|
BAB 2
LANDASAN TEORI
2.1 Teori umum
•
Data
Data
merupakan
aliran fakta
yang mewakili
kejadian
yang
terjadi
dalam
organisasi atau dalam lingkungan fisik sebelum mereka diatur menjadi sebuah
bentuk
yang
dapat
dimengerti dan digunakan
oleh pengguna (Laudon,
2000, p8).
Sedangkan menurut Navathe dan Elmasri (2000, p4), data adalah fakta yang dapat
disimpan dan memiliki arti. Sehingga dapat disimpulkan bahwa data adalah fakta
yang telah terjadi, memiliki arti, dan dapat disimpan serta dapat diatur sedemikian
rupa sehingga dapat digunakan untuk berbagai tujuan.
Secara tradisional, data diorganisasikan ke dalam suatu hirarki yang terdiri
atas elemen, rekaman (record), dan berkas (file).
•
Elemen data
Elemen data adalah satuan data terkecil yang tidak dapat dipecah
lagi
menjadi
unit
yang bermakna.
Istilah lain
untuk elemen data adalah
field, kolom, item, dan atribut.
•
Rekaman
Rekaman adalah gabungan sejumlah elemen data yang saling
terkait. Dalam sistem basis data relasional, rekaman biasa disebut dengan
istilah tuple atau baris.
6
|
|
7
•
Berkas
Himpunan seluruh rekaman yang bertipe sama membentuk sebuah
berkas.
Berkas
dapat
dikatakan
sebagai
kumpulan rekaman
data
yang
berkaitan dengan suatu subyek. Dalam sistem basis data relasional,
berkas mewakili komponen yang disebut tabel atau relasi.
•
Basis data
Basis
data
adalah
suatu
koleksi
data
yang
saling
berhubungan secara
logikal,
dan
sebuah
deskripsi
data
yang dirancang untuk
memenuhi kebutuhan
informasi
suatu
organisasi (Connolly,
2005,
p15).
Dapat
dikatakan
juga
basis
data
adalah kumpulan
file
yang
saling
berhubungan, hubungan
tersebut
biasa
ditunjukkan dengan kunci dari tiap file yang ada. Suatu basis data menunjukkan
satu
kumpulan
data
yang
dipakai
dalam
satu
lingkup
organisasi. Basis
data
menjadi salah satu bagian penting dari perusahaan untuk menyimpan informasi-
informasi yang diinginkan perusahaan tersebut.
•
Sistem basis data
Sistem
basis
data
pada
dasarnya
adalah
sekumpulan aplikasi
yang
berinteraksi dengan basis data yaitu DBMS dan basis data itu sendiri (Connoly
2005, p4). Keseluruhan sistem terkomputerisasi tersebut membolehkan pengguna
menelusuri kembali dan mengubah informasi tersebut sesuai kebutuhan.
|
|
8
2.2 Teori khusus
2.2.1 Pendekatan Basis Data
Basis data
adalah
suatu
koleksi
data
yang saling
berhubungan
secara
logikal, dan sebuah deskripsi data yang dirancang untuk memenuhi kebutuhan
informasi
suatu
organisasi (Connolly, 2005,
p15).
Basis
data
juga
dapat
diartikan sebagai dari file
yang
saling
berhubungan di
mana setiap baris pada
suatu
basis
data
juga
harus
saling
terhubung dengan
baris
pada
lain
file
(Whitten, 2004, p548).
Dapat disimpulkan bahwa basis
data
menyimpan data
yang
saling
berhubungan yang
dibutuhkan
oleh
suatu
organisasi
untuk
menyediakan informasi-informasi yang berguna.
Dengan
basis
data
dapat
mempercepat proses
pemenuhan
suatu
kebutuhan informasi
suatu
organisasi
di
mana
kebutuhan
informasi
tersebut
berbeda-beda pada tiap-tiap organisasi.
Sebuah
basis
data
yang
besar,
memerlukan sebuah
perangkat
lunak
untuk
mengatur basis
data tersebut secara keseluruhan. Perangkat
lunak
yang
dapat digunakan untuk membuat, mengakses, mengontrol, dan mengatur suatu
basis
data
dinamakan sistem
manajemen
basis
data,
biasa
disebut
dengan
database management system, disingkat DBMS (Whitten, 2004, p554).
Selain membutuhkan sebuah perangkat lunak untuk mengatur basis data
yang
ada, sebuah
organisasi
juga
membutuhkan seseorang
yang
bertanggung
jawab
terhadap basis data
yang ada.
Orang
yang bertanggung jawab terhadap
realisasi
fisikal
dari
suatu
basis
data,
yang
meliputi perancangan basis
data
fisikal,
implementasi, kontrol
keamanan
dan
integritas,
pemeliharaan
operasional sistem, dan
memastikan kepuasan pengguna terhadap unjuk kerja
|
 9
aplikasi dinamakan dengan database administrator , disingkat DBA (Connolly,
2005, p22).
2.2.2 Database Application Lifecycle (DBLC)
Untuk merancang aplikasi sistem basis data diperlukan tahapan-tahapan
terstruktur
yang
harus diikuti
yang
dinamakan dengan
Siklus
Hidup
Aplikasi
Basis
Data
(Database Application Lifecycle) atau
disingkat dengan
DBLC.
Perlu diingat bahwa tahapan dalam DBLC
tidak
harus
berurutan, namun juga
melibatkan beberapa pengulangan ke tahapan sebelumnya melalui putaran
balik (feedback loops). Tahapan-tahapan tersebut terlihat pada gambar 2.1.
Tahapan
Aktivitas Utama
Database planning
Merencanakan bagaimana tahapan dari DBLC dapat terrealisasi
dengan efektif dan efisien
System definition
Menspesifikasikan ruang lingkup dari sistem basis data
Requirement collection and
analysis
Mengumpulkan dan menganalisa kebutuhan dari sistem basis
data yang baru
Database desain
Desain konseptual, logikal dan fisikal dari basis data
DBMS selection (optional)
Memilih DBMS yang sesuai dengan sistem basis data
Application Desain
Melakukan desain tampilan dan aplikasi yang menggunakan dan
memproses basis data
Prototyping (optional)
Membangun model untuk sistem basis data yang memungkinkan
pendesain untuk memvisualisasikan dan mengevaluasi
bagaimana sistem akhir
Implementation
Membuat definisi fisikal dari basis data dan aplikasinya
Data convertion and
loading
Memasukkan data lama ke dalam sistem basis data dan merubah
koneksi dari aplikasi lama ke sistem basis data baru
Testing
Basis data diperiksa untuk mengetahui kesalahan dan
divalidasikan terhadap kebutuhan pengguna
Operation maintenance
Sistem basis data diimplementasikan secara penuh dan diperiksa
secara kesinambungan. Saat dibutuhkan, kebutuhan baru bisa
ditembahkan melalui tahapan alur hidup
Tabel 2.1 Tahapan DBLC (Connolly, 2005, p285)
|
 10
Database Planning
System Definition
Requirements Collection
and
Analysis
DBMS
Selection
(optional)
Database
Design
Conceptual
Database
Design
Logical Database
Design
Application Design
Physical
Database
Design
Prototyping (optional)
Implementation
Data Conversion
and
Loading
Testing
Operational
Maintenance
Gambar 2.1 Database Application Lifecycle (Connolly, 2005, p284)
|
|
11
2.2.3 Perencanaan Basis Data
Perencanaan basis
data
adalah
kegiatan
pengaturan
yang
memungkinkan tahap-tahap dalam aplikasi basis data dapat diwujudkan secara
efisien dan secara efektif mungkin (Connolly, 2005, p285). Tahap perencanaan
basis data juga harus menjelaskan :
•
Mission statement
dari proyek basis
data. Mission
statement
ini
menjelaskan tujuan
utama
aplikasi
basis
data,
juga
membantu
menjelaskan tujuan proyek basis data,
dan
menyediakan maksud
yang
lebih jelas dalam pembuatan
aplikasi basis data secara efektif dan
efisien
(Connolly,
2005,
p286).
Dengan
merumuskan
apa
sebenarnya
yang
menjadi tujuan dari proyek basis data
ini
diharapkan dapat
lebih
memfokuskan pekerjaan pada tahap selanjutnya.
•
Mission objectives. Selain merumuskan tujuan dari sebuah proyek basis
data,
harus
diperhatikan juga
mengenai
tugas
apa
saja
yang
harus
didukung oleh
basis
data
tersebut.
Setiap
mission
objective
akan
menjelaskan tugas tertentu yang harus didukung oleh basis data, dengan
asumsi jika
basis
data
mendukung
mission
objectives,
maka
mission
statementnya juga akan sesuai (Connolly, 2005, p286).
2.2.4 Pendefinisian Sistem
Pendefinisian sistem (system definition)
menggambarkan ruang lingkup
dan batasan
aplikasi basis data
dan
kebanyakan
pandangan
pengguna
(major
user
view)
(Connolly, 2005,
p286).
Hal
ini
sangat
penting dilakukan dalam
|
|
12
proses perancangan basis data agar lebih terfokus pada proyek basis data yang
dibuat.
Pandangan pengguna
(user
view)
sangat
diperlukan untuk
mengidentifikasi
informasi-informasi
yang
dibutuhkan oleh
user.
Pandangan
pengguna
menggambarkan apa
yang dibutuhkan oleh
aplikasi basis
data dari
sudut pandang
jabatan
tertentu,
seperti
manajer
atau
pengawas,
maupun dari
sudut
pandang
area
aplikasi
perusahaan,
seperti
pemasaran, personalia, atau
pengawasan persediaan (Connolly, 2005, p287).
2.2.5 Pengumpulan Kebutuhan dan Analisis
Tahap selanjutnya
yang dilakukan setelah Pendefinisian Sistem adalah
tahap pengumpulan kebutuhan dan analisis. Dalam
tahap ini dilakukan proses
pengumpulan dan
analisa
informasi
tentang
bagian
organisasi
yang
akan
didukung
oleh
aplikasi
basis
data,
dan
menggunakan informasi
ini
untuk
mengidentifikasi kebutuhan pengguna
terhadap
sistem
yang
baru (Connolly,
2005, p288).
Suatu
proses
resmi
dalam
menggunakan teknik-teknik
seperti
wawancara atau kuesioner untuk mengumpulkan fakta-fakta tentang sistem dan
kebutuhan-kebutuhannya dinamakan dengan teknik fact-finding (Connolly,
2005, p314). Ada lima kegiatan yang dipakai dalam teknik ini, yaitu :
1. Memeriksa dokumentasi
Pemahaman
terhadap
jalannya
sistem
akan
cepat
diperoleh
dengan
memeriksa dokumen-dokumen,
formulir, laporan, dan berkas
yang
terkait dengan sistem yang sedang berjalan pada perusahaan.
|
|
13
Dengan pemeriksaan ini diharapkan dapat mengetahui data-data apa saja
yang akan disimpan di dalam basis data.
2. Wawancara
Wawancara
bertujuan
untuk
mengumpulkan fakta-fakta,
memeriksa kebenaran
fakta
yang
ada
dan
mengklarifikasinya,
menimbulkan
antusiasme,
melibatkan
pengguna
akhir,
mengidentifikasi
kebutuhan-kebutuhan, dan
mengumpulkan
ide-ide
dan
pendapat
(Connolly, 2005, p317). Teknik ini memerlukan kemampuan komunikasi
yang
baik
untuk
menghadapi pengguna
yang
memiliki
nilai,
prioritas,
pendapat, motivasi, dan kepribadian yang berbeda-beda.
Keuntungan menggunakan teknik ini menurut Thomas Connolly (2002,
p3018) antara lain:
•
Memungkinkan
orang
yang
diwawancara
untuk
menanggapi
pertanyaan dengan bebas dan terbuka
•
Memungkinkan
orang
yang
diwawancara
merasa
bahwa
ia
merupakan bagian dari proyek
•
Memungkinkan pewawancara untuk
menindaklanjuti komentar-
komentar menarik yang dibuat oleh orang yang diwawancara
•
Memungkinkan pewawancara untuk
mengubah atau
menyusun
kembali pertanyaan selama kegiatan wawancara
•
Memungkinkan pewawancara untuk mengamati bahasa tubuh orang
yang diwawancara
|
|
14
Kerugian teknik ini menurut Thomas Connolly (2002,p306) yaitu :
•
Sangat memakan waktu dan biaya, sehingga menjadi tidak praktis
•
Keberhasilannya
tergantung
pada
kemampuan
komunikasi
pewawancara
•
Keberhasilannya
tergantung
pada
keinginan
orang
yang
diwawancara untuk ikut serta dalam wawancara
3. Mengamati operasional perusahaan
Pengamatan ini
memungkinkan untuk
ikut
serta atau
mengamati
seseorang melakukan kegiatan untuk mempelajari sistem. Salah satu
faktor
pengamatan dapat
berhasil
adalah
dengan
mencari
informasi
sebanyak mungkin tentang aktivitas yang akan diamati serta orang
yang
melakukan aktivitas tersebut.
Keuntungan menggunakan teknik ini antara lain :
•
Validitas fakta dan data dapat diperiksa
•
Pengamat dapat melihat dengan jelas apa yang dikerjakan
•
Pengamat
juga
dapat
memperoleh
data
yang
menjelaskan
lingkungan fisik dari tugas yang diberikan
•
Relatif murah
•
Pengamat dapat membuat pengukuran kerja
|
|
15
Kerugian teknik ini yaitu :
•
Sangat memakan waktu dan biaya, sehingga menjadi tidak praktis
•
Dapat terlewat dalam mengamati
tugas-tugas
yang
melibatkan
tingkat kesulitan yang lain
•
Beberapa tugas tidak selalu dilakukan dengan cara seperti pada saat
pengamatan
4. Penelitian
Selain
melakukan penelitian
yang
berasal dari
dalam organisasi
itu
sendiri,
dapat
juga
dilakukan
pengumpulan
informasi
yang
berasal
dari
luar organisasi tersebut. Beberapa contoh sumber informasi
tersebut
antara
lain
jurnal
komputer, buku-buku
referensi,
dan
internet.
Sumber
informasi
tersebut
juga
dapat
digunakan
untuk
memecahkan masalah
serupa.
Keuntungan menggunakan teknik ini antara lain :
•
Dapat menghemat waktu jika solusinya telah tersedia
•
Peneliti dapat mengamati
cara orang lain memecahkan
masalah
yang sama atau menemui kebutuhan yang serupa
•
Membuat para peneliti selalu up-to-date dengan perkembangan baru
Kerugian teknik ini yaitu :
•
Dapat menjadi sangat memakan waktu
•
Membutuhkan akses ke sumber informasi yang tepat
•
Dapat saja tidak membantu memecahkan masalah karena tidak
didokumentasikan
|
|
16
5. Kuesioner
Teknik
lain
yang
dapat
digunakan untuk
mengumpulkan
informasi
yang
dibutuhkan
adalah
dengan
menggunakan kuesioner.
Kuesioner adalah
suatu
dokumen
dengan
tujuan
khusus
yang
memungkinkan fakta-fakta
dikumpulkan
dari
banyak
orang
sambil
menjaga
kontrol
terhadap
tanggapan yang
diberikan
(Connolly, 2005,
p320).
Keuntungan menggunakan teknik ini antara lain :
•
Orang dapat melengkapi dan mengembalikan kuesioner pada waktu
yang sebaik-baiknya
•
Tidak mahal untuk mengumpulkan data dari banyak orang
•
Responden
lebih
mudah
untuk
memberikan jawaban
yang
benar
karena jawaban yang diberikan dapat dijaga kerahasiaannya
•
Tanggapan dapat ditabulasikan dan dianalisa dengan cepat
Kerugian teknik ini yaitu :
•
Jumlah responden dapat saja rendah, sekitar 5% sampai 10%
•
Kuesioner dapat saja dikembalikan dengan tidak lengkap
•
Tidak
menyediakan kesempatan untuk
mengubah pertanyaan yang
salah diartikan
•
Tidak dapat mengamati dan menganalisa bahasa tubuh responden
•
Memakan waktu untuk menyiapkan kuesioner
|
|
17
2.2.6 Entity-Relationship Modelling (E-R Modelling)
Model
Entity-Relationship
merupakan salah
satu
model
yang
dapat
memastikan pemahaman yang
tepat
terhadap
data
dan
bagaimana
penggunaannya di
dalam suatu
organisasi
(Connolly, 2005,
p342). Model
ini
dimulai
dengan
identifikasi entitas
dan
relationship
antardata
yang
harus
direpresentasikan
di dalam model, dan kemudian ditambahkan
atribut dan
setiap constraint pada entitas, relationship, dan atributnya.
2.2.6.1 Konsep Dasar Model E-R
Beberapa konsep dasar dalam model E-R, yaitu:
A. Tipe Entitas
Tipe entitas adalah sekumpulan
objek yang memiliki
properti
yang
sama,
yang
diidentifikasikan di
dalam
organisasi
karena
keberadaannya yang
bebas
(independent
existence)
(Connolly, 2005, p343). Sedangkan entity occurrence adalah sebuah
objek
dari
satu
tipe
entitas
yang
dapat
diidentifikasi secara
unik
(Connolly,
2005,
p345).
Keberadaan
objek-objeknya secara
fisik/nyata (physical existence), seperti entitas Pegawai, Rumah, dan
Pelanggan,
atau
secara
konseptual/abstrak (conceptual
existence),
seperti entitas Inspeksi, Penjualan, dan Peninjauan.
Setiap
tipe
entitas
dilambangkan dengan
sebuah
persegi
panjang
yang
diberi
nama
dari
entitas
tersebut.
Nama
tipe
entitas
biasanya adalah kata benda tunggal. Huruf pertama dari setiap kata
|
 18
pada nama tipe entitas
ditulis dengan
huruf besar. Representasi
diagram tipe entitas terlihat pada gambar 2.2.
Gambar 2.2
Representasi diagram dari tipe entitas Pegawai dan Cabang
(Connolly, 2005, p345)
Tipe entitas dapat diklasifikasikan menjadi :
•
Tipe Entitas Kuat, yaitu tipe entitas yang keberadaannya tidak
bergantung pada tipe entitas lainnya (Connolly, 2005, p354).
•
Tipe
Entitas
Lemah,
yaitu
tipe
entitas
yang
keberadaannya
bergantung pada tipe entitas lainnya (Connolly, 2005, p355).
Gambar 2.3
Representasi diagram tipe entitas kuat dan tipe entitas lemah
(Connolly, 2005, p355)
B. Tipe Relationship
Tipe relationship adalah sekumpulan hubungan antartipe
entitas yang
memiliki arti (Connolly, 2005, p346). Sedangkan
|
|
19
relationship
occurrence
adalah
sebuah
hubungan yang
dapat
diidentifikasikan secara
unik,
yang
meliputi
sebuah
kejadian
(occurrence) dari setiap tipe entitas di dalam relationship
(Connolly, 2005, p346).
Tipe
relationship
digambarkan dengan
sebuah
garis
yang
menghubungkan
tipe
entitas-tipe
entitas
yang
saling
berhubungan.
Garis
tersebut diberi
nama
sesuai
dengan
nama
hubungannya
dan
diberi tanda panah satu arah di samping nama hubungannya.
Biasanya
sebuah
relationship
dinamakan dengan
menggunakan
kata kerja, seperti
Mengatur, atau dengan
sebuah
frase singkat yang meliputi sebuah kata kerja, seperti DisewaOleh.
Sedangkan tanda panah ditempatkan di
samping
nama relationship
yang mengindikasikan arah bagi pembaca untuk
mengartikan nama
dari suatu relationship.
Huruf pertama
dari
setiap kata
pada
nama
relationship ditulis dengan huruf besar. Representasi diagram dari
suatu tipe relationship terlihat pada gambar 2.4.
Pegawai
Memiliki
Cabang
'
Cabang
memiliki pegawai '
Gambar 2.4
Representasi diagram dari tipe relationship
(Connolly, 2005, p347)
•
Derajat dari Tipe Relationship
Derajat
dari
tipe
relationship
adalah
jumlah
tipe
entitas
yang ikut serta dalam sebuah relationship (Connolly, 2005, p347).
|
 20
Complex
relationship
types
adalah sebuah
relationship
dengan
derajat
yang
lebih
dari
binary
(Connolly, 2005,
p348).
Sebuah relationship yang memiliki derajat dua dinamakan binary
(Connolly, 2005,
p348).
Gambar
2.4
juga
merepresentasikan
diagram relationship
derajat dua. Sedangkan sebuah relationship
derajat
tiga
dinamakan ternary,
dan
jika
sebuah
relationship
memiliki derajat empat dinamakan quarternary
(Connolly, 2005,
p348).
Lambang
belah
ketupat
merepresentasikan relationship
yang
memiliki derajat
lebih
dari
dua.
Nama
dari
relationship
tersebut ditampilkan di dalam lambang belah ketupat. Panah yang
biasanya terdapat
di
samping nama
suatu
relationship
dihilangkan. Representasi diagram derajat tiga dari suatu tipe
relationship terlihat pada gambar 2.5.
Pegawai
Mendaftarkan
Cabang
Klien
'Pegawai
mendaftarkan
seorang
klien
pada sebuah cabang'
Gambar 2.5
Representasi diagram derajat tiga dari suatu tipe relationship
(Connolly, 2005, p362)
|
 21
•
Recursive Relationship
Recursive
relationship
adalah sebuah
tipe
relationship
dimana tipe entitas
yang
sama
ikut serta
lebih
dari sekali
pada
peran yang berbeda (Connolly, 2005, p349).
Relationship
dapat
diberikan nama
peran
untuk
menentukan fungsi
dari
setiap
entitas
yang
terlibat
dalam
relationship
tersebut. Representasi diagram recursive relationship
beserta nama perannya terlihat pada gambar 2.6.
Nama
peran juga
dapat
digunakan jika
dua
buah
entitas
dihubungkan melalui
lebih
dari
satu
relationship.
Representasi
diagram nama peran yang digunakan pada dua buah entitas
terlihat pada gambar 2.7.
Nama peran
Mengawasi
Nama peran
Orang yang
diawasi
Pengawas
Pegawai
'Pegawai (Pengawas)
mengawasi pegawai (orang yang diawasi)'
Gambar 2.6
Representasi diagram recursive relationship dan nama peran
(Connolly, 2005, p349)
|
 22
Pegawai
Cabang
Memiliki
'Manajer mengatur
kantor cabang'
Nama peran
Manajer
Mengatur
Kantor
Cabang
Anggota
Pegawai
Kantor
Cabang
Nama peran
'Kantor
cabang memiliki
anggota
pegawai'
Gambar 2.7
Representasi diagram entitas dengan dua
relationship berbeda beserta nama peran (Connolly, 2005, p350)
C. Atribut
Atribut
adalah
properti sebuah
entitas
atau
relationship
(Connolly, 2005, p350).
Menurut Jeffery L. Whitten (2004,
p295),
atribut merupakan properti deskriptif atau
karakteristik dari
sebuah
entitas.
Atribut
menampung nilai
yang
menjelaskan
setiap
entity
occurrence
dan
menggambarkan bagian
utama
dari
data
yang
disimpan di dalam basis data.
Atribut
domain
adalah
sekumpulan nilai
yang
dibolehkan
bagi
satu
atau
lebih
atribut (Connolly,
2005, p350).
Atribut dapat
diklasifikasikan menjadi:
1)
Simple
attribute
adalah atribut yang
terdiri dari
komponen
tunggal dengan keberadaaannya yang bebas (Connolly, 2005,
p351).
|
|
23
2) Composit
attribute
adalah
atribut
yang terdiri dari
beberapa
komponen, dan
keberadaan setiap
komponen
tersebut
bebas
(Connolly, 2005, p351).
3)
Single-valued
attribute
adalah atribut yang
hanya
memiliki
sebuah nilai
untuk
setiap occurrence
dari
sebuah entitas
(Connolly, 2005, p351).
4)
Multi-valued
attribute
adalah
sebuah
atribut yang
memiliki
banyak nilai
untuk setiap occurrence dari sebuah tipe entitas
(Connolly, 2005, p352).
5) Derived attribute adalah
atribut
yang merepresentasikan
sebuah
nilai
yang diturunkan
dari
atribut
lain
yang
berhubungan atau kumpulan dari atribut (Connolly, 2005,
p352).
2.2.6.2 Keys
Candidate
key
adalah
himpunan atribut
yang
minimal
yang
secara
unik
mengidentifikasikan setiap
occurrence
dari
sebuah
tipe
entitas (Connolly, 2005, p352).
Composite
key
adalah
sebuah
candidate
key
yang
terdiri
atas
dua atau lebih atribut (Connolly, 2005, p353).
Primary
key
adalah
candidate
key
yang
terpilih untuk
mengidentifikasikan secara
unik
setiap
occurrence
dari
sebuah
tipe
entitas
(Connolly, 2005,
p353).
Pada
sebuah
tipe
entitas
biasanya
terdapat lebih dari satu candidate key yang salah satunya harus dipilih
|
 24
untuk
menjadi
primary
key.
Pemilihan
primary
key
didasarkan pada
panjang
atribut, jumlah
minimal atribut yang diperlukan, dan
keunikannya.
Alternate
key
adalah setiap
candidate
key
yang
tidak
terpilih
menjadi
primary
key,
atau
biasa disebut
dengan
secondary
key
(Whitten, 2004, p298).
Foreign key adalah
sebuah primary key pada
sebuah
entitas
yang digunakan pada entitas lainnya untuk mengidentifikasikan sebuah
relationship (Whitten, 2004, p301).
primary key
ruang untuk
menuliskan
atribut
Pegawai
noPeg {PK}
nama
jabatan
gaji
/totalPeg
Mengatur
Memiliki
derived
attribute
Cabang
noCab {PK}
alamat jalan
kota
kodepos
telp
[1..3]
composite
attribute
multi-valued
attribute
Gambar 2.8
Representasi diagram entitas Pegawai dan Cabang beserta
atribut dan primary keynya (Connolly, 2005, p354)
2.2.6.3 Batasan Struktural (Structural Constraints)
Batasan-batasan
yang
menggambarkan pembatasan
pada
relationship seperti yang ada pada ‘real world’
harus
diterapkan pada
tipe entitas yang ikut serta pada sebuah relationship. Jenis utama dari
|
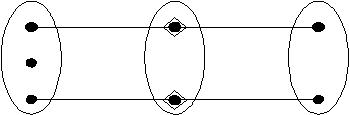 25
batasan pada suatu relationship dinamakan multiplicity (Connolly,
2005, p356).
Multiplicity adalah jumlah occurrence yang mungkin terjadi
pada
sebuah tipe
entitas
yang berhubungan ke
sebuah occurrence dari
tipe entitas lain pada suatu relationship (Connolly, 2005, p356).
Derajat
yang biasanya digunakan pada suatu relationship adalah
binary relationship, yang terdiri atas :
•
One-to-one (1:1) Relationship
Setiap
relationship
menggambarkan hubungan
antara
sebuah entity
occurrence
pada
entitas
yang
satu
dengan sebuah
entity
occurrence
pada
entitas
lainnya yang
ikut
serta
dalam
relationship tersebut.
Pegawai
tipe entiti
(noPeg)
SG5
Mengatur
tipe relationship
r1
Cabang tipe entiti
(noCab)
B003
SG37
SL21
r2
B005
Gambar 2.9 Semantic net menunjukkan dua occurrence dari
relationship Pegawai Mengatur Cabang (Connolly, 2005, p357)
|
 26
setiap cabang diatur
oleh satu orang pegawai
seorang pegawai dapat
mengatur nol atau satu cabang
Pegawai
noPeg
Mengatur
1..1
0..1
Cabang
noCab
Multiplicity
Gambar 2.10 Multiplicity dari relationship one-to-one (1:1)
(Connolly, 2005, p358)
•
One-to-many (1:*) Relationship
Setiap
relationship
menggambarkan hubungan
antara
sebuah entity occurrence pada entitas yang satu dengan satu atau
lebih entity occurrence pada entitas lainnya yang ikut serta dalam
relationship tersebut.
Pegawai
tipe entiti
(noPeg)
SG5
Melihat
tipe relationship
r1
RumahSewa tipe
entiti
(noRumah)
PG21
SG37
r2
PG36
PA14
SA9
r3
PG4
Gambar 2.11 Semantic net menunjukkan tiga occurrence dari
relationship Pegawai Melihat RumahSewa (Connolly, 2005, p358)
|
 27
setiap rumah sewa
dilihat
oleh
nol
atau satu pegawai
setiap pegawai
melihat nol
atau
lebih
rumah sewa
Pegawai
noPeg
Melihat
0..1
0..*
RumahSewa
noRumah
Gambar 2.12 Multiplicity dari relationship one-to-many (1:*)
(Connolly, 2005, p359)
•
Many-to-many (*:*) Relationship
Setiap
relationship
menggambarkan hubungan antara satu
atau
lebih
entity
occurrence
pada
entitas
yang
satu
dengan satu
atau
lebih
entity
occurrence
pada
entitas
lainnya
yang
ikut
serta
dalam relationship tersebut.
Koran tipe entiti
(namaKoran)
Glasgow Daily
The
News West
Aberdeen Express
Mengiklankan
tipe
relationship
r1
r2
r3
r4
RumahSewa tipe
entiti
(noRumah)
PG21
PG36
PA14
PG4
Gambar 2.13 Semantic net menunjukkan empat occurrence dari
relationship Koran Mengiklankan RumahSewa (Connolly, 2005, p360)
|
 28
setiap
rumah
sewa diiklankan
pada nol atau lebih
koran
setiap koran
mengiklankan satu
atau lebih rumah
sewa
Koran
namaKoran
Mengiklankan
0..*
1..*
RumahSewa
noRumah
Gambar 2.14 Multiplicity dari relationship many-to-many (*:*)
(Connolly, 2005, p360)
2.2.7 Cardinality dan Participation Constraints
Multiplicity sebenarnya terdiri atas dua constraint yang berbeda, yaitu:
A. Cardinality
Cardinality
adalah
nilai
maksimum dari
relationship
occurrence
yang
mungkin terjadi
untuk
sebuah
entitas
yang
ikut
serta
pada
suatu
relationship (Connolly, 2005, 363).
B. Participation
Participation menentukan apakah semua atau hanya beberapa entity
occurrence
yang
ikut
serta
dalam sebuah relationship
(Connolly,
2005,
363). Participation constraint dibagi menjadi :
•
Mandatory participation
Mandatory participation melibatkan semua entity occurrence
pada relationship tertentu (Connolly, 2005, p363).
•
Optional participation
Optional participation melibatkan beberapa entity occurrence
pada relationship
tertentu (Connolly, 2005,
p363).
Representasi
|
 29
diagram
terhadap multiplicity
sebagai
cardinality
dan
participation
constraints dapat dilihat pada gambar 2.15.
Cardinality
sebuah cabang
diatur
oleh
seorang pegawai
seorang
pegawai
mengatur satu cabang
Pegawai
noPeg
Mengatur
1..1
0..1
Cabang
noCab
'semua cabang diatur'
(mandatory participation
pada Cabang)
'tidak semua
pegawai
mengatur
cabang' (optional
participation
pada Pegawai)
Participation
Gambar 2.15
Multiplicity sebagai cardinality dan participation
constraints pada relationship one-to-one (1:1) Pegawai Mengatur
Cabang (Connolly, 2005, p363)
2.2.8 Specialization/Generalization
Konsep dasar dari pemodelan dengan ER Diagram sering kali tidak
cukup mendukung untuk merepresentasikan kebutuhan dari aplikasi yang lebih
baru,
dan
kompleks.
Hal
ini
menstimulasikan kebutuhan
untuk
memberikan
tambahan
konsep
permodelan yang
semantik.
Permodelan ER
yang
telah
mendukung
konsep
semantik biasa
kita
sebut
Enhanced
Entity-Relationship
(ERR)
Model.
Pada
ERR
model,
kita
mengenal konsep
Specialization/Generalization. Specialization.
|
|
30
Konsep
Specialization/Generalization
memberikan dukungan
akan
adanya Subclass/Superclass dan proses attribute inheritance Superclass adalah
tipe
entitas
yang
memiliki satu
atau
lebih
anggota
yang
perlu
ditampilkan
didalam
model data. Sedangkan
Subclass adalah anggota
dari sebuah tipe
entitas yang perlu direpresentasikan dalam model data (Connolly, 2005, p372).
2.2.9 Perancangan Basis Data (Database Design)
Perancangan basis
data
(database
design)
adalah
proses
pembuatan
sebuah rancangan untuk basis
data
yang akan
mendukung operasi dan tujuan
perusahaan
yang
dibutuhkan
oleh
sistem
basis
data(Connolly, 2005,
p291).
Dalam
perancangannya diperlukan
metodologi
yang
benar
sehingga
perancangan dapat
berjalan
sesuai
dengan
konsep
yang
ada.
Metodologi
perancangan
(design
methodology)
adalah
pendekatan terstruktur
yang
menggunakan
prosedur-prosedur,
teknik-teknik, peralatan,
dan
dokumentasi
untuk
mendukung
dan
memudahkan proses
perancangan
(Connolly,
2005,
p438).
Teknik
ini
digunakan
untuk
membantu
merencanakan, mengatur,
mengontrol,
dan
mengevaluasi
proyek
pengembangan basis
data.
Tahapan
dalam metodologi perancangan ada tiga, yaitu :
2.2.9.1 Perancangan Basis Data Konseptual ( Conceptual Database Design)
Conceptual database
design
adalah proses
membangun
model
informasi yang digunakan organisasi, bebas dari semua
pertimbangan
fisik
(Connolly, 2005,
p439). Pertimbangan fisik
yang
dimaksud
meliputi
DBMS
yang
akan
digunakan,
program
aplikasi,
bahasa
|
|
31
pemrograman, platform perangkat keras, unjuk kerja, dan pertimbangan
fisik
lainnya. Langkah-langkah dalam
metodologi conceptual database
design yaitu :
Langkah 1 - Membangun Local Conceptual Data Model untuk
setiap pandangan pengguna
Bertujuan
untuk memecah
rancangan
menjadi tugas-tugas yang
dapat
diatur
dengan
memeriksa sudut
pandang
yang
berbeda
dari
pengguna di
dalam
organisasi (Connolly,
2005,
p442).
Hasil
dari
langkah
ini
berupa pembuatan satu
atau
lebih
local
conceptual
data
model yang
merupakan
penggambaran
yang
tepat
dan
lengkap
dari
suatu organisasi dilihat dari para pengguna yang berbeda.
Tugas-tugas
yang dilakukan pada langkah ini terdiri dari :
Langkah 1.1 Mengidentifikasi tipe entitas
Tipe entitas dapat
dikenali
dengan
mengidentifikasikan
kata
benda
atau
frase
kata
benda
pada
spesifikasi kebutuhan
pengguna, objek
besar
seperti
orang (people),
tempat
(place),
benda
(thing)
atau
konsep
(concept).
Alternatif lain
adalah
dengan mencari obyek yang keberadaannya bebas.
Langkah 1.2 Mengidentifikasi Relationship Type
Bertujuan
untuk
mengidentifikasi relationship
yang
penting
yang
ada
antara
tipe
entitas-tipe entitas
yang
telah
diidentifikasi
sebelumnya.
Tipe relationship diidentifikasikan
|
|
32
dengan
mencari
kata kerja atau
suatu
kata
yang
berhubungan
dengan kata kerja.
Langkah 1.3 Mengidentifikasi dan menghubungkan atribut
dengan entitas dan relationship
Tujuannya untuk
menghubungkan atribut dengan entitas
dan tipe relationship yang tepat. Atribut yang dimiliki
oleh
setiap
entitas
dan
relationship
harus
memenuhi karakteristik
atribut yaitu
simple/composite
attribute,
single/multi-valued
attribute, dan derived attribute.
Langkah 1.4 Menentukan domain atribut
Domain adalah sekumpulan nilai dimana satu atau
lebih
atribut
memperoleh nilainya
(Connolly,
2005,
p450).
Contoh
menentukan
domain
pada
atribut
JenisKelamin di
entitas
Mahasiswa adalah dengan ‘L’ atau ’P’.
Langkah 1.5 Menentukan atribut Candidate Key, Primary
Key dan Alternate Key
Tujuannya
untuk
mengidentifikasi
candidate key
setiap
tipe entitas, dan jika terdapat lebih dari satu candidate key maka
terpilih satu sebagai primary key dan sisanya dapat kita jadikan
sebagai alternate key.
|
|
33
Langkah 1.6
Pertimbangkan
penggunaan
enhance
modelling concepts (langkah pilihan)
Maksud
dari
langkah
ini adalah
untuk
menentukan
specialization, generalization, aggregation, composition.
Specialization
merupakan suatu proses
memaksimalkan
perbedaan-perbedaan antara
anggota-anggota
sebuah
entitas
dengan
cara
mengidentifikasi karakteristik
yang
membedakan
entitas tersebut (Connolly, 2005, p374).
Generalization
merupakan suatu
proses
meminimalkan
perbedaan-perbedaan antara
entitas-entitas
dengan
cara
mengidentifikasi sifat umum entitas (Connolly, 2005, p375).
Aggregation
menggambarkan
relationship ‘has-a’
atau
‘is-part-of’
antara tipe
entitas dimana
yang
satunya
mewakili
‘whole’ (seluruhnya)
dan yang satunya lagi mewakili ‘part’
(bagian) (Connolly, 2005, p383).
Langkah 1.7 Memeriksa redudansi
Bertujuan
memeriksa conceptual
model
untuk
menghindari adanya
redundansi
atau
pengulangan data
dalam
model. Ada dua kegiatan yang dapat dilakukan pada tahap ini:
1)
Memeriksa kembali one-to-one relationship (1:1)
Kemungkinan
ada dua entitas
yang
menggambarkan objek
yang
sama
dalam organisasi. Oleh
karena itu, kedua entitas tersebut harus digabungkan.
|
|
34
2)
Menghilangkan relasi yang redundan
Suatu relationship menjadi redundan jika informasi
yang sama dihasilkan melalui
relationship
yang
lainnya.
Untuk
meminimalkan data model maka relationship
yang
redundan harus dihilangkan.
Langkah 1.8 Memvalidasi conceptual model dengan transaksi
Bertujuan untuk memastikan local conceptual data model
mendukung transaksi yang dibutuhkan oleh pandangan pengguna
(Connolly, 2005, p456). Dua pendekatan untuk memastikan local
conceptual data model mendukung kebutuhan transaksi :
1)
Menggambarkan transaksi (describing the transaction)
Memeriksa semua
informasi
(entitas,
relationship,
dan
atributnya) yang
dibutuhkan
setiap
transaksi
yang
disediakan oleh model (Connolly, 2005, p456).
2)
Menggunakan transaction pathways
Memvalidasi data
model
terhadap
kebutuhan
transaksi
dengan
menggambar diagram
yang
mewakili
pathway yang diambil oleh setiap transaksi secara
langsung pada E-R diagram (Connolly, 2005, p457).
|
|
35
Langkah 1.9 Melihat kembali conceptual data model dengan
pengguna
Langkah
ini
dilakukan dengan
tujuan
untuk
memastikan
bahwa data model merupakan representasi yang benar bagi setiap
pandangan.
2.2.9.2 Perancangan Basis Data Logikal (Logical Database Design)
Desain
basis
data
logikal
adalah
proses
membangun model
informasi
yang digunakan organisasi berdasarkan model data
tertentu,
tetapi tidak tergantung dari Database Management System (DBMS) dan
pertimbangan fisik
lainnya
(Connolly,
2005,
p439).
Langkah-langkah
dalam metodologi logical database design yaitu:
Langkah 2 Membangun dan validasi logical data model
Tujuannya
untuk
membangun sebuah
logical
data
model
dari
sebuah conceptual
data
model
yang
mewakili pandangan tertentu dari
organisasi
dan
kemudian
memvalidasi model
ini
untuk
memastikan
bahwa strukturnya benar (dengan menggunakan teknik normalisasi) dan
untuk
memastikan
dukungannya
terhadap
transaksi-transaksi yang
dibutuhkan. Kegiatan yang dilakukan pada langkah ini meliputi :
Langkah 2.1 Membuat relasi untuk logical data model
Bertujuan
untuk
menyaring conceptual
data
model
sehingga
fitur-fitur yang
tidak
sesuai
dengan
model
relasional
dihilangkan. Langkah-langkahnya antara lain :
|
|
36
1)
Menentukan tipe entitas kuat
Untuk semua entitas
dengan jenis
kuat,
buatlah sebuah
entitas
yang
memiliki semua
atribut
yang
dimilikinya.
Untuk
Composit
attribute,
hanya
sertakan atribut
pokoknya saja.
2)
Menentukan tipe entitas lemah
Untuk setiap entitas
lemah, buatlah sebuah entitas
yang
termasuk semua atribut yang dimilikinya. Namun begitu,
Primary Key dari entitas
ini belum bisa ditentukan
sampai relasinya dengan entitas kuat dibuat.
3)
Membuat One-to-many (1:*) Relationship
Pada relasi jenis ini, entitas pada ‘sisi
satu’ kita anggap
sebagai
entitas
induk
sedangkan
entitas
pada ‘sisi
banyak’
dianggap sebagai
entitas
anak.
Untuk
merepresentasikan hubungan
ini,
kita
kirimkan
Primary
Key dari
entitas induk sebagai Foreign Key pada entitas
anak
4)
Membuat one-to-one (1:1) binary Relationship
Relasi
1:1
lebih
sulit
ditentukan
hubungannya. Hal
ini
disebabkan karena Cardinality dan Participation
|
|
37
Constraints
juga
akan
menentukan dalam
mengidentifikasi entitas
induk dan anak dalam relasi
ini.
a)
Mandatory Participation pada kedua sisi
Pada
kasus
ini,
maka kita
harus
menggabungkan
kedua
entitas
yang
memiliki relasi
jenis
ini
dan
memilih salah satu dari kedua Primary
Key sebagai
Primary Key yang baru
b)
Mandatory Participation pada satu sisi
Pada kasus
ini, kita bisa
mengidentifikasikan entitas
yang berada pada sisi Optional Participation sebagai
entitas
induk,
sedangkan yang
berada
pada
sisi
Mandatory
Participation
sebagai entitas
anak.
Seperti
pada
langkah
sebelumnya, kita
kirimkan
Primary Key dari entitas
induk sebagai Foreign Key
pada entitas anak.
c)
Optional Participation pada kedua sisi
Pada
kasus
ini,
pemilihan induk
dan
anak
bisa
berubah-ubah. Untuk
bisa
menentukan,
maka
kita
harus mencari sisi Optional Participation mana yang
lebih
mendekati sebagai
Mandatory
Participation.
Atau
dengan
kata
lain, pemecahan untuk
relasi
ini
sangat tergantung dengan kondisi data.
|
 38
5)
Membuat one-to-one (1:1) recursive Relationship
Untuk pemecahan hubungan ini, kita bisa menggunakan
cara yang sama dengan yang kita terapkan dengan yang
kita gunakan pada 1:1 relationship.
6)
Memecah Superclass/subclass relationship
Untuk
setiap Superclass/subclass
relationship
kita
mengidentifikasikan superclass
sebagai
entitas
induk
sedangkan subclass
sebagai
entitas
anak.
Cara
kita
merepresentasikan data
ini
sangatlah
tergantung dengan
Disjoint constraint dan Participation constraint dari
Superclass/subclass relationship.
Participation constraint
Disjoint constraint
Pemecahan
Mandatory
Nondisjoint {And}
Gabungkan entitas
induk
dan
semua
entitas
anak
kedalam sebuah entitas
Optional
Nondisjoint {And}
Gabungkan
semua entitas
anak kedalam satu entitas,
sedangkan entitas
induk
tetap terpisah
Mandatory
Disjoint {Or}
Gabungkan entitas
induk
kedalam
masing-masing
entitas anak.
Optional
Disjoint {Or}
Setiap entitas tetap berdiri
sendiri
Tabel 2.2 Pemecahan Superclass/subclass relationship(Connolly, 2005, p468)
|
|
39
7)
Menghilangkan
many-to-many
(*:*)
binary
relationship types
Dengan memecah relationship yang mengandung
many-to-many
(*:*)
untuk
mengidentifikasikan sebuah
entitas tengah (intermediate entity) sehingga relationship
ini
digantikan dengan
dua
buah
one-to-many
(1:*)
relationship, dengan entitas
tengah berada di antara dua
buah entitas yang lama.
8)
Menghilangkan complex relationship types
Dihilangkan dengan
memecah
relationship
ini
untuk
mengidentifikasikan
entitas
tengah
(intermediate
entity).
Kemudian complex
relationship
ini
akan
digantikan dengan
beberapa
one-to-many
(1:*)
binary
relationship.
9)
Menghilangkan multi-valued attributes
Cara menghilangkannya dengan memecah atribut
ini untuk mengidentifikasikan sebuah entitas. Setelah itu,
kirimkan
Primary Key pada entitas
induk
sebagai
Foreign Key pada entitas anak.
|
|
40
Langkah 2.2
Validasi
relasi
dengan
menggunakan
normalisasi
Normalisasi adalah
suatu
teknik
untuk
menghasilkan
himpunan
relasi dengan
properti
yang diinginkan berdasarkan
kebutuhan-kebutuhan data
suatu
organisasi
(Connolly,
2005,
p388).
Proses
normalisasi
dimulai
dengan
memindahkan data
sumber ke bentuk tabel dengan
format baris
dan kolom. Tabel
ini
berbentuk tidak
normal
dan
disebut
dengan
unnormalized
table (Connolly, 2005, p403).
Unnormalized
form (UNF)
adalah suatu
tabel
yang
terdiri dari satu atau lebih kelompok yang berulang (repeating
group) (Connolly, 2005, p403). Repeating group adalah sebuah
atribut atau himpunan atribut di dalam tabel yang memiliki lebih
dari
satu nilai
(multiple value)
untuk sebuah primary key pada
tabel tersebut (Connolly, 2005, p403).
Tingkatan
normalisasi yang digunakan
sebagai landasan
penulisan skripsi ada tiga tahap yaitu :
1)
First Normal Form (1NF)
Suatu relasi dikatakan 1NF
jika titik
temu tiap
baris dan kolom pada relasi tersebut mengandung satu
dan hanya satu nilai (Connolly, 2005, p403).
Sebuah
relasi akan berada dalam bentuk 1NF
jika repeating groupnya sudah hilang. Ada dua
|
|
41
Langkah 2.2
Validasi
relasi
dengan
menggunakan
pada tabel yang tidak normal, yaitu:
•
Dengan
memasukkan
data
yang
sesuai
ke
dalam kolom yang
kosong
dari
baris
yang
mengandung data berulang.
•
Dengan menempatkan data yang berulang
bersama salinan
atribut kunci pada
relasi
yang
terpisah.
Sebuah primary key diidentifikasikan
ke dalam relasi yang baru.
2)
Second Normal Form (2NF)
Relasi
dikatakan 2NF
jika
relasi
tersebut
berada pada
1NF
dan
setiap
atribut yang
bukan
primary
key
bergantung penuh
(fully
functionally
dependent)
terhadap
primary
key
(Connoly, 2002,
p407).
Full functional dependency terjadi jika A dan
B merupakan
atribut dari suatu relasi, dan B
dikatakan bergantung penuh terhadap A (A?B), jika
B
bergantung terhadap
A,
namun
bukan
subset dari
A (Connolly, 2005, p393).
Untuk menghasilkan
relasi
dalam
bentuk
2NF
melibatkan
penghilangan
ketergantungan
sebagian (partial dependency) dan menempatkannya
|
|
42
pada relasi yang baru bersama salinan atribut
penentunya (determinant attribute).
3)
Third Normal Form (3NF)
Suatu
relasi
dikatakan 3NF
jika
relasi
tersebut berada dalam bentuk 1NF dan 2NF, dan
tidak ada
atribut bukan primary key bergantung
secara
transitif (transitively
dependent)
terhadap
primary key (Connolly, 2005, p409).
Transitive
dependency
ialah
sebuah kondisi
dimana
A,
B,
dan
C
merupakan atribut
dari relasi
yang
jika
A?B
dan
B?C
maka C
disebut
bergantung secara
transitif
(transitively
dependent)
terhadap A
melalui
B
(A
tidak
functionally
dependent
terhadap B atau C) (Connolly, 2005,
p397).
Langkah 2.3
Validasi relasi terhadap transaksi pengguna
Bertujuan
untuk
memastikan bahwa
relasi-relasi pada
local
logical
data
model
mendukung
transaksi-transaksi yang
dibutuhkan oleh
pengguna,
seperti
terinci
pada
spesifikasi
kebutuhan pengguna.
|
|
43
Langkah 2.4 Menentukan integrity constraint
Integrity
constraint
adalah
batasan-batasan yang
harus
ditentukan
untuk
melindungi basis
data
agar
tetap
konsisten
(Connolly,
2005, p474). Ada lima jenis integrity constraint,
yaitu :
1)
Required data
Beberapa atribut
harus
selalu
berisi
nilai
yang
benar
(valid),
tidak dapat
bernilai
null.
Constraint ini
harus
diidentifikasikan
pada saat
mendokumentasikan
atribut-atribut pada kamus data (langkah 1.3).
2)
Attribute domain constraint
Setiap
atribut
memiliki domain,
yaitu
himpunan
nilai
yang
dibolehkan
(Connolly, 2005,
p475). Constraint ini
harus diidentifikasikan pada saat
pemilihan attribute domain untuk data model (langkah
1.4).
3)
Multiplicity
Multiplicity merepresentasikan batasan jumlah yang
ada antar data yang ada di basis data.
4)
Entity integrity
Primary
key
dari
sebuah entitas tidak
boleh
bernilai null. Constraint
ini harus dipertimbangkan
|
|
44
pada saat penentuan primary key bagi setiap
tipe
entitas (langkah 1.5).
5)
Referential integrity
Jika suatu foreign key memiliki nilai, maka
nilai tersebut harus menunjuk ke sebuah baris yang ada
pada relasi ‘parent’.
6)
General constraint
Kegiatan update entitas dibatasi oleh peraturan
atau kebijakan organisasi
yang
mengatur transaksi
yang diwakilkan oleh update yang dilakukan.
Langkah 2.5 Meninjau kembali local logical data model
yang dibuat dengan pengguna
Tujuan yang
ingin
dicapai adalah
untuk
memastikan
bahwa
local
logical
data
model
dan
dokumentasi pendukung
yang menggambarkan
model merupakan perwakilan yang benar
dari pandangan pengguna.
Langkah
2.6 Menggabungkan
model
data
logikal
menjadi
sebuah model data global (langkah pilihan)
Langkah
ini
hanya
perlu
dilakukan apabila
saat
desain
dilakukan
dengan pandangan
masing-masing
user. Model data
logikal
adalah
cara
pandang
satu
atau
beberapa pengguna
terhadap basis
data.
Sedangkan
model
data
global
|
|
45
menggambarkan pandangan semua pengguna terhadap basis
data.
Langkah
2.7
Memeriksa
untuk
mengantisipasi
perkembangan
Langkah
ini
kita
lakukan
untuk
memeriksa akan adanya
perubahan siknifikan dalam waktu dekat dan memeriksa apakah
model
data
logikal yang
kita
buat
bisa
mengakomodasi
perubahan itu.
2.2.9.3 Perancangan Basis Data Fisikal (Physical Database Design)
Perancangan basis data fisikal (physical database design) adalah
proses
untuk
menghasilkan penjelasan dari
pengimplementasian
suatu
basis
data
pada
media
penyimpanan kedua,
juga
menjelaskan base
relation, pengaturan
file, dan
indeks
yang
digunakan
untuk
mencapai
akses
data
yang
efisien, integrity
constraint,
serta
ukuran keamanan
(Connolly, 2005, p294).
Langkah-langkah metodologi perancangan
basis data fisikal terdiri dari:
Langkah 3 Menterjemahkan logical data model untuk target
DBMS
Bertujuan
untuk
menghasilkan skema basis data relasional bagi
global
logical
data
model
yang
dapat
diimplementasikan
pada
target
DBMS.
|
|
46
Langkah 3.1 Membuat base relations
Untuk
setiap
relasi
yang
diidentifikasikan pada
global
logical
data
model,
definisinya
terdiri
dari
nama
relasi,
daftar
simple
attribute
diikuti tanda
kurung,
primary
key
berserta
alternate key dan foreign key jika ada, dan referential integrity
constraint bagi foreign key yang teridentifikasi.
Definisi setiap
atribut
pada
kamus
data
terdiri
dari
domainnya
yang
terdiri
atas
tipe
data,
panjang data,
setiap
constraint pada
domain, nilai
defaultnya
jika
ada,
dan
keterangan apakah atribut dapat memiliki nilai null.
Langkah 3.2 Membuat representasi dari derived data
Bertujuan
untuk
menentukan cara
untuk
merepresentasikan derived data
yang ada
dalam
global
logical
data model ke dalam target DBMS.
Biasanya derived attribute tidak terlihat pada logical
data
model
namun
didokumentasikan di
dalam
kamus
data.
Untuk
setiap derived
attribute
yang
ada,
tanda ‘/’
digunakan
untuk menandakan atribut tersebut adalah derived attribute.
Langkah 3.3 Merancang general constraints
Bertujuan
untuk
merancang
batasan-batasan organisasi
untuk
target DBMS. Update terhadap
relasi
dibatasi
oleh
|
|
47
peraturan organisasi yang mengatur transaksi ‘real world’ yang
diwakili oleh update tersebut.
Langkah 4 Merancang organisasi file dan indeks
Bertujuan
untuk
menentukan organisasi
file
yang
optimal
untuk
menyimpan base
relation
dan
indeks
yang
diperlukan untuk
mencapai
unjuk kerja
yang sesuai, dengan
cara
penentuan
penyimpanan
relasi dan
baris-baris
pada
tempat penyimpanan kedua.
Langkah 4.1 Menganalisis transaksi
Bertujuan untuk
memahami fungsi
dari
transaksi
yang
dijalankan pada
basis
data
dan
menganalisis transaksi-transaksi
yang penting. Dalam menganalisis transaksi, kriteria unjuk kerja
yang harus diidentifikasi seperti:
•
Transaksi
yang sering digunakan dan
yang
memiliki
dampak yang signifikan pada unjuk kerja
•
Transaksi yang penting bagi kegiatan operasional bisnis
•
Peak load, yaitu
saat-saat pada
hari
atau
minggu
dimana
akan
ada
permintaan yang
tinggi
terhadap
basis
data
(Connolly, 2005, p502)
|
|
48
Langkah 4.2 Memilih organisasi file
Untuk menentukan
organisasi file yang efisien untuk
setiap base relation.
Langkah 4.3 Memilih indeks
Untuk
menentukan apakah penambahan indeks akan
meningkatkan unjuk kerja sistem. Ada tiga jenis indeks yaitu:
•
Primary index
Pengindeksan dilakukan pada kolom kunci (key field),
yang
diurutkan terlebih
dahulu
secara
sekuensial
(Connolly, 2005, p1277).
•
Clustering index
Pengindeksan dilakukan pada kolom bukan kunci (non-key
field),
yang
sudah
diurutkan terlebih
dahulu
secara
sekuensial. Kolom
bukan
kunci
itu
disebut
juga
dengan
clustering attribute (Connolly, 2005, p1277).
•
Secondary index
Pengindeksan yang
dilakukan
pada
kolom
yang
tidak
terurut di dalam file data (Connolly, 2005, p1277).
Langkah 4.4 Memperkirakan
kebutuhan
ruang
penyimpanan
|
|
49
Memperkirakan besarnya
ruang
penyimpanan
yang
dibutuhkan
untuk
mendukung
implementasi basis
data
pada
tempat penyimpanan kedua. Hal ini sangat tergantung pada
target
DBMS
dan
perangkat
keras
yang
digunakan. Perkiraan
ukuran dapat dilakukan dengan mengukur besar data
tiap baris
dan jumlah baris pada setiap relasi.
Langkah 5 Merancang pandangan pengguna (user views)
Bertujuan
untuk
merancang
pandangan pengguna
yang
diidentifikasikan
selama tahap pengumpulan kebutuhan dan analisa
pada
daur
hidup
aplikasi
basis
data
relasional (database
application
lifecycle).
Langkah 6 Merancang mekanisme keamanan
Bertujuan
untuk
menentukan bagaimana
kebutuhan
keamanan
akan direalisasikan. Keamanan bagi basis data sangat diperlukan karena
basis data merupakan sumber daya perusahaan yang penting. Dua tipe
keamanan basis data (Connolly, 2005, p516), yaitu:
•
Keamanan
sistem
Memberikan perlindungan terhadap
akses
dan
penggunaan basis data pada tingkat sistem, seperti user
name dan password.
|
|
50
•
Keamanan data
Memberikan perlindungan akses
dan
penggunaan
objek
basis
data, seperti relasi dan view
dan
aksi
terhadap
objek yang dapat dimiliki oleh pemakai.
2.2.10 Pemilihan DBMS (Database Management System)
DBMS (Database Management System) adalah perangkat lunak khusus
yang digunakan untuk membuat, mengakses, mengontrol, dan mengatur sebuah
basis data (Whitten, 2004, p760).
Karena
suatu
organisasi
memerlukan perluasan
atau
perubahan
pada
sistem yang
sedang
berjalan, maka
akan
menjadi
hal
yang
perlu
untuk
mengevaluasi produk-produk
DBMS
yang
baru.
Tujuannya
untuk
memilih
sebuah sistem
yang
sesuai
dengan
kebutuhan perusahaan
saat
ini
maupun
di
masa yang akan datang,
yang seimbang dengan biaya-biaya yang dikeluarkan
termasuk dalam pembelian produk
DBMS, perangkat lunak maupun perangkat
keras
tambahan
yang
dibutuhkan untuk
mendukung
sistem
basis
data,
dan
biaya-biaya lain
yang
berhubungan dengan perubahan dan
pelatihan pegawai.
Tahapan utama dalam memilih DBMS antara lain :
1) Mendefinisikan syarat-syarat sebagai referensi
Dibuat
dengan
menyatakan tujuan
dan
ruang
lingkup
pembelajaran,
tugas-tugas
yang
akan
dikerjakan,
penjelasan kriteria
(berdasarkan spesifikasi
kebutuhan
pengguna)
yang
akan digunakan
dalam mengevaluasi produk-produk DBMS, daftar produk-produk
|
|
51
yang
dimungkinkan,
semua batasan-batasan
dan
skala
waktu
yang
dibutuhkan untuk pembelajaran.
2) Daftar singkat dua atau tiga produk
Kriteria
yang
dianggap penting
dalam
keberhasilan
implementasi dapat
digunakan
untuk membuat daftar produk-produk
DBMS dalam evaluasi, seperti dana
yang
tersedia, tingkat dukungan
vendor,
kecocokan dengan
perangkat
lunak
lainnya,
dan
apakah
produk hanya berjalan pada perangkat keras tertentu.
3) Evaluasi produk
Fitur-fitur yang
digunakan dalam
evaluasi
produk-produk
DBMS
dikelompokkan menjadi
definisi
data,
definisi
fisik,
kemampuan akses, penanganan keperluan-keperluan, pengembangan,
dan fitur-fitur lainnya.
4) Merekomendasikan pilihan dan memproduksi laporan
Langkah
terakhir
dari
pemilihan DBMS
adalah
mendokumentasikan prosesnya
dan
membuat
pernyataan
dalam
penemuan dan rekomendasi atas produk DBMS tertentu.
2.3 Teori Data Flow Diagram
2.3.1
Pengertian Data Flows
“Data flow represents an input of data to a process or the output of data
(or information) from a process.” (Whitten,2004,hal 357) yang artinya adalah
Data
flow
merepresentasikan masukan
dari
data
menuju
proses
atau
output
dari
data
(atau
informasi)
dari
sebuah
proses. Proses merespon
masukan
|
|
52
(input) dan menghasilkan keluaran (output) , satu proses minimal mempunyai
satu masukan dan satu keluaran.
2.3.2
Pengertian Data Flow Diagram
“A data flow diagram (DFD)
is a graphical representation that depicts
information flow and the transforms that are applied as data move from input
to output.” (Pressman,2005,hal 305)
yang artinya adalah data flow diagram
adalah
representasi
grafis
yang
menggambarkan
aliran
informasi
dan
transformasi yang terjadi saat data bergerak dari masukan menjadi keluaran.
Diagram aliran data mempunyai kegunaan untuk memperhatikan :
-
Informasi yang masuk dan keluar dari system
-
Apa yang merubah informasi
-
Dimana informasi disimpan
2.3.3
Merancang Data Flow Diagram
Dalam
diagram aliran
data
terdapat
levelisasi
yang
bertujuan
untuk
menghindari aliran data yang rumit dan kompleks. Levelisasi dimulai dengan
tingkatan tertinggi dan kemudian diuraikan ke dalam bentuk yang lebih rinci.
Tingkatan tersebut terdiri dari :
1.
Diagram konteks (Context Diagram)
Memperlihatkan karakteristik suatu sistem.
2. Diagram nol
Menggambarkan proses-proses utama yang ada pada suatu sistem.
3. Diagram rinci
|
 53
Merupakan proses rinci dari proses yang terdapat dari tingkatan
sebelumnya.
Simbol-simbol yang digunakan untuk menggambarkan diagram aliran
data yaitu :
De Marco dan Yourdon
Gane dan Sarson
Process
Data Store
Source / Sink
Data Flow
Tabel 2.3 Perbandingan simbol diagram aliran data berdasarkan De Marco dan
Yourdon dengan Gane dan Sarson
Terdapat beberapa peraturan yang harus diikuti saat menggambar diagram
aliran data (Jeffrey A. Hoffer ,2000,p286)
Process :
-
Tidak ada proses yang hanya mempunyai output. Jika sebuah objek
hanya mempunyai output maka itu adalah source.
|
|
54
-
Tidak ada proses yang hanya mempunyai input. Jika sebuah objek
hanya mempunyai input maka itu adalah sink.
-
Sebuah proses harus dilabeli dengan sebuah kata kerja.
Data Store :
-
Data tidak dapat bergerak dari sebuah data store menuju data store
lainnya. Data dapat bergerak melalui proses.
-
Data tidak dapat bergerak secara langsung dari source menuju data
store. Data harus bergerak melalui proses dimana data diterima dari
data source dan menempatkan data ke data store.
-
Data tidak dapat bergerak langsung menuju sink dari data store. Data
harus bergerak melalui proses.
-
Sebuah data store harus dilabeli dengan kata benda.
Source / Sink :
-
Data tidak dapat bergerak secara langsung dari source menuju sink.
Data harus melalui proses.
-
Sebuah source/sink harus dilabeli dengan kata benda.
Data Flow :
-
Sebuah data flow hanya mempunyai satu arah diantara simbol.
-
Sebuah cabang pada data flow berarti beberapa data yang sama menuju
dua atau lebih proses yang berbeda.
|
|
55
-
Sebuah penggabungan pada data flow berarti data yang sama muncul
dari dua atau lebih proses menuju sebuah lokasi yang sama.
-
Sebuah data flow tidak boleh menuju proses yang sama dengan sumber
prosesnya (rekursif). Harus ada minimal satu proses yang menangani
data flow, menghasilkan data flow, dan mengembalikan data flow
menuju proses awal.
-
Sebuah data flow menuju data store berarti memperbarui (update atau
delete) data.
-
Sebuah data flow dari data store berarti mengambil atau menggunakan
data.
-
Sebuah data flow mempunyai label berupa kata kerja. Bisa lebih dari
satu kata kerja yang muncul pada sebuah panah data flow dengan syarat
semua aliran / flows pada satu panah bergerak sebagai satu paket.
|