|
BAB 2
LANDASAN TEORI
2.1. Algoritma dan Pemrograman
Dalam
matematika
dan
komputasi, algoritma
merupakan
kumpulan
perintah
untuk
menyelesaikan suatu
masalah
8)
.
Kumpulan
perintah
ini biasanya
diterjemahkan oleh
komputer secara
bertahap dari
yang
pertama
sampai
yang
terakhir
secara
sekuensial.
Masalah yang
terkait
disini
dapat
berupa
berbagai
macam masalah asalkan
masalah
tersebut memiliki kriteria
kondisi
awal
yang
harus dipenuhi sebelum menjalankan algoritma.
Kata algoritma berasal dari latinisasi nama seorang ahli
matematika dari
Usbekistan
Al
Khawarizmi
(hidup
sekitar
abad
ke-9), sebagaimana tercantum
pada
terjemahan karyanya dalam
bahasa
latin
dari
abad
ke-12
"Algorithmi
de
numero
Indorum".
Pada
awalnya kata
algoritma adalah
istilah
yang
merujuk
kepada
aturan-aturan
aritmatik
untuk
menyelesaikan persoalan
dengan
menggunakan bilangan numerik arab (sebenarnya dari India, seperti tertulis pada
judul di atas). Pada abad ke-18, istilah ini berkembang menjadi algoritma, yang
mencakup semua prosedur atau urutan langkah yang jelas dan diperlukan untuk
menyelesaikan suatu permasalahan.
Jenis-jenis
algoritma
dapat
diklasifikasikan berdasarkan
metode
yang
digunakan untuk mendesain algoritma tersebut. Menurut Cormen dan Leiserson,
6
|
|
7
disamping metoda sekuensial (Sequential Programming), terdapat empat metode
umum
yang
digunakan
dalam
mendesain
algoritma
yaitu
Divide
and
Conquer,
Dynamic Programming, Greedy Algorithms, dan Amortized Analysis. Penjelasan
dari masing – masing metoda diberikan pada sub bab berikut.
2.1.1. Divide and Conquer
Divide
and
Conquer
merupakan pendekatan algoritma
yang
membagi-bagi permasalahan ke dalam bentuk yang lebih kecil, sehingga
dapat dipecahkan secara terpisah
9)
.
Pendekatan ini
memecahkan masalah
ke dalam sub-masalah yang mirip namun dengan ukuran yang lebih kecil,
untuk
kemudian
dapat
dipecahkan
secara
rekursif
(perulangan). Hasil
pemecahan
tiap-tiap sub-masalah kemudian digabungkan kembali untuk
mendapatkan solusi masalah secara keseluruhan.
Pendekatan
Divide and Conquer memiliki
tiga
langkah
umum
pada
setiap
tingkat
perulangan, yaitu
Divide,
Conquer,
dan
Combine.
Contoh
umum
dari
penggunaan pendekatan
ini
dalah
dalam
algoritma
Merge Sort. Pada algoritma
Merge Sort, banyaknya
angka yang ada
dibagi dengan pembagi dua (Langkah Divide). Kemudian urutkan angka-
angka
tersebut
pada
tiap
sub-masalahnya
(Langkah Conquer).
Setelah
angka-angka
tersebut terurut, gabungkan
dengan sub-masalah lainnya
agar membentuk solusi umum (Langkah Combine).
|
|
8
Menggunakan
pendekatan
Divide
and
Conquer
memiliki
keuntungan sebagai berikut :
-
Dapat memecahkan masalah yang sulit.
Divide
and
Conquer
merupakan cara
yang
sangat
efektif
untuk
menyelesaikan masalah
yang
rumit.
Contoh
lain
yang
memerlukan
pendekatan ini
adalah penyelesaian Tower
of
Hanoi. Pada
Tower
of
Hanoi, akan lebih efektif untuk memecahkan masalah adalah dengan,
menyelesaikan
masalah dan kemudian
menggabungkannya, daripada
menyelesaikan
secara sekuensial
tanpa
memecahkan ke
dalam
sub-
masalah terlebih dahulu.
-
Memiliki efisiensi algoritma yang tinggi.
Pendekatan Divide
and
Conquer
juga
memiliki
efisiensi
algoritma
yang cukup
tinggi. Contohnya, jika ukuran
masalah n
memiliki sub-
masalah
p
dengan
ukuran
n/p
pada
tiap
perulangannya, maka
kompleksitas algoritma untuk ukuran waktu konstan O akan menjadi
O
(
n
log n
)
. Cara ini lebih efisien dalam menyelesaikan algoritma
sorting yang memiliki kompleksitas algoritma
O
(
n
2
)
jika dijalankan
dengan algoritma sekuensial.
-
Dapat bekerja secara paralel.
Divide and Conquer telah didisain untuk dapat bekerja dalam mesin-
mesin yang memiliki banyak prosesor. Terutama
mesin yang
|
|
9
memiliki
sistem
pembagian
memori,
dimana
komunikasi data
antar
prosesor
tidak
perlu
direncanakan terlebih
dahulu,
hal
ini
karena
pemecahan sub-rutin dapat dilakukan di prosesor lainnya.
-
Akses memori yang cukup kecil.
Untuk
akses
memori, Divide
and
Conquer
dapat
meningkatkan
efisiensi memori
yang
ada
cukup
baik.
Hal
ini
karena,
sub-rutin
memerlukan memori
lebih
kecil
daripada
masalah
utamanya.
Disamping
itu,
Divide
and
Conquer hanya
memerlukan satu
bagian
memori
untuk
menyelesaikan sub-rutin
sub-rutin
tersebut
(karena
berupa
perulangan dan
sudah
memiliki
pesanan
memori
untuk
variabel-variabelnya).
Kerugian
–
kerugian
menggunakan
pendekatan
Divide and
Conquer adalah:
-
Lambatnya proses perulangan
Proses pemanggilan sub-rutin yang berlebih, sehingga call stack
penuh
dari
beberapa sub-rutin tersebut. Hal
ini
dapat
menjadikan
beban
yang
cukup signifikan pada prosesor.
Misalnya
pengulangan
yang terus menerus pada sub-rutin
yang cukup banyak, sehingga
dapat memperlambat proses pengulangan.
|
|
10
-
Lebih rumit untuk masalah yang sederhana
Untuk
pemecahan masalah
yang
relatif
sederhana,
algoritma
sekuensial terbukti lebih mudah dibuat daripada algoritma divide and
conquer.
Hal
ini disebabkan karena algoritma sekuensial tidak perlu
melalui ketiga langkah yang dilakukan oleh divide and conquer.
Salah
satu
contohnya ialah,
untuk
menambah
n-banyak
bilangan,
perulangan sederhana
akan
lebih
mudah
dibuat
daripada
harus
memecah
n-bilangan
tersebut,
menambahkannya satu sub-rutin
demi
satu sub-rutin, kemudan menjumlahkan hasil dari sub-rutin tersebut.
2.1.2. Dynamic Programming
Seperti metoda Divide and Conquer, Dynamic Programming juga
menyelesaikan
masalah
dengan
cara
menggabungkan solusi-solusi
dari
penyelesaian
subrutin-subrutinnya¹
)
. Perbedaan
pokok
Dynamic
Programming
dapat
digunakan
saat
subrutin-subrutinnya tidak
independen,
yaitu,
saat subrutinnya
membagi
sub-subrutin. Dalam
konteks ini, Divide and Conquer memerlukan langkah yang lebih banyak
daripada
Dynamic Programming,
karena
harus
mengerjakan subsubrutin
yang mirip berkali-kali. Pada Dynamic Programming, setiap subsubrutin
hanya dijalankan sekali untuk kemudian disimpan nilainya didalam tabel,
sehingga dapat mempersingkat waktu kerja.
|
|
11
Dynamic
Programming
biasanya
diaplikasikan pada
masalah
optimisasi. Masalah seperti ini dapat memiliki banyak solusi. Setiap
solusi
memiliki
nilai-nilai
yang
berbeda. Disinilah
tugas
Dynamic
Programming
untuk
mencari solusi
yang paling optimal. Pengembangan
Dynamic
Programming
dapat
dipecah menjadi empat
langkah utama,
yaitu:
1. Menyusun struktur solusi optimal.
2. Secara rekursif tentukan nilai dari solusi optimal tersebut.
3. Hitung nilai solusi optimal dengan cara bottom-up.
4. Buat solusi optimal dari informasi-informasi tersebut.
Keuntungan Dynamic
Programming
adalah
bahwa
metode
ini
dapat
mempersingkat
waktu
yang
sangat
signifikan bagi
masalah
yang
memiliki
lebih
dari
satu
solusi,
karena
dapat
menemukan solusi
yang
optimal.
Sedangkan
kerugiannya adalah bahwa
Dynamic
Programming
juga
memerlukan
waktu
yang relatif lebih
lama saat
memecahkan
masalah dengan subrutin yang relatif sedikit.
Salah satu contoh permasalahan yang
memerlukan solusi optimal
adalah
pencarian
angka
ke-n
dari
deret
Fibonacci,
yang
beradasarkan
pada definisi matematis:
function fib(n)
if n = 0 or n = 1
return n
|
|
12
else
return fib(n - 1) + fib(n - 2)
Jika pada rumus diatas dipanggil fib(5), akan ada banyak
fungsi
yang sama yang dipanggil berkali-kali:
1.
fib(5)
2.
fib(4) + fib(3)
3.
(fib(3) + fib(2)) + (fib(2) + fib(1))
4.
((fib(2)
+
fib(1))
+
(fib(1)
+
fib(0)))
+
((fib(1)
+
fib(0)) + fib(1))
5. (((fib(1)
+
fib(0))
+
fib(1))
+
(fib(1)
+
fib(0)))
+
((fib(1) + fib(0)) + fib(1))
Pada umumnya, fib(2) dihitung dua kali (pada no. 3). Pada contoh
yang
lebih besar, banyak fungsi
fib(n), atau subrutin, yang dikomputasi
ulang, sehingga memerlukan waktu yang cukup besar. Jika menggunakan
Dynamic Programming,
maka
nilai
fib(2)
hanya
perlu
dilakukan
sekali
dimana nilai
tersebut kemudian akan ditampung di satu
tabel yang
akan
dipanggil kembali jika menemukan kasus serupa. Fungsi hasilnya
hanya
memerlukan
kompleksitas
O(n)
daripada
menggunakan sekuensial,
maupun Divide and Conquer.
|
|
13
2.1.3. Greedy Algorithms
Algoritma yang
digunakan untuk
optimalisasi
solusi
biasanya
melewati beberapa langkah, dengan pilihan-pilihan di setiap langkahnya.
Untuk
banyak
masalah
yang
memerlukan optimalisasi solusi,
menggunakan Dynamic
Programming
akan
membuang
banyak sumber
daya
(memori
dan
waktu).
Greedy
Algorithm
merupakan metode
yang
akan
selalu
memilih
pilihan
yang
terbaik di
setiap
langkahnya. Greedy
Algorithm
selalu
memilih
pilihan
optimal pada
setiap
langkahnya
yang
berpeluang
tinggi
untuk
menjadi
pilihan
terbaik
seterusnya. Contoh
masalah
yang
dapat
diselesaikan dengan
Greedy
Algorithm
adalah
Minimum Spanning Tree, Dijkstra’s Algorithm untuk jalan terpendek dari
satu sumber, dan Chvatal Greedy Set-Covering Heuristic.
2.1.4. Amortized Analysis
Dalam
Amortized
Analysis,
waktu
yang
diperlukan untuk
memproses
struktur-data
terurut
dirata-ratakan dari
semua
operasi.
Amortized
Analysis
dapat
digunakan
untuk
menunjukkan bahwa
nilai
operasi
rata-rata
cukup
kecil,
walaupun ada
beberapa
operasi
yang
memiliki nilai besar. Metoda
ini
cukup
berguna
untuk
menghitung nilai
sumber daya yang terbuang secara keseluruhan.
|
|
14
2.2. Kecerdasan Buatan (Artificial Intelligence)
Kecerdasan buatan
atau
Artificial
Intelligence
(AI)
adalah
salah
satu
cabang
ilmu
komputer
yang
berhubungan dengan
tingkah
laku
yang
pintar,
belajar dan dapat beradaptasi pada mesin²
)
. Penelitian pada Artificial
Intelligence dipusatkan pada
penghasilan mesin yang
mengotomatisasikan
tugas-tugas
yang
memerlukan tingkah
laku
yang
pintar.
Contohnya
kontrol,
perencanaan
dan
penjadwalan, kemampuan
menjawab
diagnostik
dan
pertanyaan-pertanyaan pelanggan,
handwriting,
suara
dan
pengenalan
wajah.
Untuk
itu,
Artificial Intelligence
telah
menjadi disiplin
ilmu,
difokuskan
pada
penyediaan solusi
masalah-masalah kehidupan
nyata, aplikasi software,
game
strategi seperti catur komputer dan video game lainnya.
2.2.1. Klasifikasi Ilmu Artificial Intelligence
Artificial
Intelligence
dibagi
dalam
dua
bidang studi
yaitu:
Artificial Intelligence Konvensional dan Computational Intelligence (CI).
Artificial
Intelligence
Konvensional terutama
meliputi
metode
yang
diklasifikasikan sebagai mesin yang belajar (machine learning), dicirikan
dengan
analisis
statistika. Ini
juga
dikenal
sebagai
simbolik Artificial
Intelligence,
logikal Artificial
Intelligence,
neat
Artificial
Intelligence
(menyatakan solusi
harus
luwes, jelas
dan
benar)
dan
Good
Old
Fashioned Artificial Intelligence (GOFAI). Metodenya meliputi :
-
Sistem Pakar (Expert System):
menerapkan kemampuan menalar
untuk
mencapai kesimpulan. Sebuah sistem pakar dapat
memproses
|
|
15
sejumlah
besar
informasi
yang
diketahui
dan
menyediakan
kesimpulan berdasarkan informasi tersebut.
-
Case based reasoning : merupakan proses penyelesaian masalah baru
berdasarkan pada solusi dari masalah lampau yang serupa. Case
based
reasoning
dapat
disebut
juga
menganalogikan masalah
yang
mirip dengan masalah lampau.
-
Bayesian networks : merupakan
grafik
asiklik
tertuju
dimana
tiap
node-nya
mewakilkan satu
variabel, dan
garis penghubung tiap node
disebut
hubungan
ketergantungan
statistik
diantara
variabel
tersebut
dan
nilai
distribusi
probabilitas
lokal
untuk
tiap
variabel
yang
diberikan dari node sebelumnya.
-
Behavior based Artificial Intelligence : merupakan kecerdasan buatan
dimana kecerdasannya dibuat dari banyak elemen modul yang relatif
sederhana dalam
membuatnya. Setiap
elemen
berfungsi
hanya
pada
konteks khusus, yang hanya dikenali oleh modul tersebut.
Computation
Intelligence
meliputi
pengembangan iterative
atau
belajar. Pembelajaran didasarkan pada
kumpulan data-data empiris
yang
dihubungkan dengan kecerdasan buatan
non-simbolik. Beberapa metode
pembelajaran tersebut adalah sebagai berikut:
-
Neural Network: sistem dengan kemampuan pengenalan pola.
|
|
16
-
Fuzzy System:
teknik untuk
menalar dibawah ketidakpastian, secara
luas
digunakan pada
industri
modern
dan
sistem
kontrol
produk
konsumen.
-
Evolutionary computation: menerapkan konsep
yang terinspirasi dari
permasalahan
biologi
seperti
populasi,
mutasi
dan
survival of the
fittest
untuk
menghasilkan solusi
yang
lebih
baik.
Metode
ini dapat
dibagi
lagi
menjadi
evolutionary
algorithm
(contoh
genetic
algorithm) dan swarm intelligence (contoh ant algorithm).
Dengan
hybrid
intelligent
system
berusaha untuk
membuat
kombinasi dari dua
group
ini. Aturan kesimpulan pakar dapat dihasilkan
melalui neural
network atau aturan produksi dari
pembelajaran statistika
seperti
ACT-R.
Otak
manusia
menggunakan multiple
teknik
untuk
bersama-sama
memformulasikan dan
menghasilkan
cross-check.
Jadi,
integrasi
terlihat
menjanjikan dan
mungkin
perlu
dalam
artificial
intelligence yang sebenarnya.
Satu
metode
baru
yang
menjanjikan disebut
intelligence
amplification,
dimana
mencoba
mencapai tingkat
artificial
intelligence
dalam
proses
pengembangan yang
evolusioner
sebagai
penjelasan
kecerdasan manusia melalui teknologi.
|
|
17
2.2.2. Pengunaan artificial intelligence pada Bisnis
Bank
menggunakan sistem
kecerdasan
buatan
untuk
mengorganisasikan operasi,
penanaman
saham
dan
mengatur
properti.
Pada
agustus
2001,
robot
melebihi manusia dalam
simulasi
kompetisi
pertukaran keuangan
(BBC
news,
2001).
Klinik
medikal
dapat
menggunakan sistem
kecerdasan
buatan
untuk
mengatur
dan
menjadwalkan, membuat
rotasi
pegawai
dan
menyediakan
informasi
secara
periodik.
Banyak
juga
aplikasi
tergantung pada
jaringan
syaraf
tiruan
(ANN
–
artificial
neural
network),
yaitu jaringan
yang
mempolakan organisasi
dalam
cara
meniru
otak
manusia.
Aplikasi
ini
mempunyai banyak
kebaikan
dalam
hal
pengenalan pola.
Institusi
keuangan
telah
lama
menggunakan
sistem
seperti
ini
untuk
mendeteksi
klaim di luar kewajaran. ANN juga digunakan secara luas pada homeland
security,
suara dan pengenalan teks, diagnosis
medical, data
mining dan
e-mail
spam
filtering.
Homeland
security
mempunyai fungsi
untuk
mencegah, mendeteksi, menanggapi dan
memperbaiki suatu tingkah laku
kegiatan seperti teroris dan juga bencana alam.
Robot
juga
telah
umum
digunakan di
banyak
industri.
Mereka
sering diberikan pekerjaan yang dipertimbangkan berbahaya bagi
manusia.
Robot
juga
terbukti efektif
pada
pekerjaan
yang
sangat
repetitive
yang
mungkin
menyebabkan kesalahan atau
kecelakaan
tugas
karena kehilangan konsentrasi, jika dikerjakan oleh manusia. Contohnya
|
|
18
General
Motor (GM)
menggunakan 16.000
robot
untuk
tugas
painting,
welding
dan
assembly.
Jepang
merupakan negara
pemimpin
dalam
penggunaan robot,
dari
data
yang
didapat
pada
1995,
700.000
robot
digunakan secara luas diseluruh dunia dan lebih dari 500.000 berasal dari
Jepang (Encarta, 2006).
2.3. Pengenalan Suara
Pengenalan suara (Voice recognition atau dikenal juga sebagai automatic
speech recognition, computer speech recognition) adalah proses mengubah
sinyal
suara
ke
kalimat
(text)
11)
.
Dalam
hal
ini
diperlukan algoritma
yang
diimplementasikan
pada program komputer untuk menjalankan perintah
tersebut. Aplikasi pengenalan suara muncul beberapa tahun yang lalu termasuk
voice
dialing,
data
entry
sederhana
(contoh
memasukkan
nomor
kartu
kredit)
dan menyediakan dokumen terstruktur (contoh laporan radiologi).
2.3.1. Kinerja Sistem Pengenalan Suara
Sistem
pengenalan suara,
tergantung
pada
beberapa
faktor,
dapat
memiliki rentang kinerja yang diukur dari rata-rata error kalimat. Faktor-
faktor
ini
termasuk
lingkungan, rata-rata
berbicara,
konteks
(atau
tata
bahasa) yang digunakan dalam pengenalan.
Kebanyakan pengguna
pengenalan
suara
cenderung
setuju
bahwa
mesin
perintah
dapat
mencapai
kinerja
yang
tinggi
pada
kondisi
|
|
19
terkontrol. Bagian yang membingungkan terutama datang dari campuran
penggunaan istilah pengenalan suara dan pendiktean.
Sistem pendiktean memerlukan periode pendek pelatihan yang dapat
menangkap
suara
yang
berlanjutan dengan
kosakata
yang
luas
dengan
akurasi
yang
tinggi. Kebanyakan
perusahaan
komersial
mengklaim
bahwa
software
pengenalan dapat
mencapai
antara
98%
sampai
99%
keakuratannya jika
beroperasi
pada
kondisi
yang optimal.
Kondisi
optimal
ini
berarti
pengetesan
subjek
memiliki
1)
karakteristik
speaker
yang
cocok
dengan
data
training,
2)
pembicara yang
sama,
dan
3)
lingkungan yang
tenang
(tanpa
noise).
Inilah
penyebab
mengapa
pada
kebanyakan pengguna,
menemukan kinerja
rata-rata
pengenalan lebih
rendah dari
98%
sampai 99%.
Keterbatasan
yang
lainnya
adalah
kosakata,
sistem tanpa
pelatihan
hanya
dapat
mengenali sejumlah
kecil
kalimat dari beberapa pembicara.
2.3.2. Formula Noisy Channel pada Statistika Pengenalan Suara
Banyak
metode
modern
seperti
sistem
pengenalan suara
HMM
(Hidden Markov Model) berdasarkan formulasi noisy channel. Metoda ini
menyatakan bahwa
tugas
dari
sistem
pengenalan
suara
untuk
mencari
rangkaian kata
yang
mirip
untuk sinyal akustik yang diketahui. Dengan
kata
lain,
sistem
mencari
rangkaian
kata
diantara
semua
kemungkinan kata dari rangkaian W* sinyal akustik A. Menurut Hidden
|
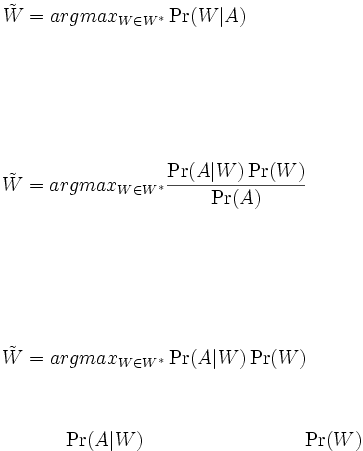 20
Markov Model terminologi disebut rangkain observasi. Model tersebut
adalah :
............(2.1)
Berdasarkan aturan Bayes, formula diatas dapat ditulis ulang sebagai :
..............(2.2)
Sinyal akustik umumnya pada pemilihan rangkaian kata, maka
formula diatas dapat disederhanakan menjadi :
................(2.3)
Dimana :
disebut model akustik.
dikenal
sebagai model bahasa.
Pemodelan akustik dan pemodelan bahasa penting untuk dipelajari
pada statistika pengenalan suara. Pada skripsi ini akan fokus pada
penjelasan penggunaan hidden Markov Model (HMM) karena digunakan
pada banyak sistem secara luas.
|
|
21
2.4. Pengenalan Percakapan
Speech
Recognition
atau
pengenalan percakapan adalah
proses
yang
mengkonversi sinyal
percakapan
menjadi
kata-kata
teridentifikasi, dengan
melalui
serangkaian
algoritma
12)
.
Aplikasi-aplikasi
yang terlahir
dari
teknologi
tersebut adalah voice
dialing
(contohnya
“call home”), call routing
(contohnya
“I would like to make a collect call”), simple data entry, dan persiapan membuat
dokumen terstruktur.
2.4.1. Sejarah Pengenalan Percakapan
Penelitian
dalam
Pengenalan Percakapan
Otomatis
(Automatic
Speec Recognition—ASR) sudah dimulai lebih dari 60 tahun
yang lalu
5)
.
Percobaan pertama
untuk
membuat
sistem
ASR
dengan
mesin
berlangsung pada
tahun
1950an,
saat
banyak
peneliti
berusaha
mengeksploitasi ide-ide mendasar dari
fonetika akustik. Pada tahun 1952
di Laboraturium Bell, Davis, Biddulph, dan Balashek membangun sebuah
sistem untuk mengenali digit yang diucapkan oleh satu pembicara. Sistem
tersebut bekerja dengan cara mengukur resonansi spektral di daerah vokal
pada
tiap
digitnya. Dengan
usaha
mandiri di
RCA
Laboratories pada
tahun
1956,
Olson
dan
Belar
mencoba
untuk
mengenali 10
suku
kata
berbeda pada satu pembicara, yang kemudian diwujudkan dalam 10 kata
dengan suku kata satu (monosyllabic words). Sistem tersebut juga bekerja
dengan pengukuran spektral
terutama di
daerah
vokal. Pada tahun 1959,
pada
sebuah Universitas di
Inggris, Fry
dan
Denes
mencoba membuat
|
|
22
pengenal
fonem
untuk
mengenali 4
vokal
dan
9
konsonan.
Mereka
menggunakan Spectrum
Analyzer
dan
pattern
matcher
untuk
membuat
keputusan
pengenalan. Aspek
yang
tergolong
baru
dalam penelitian
ini
adalah
penggunaan informasi
statistik
tentang
urutan
fonem
di
Inggris
yang
diperbolehkan (sintaks
bahasa
yang
belum
sempurna).
Kasusnya
adalah
untuk
meningkatkan akurasi
fonem keseluruhan
untuk kata-kata
yang terdiri dari dua fonem atau lebih. Usaha
lain yang dilakukan dalam
periode ini adalah pengenal vokal dari Forgie and Forgie, yang dibuat di
MIT Lincoln Laboratories pada
taun
1959, yang
mana
mengenali 10
vokal
yang
melekat
dalam
format
/b/-vokal-/t/ tanpa
tergantung
pada
pembicaranya. Pada
sistem
ini
digunakan
Filter
Bank
Analyzer
untuk
menghasilkan
informasi
spektral,
dan estimasi
variasi waktu dari
resonansi pernapasan manusia dibuat untuk menentukan vokal mana yang
dibicarakan.
Pada tahun 1960an beberapa ide-ide mendasar dalam pengenalan
percakapan
bermunculan
dan
dipublikasikan. Namun,
ide-ide
tersebut
berawal di Jepang saat beberapa peneliti Jepang
membuat special-
purpose
hardware
sebagai
bagian
dari
sistemnya. Satu sistemnya,
yang
dibuat oleh Suzuki dan Nakata dari Lab Radio Research di Tokyo, adalah
perangkat keras
pengenal
vokal.
Sistem
tersebut
menggunakan
elaborated
filter
bank
spectrum
analyzer
yang
menghubungkan semua
output
dari
tiap
kanal
analis
spektrum (dengan
diberi
nilai)
ke
sirkuit
|
|
23
vowel-decision.
Disini
menggunakan skema
logis
keputusan
mayoritas
yang
digunakan
untuk
memilih
vokal
yang
diucapkan. Perangkat
keras
Jepang
lainnya
yang dibuat oleh
Doshita
dari
Universitas Kyoto
pada
tahun 1962 adalah pengenal fonem. Dalam perangkat keras ini,
diperlukan
pembagi
percakapan dengan analisis zero-crossing
dari
banyak
daerah
berbeda
di
suara
input
untuk
menghasilkan
output
yang
terkenali. Usaha
orang
Jepang
yang
ketiga
adalah
perangkat
keras
pengenal
digit
dari
Nagata
di
Laboratorium NEC
pada
tahun
1963.
Perangkat
keras
ini
merupakan
yang
paling
terkenal
sebagai percobaan
pertama dalam pengenalan percakapan di NEC dan merupakan awal dari
program riset yang lama dan sangat produktif.
Sekitar tahun 1960an dibuat tiga proyek yang berdampak sangat
besar dalam penelitian dan pengembangan pengenalan percakapan selama
20 tahun terakhir. Proyek pertama adalah
hasil usaha Martin dan teman-
temannya di
Laboratorium RCA, yang dimulai pada akhir 1960an.
Proyek
ini
mengembangkan solusi
realistis
untuk
permasalahan
yang
berhubungan
dengan
ketidakseragaman skala
waktu
pada
kasus-kasus
percakapan.
Martin
mengembangkan
beberapa
metoda
normalisasi-
waktu,
berdasarkan pada
kemampuan
untuk
mendeteksi
awal
dan
akhir
percakapan, yang secara signifikan
mengurangi variasi
nilai pengenalan.
Martin
mengembangkan metode
tersebut
dan
berhasil
mempublikasikan
produk pengenalan
percakapannya
dengan
dibantu
oleh
Threshold
|
|
24
Technology Company. Pada saat itu pula, di The Soviet Union, Vintsyuk
mengusulkan penggunaan
metode
dynamic
programming
untuk
menyamaratakan waktu
pada
sepasang
ungkapan,
yang
kemudian
dinamakan metoda
dynamic
time
warping.
Walaupun
inti
dari
konsep
dynamic time warping dikembangkan di dalam proyek Vintsyuk, namun
proyek
ini tidak terdengar sampai ke belahan bumi
bagian barat
hingga
awal
1980an,
dimana
metode-metode formal
sudah
diusulkan
dan
diimplementasikan oleh peneliti lain.
Karya
sukses
terakhir pada
tahun 1960an adalah
penelitian
perintis dari
Reddy
di
bidang
pengenalan percakapan kontinyu dengan
penelusuran dinamis
fonem-fonem.
Penelitian
Reddy
selanjutnya
berkembang menjadi program riset pengenalan percakapan di Universitas
Carnegie
Mellon
yang
sampai
saat
ini
merupakan pemimpin
sistem
pengenalan percakapan kontinyu.
Pada
tahun
1970an,
riset
pengenalan
percakapan
meraih banyak
pengembangan-pengembangan.
Pertama
pengembangan
di
bidang
kata
terisolasi atau pengenalan ungkapan diskrit oleh Velichko dan Zagoruyko
di Russia, Sakoe dan Chiba di Jepang, dan Itakura di Amerika. Velichko
dan
Zagoruyko
mempelajari
pengembangan ide-ide
pengenalan-pola
dalam
pengenalan
percakapan. Chiba
dan
Sakoe
meneliti
bagaimana
Dynamic
Programming
dapat diaplikasikan dengan baik. Penelitian
|
|
25
Itakura menunjukkan ide Linear Predictive Coding (LPC), yang pada saat
itu sudah pernah digunakan dalam Low-bit-rate Speech Coding, dan
dapat
dikembangkan dalam
sistem
rekognisi
percakapan
melalui
penggunaan pengukuran jarak teratur berdasarkan parameter spektral
LPC.
Pengembangan
lain di
tahun 1970an
adalah
awal dari
penelitian
panjang
dalam
pengenalan percakapan di
IBM
dimana
para
peneliti
mempelajari
tiga
tugas
berbeda
selama
hampir
dua
dekade.
Tiga
tugas
tersebut adalah
:
New
Raleigh
Language
untuk
operasi basis
data
sederhana, The Laser Patent Text Language untuk merekam paten laser,
dan tugas korespondensi kantor, serta Tangora, untuk pengucapan memo
sederhana.
Pada AT&T Bell
Labs, peneliti memulai serangkaian eksperimen
yang bertujuan
membuat sistem rekognisi percakapan yang benar-benar
tidak
tergantung
pada
pembicaranya. Untuk
mencapainya,
algoritma
clustering
digunakan
untuk
menentukan beberapa
pola
berbeda
yang
diperlukan
untuk
merepresentasikan semua variasi kata-kata berbeda
pada
populasi
pengguna
yang
luas.
Penelitian ini
telah
dikembangkan
selama
lebih dari 10
tahun sehingga tehnik untuk
membuat pola bebas-
pembicara (Independent Speaker) saat ini dapat digunakan dengan bebas.
|
|
26
Setelah rekognisi kata terisolasi menjadi kunci fokus riset di tahun
1970an,
masalah
rekognisi
kata
tersambung
menjadi
fokus riset
pada
tahun 1980an. Tujuannya adalah untuk
menciptakan sistem kokoh
yang
mampu mengenali
serangkaian kata-kata
yang diucapkan
dengan
lancar
berdasarkan
pada
penyesuaian
pola-pola
berkesinambungan pada
kata-
kata
individu.
Banyak
algoritma
pengenalan kata
tersambung
yang
diformulasikan dan diimplementasikan, diantaranya :
-
pendekatan pemrograman dinamis dua-tingkat oleh Sakoe di Nippon
Electric Corporation (NEC)
-
metode one-pass oleh Birdle dan Brown di Joint Speech Research
Unit (JSRU) di Inggris
-
pendekatan
pembangunan tingkat oleh
Myers
dan
Rabiner
di
Bell
Labs, dan
-
pendekatan pembuatan tingkat singkronisasi kerangka oleh
Lee dan
Rabiner di Bell Labs.
Tiap
prosedur
penyesuaian ‘optimal’
ini
memiliki
keuntungan
implementasinya masing-masing, yang dieksploitasi untuk banyak tugas.
Penelitian percakapan pada tahun 1980an dicirikan dengan adanya
pergeseran teknologi dari pendekatan berdasarkan cetakan (template)
ke
metoda modeling statistikal—terutama pendekatan
Hidden Markov
Model
(HMM).
Walaupun
metodologi HMM
dapat
dipahami
oleh
beberapa
laboratorium (terutama
IBM, Institute
for Defense
Analyses
|
|
27
(IDA), dan
Dragon Systems),
namun
belum
dapat
disebarluaskan
sebelum pertengahan tahun 1980an, dimana pada saat itu tehnik ini telah
diaplikasikan
ke
seluruh
laboratorium riset
pengenalan
percakapan
di
dunia.
Teknologi ‘baru’
lainnya
yang dikenalkan di
akhir tahun 1980an
adalah
ide
atau
gagasan
mengaplikasikan
jaringan
syaraf
tiruan
(JST)
atau
Artificial
Neural
Network
(ANN)
pada
permasalahan pengenalan
percakapan.
JST pertama
kali dikenalkan
pada tahun
1950an,
namun
tidak
pernah
terbukti
berguna
karena
memiliki banyak
masalah
dalam
prakteknya. Namun,
pada tahun 1980an, pemahaman
mendalam tentang
keuntungan
dan
kerugian
dari
JST
dipelajari,
sebagaimana dengan
hubungan teknologi
tersebut
dengan
metode
klasifikasi sinyal
klasik.
Beberapa cara baru untuk mengimplementasikan sistem juga dikenalkan.
Tahun
1980an
merupakan dekade
dimana
motivasi
utama
diberikan untuk mengembangkan sistem pengenalan percakapan kontinyu
oleh komunitas Defense Advanced Research Projects Agency (DARPA).
Sponsor
program riset
besar
ini
bertujuan
meraih akurasi
tinggi
untuk
pengenalan percakapan kontinyu
1000
kata.
Kontribusi riset
utama
dihasilkan oleh CMU (juga dikenal dengan SPHINX System), BBN
dengan
Bylos System,
Lincoln Labs,
SRI,
MIT,
dan
AT&T
Bell
Labs.
Program
DARPA berlanjut sampai tahun 1990an, dengan pergeseran
|
|
28
tekanan kepada bahasa
natural di
pengenalnya. Pada
waktu
yang sama,
teknologi pengenalan percakapan telah banyak digunakan dalam jaringan
telefon
untuk
mengotomasikan juga
mengembangkan servis-servis
operator.
2.4.2. Hidden Markov Model
Hidden Markov Model (HMM) merupakan pendekatan yang dapat
mengelompokkan sifat-sifat spektral dari tiap bagian suara pada beberapa
pola
4)
.
Teori
dasar
dari
HMM
adalah
dengan
mengelompokkan sinyal
suara sebagai proses parametrik acak, dan parameter proses tersebut
dapat dikenali (diperkirakan) dalam akurasi yang tepat.
2.4.2.1.Arsitektur Hidden Markov Model
Diagram
dibawah
menunjukkan
arsitektur
umum dari
HMM,
seperti disajikan pada gambar 2.1. Tiap bentuk oval mewakili variabel
random yang dapat
mengambil nilai.
Variabel
random x(t) yaitu
nilai
dari
variabel
tersembunyi
pada
waktu
t.
Variabel
random
y(t)
yaitu
nilai
variabel
yang
diteliti
pada
waktu
t.
Tanda panah
pada
diagram
menunjukkan ketergantungan kondisi.
|
 29
Gambar 2.1 Evolusi temporal dari hidden Markov model
Dari
diagram,
ini
jelas
bahwa
nilai
variabel
tersembunyi
x(t)
(pada waktu t) hanya tergantung pada nilai variabel tersembunyi x(t-1)
(pada
waktu
t-1).
Serupa, nilai
variabel yang
diteliti
y(t)
hanya
tergantung pada nilai
variabel tersembunyi x(t) (keduanya pada waktu
t).
2.4.2.2.Implementasi HMM pada Pengenalan Suara
4)
Salah
satu
implementasi HMM
yang
digunakan
pada
skripsi
ini
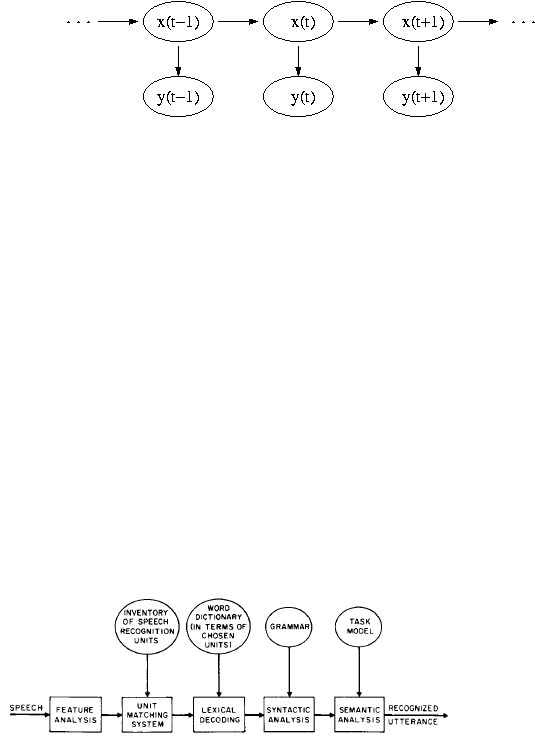
adalah implementasi HMM pada sistem pengenalan suara. Diagram blok
disajikan pada
gambar 2.2. Gambar tersebut
menunjukkan diagram blok
dari pendekatan pengenalan pola pada sistem pengenalan suara kontinyu.
Gambar 2.2 Diagram Blok Pengenalan Suara Kontinyu
|
|
30
Langkah-langkah pengenalan
pola
secara
umum
dapat
dijelaskan
sebagai berikut:
Suara
yang
menjadi input
pada
Gambar
2.2
akan
melalui
proses
Feature
Analysis
yang
memfilter suara
input
menjadi
spektral-spektral
suara. Setelah
melalui proses Feature
Analysis,
spektral suara kemudian
akan
dipecah
menjadi suku
kata-suku kata pada proses
Unit
Matching
System.
Pada
proses
Unit
Matching
System,
sistem akan
membaca
database suku kata untuk kemudian dicari suku kata-suku kata yang mirip
dengan spektral suara input. Pada Lexical Decoding, tiap suku kata yang
terdapat di Unit Matching System disusun menjadi kata berdasarkan Word
Dictionary. Pada Synctactic
Analysis, tiap kata
yang
terdapat di Lexical
Decoding
disusun
menjadi
frase berdasarkan database
frase Grammar.
Dengan
berdasarkan pada
database
Task
Model,
Semantic
Analysis
memungkinkan pembentukan
kalimat
dari
frase-frase
yang
ada
di
Syntactic Analysis.
Sedangkan pengertian dari tiap-tiap proses adalah sebagai berikut:
a. Feature Analysis
Merupakan analisis spektral dan atau temporal dari sinyal
suara
yang dilakukan
untuk mengobservasi vektor yang
akan
digunakan untuk
melatih
HMM
yang
mengelompokkan
berbagai suara percakapan.
|
|
31
b. Unit Matching System
Unit
Matching
System
bertugas
menyamakan
semua
bagian-
bagian percakapan unit dengan input percakapan. Teknik
untuk
memberikan nilai
kesesuain,
dan
menentukan nilai
pasangan terbaik
(subyek
ke
leksikal
dan
batasan
sintaktik
sistem) termasuk tumpukan prosedur dekoding, dan prosedur
penilaian akses leksikal. Kemungkinan dapat memuat unit
sub-kata
linguistik
seperti phones, diphones, demisyllables,
dan
syllables,
juga
unit derivasinya seperti fenemes,
fenones,
dan
unit
akustik. Kemungkinan lain
juga
meliputi
unit
kata
keseluruhan,
dan
bahkan
unit
yang
berkorespondensi ke
kelompok 2 atau lebih kata (frase dan preposisi seperti and an,
in
the,
of
a,
dll).
Secara
umum,
makin
sederhana unitnya
(contohnya phones),
maka
makin
sedikit
dari
mereka
yang
berada
di
dalam
bahasa,
dan
makin
kompleks
strukturnya
di
percakapan kontinyu.
Untuk
rekognisi
suara
skala
besar
(menggunakan
lebih dari 1000 kata), penggunaan
sub-kata
unit
percakapan semakin
dibutuhkan karena
sulit
untuk
merekam set
pelatihan
yang cukup
untuk mendisain
unit-unit
HMM
jika
katanya terlalu
banyak. Namun,
untuk
aplikasi
spesialisasi (contohnya menggunakan kosakata
yang
sedikit,
dan tugas-tugas yang dibatasi), menganggap kata sebagai
|
|
32
basis
unit
percakapan merupakan hal
yang
masuk
akal
dan
praktis.
c. Lexical Decoding
Proses
ini
meletakkan
batasan-batasan pada
unit
matching
system sehingga jalan-jalan yang dilalui merupakan jalan-jalan
yang
berhubungan dengan
bagian-bagian percakapan
yang
terdapat
pada
kamus
kata.
Prosedur
ini
menjelaskan bahwa
kamus
kata
pengenalan suara
harus
dispesifikasikan
dalam
istilah
unit
dasar
yang
dipilih
untuk pengenalan. Spesifikasi
tersebut dapat
berupa
satu atau
lebih
state
jaringan
terbatas,
atau berupa
statistikal. Pada
kasus
dimana
unit
yang
dipilih
adalah kata-kata (atau kombinasi kata—frase), langkah
Lexical
Decoding dapat
dihilangkan dan
struktur
pengenalan
dapat disederhanakan.
d. Syntactic Analysis
Proses
ini,
meletakkan
batasan-batasan lebih
jauh
pada
sistem penyesuaian unit sehingga jalur yang dicari benar-
benar
merupakan jalur
yang
berisikan kata-kata
yang
sesuai
dengan kata-kata inputnya. Kata
–
kata dalam
jalur
tersebut
terdiri
atas
kata-kata dan
kata-kata
tersebut
memiliki
rangkaian yang sesuai dengan
yang terletak pada kamus
|
|
33
katanya.
Kamus kata tersebut dapat
direpresentasikan dengan
jaringan state deterministik terbatas (dimana semua kombinasi
kata yang diterima oleh
kamus kata
disebutkan), atau dengan
kamus
kata
statistikal.
Contohnya model
kata
trigram
yang
mana kemungkinan
urutan
3
kata
spesifik
sudah
ditentukan.
Untuk
beberapa
tugas
kontrol
dan
perintah,
hanya
satu
kata
dari
beberapa
set
terbatas
yang
dibutuhkan
untuk
dikenali.
Oleh
sebab
itu,
kamus
katanya bersifat
trivial
atau
kadang-
kadang
tidak
diperlukan. Tugas-tugas
tersebut
biasanya
termasuk
kedalam
tugas
pengenalan kata
terisolasi.
Untuk
aplikasi
lain
(contohnya rangkaian
digit)
kamus
kata
yang
sangat sederhana sudah cukup memenuhi persyaratan tersebut.
Namun,
ada
tugas-tugas dimana
kamus
kata
menjadi
faktor
dominan. Maka kamus kata
dapat
mengembangkan performa
rekognisi
dengan
menghasilkan
batasan-batasan pada
rangkaian unit percakapan yang merupakan kandidat-kandidat
valid. Walaupun hal
ini menambah batasan-batasan lebih
lanjut dalam proses pengenalan
e. Semantic Analysis
Proses ini, seperti pada synctactic analysis maupun lexical
decoding,
menambah
batasan-batasan
lebih lanjut pada set
jalur pencarian rekognisi percakapan input. Namun, pada
|
|
34
Semantic
Analysis,
batasan-batasan tersebut
diatur
melalui
model
dinamis
dari
state
rekognisi.
Berdasarkan state
rekognisi, beberapa string input yang benar dieliminasi secara
syntactic
dari
beberapa
pilihan. Hal
ini
membuat tugas
rekognisi
lebih
mudah
dan
dapat
meningkatkan performa
sistem.
|