|
BAB 2
LANDASAN TEORI
2.1 Teori Umum
2.1.1 Definisi Database
Menurut Date (1990, p 10), database adalah suatu kumpulan dari data yang
bersifat persistent (yaitu data yang berbeda satu dengan yang lainnya) sementara dan
digunakan oleh sistem-sistem aplikasi pada suatu organisasi perusahaan.
Sedangkan menurut McLeod (2001, p 258) database adalah suatu kumpulan
data komputer yang terintegrasi, diorganisasikan, dan disimpan dengan suatu cara
yang memudahkan untuk proses retrieval (pengambilan data kembali).
Menurut
O’Brien
(1997,
p
166),
database
merupakan suatu koleksi yang
terintegrasi dimana secara logika berhubungan dengan record dari file.
Sedangkan menurut Connolly (2005, p 15), database adalah sekumpulan data
yang
saling berhubungan dan penjelasan atas data tersebut dirancang untuk
mempertemukan
atau
menghasilkan
informasi
yang
diperlukan
dalam suatu
organisasi.
Dari teori-teori diatas dapat disimpulkan bahwa sistem basis data (database)
adalah
sekelompok
elemen
data,
saling
terintegrasi,
dan
berhubungan
untuk
mencapai tujuan organisasi perusahaan.
8
|
|
|
|
9
2.1.2 DBMS (Database Management System)
Menurut Menurut Connolly (2005, p 16) “DBMS adalah suatu sistem
software
yang
memungkinkan user
dapat
mengidentifikasikan,
membuat,
memelihara, dan mengatur akses dari database”.
Keuntungan DBMS:
1. Mengontrol data berulang
2. Konsistensi data
3. Lebih banyak informasi yang didapat dari jumlah data yang sama
4. Adanya pembagian data
5. Meningkatkan integritas data
6. Meningkatkan keamanan
7. Mengembangkan backup dan layanan perbaikan
8. Meningkatkan pemeliharaan melalui data independen
Kerugian DBMS:
1. Kompleksitas
2. Ukuran
3. Biaya DBMS, hardware tambahan, konversi
4. Performa
5. Tingkat kegagalan yang lebih tinggi
|
 10
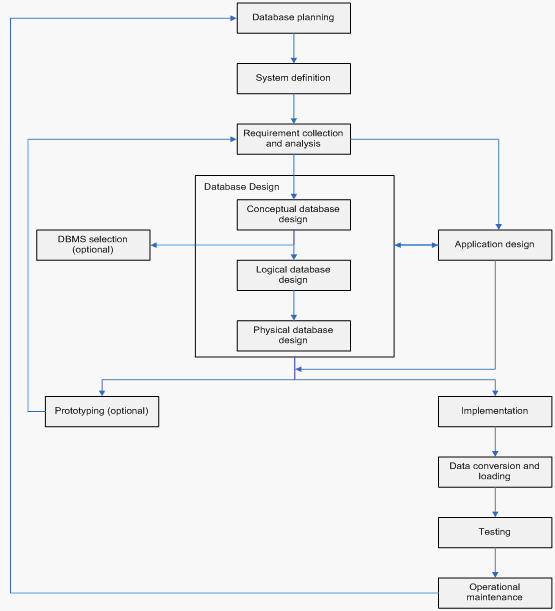
2.1.3 Siklus hidup Database
Menurut
Connolly
(2005,
p
284)
dalam perancangan
database
perlu
diperhatikan tentang siklus hidup dari database. Siklus hidup tersebut adalah (lihat
gambar 2.1) :
Gambar 2.1 The database system development lifecycle
|
|
11
Berikut
adalah
ringkasan
dari
aktivitas
utama
di setiap
langkah
dari
siklus
hidup database di atas:
1. Database Planning
Merencanakan
bagaimana
tahapan
dari
siklus
hidup
bisa
direalisasikan
secara
efektif dan efisien.
2. System Definition
Menspesifikasikan ruang lingkup dan batasan dari aplikasi database, pengguna,
dan cakupan aplikasi yang digunakan.
3. Requirement Collection and Analysis
Mengumpulkan dan menganalisis permintaan pengguna dan ruang lingkupnya.
4. Database Design
Perancangan database secara konseptual, logikal, dan fisikal.
5. DBMS Selection
Penyeleksian DBMS.
6. Database Application Design
Mendesain tampilan untuk pengguna dan program aplikasi yang akan digunakan.
7. Prototyping
Membangun
sistem
model
kerja
dari
aplikasi,
yang
digunakan
untuk
memvisualisasikan dan mengevaluasi sistem aplikasi keseluruhan.
8. Implementation
Mengimplementasikan sistem aplikasi dan sistem database.
9. Data Conversion and Loading
Konversi dan pemindahan data dari sistem lama ke sistem database yang baru.
|
|
12
10. Testing
Pengujian dan validasi sistem.
11. Operational Maintenance
Proses pemeliharaan dari sistem.
2.1.4 Definisi Data Warehouse
Menurut W.H Inmon (2002, p 31), “Data warehouse is a subject-oriented,
integrated, time-variant and non-volatile collection of data in support of
management’s decision-making process”, dimana data warehouse adalah kumpulan
data yang mendukung pengambilan keputusan
manajemen yang berkarakteristik
subject-oriented, integrated, non-volatile dan time-variant. Data warehouse
digunakan sebagai dasar dari sistem penunjang keputusan yang dikembangkan untuk
menyelesaikan
beberapa
masalah
yang
muncul pada sebuah organisasi dengan
menggunakan basis data yang sama
dimana dijalankan melalui OLTP (Online
Transaction Processing).
Menurut Connolly (2005, p 1151), “A subject-oriented, integrated, time-
variat, and
non-volatile
collection
of
data
in
support
of
management’s
decision
making process.” Menurutnya, data warehouse
adalah sekumpulan data yang
berorientasi subyek, terintegrasi, memiliki rentang waktu, dan tidak berubah, untuk
mendukung pihak manajemen dalam proses pengambilan keputusan.
Menurut
McLeod
(2001,
p
267),
data
warehousing
adalah
perkembangan
dari konsep database yang menyediakan sumber daya data yang lebih baik bagi para
pemakai dan memungkinkan pemakai untuk memanipulasi dan menggunakan data
tersebut secara intuitif.
|
|
13
Menurut
Elmasri dan Navathe (2000,
p
842),
data warehouse adalah
database yang berbeda dari database tradisional dari segi struktur, fungsi, kinerja,
dan tujuan.
Dari definisi-definisi diatas, dapat disimpulkan bahwa data warehouse adalah
sejumlah
besar
data
yang
dikumpulkan,
yang
kemudian
diolah melalui
proses
pembersihan,
ekstraksi,
dan
transformasi
menjadi sekumpulan data yang dapat
menyediakan informasi strategis dan mendukung usaha pengambilan keputusan yang
lebih baik
Hampir
semua
sumber
data
pada
data
warehouse berasal dari lingkungan
operasional.
Beberapa
faktor di bawah ini menunjukkan bahwa pengulangan data
antara dua lingkungan sangat jarang terjadi:
1.
Data disaring begitu masuk ke lingkungan data warehouse,
hanya data
yang
diperlukan oleh proses DSS (Decision
Support
Systems)
yang
masuk
ke
lingkungan data warehouse.
2. Sifat data sangat berbeda dari satu lingkungan ke lingkungan berikutnya.
Data
pada
lingkungan operasional sangat baru sedangkan data pada data
warehouse
sudah tidak baru lagi.
3. Ada ringkasan data pada data warehouse yang tidak ditemukan pada lingkungan
operasional.
4.
Data mengalami
transformasi fisik dan diubah secara radikal begitu masuk ke
lingkungan data
warehouse.
Yang
dimaksud
transformasi
fisik
adalah
proses
pemindahan data dari data operasional ke dalam data warehouse, dimana terjadi
perubahan format data agar berorientasi pada subyek, terintegrasi, time-variant,
|
 14
dan
tak
berubah
terhadap
proses
operasional.
Dalam
proses
transformasi
dilakukan langkah-langkah berikut ini:
a. Konversi data
b. Memilih data yang terbaik jika berasal dari lebih dari satu sumber.
c. Summary data.
d. Menambah struktur kunci dan struktur fisik.
e. Mengatur ulang format data.
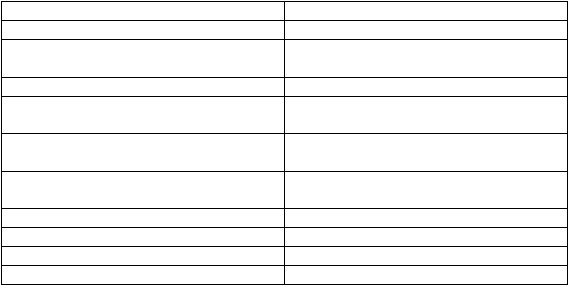
Berikut
ini ditampilkan tabel perbandingan OLTP dengan
Data Warehouse
(lihat tabel 2.1):
Tabel 2.1 Perbandingan OLTP dan Data Warehouse
OLTP
Data Warehouse
Menangani data sekarang
Menangani data sejarah
Menyimpan data secara detil
Menyimpan data yang bersifat detil,
lightly dan highly summarized
Datanya dinamis
Datanya secara garis besar statik
Prosesnya berulang
Prosesnya bersifat ad hoc, unstructed,
dan heuristic
High level of transaction throughput
Medium to low level of transaction
throughput
Pola penggunaannya dapat diprediksi
Pola
penggunaannya
tidak
dapat
diprediksi
Transaction-driven
Analysis-driven
Berorientasi aplikasi
Berorientasi analisis
Mendukung keputusan per hari
Mendukung keputusan strategis
Melayani operational user
Melayani managerial user
Dari
tabel
di
atas
diketahui
bahwa
OLTP
dan data
warehouse
memiliki
karakteristik
yang
berbeda.
Sistem OLTP
menyediakan
sumber
data
untuk
data
warehouse, atau dengan kata lain, data warehouse sendiri secara periodik diisi data
dengan data dari OLTP setelah menjalani pembersihan dan integrasi data.
|
|
15
2.1.5 Konsep Data Warehouse
Konsep orisinil dari data warehouse adalah sebagai ‘information warehouse’
dan
merupakan
suatu
solusi
untuk
mengakses
data
yang
terdapat
dalam sistem.
Kemudian konsep tersebut berkembang, data warehouse tidak hanya sebagai suatu
solusi untuk mengakses data, melainkan juga digunakan sebagai suatu penunjang
dalam proses
pembuat
keputusan
(decision
making
process)
dalam manajemen.
Karakteristik data warehouse menurut Inmon (2002, p 31) adalah:
1. Berorientasi subyek (subject-oriented)
Data warehouse
berorientasi subyek karena diorganisasikan di sekitar subyek-
subyek
utama
dari
perusahaan,
seperti: customers,
products,
dan
sales.
Data
warehouse tidak diorganisasikan pada area-area aplikasi utama, seperti customer
invoicing, stock
control, dan product sales. Hal ini dicerminkan dalam
kebutuhannya
dalam menyimpan
data-data
yang
digunakan
sebagai
pembuat
keputusan, daripada aplikasi yang berorientasi
terhadap
data.
Jadi
dengan
kata
lain,
data
yang
disimpan
tidaklah
berorientasi terhadap proses, melainkan
berorientasi pada subyek mana yang
membutuhkan data tersebut. Perbedaan
antara
orientasi
aplikasi
proses
dengan orientasi
subyek
terlihat
jelas
dari
perbedaan
isi
data
pada
tingkatan data
yang
rinci.
Data
yang
tidak
digunakan
pada pemrosesan sistem penunjang keputusan (Decision Support Systems) tidak
termasuk
sebagai
data
inputan
pada
data warehouse, sedangkan
pada orientasi
aplikasi operasional, data yang digunakan terdiri atas data untuk keperluan
fungsional atau pemrosesan baik yang dibutuhkan maupun yang tidak
dibutuhkan. Cara lain untuk membedakan data berorientasi aplikasi operasional
|
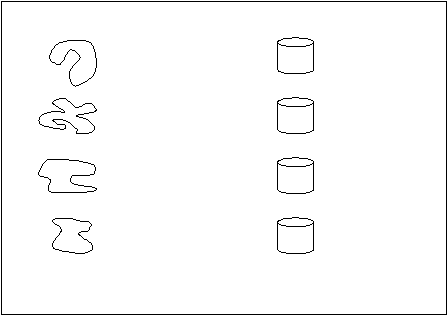 16
dengan data pada warehouse
adalah pada hubungan-hubungan dari data. Data
operasional memelihara hubungan yang terus-menerus antara dua atau lebih
tabel berdasarkan kaidah bisnis untuk waktu yang singkat. Data pada warehouse
menjangkau jangka waktu yang panjang dan hubungan-hubungan yang diperoleh
dalam data warehouse sangat banyak.
Untuk
lebih jelasnya, dapat dilihat pada
gambar 2.2.
operational
data
warehouse
auto
customer
life
policy
health
premium
casualty
claim
applications
subjects
Gambar 2.2 Data yang berorientasi subyek
2. Terintegrasi (integrated)
Aspek terpenting dalam ruang lingkup warehousing adalah sumber
data (data
source) yang terintegrasi. Sumber data diintegrasikan untuk memenuhi berbagai
kebutuhan informasi dalam organisasi, karena sumber data tersebut berasal dari
sistem-sistem aplikasi perusahaan
yang berbeda dan luas sehingga sumber data
tersebut sering kali tidak konsisten dalam penggunaannya, sebagai contoh
format-format yang berbeda. Adapun proses
yang terjadi dalam membuat data-
|
|
17
data sumber yang berbeda-beda menjadi konsisten meliputi pengubahan format,
memformat ulang, menyusun ulang, merangkum sehingga sumber data konsisten
dalam menyajikan gambaran hasil penyatuan dari data tersebut kepada
pengguna. Syarat integrasi sumber data
dapat dipenuhi dengan berbagai cara
seperti konsisten dalam penamaan variabel, konsisten dalam ukuran variabel dan
konsisten dalam struktur pengkodean dan konsisten dalam atribut fisik dari data.
Pada
lingkungan
operasional
terdapat
berbagai
macam aplikasi
yang
mungkin
dibuat oleh pengembang (developer) yang berbeda-beda, oleh karena itu,
mungkin aplikasi
tersebut ada istilah atau variabel
yang
memiliki
maksud
yang
sama
tetapi
nama
dan
formatnya
berbeda. Hal tersebut tidak diperkenankan
sebagai
sumber
data
yang
terintegrasi, seluruhnya harus konsisten, maksudnya
berbagai
data
yang
berbeda
baik
dalam bentuk
nama
dan
formatnya,
harus
dikonversi menjadi nama dan format yang disepakati bersama. Dengan
demikian, tidak ada
lagi kerancuan karena terdapat
lebih dari satu sumber data
dan ketidak-konsistensian nama, tanggal dan sebagainya, seperti contoh pada
gambar 2.3.
|
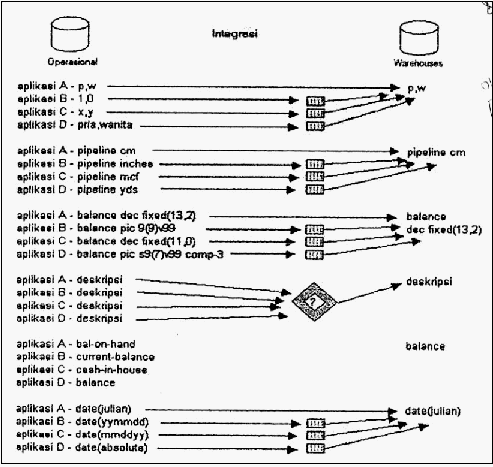 18
Gambar 2.3 Integrasi data warehouse
3. Memiliki rentang waktu (time-variant)
Seluruh data di dalam warehouse dapat dikatakan akurat serta valid pada interval
atau rentang
waktu
tertentu.
Karakteristik
dasar
data dalam warehouse
sangat
berbeda dengan data pada lingkungan operasional, dimana data hanya akurat
untuk waktu sesaat setelah data diakses, sedangkan data pada warehouse dapat
dikatakan akurat selama periode waktu tertentu sehingga memiliki interval /
rentang
waktu
(time
variant).
Data
ditampung
pada
time variant
yang
valid,
kemudian akan ditampilkan ke dalam snapshot. Setiap
lingkungan
mempunyai
|
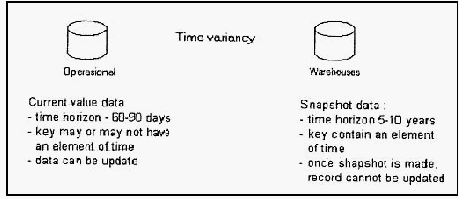 19
rentang waktu yang berbeda. Pengumpulan rentang waktu pada data di dalam
data warehouse secara signifikan lebih lama daripada yang terdapat pada sistem
operasi. Rentang waktu 60-90 hari adalah suatu keadaan normal bagi sistem
operasi. Sementara itu, rentang waktu 5-10 tahun adalah keadaan normal bagi
sebuah
data warehouse.
Karenanya,
data
warehouse
memiliki
data
historikal
lebih banyak daripada data pada lingkungan lain, seperti
terlihat pada
gambar
2.4.
Gambar 2.4 Rentang waktu data warehouse
4. Tetap atau tidak berubah (non-volatile)
Karakteristik keempat dari data warehouse adalah non-volatile. Maksudnya data
pada warehouse tidak di-update secara real time, tetapi di-refresh / diperbaharui
dari
sistem
operasional
secara regular
/
teratur.
Data baru
yang
selalu
ditambahkan sebagai suplemen bagi basis data itu sendiri bukan sebagai sebuah
perubahan. Basis data tersebut secara berkala
dan
terus
menerus
memasukkan,
kemudian secara incremental (naik secara bertahap) disatukan dengan data
sebelumnya.
Ketika
data pada database
memuat
data baru dan
database
|
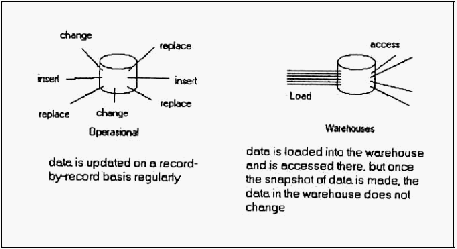 20
kemudian
di-load ke
dalam data
warehouse,
maka
data
warehouse
tidak
memperbaharui snapshot
dari
data
warehouse
yang lama
tetapi membuat
snapshot sehingga syarat non-volatille tercapai dan history dari data warehouse
terus terjaga. Ilustrasinya dapat dilihat pada gambar 2.5.
Gambar 2.5 Data warehouse tidak berubah
2.1.6 Anatomi Data Warehouse
Konsep penerapan data warehouse
adalah
mengambil
data
dari
berbagai
sumber dan memindahkannya ke dalam sebuah pusat pengumpulan data yang besar.
Anatomi data warehouse terbagi tiga, yaitu:
1. Data warehouse fungsional (Functional Data Warehouse)
Data
warehouse
fungsional
mempergunakan
pendekatan kebutuhan dari tiap
bagian fungsi bisnis, misalnya departemen, divisi, dan sebagainya, untuk
mendefinisikan jenis data yang akan ditampung di dalam sistem. Penerapan data
warehouse
fungsional
ini
memiliki resiko
kehilangan
konsistensi
data
di
luar
|
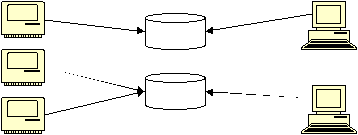 21
lingkungan
fungsi
bisnis
bersangkutan,
jika
pendekatan
ini
lingkupnya
diperbesar dari lingkungan fungsional menjadi lingkup perusahaan. Keuntungan
penerapan pendekatan sistem ini adalah bahwa sistem ini dapat
memberi solusi
yang
mudah
untuk dibangun
dengan biaya
investasi
yang
relatif rendah
yang
dapat memberikan kelompok pemakai sebuah kemampuan sistem pengumpulan
data yang terbatas (lihat gambar 2.6).
Sistem
operasional
Data
Workstation
Data
Gambar 2.6 Data warehouse fungsional
2. Data warehouse terpusat (Centralized Data Warehouse)
Pendekatan jenis ini banyak digunakan oleh pemakai karena terbiasa dengan
lingkungan mainframe yang terpusat. Data diambil dari seluruh sistem
operasional dan disimpan di dalam pusat penyimpanan data (storage). Data yang
terkumpul digunakan untuk membangun data warehouse
fungsional
masing-
masing. Alasan menggunakan sistem ini adalah bahwa data benar-benar terpadu.
Tetapi
sistem
ini
mengharuskan
pemasok
data
harus
mengirim data
tepat
waktunya agar tetap konsisten dengan pemasok lainnya. Di samping itu, pemakai
hanya dapat
mengambil data dari pusat pengumpulan data saja dan tidak dapat
secara langsung berhubungan dengan pemasok datanya sendiri. Faktor yang
membuat
orang
keberatan
menggunakan
pendekatan
ini adalah
biaya
|
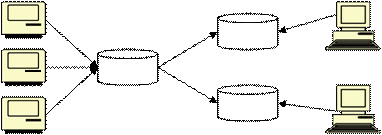 22
pemeliharaan yang tinggi atas sistem pengumpulan data yang sedemikian besar
juga waktu membangun sistemnya (lihat gambar 2.7).
Sistem
operasional
Data
Data
Workstation
Data
Gambar 2.7 Data warehouse terpusat
3. Data warehouse terdistribusi (Decentralized Data Warehouse)
Pendekatan ini memungkinkan pemakai untuk langsung berhubungan dengan
sumber data maupun dengan pusat pengumpul data lainnya, karena
dikembangkan berdasarkan konsep data “gateway”. Pendekatan ini
mengandalkan
keunggulan teknologi
“client
/
server”.
Kekurangan
pendekatan
ini
adalah
sistem memerlukan
biaya
yang
sangat
besar
karena
setiap
sistem
pengumpulan
data
fungsional
dan
sistem operasinya
dikelola
secara
terpisah.
Selain
itu,
perlu
sinkronisasi
untuk memelihara
keterpaduan
data.
Metode
ini
efektif
apabila
data
tersedia
dalam bentuk
yang
konsisten.
Pemakai
dapat
menambah data tersebut dengan informasi
baru apabila ingin membentuk
gambaran baru atas informasi. Ilustrasi ini terlihat pada gambar 2.8:
|
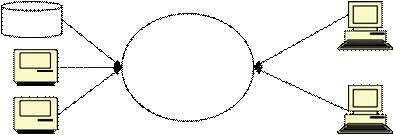 23
Sistem
Data
Data
operasional
Warehouse
Gateway
Workstation
Gambar 2.8 Data warehouse terdistribusi
2.1.7 Arsitektur Data Warehouse
Menurut
Anahory dan
Murray (1997),
arsitektur dan komponen
utama dari
data warehouse dapat dilihat pada gambar 2.9 berikut:
|
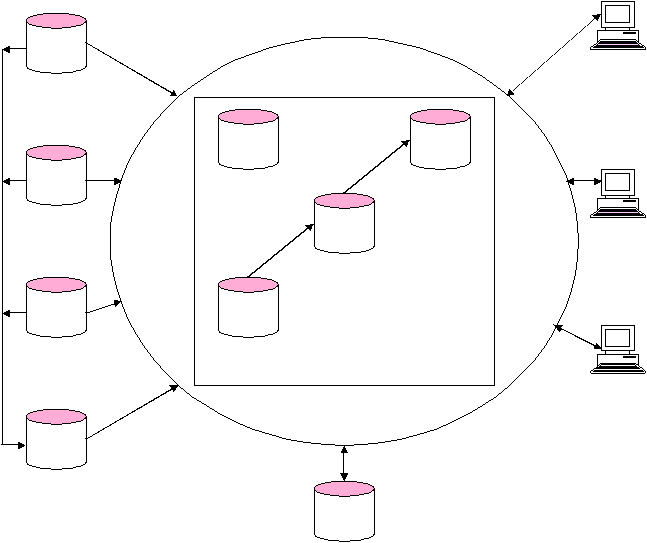 24
Operational data
source 1
Warehouse Manager
Reporting, query,
application
development, and
EIS tools
Metadata
Highly
summarized data
Operational data
source 2
Load
Manager
Query
Manager
OLAP
tools
Lightly
summarized data
DBMS
Operational data
source n
Detailed data
Warehouse Manager
Data
mining
tools
Operational data store
(ODS)
End-user
access tools
Archive/backup data
Gambar 2.9 Arsitektur data warehouse secara umum
Komponen arsitektur data warehouse yang dikemukakan oleh Anahory dan Murray
(1997), meliputi:
1. Operational Data
Sumber data dari data warehouse dapat diambil langsung dari:
a. Mainframe dimana data disimpan pada tingkatan tertinggi.
|
|
25
b. Data bagian yang
terdapat pada sistem file seperti VSAM, RMS, dan
RDBMS seperti Informix dan Oracle.
c. Server / workstation pribadi yang terletak dalam jaringan.
d. Sumber
eksternal
(misalnya
database dari
internet,
database
dari rekanan
seperti dari rekanan atau distributor).
2. Penyimpanan Data Operasional (Operational Data Store / ODS)
Sebuah
ODS
merupakan
tempat
penyimpanan
data
yang
terintegrasi,
dimana
data yang tersimpan dalam ODS digunkan untuk analisis. ODS menerima
inputan data
yang sama dengan data
yang diterima pada data warehouse, tetapi
pada
kenyataannya
data
yang
ada pada
ODS
dipindahkan
ke
dalam
data
warehouse.
Dalam
semua
keadaan,
penyimpanan data
operasional
harus
dibuat
terpisah dari data warehouse. Dengan membangun ODS, akan sangat membantu
dalam membangun data warehouse karena data pada ODS adalah data bersih dan
sudah terekstrasi dari sistem sumber.
3. Load Manager
Disebut
juga
sebagai
komponen front-end
yang
bertugas
melakukan
seluruh
operasi
yang berhubungan
dengan
ekstraksi
dan
me-load
data ke
warehouse.
Data tersebut mungkin saja diekstrak secara langsung dari sumber data atau yang
umum digunakan
adalah
dari data
store
operasional.
Operasi-operasi
yang
dilakukan oleh load manager termasuk didalamnya
transformasi-transformasi
sederhana dari data, agar data tersebut menjadi siap untuk dimasukkan pada
warehouse.
|
|
26
4. Warehouse Manager
Warehouse manager
melakukan
seluruh
operasi
yang
berhubungan
dengan
kegiatan manajemen data di dalam warehouse. Operasi tersebut meliputi:
a. Analisis terhadap data untuk memastikan konsistensi.
b. Transformasi dan penggabungan sumber data dari tempat penyimpanan
sementara menjadi tabel-tabel data warehouse.
c. Penciptaan indeks-indeks dan view-view berdasarkan tabel-tabel dasar.
d. Melakukan denormalisasi dan agregasi jika diperlukan.
e. Backing-up dan mengarsipkan data.
5. Query Manager
Disebut juga sebagai komponen back-end melakukan operasi yang berhubungan
dengan manajemen user queries. Operasi yang dilakukan oleh komponen ini
termasuk
mengarahkan query kepada
tabel-tabel
yang
tepat
dan
menjadwalkan
eksekusi dari query-query tersebut.
6. Data detil yang aktif sekarang (current detail data)
Data detil yang aktif sekarang
yaitu: data yang mencerminkan keadaan terbaru,
yang
mendapat
perhatian
utama.
Data
ini
merupakan level
terendah
dari
data
warehouse, dapat diakses dan memerlukan storage yang besar namun mahal dan
sulit untuk diatur karena data ini sangat kompleks.
7. Data historis (older detail data)
Data historis adalah hasil backup yang disimpan dalam storage terpisah dan pada
saat tertentu
dapat
diakses kembali. Penyusunan
direktori
untuk
data
ini
harus
mencerminkan umur dari data agar memudahkan pengaksesan kembali.
|
|
27
8. Data ringkasan level menengah (lightly summarized data)
Data ringkasan level menengah adalah data hasil ringkasan dari data tingkat
rendah
yang
ada
pada
data
detil
yang aktif
sekarang,
tapi
belum bersifat
total
summary.
Pengaksesan
data
ini
banyak
ditampilkan
dalam bentuk
view
dari
kondisi yang sedang berjalan atau sudah berjalan.
9. Data ringkasan level tinggi (highly summarized data)
Data ringkasan level tinggi adalah data yang tersusun rapi dan mudah diakses,
terutama untuk melakukan analisa perbandingan data berdasarkan urutan waktu
dan analisa yang menggunakan data multidimensi. Sumber data ini dapat berasal
dari data yang aktif sekarang ataupun di luar dari data warehouse.
10. Metadata
Metadata bukan data
hasil kegiatan operasional seperti empat jenis data di atas.
Metadata merupakan data
tentang data (Darling, 1996), data
yang berisi semua
objek yang ada pada data warehouse pada definisi dari database, tabel, kolom,
view, query, transformasi, validasi, dan lain-lain. Tujuan utama metadata adalah
untuk menunjukkan jalur asal dimana data dimulai, sehingga administrator
warehouse
dapat
mengetahui
history
dari
segala
item
dalam
warehouse.
Metadata dibuat untuk menjawab struktur data spesifik, walaupun asal datanya
sama. Metadata
juga
menyediakan
catatan asal data
yang dipergunakan
dalam
proses
transformasi.
Catatan
ini
memberikan
referensi
kepada
pengguna
akhir
dari
sistem,
seperti
juga
keabsahan
data
bagi
sistem pengumpulan
data
perusahaan.
Metadata
yang
berasosiasi
dengan
transformasi
dan loading
data
harus mendeskripsikan sumber data dan segala perubahan yang dibuat terhadap
data. Sebagai contoh,
untuk setiap field sumber harus terdapat sebuah pengenal
|
|
28
unik, nama field orisinil, tipe data sumber, dan lokasi orisinil meliputi sistem dan
nama objek, termasuk tipe data tujuan dan tabel nama tujuan. Jika
field
merupakan subyek dari suatu transformasi, juga harus direkam.
Metadata tidak
mengandung
data
yang
diambil
langsung dari
lingkungan
operasional,
tetapi
memuat informasi penting yang digunakan sebagai:
a.
Direktori
untuk
membantu
analisis DSS
mengalokasikan
isi
daripada data
warehouse.
Panduan
untuk
menempatkan
data
operasional
ke
dalam
data
data
warehouse
serta aturan-aturan tranformasi
yang diperlukan
agar
suatu
data operasional dapat dipindahkan ke dalam data warehouse.
b. Panduan
untuk
membuat
ringkasan
data dari
data
detil
sekarang
menjadi
data
ringkasan
level
menengah,
dari
data
detil
ringkasan level
menengah
menjadi
data
ringkasan
level tinggi,
dan
lain-lain.
Tidak
semua hasil
ringkasan disimpan dalam data warehouse tetapi hanya hasil ringkasan yang
sering digunakan yang akan disimpan.
Menurut Connolly (2005, p 1159), pada area ini warehouse menyimpan seluruh
definisi-definisi metadata / data mengenai data itu sendiri (data about data) yang
akan
digunakan
oleh
seluruh
proses
di
dalam warehouse.
Metadata digunakan
untuk berbagai tujuan antara lain:
a. Proses loading dan ekstraksi – metadata digunakan
untuk
memetakan
sumber-sumber data kepada seluruh view data di dalam warehouse.
b. Proses manajemen warehouse – metadata digunakan untuk mengotomatisasi
produksi tabel-tabel summary.
c. Sebagai bagian dari proses query management – metadata digunakan untuk
mengarahkan sebuah query kepada sumber data yang paling sesuai.
|
|
29
Struktur dari metadata beragam pada setiap proses, hal ini mencerminkan bahwa
metadata
mendekripsikan
item
data
yang sama seperti
yang
terdapat
di
dalam
data warehouse. End-user tools menggunakan metadata ini untuk dapat mengerti
bagaimana cara membuat sebuah query.
11. End-user Access Tools
Prinsip
atau tujuan
utama
dari
data
warehousing
adalah
untuk
menyediakan
informasi
bisnis
kepada user
untuk
dapat
melakukan
pengambilan
keputusan
secara cepat dan tepat. User ini berinteraksi dengan warehouse melalui end-user
access tools. Data warehouse harus secara efisien mendukung secara khusus
kebutuhan user serta secara rutin melakukan analisis. Performa yang baik dapat
dicapai
dengan
merencanakan
dahulu
keperluan
untuk
melakukan joins,
summations,
dan
laporan per periode
dengan end-users.
Berdasarkan kategori
yang
dikemukakan oleh
Berson
dan
Smith
(1997)
terdapat 5
grup
utama dari
tools tersebut, antara lain:
a. Reporting and Query Tools
Reporting
Tools
meliputi
production
reporting
tools
dan report
writers.
Production reporting tools
digunakan
untuk
menghasilkan
laporan
operasional regular
(biasa),
seperti
faktur
pelanggan,
dan
pembayaran staf.
Sedangkan report writer adalah desktop tools yang dirancang untuk end-user
(pengguna). Query tools untuk data warehouse relasional dirancang untuk
menerima SQL atau menghasilkan pernyataan SQL
untuk proses query data
yang tersimpan dalam warehouse.
b. Application Development Tools
Aplikasi
yang dapat digunakan user yaitu graphical data access yang
|
|
30
dirancang secara primary
untuk sisi client-server. Beberapa application
development tools
terintegrasi dengan OLAP tools dan dapat mengakses
semua sistem basis data utama, mencakup Oracle, Sybase, dan Informix.
c. Executive Information System (EIS) Tools
EIS atau yang lebih dikenal sebagai ‘everybody’s information systems’, yang
semula dikembangkan untuk mendukung pengambilan keputusan strategi
tingkat
tinggi.
Kemudian
meluas
untuk
mendukung
semua
tingkat
manajemen.
EIS
tools
yang
terasosiasi
dengan
mainframe
memungkinkan
user
membuat aplikasi pendukung pengambilan keputusan untuk
menyediakan overview data eksternal. Saat ini, perbedaan antara EIS dengan
decision-support
tools lainnya semakin tidak
jelas, sejak
pengembang
EIS
melakukan penambahan fasilitas-fasilitas tambahan dan menyediakan
aplikasi
custom-built
untuk
area
bisnis
seperti
penjualan,
marketing, dan
keuangan.
Sementara
itu,
Decision
Support
Systems (DSS)
adalah
sebuah
model yang didasarkan pada sejumlah prosedur dalam memproses data dan
pertimbangan yang bertujuan membantu manajer ketika membuat keputusan.
DSS dibangun bukan untuk menggantikan peran manajer dalam menganalisa
masalah dan mengambil keputusan, melainkan membantu peran manajer
dalam menganalisa sejumlah data yang begitu besar sehingga keputusan yang
diambil berdasarkan data dan informasi yang akurat.
|
|
31
d. Online Analytical Processing (OLAP) Tools
OLAP tools
berbasis pada konsep basis data multi-dimensi dan
memperbolehkan pengguna untuk menganalisis data menggunakan view yang
kompleks dan multi-dimensional. Tools ini mengasumsikan bahwa data
diatur dalam model multi-dimensi
e. Data Mining Tools
Data
mining
adalah
sebuah
proses
untuk
menemukan
suatu korelasi
baru
yang bermakna, pola dan kecenderungan baru dengan menggali data yang
sangat besar menggunakan teknik statistik, matematis, dan intelegensia semu
(Artificial Intelligence). Data
mining
mempunyai potensi
yang
cukup
baik
dalam menggali OLAP yang disediakan oleh data warehouse.
2.1.8 Data Mart
Data mart adalah sebuah subset dari suatu data warehouse yang secara
normal
berbentuk
rangkuman
data
yang
berhubungan
dengan
sebuah
departemen
atau
fungsi
bisnis tertentu. Data
mart
dapat
berdiri
sendiri atau
terhubung
secara
sentral dengan data warehouse perusahaan.
Karakteristik
yang
membedakan data
mart dengan data warehouse meliputi:
1. Data mart hanya fokus terhadap permintaan user terhadap satu departemen atau
fungsi bisnis.
2. Data mart secara normal tidak mengandung data operasional secara detil, tidak
seperti data warehouse.
3. Karena
data
mart
memuat
lebih
sedikit
data
dibandingkan
dengan
data
warehouse, data mart lebih mudah dimengerti dan ditelusuri.
|
 32
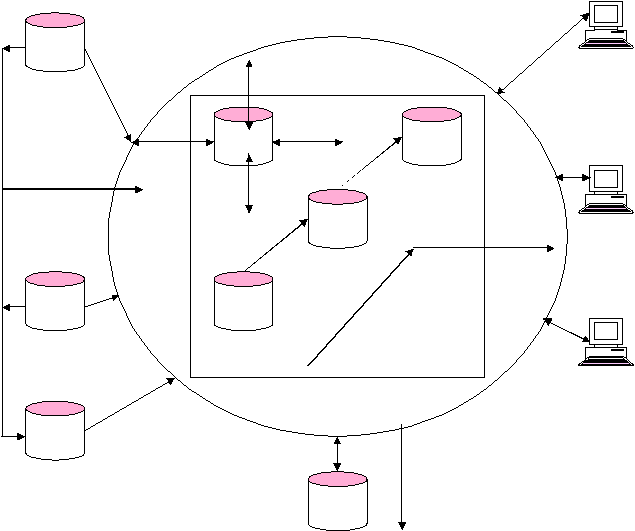
2.1.9 Aliran Proses Data Warehouse
Data warehousing menekankan pada manajemen 5 pokok data flows, yaitu
inflow, upflow, downflow, outflow dan metaflow (Hackarthorn, 1995) seperti terlihat
pada gambar 2.10 di bawah ini:
Warehouse Manager
Operational data
source 1
Metaflow
Metadata
Inflow
Highly
summarized data
Operational data
source 2
Load
Manager
Outflow
Query
Manager
OLAP
tools
Lightly
summarized data
Upflow
DBMS
Operational data
source n
Detailed data
Warehouse
Manager
Data
mining
tools
Operational data store
(ODS)
Downflow
End-user
access tools
Archive/backup data
Gambar 2.10 Aliran informasi pada sebuah data warehouse
|
|
33
1. Inflow
Adalah proses yang berkaitan dengan ekstraksi, pembersihan, dan pemasukan
data
dari
sistem
sumber
ke
dalam data
warehouse.
Cara
lain,
data
bisa
saja
dimuat
dalam ke
penyimpanan
data operasional
sebelum
ditransfer
ke
data
warehouse. Karena data sumber kebanyakan dihasilkan oleh OLTP systems,
maka data harus terlebih dahulu direkonstruksi untuk keperluan data warehouse.
Proses rekonstruksi data melibatkan:
1. Pembersihkan ‘data kotor’ (data yang tidak sama formatnya, tidak
konsisten).
2. Merestrukturisasi data agar sesuai dengan kebutuhan data dari data
warehouse yang baru, contohnya menambah dan / atau membuang fields dan
denormalisasi data.
3. Memastikan bahwa data sumber konsisten dengan data itu sendiri dan
dengan data lain yang sudah ada dalam warehouse.
Untuk dapat secara efektif mengatur inflow,
mekanisme
harus diidentifikasikan
terlebih dahulu untuk menentukan kapan memulai mengekstrak data untuk
melakukan transformasi yang diperlukan, dan untuk
menjamin konsistensi.
Ketika
mengekstrak data dari sistem sumber, adalah penting
untuk memastikan
bahwa
data
dalam keadaan
konsisten
untuk
dapat
menghasilkan
view
yang
konsisten serta terintegrasi dari
corporate data. Setelah data telah diekstrak,
biasanya
data
akan
ditampung
dan
dimuat
ke
dalam penyimpanan
sementara
untuk keperluan pembersihan dan pengecekan konsistensi data.
|
|
34
2. Upflow
Upflow adalah proses yang berkaitan dengan menambahkan nilai (value) ke data
dalam warehouse melalui aktivitas summarizing, packaging, dan distribusi data.
1.
Summarizing, membuat ringkasan data dengan proses
selecting, projecting,
joining,
dan grouping
data
relasional ke
dalam
tampilan
yang
lebih
tepat
guna
dan
mudah
dimengerti
bagi
penggunanya. Summarizing
melibatkan
operasi relasional sederhana dengan melakukan
analisis
statistik
modern
termasuk mengenali tren (identifying trends), pengelompokan (clustering)
dan pengambilan sample data (sampling the data).
2. Packaging the data, dengan mengkonversikan data yang telah dirangkum ke
bentuk yang lebih tepat guna seperti,
lembar kerja (spreadsheets), dokumen
teks, diagram, bentuk grafik lainnya, database pribadi, dan animasi.
3. Distributing
the
data,
memasukkan
data
ke
dalam
grup-grup
yang
sesuai
untuk meningkatkan ketersediaan dan kemudahan akses.
Ketika
menambahkan
nilai (value) ke data, pertimbangan yang baik diperlukan
dalam mendukung kebutuhan performa dari data warehouse tersebut dan untuk
meminimalisasikan
biaya
operasional
berjalan.
Kebutuhan
tersebut
dangat
penting dalam
menentukan desain ke arah yang benar, membuat restrukturisasi
untuk
memperbaiki query
performance
atau
untuk
menurunkan
biaya
operasional.
Dengan
kata
lain,
data warehouse
administrator
harus
mengidentifikasi
desain
database
yang
paling
sesuai
dengan
kebutuhan,
yang
bisa mengakomodasi semua kebutuhan.
|
|
35
3. Downflow
Downflow adalah proses yang diasosiasikan
dengan
mengarsipkan
dan
mem-
backup data dalam warehouse. Mengarsipkan data lama
memegang
peranan
penting
dalam memelihara
efektivitas
dan
performa
data
warehouse
dengan
mentransfer
data
yang
sudah
lama,
dalam jumlah
tertentu,
ke
tempat
penyimpanan
(diarsipkan)
seperti magnetic tape atau optical
disk. Jika skema
partisi dipilih secara benar untuk database, jumlah data online seharusnya tidak
akan mempengaruhi performa. Partisi adalah pilihan desain tepat guna untuk
database-database yang sangat besar, yang memungkinkan fragmentasi sebuah
tabel
penyimpan
record
dalam jumlah
yang
sangat
besar,
dibagi
ke
dalam
beberapa tabel yang lebih kecil. Aturan untuk partisi dapat berdasarkan
karakteristik
data
seperti
area dalam sebuah
negara.
Downflow
data
mencakup
proses untuk
meyakinkan bahwa dari keadaan aktif sebuah data dapat dibangun
kembali
jika
ada
kehilangan
data,
atau kegagalan
software
/
hardware.
Data
yang
telah
diarsipkan
sebaiknya
disimpan sedemikian rupa sehingga
memungkinkan pembaruan data dalam warehouse jika diperlukan.
4. Outflow
Outflow merupakan proses yang diasosiasikan dengan bagaimana membuat data
tersedia bagi pengguna
(end-users). Outflow adalah keadaan dimana nilai
yang
sebenarnya dari
data warehouse
diketahui
oleh
organisasi.
Ini
memerlukan
pemaknaan ulang (re-engineering) proses bisnis untuk dapat mencapai
keuntungan kompetitif (Hackarthorn, 1995). Dua aktivitas utama yang ada dalam
outflow adalah termasuk hal berikut:
|
|
36
1.
Accessing, yaitu hal yang berkaitan
dengan bagaimana memenuhi
permintaan end-users
akan
data
yang
mereka
butuhkan.
Hal
yang
utama
adalah bagaimana menciptakan keadaan yang memungkinkan pengguna bisa
menggunakan query tools untuk mengakses sumber data dengan benar secara
efektif. Frekuensi akses users dapat bervariasi,
mulai dari adhoc (keperluan
tertentu), rutin, sampai real-time (hampir setiap saat). Adalah penting untuk
memastikan
bahwa
sumber
daya
sistem digunakan
secara
efektif
dalam
menjadwalkan (scheduling) eksekusi dari query yang dilakukan oleh user.
2.
Delivering, yaitu hal yang berkatian dengan bagaimana
menyampaikan
informasi
ke workstation
end-users
secara
proaktif.
Ini adalah area yang
relatif baru dalam data warehousing, dan disebut
juga sebagai proses
yang
bertipe
‘publish
and
subscribe’
(tampil
dan gunakan
secara
berkala).
Warehouse
menerbitkan
bermacam-macam ‘business objects’
yang
direvisi
secara periodik dengan memonitor pola pemakaian. User menggunakan
suatu set business objects yang paling sesuai dengan kebutuhan mereka.
Isu
yang
penting
dalam
mengatur
outflow adalah
proses
marketing yang
aktif
tentang data warehouse kepada user, yang akan mempengaruhi operasi
organisasi secara keseluruhan. Ada aktivitas operasional
tambahan
dalam
mengatur outflow, termasuk
mengarahkan query ke tabel target
yang sesuai dan
menangkap (capturing)
informasi dalam query profiles yang terasosiasi dengan
group user
untuk memutuskan
fungsi agregasi
mana
yang
akan diproses. Data
warehouse
berisi
summary
data
secara
potensial
menyediakan
jumlah
sumber
data akurat untuk menanggapi sebuah query
yang spesifik termasuk data
terperinci itu sendiri dan sejumlah tumpukan lain yang sesuai dengan kebutuhan
|
|
37
user. Bagaimanapun, performa query akan bervariasi cukup signifikan,
tergantung karakter data target, isi yang paling penting dari data tersebut.
Sebagai bagian dari
manajemen outflow, sistem harus
memutuskan cara / jalan
yang paling efektif untuk menjawab sebuah query.
5. Metaflow
Metaflow adalah proses yang terasosiasi dengan manajemen metadata. Flow-flow
sebelumnya
menggambarkan
manajemen data
warehouse
dengan
melihat
bagaimana data masuk dan keluar dari warehouse. Metaflow adalah proses yang
memindahkan metadata (data tentang flow-flow lain). Metadata adalah gambaran
isi data dari data warehouse, apa yang ada didalam, darimana asal mulanya, dan
apa yang telah terjadi setelah pembersihan (cleansing), pengintegrasian
(integrating), dan summarizing. Untuk merespon kebutuhan bisnis yang terus
berubah, sistem
yang sudah ada
juga terus berubah secara konstan. Oleh sebab
itu,
warehouse
terlibat
dalam
merespon
pada
perubahan
yang
terus-menerus,
yang
juga
harus
merefleksikan perubahan-perubahan
tersebut
pada
sistem
sumber (source legacy
systems) dan lingkungan bisnis yang berubah. Metaflow
(metadata)
harus
secara
berkesinambungan
di
update dengan
perubahan-
perubahan ini.
2.1.10 Model Dimensional
Model Dimensional (Dimensionality Modelling) merupakan suatu teknik
perancangan
logikal
yang
bertujuan
untuk
menampilkan
data
yang
sesuai
standar
dan bentuknya mudah dipahami sehingga memungkinkan akses dengan kinerja yang
|
|
38
tinggi.
Dimensionality Modelling
menggunakan
konsep
dari
Entity Relationship
Modelling dengan
beberapa
batasan-batasan
yang
penting.
Setiap Dimensional
Modelling terdiri atas tabel dengan primary key yang banyak (composite), disebut
dengan
fact table
dan sekumpulan tabel-tabel yang lebih kecil disebut dengan
dimension
table.
Setiap
tabel
dimensi
mempunyai
sebuah
non-composite
primary
key yang mengarah ke satu komponen dari composite key dalam fact table. Dengan
kata
lain, primary
key
dalam tabel
fakta
dibuat
dari
dua
atau
lebih
foreign
key.
Karakteristik seperti ini dinamakan
star schema (skema bintang) atau star join,
karena menyerupai bentuk bintang.
Fitur penting
lainnya
dari sebuah
model
dimensional
adalah
semua natural
key
diganti
dengan
kunci
pengganti
(surrogate
key). Ini
berarti
bahwa
setiap
gabungan
(join) antara
tabel
fakta dengan tabel dimensi selalu didasari oleh
surrogate key, bukan natural key. Kegunaan dari kunci pengganti ini adalah
memperbolehkan
data
pada
data
warehouse
untuk
memiliki
beberapa kebebasan
dalam penggunaan
data
tidak
seperti
halnya
yang
diproduksi
oleh
sistem
OLTP.
Sebuah
sistem OLTP
memerlukan
struktur
yang
telah
dinormalisasi
untuk
mengurangi
redundansi,
validasi
untuk input data,
mendukung
volume
yang
besar
dari transaksi yang bergerak sangat cepat. Sebuah transaksi biasanya melibatkan
sebuah
proses
bisnis,
seperti
mencatat
order atau
mencetak
pembayaran invoice.
Model OLTP sering terlihat seperti jaring laba-laba yang terdiri atas ratusan, bahkan
ribuan tabel, sehingga sulit untuk dimengerti.
|
|
39
2.1.11 Star Scheme
Skema bintang adalah merupakan sebuah struktur logikal yang memiliki
tabel fakta yang terdiri atas data faktual di tengahnya, dan dikelilingi oleh tabel-tabel
dimensi yang berisi referensi data (yang dapat didenormalisasi).
Tabel fakta yang baik mengandung satu atau lebih numerical measure, atau
‘fakta’,
yang
berhubungan
dengan
masing-masing
record.
Fakta dalam tabel
fakta
harus berupa data
numerik dan aditif karena aplikasi data warehouse
hampir tidak
pernah
mengakses
satu record
tunggal,
melainkan
ratusan,
ribuan,
bahkan
jutaan
record pada suatu waktu dan kemudian melakukan agregasi terhadap record-record
tersebut.
Tabel dimensi, secara umum mengandung informasi deskriptif berbentuk
teks.
Atribut-atribut
dimensi
digunakan
sebagai constraints
dalam
query
data
warehouse. Pada dasarnya, data warehouse yang berguna memiliki relasi yang tepat
dengan data yang terdapat pada tabel dimensi.
Keuntungan skema bintang:
1. Mudah dimengerti.
2. Kinerja yang lebih baik karena waktu query yang lebih kecil.
3. Mudah dikembangkan dan dapat menangani perubahan di masa depan.
Contoh dari skema bintang ini dapat dilihat pada gambar 2.11.
|
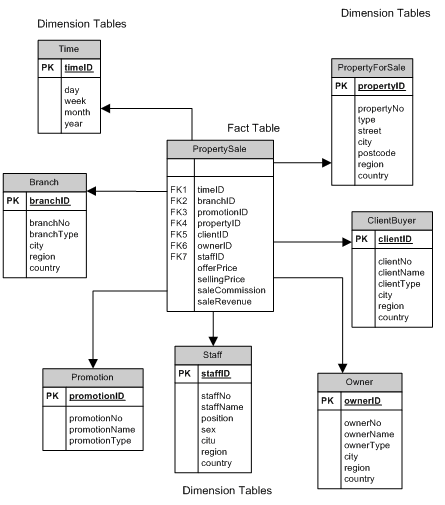 40
Gambar 2.11 Star Schema
2.1.12 Denormalisasi
Skema bintang dapat digunakan untuk mempercepat performa query dengan
melakukan denormalisasi
terhadap
informasi sumber
(reference)
ke
dalam sebuah
tabel dimensi tunggal. Denormalisasi yaitu mencatat data-data yang tidak bergantung
pada kolom lain,
meskipun pada
akhirnya
mengakibatkan
banyak terjadi
duplikasi
data. Tujuannya adalah agar semua informasi yang diperlukan harus terkandung di
tabel log itu sendiri dan tidak bergantung pada tabel lain.
|
|
41
Denormalisasi adalah suatu proses yang merubah bentuk normalisasi dari
database dengan cara penggabungan tabel dan merupakan sebuah proses yang secara
sengaja dilakukan dengan melanggar peraturan bentuk normal dari normalisasi
dengan
tujuan
untuk
meningkatkan
kinerja
(performance)
pengaksesan
data
yang
ada.
Keuntungan melakukan proses denormalisasi adalah:
1.
Mengurangi
jumlah
relasi
yang
terjadi antar tabel-tabel
yang
harus
mengalami
proses pada waktu pencarian sehingga akan meningkatkan kecepatan proses
query data.
2. Membuat struktur fisik database agar mudah dimengerti menurut model dimensi
dari
pemakai. Struktur tabel yang dibuat sesuai keinginan pemakai
memungkinkan terjadinya akses langsung yang sekali
lagi
akan
meningkatkan
kinerja.
Kelemahan melakukan proses denormalisasi adalah:
1. Proses denormalisasi secara tidak langsung akan membuat redundansi data.
2. Proses
denormalisasi
memerlukan
alokasi
memory
dan
storage
(tempat
penyimpanan) yang besar.
2.1.13 Snowflake Scheme
Skema snowflake merupakan variasi pada skema bintang yang menyimpan
seluruh
informasi
tabel
dimensi dalam bentuk
normal ketiga
dan
tabel
fakta
tetap
dalam keadaan
utuh
/
semula
(tidak
mengandung
data
yang
mengalami
denormalisasi). Dengan kata lain, suatu tabel dimensi bisa mempunyai dimensi lain
hasil normalisasi. Contoh dari snowflake scheme ini dapat dilihat pada gambar 2.12:
|
 42
Gambar 2.12 Snowflake Schema
2.1.14 Starflake Scheme
Starflake schema adalah suatu bentuk campuran yang merupakan gabungan
dari star schema dan snowflake schema. Baik itu star, snowflake maupun starflake
memiliki keuntungan didalam lingkungan data warehouse, antara lain:
1. Efficiency – efisien dalam hal mengakses data.
2. Ability to handle changing requirements – dapat berapatasi
terhadap keperluan
user.
3. Extensibility – bersifat fleksibel atas perubahan yang terjadi khususnya
perubahan yang mengarah pada perkembangan.
4. Ability to model common business situations – memiliki kemampuan dalam
memodelkan situasi bisnis secara umum.
|
|
43
5. Predictable
query
processing
–
walaupun
skema
yang
dihasilkan
sangat
kompleks, tetapi pemrosesan query menjadi dapat diperkirakan, hal ini
dikarenakan
pada
level terendah,
setiap
tabel
fakta
harus
di
query secara
independen.
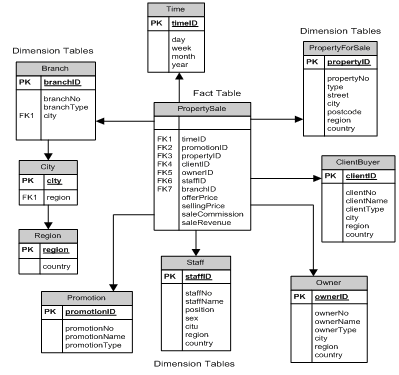
2.1.15 Metodologi Perancangan Database untuk Data Warehouse
Menurut Kimball (1996), ada sembilan tahap metodologi perancangan
database untuk data warehouse
atau yang biasa disebut ‘Nine-Step Methodology’,
yaitu:
1. Langkah 1: Pemilihan proses (choosing the process)
Sebuah proses atau
fungsi
mengacu pada subyek dari data mart tertentu. Data
mart yang pertama kali dibangun haruslah merupakan data mart yang dapat
dikirim tepat waktu dan dapat menjawab semua pertanyaan bisnis yang penting.
Pilihan
yang
terbaik
untuk
data mart
yang
pertama
cenderung
berhubungan
dengan sales,
misalnya:
property
sales,
property leasing, property advertising.
Sumber data ini mudah untuk diakses dan berkualitas tinggi.
2. Langkah 2: Pemilihan sumber (choosing the grain)
Pemilihan sumber ini maksudnya untuk memutuskan secara pasti apa yang
diwakili
atau
direpresentasikan
oleh
sebuah
tabel
fakta.
Jika
sumber
tersebut
telah dipilih untuk tabel fakta, dapat dilakukan identifikasi dimensi untuk tabel
fakta itu. Pertimbangan sumber untuk tabel fakta juga menentukan sumber dari
tiap tabel dimensi.
Misalnya,
jika sumber dari sebuah
tabel
fakta PropertySale
adalah sebuah penjualan properti individual, maka sumber dari sebuah dimensi
pelanggan merupakan rincian pelanggan yang membeli properti tertentu tersebut.
|
|
44
3. Langkah
3:
Mengidentifikasi
dimensi
(identifying
and
conforming
the
dimensions)
Set
dimensi
yang
dibangun
dengan
baik
membuat data
mart
lebih
mudah
dipahami dan mudah digunakan. Dimensi ini penting untuk menggambarkan
fakta-fakta yang terdapat pada tabel fakta melalui sumber yang tepat. Misalnya,
setiap data pelanggan pada tabel dimensi pembeli dilengkapi dengan
id_pelanggan,
no_pelanggan,
nama_pelanggan, tipe_pelanggan,
tempat
tinggal,
nama kota, dan lain sebagainya. Jika
ada dimensi
yang
muncul pada
dua data
mart, kedua data mart tersebut harus berdimensi sama, atau paling tidak salah
satunya merupakan subset matematis dari yang lainnya. Sebuah dimensi yang
digunakan oleh lebih dari 1 data mart disebut conformed dimension. Jika sebuah
dimensi digunakan pada dua data mart atau bahkan lebih, dan dimensi ini tidak
disinkronisasi
maka
keseluruhan
data
warehouse
akan
gagal
karena
dua
data
mart tidak bisa digunakan secara bersama-sama.
4. Langkah 4: Pemilihan fakta (choosing the facts)
Sumber dari tabel fakta menentukan fakta mana saja yang bisa digunakan dalam
data mart. Semua fakta harus diekspresikan pada tingkat yang telah ditentukan
oleh sumber. Fakta harus berupa data numerik dan aditif. Fakta tambahan dapat
dimasukkan
ke
dalam sebuah
tabel
fakta
kapan
saja
asalkan
fakta
tersebut
konsisten dengan sumber dari tabel.
5. Langkah 5: Menyimpan pre-kalkulasi di
tabel
fakta (storing pre-calculations in
the fact tables)
Setiap fakta yang telah diseleksi harus diperiksa kembali untuk melihat apakah
ada kesempatan
untuk menggunakan pre-kalkulasi. Hal
ini terjadi apabila fakta
|
|
45
terdapat unsur pernyataan keuntungan dan kerugian. Situasi ini akan lebih
tampak
pada
tabel
fakta
yang
berasal
dari
invoice
atau
penjualan.
Misalnya,
untuk
menghitung
totalRevenue
per
sewa
properti,
didapat
dari totalRent
dikurangi dengan clientAllowance dan staffCommission. Walaupun totalRevenue
dapat dihitung secara manual dari atribut-atribut ini, tetap saja totalRevenue perlu
disimpan untuk menghindari adanya kesalahan kalkulasi oleh user.
6. Langkah 6: Melengkapi tabel dimensi (rounding out the dimension tables)
Pada tahap ini, kita menambahkan keterangan berbentuk teks selengkap-
lengkapnya
ke
dimensi.
Keterangan
harus
bersifat
intuitif
dan
dapat
dipahami
oleh user. Kegunaan dari sebuah data mart ditentukan dari ruang
lingkup dan
sifat dari atribut pada tabel dimensi.
7. Langkah 7: Pemilihan durasi database (choosing the duration of the database)
Durasi
mengukur
sejauh
mana
ukuran
tabel
fakta dalam
waktu. Misalnya pada
perusahaan asuransi, terdapat persyaratan yang mengharuskan data disimpan
dalam rentang waktu 5 tahun atau bahkan lebih.
8. Langkah 8: Menelusuri perubahan dimensi yang perlahan (tracking slowly
changing dimensions)
Maksudnya bahwa data-data lama seperti deskripsi untuk klien lama
harus
digunakan dengan
history
transaksi
lama.
Seringkali,
data
warehouse
harus
memasukkan sebuah generalized key pada dimensi penting seperti ini dengan
maksud
membedakan serangkaian input dari klien dalam
periode tertentu. Ada
tiga tipe perubahan dimensi yang perlahan ini:
a. Tipe 1: Atribut dimensi yang telah berubah tertulis ulang (overwritten).
|
|
46
b. Tipe
2:
Atribut dimensi
yang
telah
berubah
menimbulkan
sebuah dimensi
baru.
c.
Tipe 3: Atribut dimensi
yang telah berubah menimbulkan atribut alternatif,
sehingga nilai atribut lama dan yang baru dapat diakses secara bersama pada
dimensi yang sama.
9. Langkah 9: Menentukan prioritas dan mode query (deciding the query priorities
and the query modes)
Tahap ini perancangan difokuskan pada perancangan secara fisik. Hal yang perlu
diperhatikan pada perancangan
fisik adalah
urutan secara
fisik pada
tabel
fakta
dalam disk
dan
keberadaan
penyimpanan
awal
ringkasan
atau
agregasi.
Di
samping hal tersebut, perlu diperhatikan juga hal lain seperti administrasi,
backup, performa indeks, dan keamanan.
2.1.16 OLAP
Menurut Connolly (2005, p 1205), OLAP (Online Analytical Processing)
adalah sintesis dinamis, analisis dan konsolidasi dari sekumpulan besar data multi –
dimensi. OLAP merupakan proses departmental untuk lingkungan data mart. OLAP
mendeskripsikan sebuah teknologi yang menggunakan view multi-dimensi
dari
sekumpulan data untuk menyediakan akses yang cepat ke informasi strategis untuk
analisis
lebih
lanjut.
OLAP
memperbolehkan
user
untuk
mendapatkan
pengertian
dan
pengetahuan
yang
mendalam mengenai
berbagai
aspek
dari
data
perusahaan
dengan akses yang cepat, konsisten, interaktif melalui kemungkinan variasi view dari
data.
|
 47
Tabel berikut (lihat tabel 2.2) adalah tabel dari perbandingan OLAP dengan
OLTP:
Tabel 2.2 Perbandingan OLTP dan OLAP
OLTP
OLAP
Digunakan
untuk
mendukung
kegiatan
sehari-hari
Digunakan
untuk
mendukung
kegiatan
analisis
Menggunakan view single, tidak
menggunakan view multi-dimensi
Menggunakan view multi-dimensi
Mendukung keputusan per hari
Mendukung keputusan untuk masa depan
Tidak bergantung pada OLAP
Bergantung pada data
yang tersimpan
dalam sistem OLTP
Melayani operational user
Melayani managerial user
Operasi
query-nya
sederhana
dan
berulang-ulang
Operasi query-nya lebih
rumit, ad hoc,
dan tidak melibatkan operasi data update
Memakai data sehari-hari
Memakai
data
yang
terangkum
dalam
data cube
Tabel berikut (lihat tabel 2.3) adalah tabel dari perbandingan data warehouse
dengan OLAP:
Tabel 2.3 Perbandingan Data Warehouse dan OLAP
Data Warehouse
OLAP
Menyediakan basis data untuk
menyimpan data sejarah dan
menyediakan
data cube
yang
akan
digunakan oleh OLAP
Merupakan end-user access tool dari
data warehouse
Mendukung managerial user
Mendukung
managerial
user
dan
analytical user
Tidak
bergantung pada OLAP dalam
penyediaan datanya
Bergantung pada data
yang tersimpan
pada data warehouse
Menyediakan
teknologi
yang
digunakan
untuk melakukan OLAP
Menggunakan teknologi data warehouse
dalam penggunaannya
|
|
48
Kegunaan
yang secara potensial mengikuti implementasi
yang berhasil dari
sebuah aplikasi OLAP merupakan sebuah keuntungan seperti:
1. Meningkatkan produktifitas bisnis pada end-user, IT developer, dan keseluruhan
perusahaan.
Akses
informasi
yang
lebih
terkontrol
dan
teratur
dapat
meningkatkan pengambilan keputusan yang lebih efektif.
2. Mengurangi backlog dari pengembangan aplikasi untuk staf IT dengan membuat
end-user
tercukupi
kebutuhannya
dalam membuat
perubahan
skema
dan
membangun model yang mereka inginkan.
3.
Penyimpanan dari kendali
organisasi melalui
integritas data perusahaan seperti
aplikasi OLAP tergantung dengan data warehouse dan sistem OLTP untuk me-
refresh tingkat data sumber.
4. Mengurangi
query
dan
lalu–lintas
jaringan
pada sistem OLTP
atau pada
data
warehouse.
5. Meningkatkan
kemungkinan
pendapatan
dan
keuntungan dengan
memperbolehkan perusahaan memberi tanggapan yang lebih cepat terhadap
permintaan pasar.
|
|
49
2.1.17 Definisi Data Mining
Menurut Connolly (2005, p 1233), “Data mining
adalah proses pengolahan
informasi
dari
sebuah database besar
yang
meliputi proses ekstraksi, pengenalan,
komprehensif, dan penyajian infomasi sehingga dapat digunakan untuk pengambilan
keputusan bisnis yang penting dan krusial”.
Sementara menurut Seidman (2001, p 3),
data mining (adalah proses
menemukan patterns / pola yang bernilai dan relationship
yang tersembunyi dalam
basis
data
yang
sangat
besar.
Karena
pencarian
dengan
tabel
dan
record
sangat
jarang ditemukan pattern yang berguna, data biasanya dianalisa dan diproses secara
otomatisasi.
Sedangkan
menurut
Berson
dan
Smith (1997, p
333),
data
mining
adalah
suatu alat bantu yang membantu pengguna akhir dalam mengekstrak informasi bisnis
yang penting dari database yang sangat besar.
2.1.18 Penerapan Data Mining
Di
berbagai
perusahaan
di
dunia, saat
ini
penerapan
aplikasi
dengan data
mining (Berson, 1997, p 123) untuk:
1. Correct Data
Pada saat proses menggabungkan basis
data secara besar-besaran, banyak
perusahaan menemukan data yang digabungkan tersebut tidak lengkap, dan
terdiri dari informasi yang salah dan bertentangan. Dengan menggunakan teknik
data mining, dapat membantu untuk mengidentifikasi dan membetulkan
kesalahan dengan cara yang konsisten.
|
|
50
2. Discover Knowledge
Proses mencari pengetahuan bertujuan untuk menentukan dengan jelas
relationship, pattern,
atau
correlations
yang
tersembunyi
dari
tempat
penyimpanan data di dalam basis data.
3. Visualize Data
Seorang analis harus bisa merasakan sebuah informasi yang besar yang disimpan
di dalam
basis data. Tujuannya
untuk “mempermanusiakan” data
yang banyak
dan menemukan cara yang terbaik untuk menampilkan data.
2.1.19 Metodologi Data mining
Proses data mining dilakukan dengan melalui
tahapan-tahapan tertentu
(Seidman, 2001, p 9), yaitu :
1. Analisa Masalah
Data asal atau data sumber harus bisa ditaksir untuk dilihat apakah data tersebut
memenuhi kriteria data mining. Kualitas dan kelimpahan data adalah faktor
utama
untuk
memutuskan
apakah data
tersebut
cocok
dan
tersedia
sebagai
tambahan. Hasil yang diharapkan dari dampak data mining
harus dengan
hati-
hati dimengerti dan dipastikan bahwa data yang dibutuhkan membawa informasi
yang bisa diekstrak.
2. Mengekstrak dan Membersihkan Data
Data pertama kali diekstrak dari data aslinya, seperti dari OLTP basis data, text
file, Microsoft Access Database,
dan
bahkan
dari spreadsheet, kemudian data
tersebut diletakan dalam data warehouse
yang
mempunyai struktur yang sesuai
dengan
data
model
secara
khas.
Data
Transformation
Service
(DTS)
dipakai
|
|
51
untuk mengekstrak dan membersihkan data
dari ketidakkonsistensiannya dan
ketidakkompatibelnya dengan format yang sesuai.
3. Validasi Data
Setelah data telah diekstrak dan dibersihkan, selanjutnya dengan
menelusuri
model
yang telah kita ciptakan untuk
memastikan bahwa semua data
yang
ada
adalah data sekarang dan tetap.
4. Membuat dan Melatih Model
Ketika algoritma diterapkan pada model, struktur telah dibangun. Hal ini
sangatlah
penting pada
saat
ini
untuk
melihat data yang telah dibangun untuk
memastikan data tersebut
menyerupai
fakta di dalam data sumber.
Hal
ini bisa
dibuat dengan berbagai cara.
5. Query Data
Sekali data model yang pantas / cocok telah diciptakan dan dibangun, data yang
telah dibuat tersedia untuk mendukung keputusan. Hal ini biasanya
melibatkan
penulisan
front
end
query
aplikasi
dengan
suatu
program aplikasi
atau
suatu
program basis data SQL Server melalui OLEDB melalui data mining.
6. Pemeliharaan Validasi Model Data Mining
Karakteristik data
mining
yang
telah
terisi
harus
terjaga
validasinya, seperti
persediaan jumlah suatu barang pada supermarket, apabila ada perubahan
terhadap persediaan barang tersebut, maka perubahan tersebut harus dicatat, jadi
data mining yang terbentuk akan jadi lebih efektif.
|
|
52
2.1.20 Kategori Data Mining
Teknik data mining berhubungan dengan penemuan dan pembelajaran,
pembelajaran tersebut dapat dibagi menjadi dua metode utama, yaitu supervised dan
unsupervised (Berson, Smith, 1997, p 416).
1. Supervised
Teknik ini melibatkan tahap pelatihan dimana data lama yang telah dilatih
tersebut
memiliki characteristic map yang telah diketahui terlebih dahulu untuk
diberikan
kepada
algoritma data mining.
Proses
ini
melatih
algoritma
untuk
mengenali variabel dan nilai-nilai
kunci,
yang
kemudian
menjadi
dasar
untuk
membuat prediksi ketika membaca data baru.
2. Unsupervised
Teknik ini tidak melibatkan tahap pelatihan, tetapi bergantung pada penggunaan
algoritma
yang
mendeteksi
semua
bentuk
seperti asosiasi dan rangkaian yang
terjadi berdasarkan kriteria yang spesifik dalam memasukan data. Pendekatan ini
membawa ke generasi yang mempunyai banyak peraturan yang menggolongkan
penemuan asosiasi, cluster, dan segment. Peraturan ini kemudian akan
melakukan penganalisaan untuk menentukan mana yang memiliki ketertarikan
secara universal.
2.1.21 Hubungan antara Data Mining dengan Data Warehouse
Data mining merupakan kumpulan teknik
yang bertujuan
untuk
menemukan
pola-pola yang berguna
namun
tersembunyi di dalam
basis data, dan
memprediksi
kecenderungan masa depan berdasarkan analisis dari aktivitas masa lampau. Banyak
pimpinan perusahaan telah menyadari bahwa basis data berukuran besar yang
|
 53
memiliki
banyak
informasi
menjadi
sangat penting
perannya.
Disinilah pentingnya
hubungan dan integrasi antara data mining dan data warehouse. Salah satu kunci
sukses
penerapan
data
mining
adalah
kemampuan
untuk
mendapatkan
akses
terhadap data-data yang akurat, lengkap dan terintegrasi. Oleh karena itu, aplikasi
data mining dapat meningkatkan kapabilitas dan integrasi dari data warehouse untuk
mencapai keuntungan kompetitif seperti yang terlihat pada tabel 2.4 di bawah ini.
Tabel 2.4 Perbandingan Data Warehouse dan Data Mining
Data Warehouse
Data Mining
Digunakan
untuk
menganalisa
data-data
yang
memberikan
informasi
secara
eksplisit
Digunakan untuk melakukan information
discovery
Digunakan oleh managerial user
Digunakan
oleh
Data
Analyst
dan
Business Analyst
Merupakan data mentah dari data mining
Menggunakan data dari data warehouse
Menyediakan
data
untuk
diekstrak
data
mining
Mengekstrak pengetahuan tersembunyi
dalam warehouse
Tidak dapat digunakan
untuk melakukan
prediksi
Dapat
digunakan
untuk
melakukan
prediksi
2.1.22 Teknik-teknik yang Digunakan dalam Data Mining
1. Teknik Decision Tree
Decision tree adalah suatu model prediksi yang dapat dilihat sebagai tree. Setiap
cabangnya merupakan hasil klasifikasi dari pertanyaan dan daunnya merupakan
hasil
partisi dari kumpulan data sesuai dengan klasifikasinya. Dalam
penggunaannya dalam dunia bisnis, decision tree bisa digunakan untuk membuat
segmentasi atau pengelompokan dari data
sumber,
dimana
selanjutnya
setiap
segmen dalam segmentasi
ini digambarkan sebagai “daun” dalam decision tree.
Pengelompokan konsumen, barang
/ produk dan daerah pemasaran adalah
|
|
54
contoh pengelompokan umum yang dilakukan manajer pemasaran untuk
memperoleh
tampilan data yang
mudah dimengerti dan mudah untuk dianalisa.
Algoritma
decision tree berhenti
mengembangkan
segmen
atau
cabang-
cabangnya ketika semua segmen terdiri hanya dari 1 record atau ketika sejumlah
record dalam segmen memiliki karakteristik yang sama, segmentasi data telah
tersusun
dengan baik
dengan
1
nilai prediksi
(tidak
perlu dikembangkan
lebih
lanjut karena tree tersebut mencapai tujuannya), pengembangan data perusahaan
tidak memenuhi syarat untuk melakukan pembagian lebih lanjut (sebagai contoh,
bila sejumlah data memiliki kesamaan lebih dari 90 %) (Berson, Smith, 1997, p
351-352).
2. Teknik Clustering
Metode di mana record dikelompokkan dalam grup-grup, berdasarkan kesamaan
karakteristik yang ada di antara record-record yang ada dalam database.
Biasanya teknik ini digunakan untuk high level end user untuk melihat apa yang
terjadi di database dan untuk menyederhanakan tampilan data yang ada dalam
database. Teknik ini termasuk ke dalam kategori unsupervised learning (Berson,
Smith, 1997, p 416). Clustering
dapat juga berarti segmentasi yang sangat
berguna dalam prediksi dan analisa masalah bisnis (Berson, Smith, 1997, p 407).
Contoh clustering: jika kita akan pergi ke binatu / laundry service,
maka baju-
baju kita akan dikelompokkan ke dalam jenis-jenis baju seperti baju putih, baju
berwarna cerah, jeans dan
lainnya
(karena
setiap
jenis
baju
berbeda
cara
pencuciannya).
3. Teknik Memory Based Reasoning (MBR) atau Nearest Neighbor
|
|
55
Nearest
Neighbor
adalah
salah
satu
teknik-teknik
tertua
dalam data
mining.
Nearest Neighbor mirip dengan clustering, yang digunakan untuk memprediksi
nilai dari sebuah record, dimana pengguna teknik ini harus mencari record lain
dengan jenis
dan
nilai
yang mirip
dan
menggunakan
nilai
prediksi
dari record
yang
terdekat
tersebut sebagai
acuan daripada record
yang belum diklasifikasi
(Berson, Smith, 1997, p 407). Teknik ini termasuk ke dalam kategori supervised
learning (Berson, Smith, 1997, p 416). Contoh Nearest Neighbor: jika tetangga –
tetangga
kita
berpenghasilan Rp
5.000.000,00
maka
besar
kemungkinan
penghasilan kita juga Rp 5.000.000,00.
4. Teknik Neural Network
Definisi neural networks yang sesungguhnya adalah jaringan sistem saraf dalam
otak
manusia
yang
mengenali
pola-pola, membuat perkiraan dan pembelajaran
(Berson, Smith, 1997, p 375). Sedangkan yang dimaksud di sini adalah “artificial
neural networks” yaitu program komputer yang
menerapkan pencarian pola dan
algoritma
pembelajaran bagi
mesin komputer
untuk
membuat
model
perkiraan
dari
data
historikal
yang
besar. Artificial
neural
networks,
sesuai
namanya
merupakan
“otak”
tiruan dari
otak
manusia dan
dibuat sedemikian
rupa
agar
dapat menirukan cara kerja otak manusia dalam menyelesaikan masalah. Neural
Network
sendiri
lebih
banyak
dikembangkan
dan
digunakan
dalam dunia
intelegensia
semu
/
artificial
intelligence,
daripada
di
dunia
statistika. Neural
Networks pertama kali diperkenalkan oleh McCullock dan Pits dalam seminar
dalam Perang Dunia ke-2 yang mulanya hanya menyampaikan sebuah ide
tentang unit pemrosesan sederhana (seperti sebuah neuron dalam otak manusia).
|
|
56
Ide
tersebut
dapat
dihubungkan
bersama-sama
dalam jaringan
yang
besar
sehingga membangun sebuah sistem dengan kemampuan
untuk
menyelesaikan
masalah-masalah yang sulit dan menampilkan pola-pola yang kompleks dari
yang dapat dibuat oleh satu buah unit saja (Berson, Smith, 1997, p 375).
5. Teknik Rule Induction
Rule Induction (Berson, Smith, 1997, p 469) adalah salah satu teknik dalam data
mining
yang
paling
sering
digunakan
dalam menemukan
pengetahuan
dalam
sistem
unsupervised
learning. Rule
(aturan) adalah bentuk sederhana dari
“jika
ini maka ini dan kemudian ini“. Agar aturan-aturan
tersebut
bermanfaat
maka
harus ditambahkan informasi tambahan sesuai dengan keadaan sebenarnya,
yaitu: keakuratan yang menunjukkan seberapa sering aturan tersebut benar.
Penerapannya yaitu pada angka yang menunjukkan seberapa sering aturan
tersebut dipakai.
2.1.23 Data Mining vs Online Analytical Processing (OLAP)
Data
mining
dan
OLAP
(Seidman,
Claude,
2000,
p
11)
merupakan
komponen-komponen dari Microsoft SQL Server 2000 Analysis Services. Keduanya
merupakan tools pendukung pengambilan keputusan, tetapi data mining dan OLAP
dirancang
untuk
pengguna
yang
berbeda.
OLAP
dibuat
khusus
untuk
menyimpan
data dalam bentuk tabel singkat untuk
menyediakan pemanggilan dan navigasi data
tersebut oleh end-users. Banyak pemakai yang menganggap bahwa ini adalah sebuah
solusi data mining karena pemakai dapat menemukan informasi tentang data dengan
mencari
informasi-infomasi singkat,
yang
kemudian
di
analisa
untuk
menemukan
|
 57
hubungan kausal yang lebih. Bagaimana pun juga dari banyak kasus, banyak
pemakai mencari melalui dimensi-dimensi yang berisi arti dan hubungan yang telah
dikenal dengan baik.
OLAP dapat digunakan untuk mencoba menemukan data baru. Tetapi karena
penemuan data telah diselesaikan oleh end users, dengan bantuan sebuah tool OLAP,
penemuan data akan menjadi tidak teratur dan tidak lengkap. Data mining tidak
terlalu mementingkan untuk memperbolehkan end user dengan mudah melihat data-
data yang telah terangkum, namun
lebih pada
menemukan pola dan rule baru
yang
dapat digunakan
sebagai
hasil
untuk
masa
mendatang. Jadi kesimpulan
dari
perbedaan yang
ada
adalah OLAP
merupakan suatu
mekanisme penyimpanan
dan
retrieval yang
efisien,
sedangkan data mining adalah
untuk
knowledge discovery.
(lihat tabel 2.5)
Tabel 2.5 Perbandingan OLAP dan Data Mining
OLAP
Data Mining
Aplikasinya lebih umum
Aplikasinya lebih khusus dan spesifik
dibanding OLAP
Bidang ilmu yang mempengaruhi dan
digunakan hanya untuk aplikasi
database
Bidang
ilmu
yang
mempengaruhi
dan
digunakan
meliputi
ilmu
matematika,
statistik, AI, dan lain-lain
Merupakan end-user access tool dari
data warehouse
Merupakan tahap lanjut dari OLAP
|
|
58
2.1.24 Definisi Rekayasa Piranti Lunak (Software Engineering)
Software
Engineering sebagai
suatu disiplin
teknologi
yang
terkait dengan
pemeliharaan dan produksi produk perangkat lunak secara sistematis yang
dikembangkan
dan
dimodifikasi tepat waktu
dan
dengan
perkiraan
biaya
(Fairley,
1985, p 5).
Software Engineering berbeda dengan pemrograman komputer tradisional.
teknik
pada
Software Engineering
digunakan untuk menentukan, merancang,
menerapkan,
memvalidasi dan
merawat produk software dengan batasan waktu dan
anggaran yang ditetapkan pada proyek tersebut. Kesimpulannya, Software
Engineering berhubungan dengan
masalah-masalah yang terdapat pada managerial
yang terdapat di luar wilayah pemrograman tradisional.
|
 59
2.1.25 Model – model Rekayasa Piranti Lunak (Software Engineering)
1. Linier Sequential Model (Waterfall Model)
Model ini (Pressman, 2001, p 28) mendekati ke pengembangan software yang
mulai dari tingkatan sistem dan prosesnya menuju dari analisa, rancangan,
coding, pengujian, dan pendukungan. (lihat gambar 2.13)
Gambar 2.13 Linier Sequential Model
|
 60
2. Prototyping Model
Membuat Prototyping Model (Pressman, 2001, p 31) dimulai dengan kebutuhan
yang dikumpukan. Dari pengembang lalu pelanggan
mencobanya dan kemudian
hasilnya digambarkan untuk keseluruhan sasaran hasil untuk perangkat lunak.
Lalu “rancangan cepat” kemudian terjadi. Rancangan yang cepat memusat pada
suatu penyajian aspek perangkat lunak tersebut. Itu semua yang akan dilihat oleh
pelanggan untuk membuat perangkat lunak tersebut lebih terfokus. (lihat gambar
2.14)
Gambar 2.14 Prototyping Model
|
 61
3. RAD Model (Rapid Application Development)
RAD Model (Pressman, 2001, p 33) adalah suatu pengembangan incremental
software yang memproses model yang penekanannya kepada suatu
pengembangan yang singkat.
Model RAD adalah suatu pengadaptasian yang
berkecepatan
tinggi
dan
juga
sebagai
model percontohan yang linier di mana
perkembangan yang cepat dicapai dengan penggunaan konstruksi component-
based. (lihat gambar 2.15)
Gambar 2.15 RAD Model
|
 62
4. Incremental Model
Incremental model (Pressman, 2001, p 35) menggabungkan elemen-elemen dari
linier sequential
model
dengan
filosofi
iterative dari prototyping.
Berdasarkan
gambar
di
bawah
ini,
incremental model
membutuhkan
linier
sequential
pada
tahapan
awal
sebagai progress
waktu
yang
telah
dijadwalkan.
Tiap-tiap linier
sequence
menghasilkan
“incremental”
yang
dapat disampaikan.
(lihat
gambar
2.16)
Gambar 2.16 Incremental Model
|
 63
5. Spiral Model
Spiral Model (Pressman, 2001, p 37) adalah suatu perangkat lunak evolusioner
yang
memproses
model
secara
kooperatif
dengan
membuat
prototype dengan
aspek yang sistematis dan yang dikendalikan pada
linier model. Model ini
menyediakan potensi
untuk
meningkatkan versi pada
perangkat
lunak tersebut.
(lihat gambar 2.17)
Gambar 2.17 Spiral Model
2.1.26 Definisi State Transition Diagram (STD)
State Transition Diagram (Yourdon, 1989, p 259) merupakan suatu modeling
tool yang
menggambarkan sifat ketergantungan pada waktu dari suatu sistem. Pada
awalnya
hanya digunakan
untuk
menggambarkan suatu sistem
yang
memiliki sifat
real-time.
|
 64
2.1.27 Notasi State Transition Diagram (STD)
Notasi yang digunakan (lihat gambar 2.18) pada State Transition Diagram
adalah (Yourdon, 1989, p 260):
merupakan state
merupakan event
Gambar 2.18 Notasi STD
2.1.28 Condition dan Action
Untuk
melengkapi State Transition
Diagram
diperlukan
dua
hal
lagi
yaitu
(Yourdon, 1989, p 265):
1. Condition
adalah suatu
event
pada
external
environment yang
dapat
dideteksi
oleh sistem
2.
Action
adalah
yang
dilakukan
oleh
sistem
bila
terjadi
perubahan state
atau
merupakan reaksi terhadap condition. Action akan menghasilkan output, message
display pada layar, dan juga menghasilkan perhitungan.
2.1.29 Definisi Fact-Finding
Fact-Finding adalah sebuah proses yang
menggunakan teknik-teknik seperti
interview dan
kuisioner
untuk
mengumpulkan
data-data
mengenai
sistem,
hal-hal
yang dibutuhkan dan preferensi.
|
|
65
2.1.30 Teknik Fact-Finding
Adapun teknik-teknik yang digunakan dalam Fact-Finding Connolly (2005,
p 317) adalah:
1. Memeriksa Dokumen
Dengan
memeriksa dokumen-dokumen
yang digunakan, maka bisa didapatkan
informasi
mengenai
keadaan
internal perusahaan
dan
mengenai
kebutuhan
perusahaan akan sistem yang akan dibangun. Dari analisa dokumen,
maka akan
didapat pula permasalahan yang timbul dengan sistem yang sudah ada sekarang.
2. Interview
Interview adalah teknik
fact finding yang paling banyak digunakan dan
merupakan teknik yang dapat menggali informasi paling banyak. Teknik ini
sendiri
dibagi
menjadi
2
bagian
yaitu unstructured
interviews
dan
structured
interviews, dimana kedua teknik ini dibedakan dari pertanyaan yang diajukan
kepada
responden.
Unstructured interviews
merupakan
interview
yang
pertanyaannya
dikembangkan
sendiri
oleh sang
pewancara
selama
wawancara
berlangsung.
Sedangkan
structured
interviews,
merupakan
interview yang
pertanyaannya sudah disusun sebelumnya dan ditambahkan berdasarkan jawaban
dari responden.
3. Observasi kegiatan perusahaan
Observasi adalah salah satu teknik yang paling efektif dalam menganalisa sistem.
Dengan
teknik
ini,
dimungkin
bagi pengamat
untuk
terlibat
dalam sistem atau
hanya
mengamati
seseorang
yang
melakukan
aktivitasnya
dalam memahami
sistem
tersebut.
Data
yang
diperoleh akan
sangat
berguna
dan
informatif
jika
|
|
66
data yang dikumpulkan melalui metode lain seperti pertanyaan-pertanyaan dan
penjelasan yang diberikan oleh end-users mempunyai nilai validitas yang cukup.
4. Riset / Penyelidikan
Salah satu teknik yang paling berguna adalah riset terhadap aplikasi dan masalah
yang dihadapi. Catatan transaksi komputer, buku referensi, dan internet adalah
sumber yang baik untuk mengumpulkan informasi. Dari sumber-sumber tersebut,
bisa didapat
informasi bagaimana orang atau pihak
lain
menyelesaikan
masalah
yang sama atau mirip dengan masalah yang dihadapi sekarang dan apakah
aplikasi
yang
dibangun
menyelesaikan masalah secara tuntas atau hanya
menyelesaikan sebagian masalah.
5. Kuesioner
Salah satu teknik lain yang digunakan dalam mengumpulkan data adalah melalui
kuesioner. Kuesioner adalah dokumen yang disusun dan dibuat untuk keperluan
khusus, yaitu untuk mengumpulkan data dan fakta dari sejumlah besar orang
dengan memiliki kontrol dari respon yang diberikan oleh responden. Kuesioner
sendiri
mempunyai
dua
format,
yaitu free-format
questions
dan
fixed-format
questions. Keduanya dibedakan
dari
jawaban
atau
respon
yang
bisa
diberikan
oleh
responden. Free-format questions
memberikan
keleluasaan
responden
dalam memberikan jawaban, dimana responden dapat
menuliskan jawaban
yang
mereka
berikan
di
tempat yang
sudah
disediakan.
Fixed-format questions
membatasi
keleluasaan
responden
dalam memberikan
jawaban,
dimana
responden
hanya
dapat
menjawab dengan memilih
pilihan
jawaban
yang
telah
disediakan.
|
|
67
2.2 Teori Khusus
2.2.1 Definisi Penjualan
Menurut Mulyadi (1997, p 204) “Kegiatan penjualan terdiri dari transaksi
penjualan
barang
atau jasa, baik secara
kredit
maupun
tunai”.
Dalam transaksi
penjualan kredit, jika order dari pelanggan telah dipenuhi dengan pengiriman barang
atau
penyerahan
jasa,
untuk
jangka tertentu perusahaan memiliki
piutang
kepada
pelanggannya. Kegiatan penjualan secara kredit ini ditangani oleh perusahaan
melalui
sistem
penjualan
kredit.
Dalam
transaksi
penjualan
tunai,
barang
atau jasa
baru diserahkan
oleh perusahaan kepada
pembeli
jika
perusahaan
telah
menerima
kas
dari
pembeli.
Kegiatan
penjualan
secara
tunai
ini
ditangani oleh
perusahaan
melalui
sistem penjualan
tunai.
Fungsi
penjualan
bertanggung
jawab
melayani
kebutuhan barang pelanggan, mengisi faktur penjualan kartu kredit untuk
memungkinkan fungsi gudang dan fungsi pengiriman melaksanakan penyerahan
barang kepada pelanggan.
Menurut Ikatan Akutansi Indonesia, kegiatan penjualan terdiri dari transaksi
penjualan barang dan jasa baik secara kredit maupun secara tunai; penjualan adalah
peningkatan jumlah aktiva atau penurunan kewajiban suatu badan usaha yaitu:
timbul dari penyerahan barang, jasa atau aktiva usaha lainnya di dalam suatu
periode.
Dari definisi tersebut dapat ditarik kesimpulan bahwa penjualan terjadi
apabila
ada
perpindahan dan timbulnya
suatu
klaim pembayaran
serta berasal dari
operasi
normal
perusahaan,
di
samping
itu biasanya pembelian diakui pada saat
penyerahan
barang
kepada
langganan
atau
perusahaan. Barang-barang
dipisahkan
|
|
68
secara fisik atau diberi tanda tertentu yang merupakan kepunyaan pelanggan setelah
mereka
memberikan
indikasi
ingin
membeli
atau
suatu
maksud
tegas
dari
kedua
belah pihak untuk melakukan transaksi jual beli.
Jadi kriteria penjualan terdiri dari:
1. Adanya
bukti
kuat bahwa pembeli
mempunyai
maksud
membeli
dan
penjual
mempunyai maksud menjual.
2. Penentuan mengenai barang tertentu
yang akan dijual dan dalam keadaan
siap
dijual.
3. Perjanjian antara pembeli dan penjual
mengenai
harga jual atau formula
untuk
mencapai harga jual.
2.2.2 Definisi Advertising
Advertising merupakan permasangan iklan melalui berbagai bentuk
presentasi
dan
promosi
non-pribadi
yang
dibayar
mengenai
gagasan,
barang, atau
jasa
oleh
sponsor
yang
teridentifikasi. Tujuan
pemasangan
iklan
adalah
tugas
komunikasi tertentu yang harus dilakukan terhadap khalayak sasaran tertentu selama
periode waktu tertentu. Tujuan pemasangan iklan dapat dikelompokkan berdasarkan
tujuan utamanya yaitu:
1. Menginformasikan
a. Menceritakan kepada pasar tentang produk baru.
b. Menganjurkan kegunaan baru produk tertentu.
c. Menginformasikan pasar tentang perubahan harga.
d. Menjelaskan cara kerja produk.
e. Menggambarkan layanan yang tersedia.
|
|
69
f.
Mengoreksi kesan yang salah.
g. Mengurangi ketakutan pembeli.
h. Menciptakan citra perusahaan.
2. Membujuk
a. Menciptakan preferensi merek.
b. Mendorong pergantian ke merek suatu organisasi.
c. Mengubah persepsi pelanggan tentang atribut produk.
d. Membujuk pelanggan membeli sekarang.
e. Membujuk pelanggan untuk menerima kunjungan tenaga penjualan.
3. Mengingatkan
a. Mengingatkan pelanggan bahwa produk itu mungkin diperlukan dalam waktu
dekat.
b. Mengingatkan pelanggan di mana membeli produk tersebut.
c. Mempertahankan produk tersebut tetap ada di benak konsumen selama bulan
musimnya.
d. Mempertahankan kesadaran prosuk tertinggi (top-of-mind) di benak.
2.2.3 Definisi Advertising Agency
Advertising
agency
atau
biro pemasangan
iklan
merupakan
perusahaan jasa
pemasaran yang membantu dalam merencanakan, mempersiapkan, menerapkan, dan
mengevaluasi
semua
atau
bagian-bagian
dari
program
pemasangan
iklan
mereka.
Biro pemasangan
iklan dewasa
ini
mempekerjakan para spesialis yang sering dapat
menjalankan
tugas
tugas
pemasangan
iklan
lebih
baik
daripada staf perusahaan
pemasang
iklan itu sendiri. Biro juga
membawa sudut pandang pemikiran dari
luar
|
|
70
untuk
memecahkan
masalah
perusahaan tersebut,
bersama
dengan
banyaknya
pengalaman dari bekerja dengan klien dan situasi yang berbeda-beda. Dengan
demikian, dewasa ini bahkan perusahaan yang mempunyai departemen pemasangan
iklan sendiri yang kuat masih menggunakan biro pemasangan iklan.
Kebanyakan biro pemasangan iklan besar
mempunyai
staf dan sumber daya
untuk menangani semua fase kampanye pemasangan iklan untuk klien mereka mulai
dari menciptakan rencana pemasaran sampai menciptakan kampanye
iklan dan
menyiapkan, menempatkan, dan mengevaluasi iklan. Biro biasanya mempunyai
empat departemen: kreatif, yang
menciptakan dan memproduksi
iklan; media,
yang
memilih
media
dan
memasang
iklan; riset, yang mempelajari karakteristik dan
keinginan khalayak; dan bisnis, yang menangani kegiatan bisnis biro tersebut. Tiap-
tiap
klien
atau
kelompok
klien
diawasi oleh
seorang
eksekutif
khusus,
dan
orang-
orang tiap-tiap departemen biasanya ditugasi menggarap satu atau lebih klien atau
kelompok klien.
2.2.4 Definisi Pemasaran
Pemasaran adalah suatu proses kegiatan yang dipengaruhi oleh berbagai
faktor sosial, budaya, politik, ekonomi, dan manajerial. Akibat dari pengaruh
berbagai faktor tersebut adalah masing-masing
individu
maupun
kelompok
mendapatkan kebutuhan dan keinginan dengan menciptakan, menawarkan, dan
menukarkan produk yang memiliki nilai komoditas. Terdapat dua unsur taktik
pemasaran, yaitu:
a. Diferensiasi, yang berkaitan dengan cara membangun strategi pemasaran dalam
berbagai aspek
di perusahaan.
Kegiatan
membangun
strategi pemasaran
inilah
|
|
71
yang
membedakan
diferensiasi
yang
dilakukan
suatu
perusahaan
dengan
yang
dilakukan oleh perusahaan lain.
b. Bauran pemasaran, yaitu seperangkat strategi-strategi pemasaran produk,
harga,
promosi dan tempat yang dipadukan oleh perusahaan untuk menghasilkan
tanggapan yang diinginkan dalam pasar sasaran.
|