedua
entity
ini
harus
digabungkan
bersama.
Apabila
memiliki
perbedaan
primary
key,
maka
pilih
salah
satu
yang akan menjadi primary key dan yang lainnya menjadi alternate key.
|
|
42
•
Menghilangkan hubungan yang redundan
Sebuah
hubungan yang
redundan
adalah
jika
informasi yang
sama
dapat
dihasilkan
melalui
hubungan
yang
lain.
Sehingga
hubungan yang
redundan
itu tidak diperlukan/dihilangkan.
8. Validasi model konseptual lokal bertentangan dengan transaksi user
Ada
dua
pendekatan
untuk
menentukan dimana
model
data
konseptual
lokal
mendukung transaksi yang dibutuhkan user, antara lain:
•
Menjelaskan transaksi-transaksi tersebut
Pada pendekatan ini,
mengecek semua
informasi
yang dibutuhkan oleh tiap
transaksi yang dibutuhkan oleh model, dengan mendokumentasikan deskripsi
dari kebutuhan-kebutuhan tiap transaksi.
•
Menggunakan pathway
transaksi
Pendekatan
kedua
ini
setiap
transaksi
direpresentasikan ke
dalam
bentuk
diagram
ER.
Pendekatan
ini
mengijinkan
perancang
untuk
memperlihatkan
area
dari
model
yang
tidak
dibutuhkan oleh
transaksi dan
area
itu
dimana
kritis untuk mengadakan transaksi.
9. Mengulang kembali model data konseptual dengan user
Tujuan
dari
tahap
ini
adalah
untuk
mengulang kembali
untuk
meyakinkan dimana
model
yang
telah
dibuat
telah
benar
untuk
direpresentasikan.
Apabila
masih
ada
maka perlu untuk diulang tahap-tahap sebelumnya sampai model itu benar.
|
|
43
2.7.2 Perancangan Basis Data Logikal
Menurut Connolly (2002, p441), perancangan
basis data secara logikal
merupakan proses pembuatan model informasi yang digunakan perusahaan berdasarkan
pada
model
data
khusus,
tapi
bebas
dari
DBMS
tertentu
dan
masalah
fisik
lainnya.
Tahap
ini mematahkan model konseptual pada sebuah
model
logikal
yang dipengaruhi
oleh data model untuk tujuan basis data. Model data logikal merupakan sumber
informasi
untuk tahap perancangan
fisikal, menyediakan
suatu kendaraan
bagi
perancang
basis
data
fisikal,
untuk
melakukan pertukaran
yang
sangat
penting
untuk
perancangan basis data yang efisien.
Langkah-langkah dalam perancangan basis data logikal, sebagai berikut:
1. Memindahkan fitur yang tidak kompatibel dengan model relational
Membersihkanmodel data konseptual
local
untuk
menghapus
fitur
yang
tidak
kompatibel dengan model relasi. Pada langkah ini kita mentransform struktur
kedalam form yang lebih mudah ditangani oleh sistem. Langkah-langkahnya, terdiri
dari:
•
Remove many-to many (*.*) type binary relationship
•
Remove many-to many (*.*) type recursive relationship
•
Remove complex type relationship
•
Remove multi-valued
2. Mengambil relasi untuk model data logikal lokal
Tujuannya adalah
membuat
relasi
untuk
model
data
logical
local
untuk
menggambarkan entity-entiti,
relationship-relationship,
dan
atribut-atribut
yang
diidentifikasi. Struktur-struktur yang mungkin disajikan dalam model data:
|
|
44
•
Type strong entity
•
Type weak entity
•
One-to-many (1:*) type binary relationship
•
One-to-one (1:1) type binary relationship
•
One-to-one (1:1) recursive relationship
•
Type superclass atau subclass
•
Many-to-many (*.*) binary relationship
•
Type complex relationship
•
Atribut-atribut Multi valued
3. Validasikan relasi menggunakan normalisasi
Proses normalisasi terdiri atas tahap-tahap sebagai berikut:
•
Bentuk normal pertama (1NF)
•
Bentuk normal kedua (2NF)
•
Bentuk normal ketiga (3NF)
•
Boyce-Codd Normal Form (BCNF)
•
Bentuk normal keempat (4NF)
•
Bentuk normal kelima (5NF)
4. Validasikan relasi bertentangan dengan transaksi user
Tujuannya
untuk meyakinkan
bahwa relasi pada model data logical local
mendukung transaksi yang diperlukan oleh tampilan.
|
|
45
5. Mendefinisikan integrity constraints
Tujuannya
untuk mendefinisikan
integrity constraints yang diberikan
dalam
tampilan. Integrity
constraints
adalah
constraints-constraints
yang
kita
harapkan
untuk menyatukan dan melindungi basis data agar tidak menjadi inconsisten.
6. Mengulang model data logikal lokal dengan user
Meyakinkan model data logikal lokal dan mendukung dokumentasi yang
menjelaskan model tersebut benar untuk direpresentasikan.
2.7.3 Perancangan Basis Data Fisikal
Menurut Connolly (2002, p478), perancangan basis data secara fisik
merupakan
proses pembuatan sebuah deskripsi dari implementasi basis data pada secondary storage
yang
menjelaskan basis
relasi,
organisasi
file,
dan
indeks
yang
digunakan
untuk
memperoleh akses pada data yang efisien, dan masalah integritas lainnya yang berkaitan,
dan
menetukan
mekanisme
security.
Tahap
ini
memungkinkan perancang
untuk
menentukan
bagaimana
basis
data
diimplementasikan. Antara
rancangan
logikal
dan
fisikal
terdapat
keterkaitan,
hal
ini
disebabkan karena
keputusan
diambil
selama
rancangan
fisikal
untuk
meningkatkan kinerja bisa
mempengaruhi data
model
logikal.
Kegiatan-kegiatan yang dilakukan, antara lain:
1. Menterjemahkan model data logical global untuk DBMS
a. Mendesain relasi dasar
Tujuannya
untuk
memutuskan
bagaimana
cara
menggambarkan identitas relasi
dasar
dalam
model
data
logikal global
dalam
target
DBMS.
Untuk
setiap
identifikasi relasi dalammodel data global, kita memiliki definisi terdiri dari:
• Nama relasi
|
|
46
• Daftar atribut-atribut dalam penyimpanan
•
Primary key (PK), alternate key (AK) dan foreign keys (FK)
•
Referensi
constraints integrity untuk
untuk
setiap
foreign keys yang
diidentifikasi.
b. Mendesain representasi dari pengambilan data
Memutuskan cara
merepresentasikan beberapa pengambilan data
muncul
dalam
model
data
logical
global
pada
sasaran
DBMS.
Atribut-atribut
yang
nilainya
dapat ditemukan dengan memeriksa nilai dari atribut lain dikenal dengan derived
atau calculated attributes.
c. Mendesain entrerprise constraints
Merancang batasan
enterprise
untuk
sasaran
DBMS.
Sebagai
contoh,
dalam
pembuatan kode SQL berikut ini:
CONSTRAINT StaffNotHandlingTooMuch
CHECK (NOT EXISTS (SELECT staffNo FROM
PropertyForRent GROUP BY
staffNo HAVING ©OUNT(*)
>
100
))
2. Merancang representasi fisikal
a. Menganalisa transaksi
Tujuannya untuk mengerti fungsi dari transaksi yang akan dijalankan pada basis
data dan untuk menganalisa transaksi-transaksi penting.
|
|
47
b. Memilih organisasi file
Tujuannya
untuk
menentukan organisasi
file
yang
efisien
untuk
setiap
relasi
dasar. Salah satu tujuan penting dari perancangan basis data fisikal adalah untuk
menyimpan data dengan cara yang efisien.
c. Pemilihan Index
Tujuannya untuk menyediakan mekanisme untuk spesifikasi key tambahan untuk
relasi yang dapat digunakan untuk penerimaan data lebih efisien.
d. Estimasi kapasitas penyimpanan yang dibutuhkan
Tujuannya
adalah
untuk
memperkirakan besarnya
penyimpanan
file
yang
dibutuhkan basis data.
3. Merancang pandangan user
Tujuannya
untuk
merancang
pandangan
dari
user
yang
diidentifikasi selama
pengumpulan kebutuhan
dan
analisa
tahap
dari
daur
hidup
aplikasi
basis
data
relasional.
4. Merancang mekanisme keamanan
Tujuannya untuk mendesain keamanan basis data yang dispesifikasi oleh user. Pada
umumnya ada dua jenis keamanan basis data:
• Keamanan sistem
Menangani akses dan penggunaan basis data pada level sistem, seperti nama
user dan password.
• Keamanan data
Menangani akses dan penggunaan objek basis data
(seperti relasi dan
tampilan) dan tindakan yang user dapat peroleh pada objek.
|