|
BAB 2
LANDASAN TEORI
2.1
Konsep Dasar Database
Definisi database adalah kumpulan data yang saling berhubungan (relasi). Istilah
tersebut
biasa
digunakan pada
sistem-sistem
yang
terkomputerisasi.
Dalam pengertian
umum, database diartikan sebagai gabungan dari elemen-elemen data yang berhubungan
dan terorganisir.
Relasi biasanya ditunjukan dengan kunci dari tiap file yang ada. Dalam satu file
terdapat
record-record yang sejenis, sama besar, sama
bentuk, yang merupakan satu
kumpulan entitas yang seragam. Satu record terdiri dari field yang saling berhubungan
menunjukan bahwa field tersebut dalam
satu pengertian yang lengkap dan direkam
dalam satu record. Dari pengertian diatas dapat disimpulkan bahwa database
mempunyai beberapa kriteria penting, yaitu:
1. Bersifat data oriented dan bukan program oriented.
2. Dapat
digunakan
oleh
beberapa
program
aplikasi
tanpa
perlu
mengubah
database-nya.
3. Dapat dikembangkan dengan mudah, baik volume maupun strukturnya.
4. Dapat memenuhi kebutuhan sistem-sistem baru secara mudah.
5. Dapat digunakan dengan cara-cara yang berbeda.
|
|
9
2.1.1
Tujuan Database
Prinsip utama database adalah pengaturan data dengan tujuan utama fleksibelitas
dan
kecepatan dalam pengambilan
data kembali. Adapun tujuan database
diantaranya
adalah sebagai berikut.
1. Efisiensi meliputi speed, space dan accurancy.
2. Menangani data dalam jumlah besar.
3. Kebersamaan pemakaian (Sharebility).
4. Meniadakan duplikasi dan inkonsistensi data.
2.1.2
Kriteria Database
Ada beberapa ketentuan
yang harus diperhatikan pada pembuatan file database
agar dapat memenuhi kriteria sebagai suatu database, yaitu :
-
Redudansi dan inkonsistensi data: Penyimpanan data yang sama dibeberapa
tempat disebut redundansi, hal ini menyebabkan pemborosan dan menimbulkan
inkonsistensi data (data tidak konsisten) karena bila terjadi perubahan terhadap
data maka data harus dirubah dibeberapa tempat, hal ini tentunya tidak efisien.
-
Pengaksesan data: Data dalam basis data harus siap diakses oleh siapa saja yang
membutuhkan dan mempunyai hak untuk mengaksesnya. Oleh karena itu perlu
dibuat suatu program pengelolaan atau suatu aplikasi untuk mengakses data yang
dikenal sebagai Database Management System (DBMS).
-
Data terisolasi
untuk standarisasi:
Jika data tersebar dalam
beberapa file
dalam
bentuk format yang tidak sama, maka akan menyulitkan dalam menulis program
aplikasi untuk mengambil dan menyimpan data, oleh karena itu data dalam satu
database harus dibuat satu format sehingga mudah dibuat program aplikasinya.
|
|
10
-
Masalah
keamanan
(security):
Tidak
setiap
pemakai
sistem
database
diperbolehkan untuk mengakses semua data, misalnya data mengenai gaji
pegawai hanya boleh dibuka oleh bagian keuangan dan personalia, sedang bagian
gudang
tidak
diperkenankan
untuk
membukanya. Keamanan dapat diatur dan
disesuaikan baik ditingkat database atau aplikasinya.
-
Masalah
integritas (Integrity): Database berisi
file yang saling berhubungan,
masalah
utama
adalah
bagaimana
kaitan antar
file
tersebut terjadi
meski
diketahui bahwa file A terkait dengan file B, namun secara teknis ada field yang
mengaitkan kedua file tersebut oleh karena itu field kunci tidak dapat diabaikan
dalam merancang suatu database.
-
Multiple user : Salah satu alasan database dibangun adalah karena nantinya data
tersebut
digunakan
oleh
banyak
orang,
baik
dalam waktu
berbeda
maupun
bersamaan sehingga kebutuhan akan database handal yang
mendukung banyak
pemakai perlu dipertimbangkan.
-
Data independence (kebebasan data) : Pada aplikasi yang dibuat dengan bahasa
pemrograman, apabila program telah selesai dibuat dan ternyata terjadi
perubahan terhadap struktur file maka program tersebut harus diubah, ini artinya
program
tersebut
tidak
bebas
terhadap
database
yang
ada.
Berlainan
dengan
paket Database Management System (DBMS) apapun
yang terjadi pada struktur
file, setiap kali hendak melihat data cukup dengan utility LIST. Ini artinya
perintah Database Management System (DBMS) bebas terhadap database karena
apapun perubahan terhadap database, semua perintah akan stabil tanpa ada yang
perlu diubah.
|
|
11
Data independence dapat dibagi menjadi dua bagian, yaitu :
-
Phisycal
Data
Independence:
Kebolehan
untuk
mengubah
pola
fisik
database
tanpa
mengakibatkan
suatu
aplikasi
program ditulis
kembali.
Modifikasi
pada
level fisik biasanya hanya pada saat meningkatkan daya guna.
-
Logical
Data
Independence:
Kebolehan
mengubah
pola
konseptual
tanpa
mengakibatkan
suatu
aplikasi
program ditulis
kembali.
Modifikasi
pada
level
konseptual teristimewa saat struktur logika database berubah, ditambahkan atau
dikurangi.
2.1.3
Abstraksi Data
Kegunaan utama sistem basis data adalah agar pemakai mampu menyusun suatu
pandangan abstraksi dari data. Bayangan mengenai data tidak lagi memperhatikan
kondisi sesungguhnya bagaimana satu data
masuk ke database disimpan dalam sektor
mana,
tetapi
menyangkut
secara
menyeluruh bagaimana
data tersebut dapat
diabstraksikan mengenai kondisi yang dihadapi oleh pemakai sehari-hari. Sistem yang
sesungguhnya,
tentang
teknis
bagaimana
data disimpan
dan
dipelihara
seakan-akan
disembunyikan
kerumitannya
dan
kemudian
diungkapkan
dalam
bahasa
dan
gambar
yang mudah dimengerti oleh orang awam.
Ada tiga kelompok
pemakai
dalam tingkatan
abstraksi saat
memandang
suatu
database, yaitu:
-
Level
Fisik
:
Level
ini
merupakan
level
abstraksi
paling
rendah
karena
menggambarkan bagaimana data disimpan dalam kondisi sebenarnya.
-
Level
Konseptual
:
Level
ini
menggambarkan
data apa
yang disimpan
dalam
database dan hubungan relasi yang terjadi antara data dari keseluruhan database.
|
|
12
Pemakai
tidak
memperdulikan
kerumitan
dalam
struktur
level
fisik
lagi,
penggambaran cukup dengan memakai kotak, garis dan hubungan secukupnya.
-
Level Pandangan Pemakai (View level): Level ini
merupakan level abstraksi data
tertinggi yang menggambarkan hanya sebagian saja yang dilihat dan dipakai dari
keseluruhan
database,
hal
ini
disebabkan
beberapa
pemakai database
tidak
membutuhkan semua isi database.
2.1.4
Komponen Utama Database
Ada 4 komponen utama dalam database, yaitu:
-
Data, yang secara fisik menyimpan informasi-informasi.
-
Database Management System (DBMS)
yaitu perangkat
lunak
yang
mengelola
database.
-
Data Description Languages (DDL) dan Data Manipulation Languages (DML),
yaitu bahasa basis data yang berfungsi untuk mendeskripsikan data ke Database
Management
System
(DBMS) dan
juga
memberi
fasilitas
untuk
perubahan,
pemeliharaan, dan pengelolaan database.
-
Program
aplikasi
yang
memudahkan
pengguna
akhir
untuk
menggunakan
data
dan mendapatkanya sebagai informasi yang sesuai.
|
|
13
2.2
Data Warehouse
Datawarehouse merupakan kumpulan data dari berbagai resource, yang
disimpan dalam suatu gudang data
(repository) dalam kapasitas besar.
Datawarehouse
biasa diartikan juga sebagai kumpulan dari data mart. Data warehouse memungkinkan
user untuk memeriksa history data dan melakukan analisis terhadap data sehingga dapat
mengambil keputusan berdasarkan analisa yang dibuat. Data Warehouse membantu para
pekerja teknologi (manager,executive,analyst) untuk pengambilan keputusan yang lebih
cepat dan mudah.
Secara
tradisional,
gudang
(warehouse) digunakan
untuk
menyimpan
barang-
barang dengan cara tertentu supaya dapat ditemukan, dikenali dan diambil kembali
dengan cepat. Fungsi data warehouse
hampir sama dengan
gudang
secara
tradisional.
(http//:www.techrepublic.com)
Dalam sebuah
perusahaan,
umumnya
data
disimpan
dalam
banyak database.
Masing-masing
database
terpisah
menurut
sistemnya masing-masing dan tidak
terintegrasi
menjadi satu. Misalkan data
untuk profil customer, marketing, payroll dan
sebagainya. Data warehouse digunakan untuk
menggabungkan data ke pusat data dan
disusun untuk membuat analisis yang lebih mudah.
2.2.1
Manfaat Data Warehouse
Adapun berbagai manfaat dari data warehouse sebagai berikut.
-
Kemampuan mengakses data yang berskala perusahaan.
-
Kemampuan memiliki data yang konsisten.
-
Dapat melakukan analisis secara cepat.
-
Dapat digunakan untuk mencari redundansi usaha di perusahaan.
|
|
14
-
Menemukan gap antara pengetahuan bisnis dengan proses bisnis.
-
Meminimalkan biaya administrasi.
-
Meningkatkan kinerja pegawai perusahaan untuk dapat melakukan tugasnya
dengan lebih efektif.
2.2.2
Karakteristik Data Warehouse
Data warehouse mempunyai karakteristik sebagai berikut.
-
Subject Oriented: Data warehouse berfokus pada entitas-entitas bisnis level
tinggi.
-
Integrated:
Data disimpan dalam format
yang
konsisten
(dalam
konvensi
penamaan, constraint domain, atribut fisik dan pengukuran).
-
Time variant: Data diasosiasikan dengan suatu titik waktu.
-
Non-volatile: Data yang berasal dari banyak resource terbebut tidak dapat diubah
karena bersifat read only.
Data
warehouse
adalah
sebagai
sebagai subject-oriented, terintegrasi,
tidak
mudah berubah (konsisten) dan merupakan kumpulan data yang mendukung keputusan
manajemen. (Connolly dan Begg, 2002, p147)
|
|
15
Istilah-istilah yang berkaitan dengan data warehouse :
1. ETL (Extract Transfer Load) adalah komponen perangkat
lunak yang berfungsi
untuk mengekstraksi data dari aplikasi ke dalam data mart.
2. Data
Mart
adalah
suatu
bagian
pada
data
warehouse
yang
mendukung
pembuatan laporan dan analisa data pada suatu unit, bagian atau operasi pada
suatu perusahaan.
3. Dimension Table merupakan tabel yang berisikan kategori dengan ringkasan data
detail
yang
dapat
dilaporkan. Seperti
laporan
laba
pada
tabel
fakta dapat
dilaporkan sebagai dimensi waktu (berupa perbulan, perkwartal dan pertahun).
4. Fact Table merupakan tabel yang umumnya mengandung angka dan data history
dimana key (kunci) yang dihasilkan sangat
unik, karena key tersebut terdiri dari
foreign key
(kunci
asing)
yang
merupakan
primary
key (kunci
utama)
dari
beberapa dimension table yang berhubungan.
5. DSS (Decision Support Systems) merupakan sistem yang menyediakan informasi
kepada
pengguna
yang
menjelaskan
bagaimana
sistem ini
dapat
menganalisa
situasi dan mendukung suatu keputusan yang baik.
2.3
OLTP (Online Transaction Processing)
OLTP
(Online Transaction
Processing)
adalah
suatu
proses
yang
menyediakan
mekanisme transaksi pada suatu database. Pada proses ini, design pada database harus
bersifat cepat untuk transaction (insert, update, delete). Hal ini bisa didapat dengan cara
menormalisasi tabel-tabel pada database.
|
|
16
Keuntungan dari normalisasi adalah mengurangi redundansi data (penumpukan
data yang sama) yang terdapat pada tabel-tabel. Hal ini mempercepat proses transaksi,
karena data yang perlu di-update pada tabel menjadi lebih sedikit. Proses peng-update-
an data-datanya pun bersifat real time situation. Dengan kata lain setiap ada data baru,
yang bukan merupakan redudansi dari data yang pernah ada, akan di-update seketika.
OLTP
(Online
Transaction
Processing) memungkinkan
banyak
pengguna
dapat
mengakses sumber data yang sama pada saat bersamaan dan melaksanakan proses yang
diperlukan. Sistem ini
memungkinkan
transaksi
dilakukan
dalam
database,
pada saat
proses bisnis berlangsung.
Dalam proses
OLTP
(Online
Transaction
Processing)
menuju
OLAP
(Online
Analytical Processing) dibutuhkan sedikitnya dua proses
normalisasi
yakni DTS (Data
Transformation Services) dan proses data validation.
2.3.1
DTS (Data Transformation Services)
Perusahaan perlu untuk memusatkan data mereka guna mendukung dalam proses
pengambilan keputusan. Data tersebut dapat disimpan dalam jumlah yang besar dalam
bentuk angka-angka dari sumber yang berbeda. Barisan data yang ada di dalam sumber
ini harus dapat di-reconciled dan diubah ke dalam beberapa kasus sebelum disimpan ke
dalam data warehouse. Data transformation services memindahkan data dari database
OLTP (Online Transaction Processing) ke data warehouse sesuai dengan tujuannya. Hal
ini
dilakukan
ketika
validasi, cleaning-up,
konsolidasi
dan
mengubah
data
yang
diperlukan. (Vieira, Robert, 2000, p91)
|
|
17
2.3.2
Data Validation
Sangatlah penting untuk
melakukan validasi data sebelum data tersebut diambil
dari database
OLTP (Online Transaction Processing) dan dikirim ke data warehouse.
Jika data tersebut tidak valid,
maka keutuhan dari analisis bisnis perlu dipertanyakan.
Hal penting lainnya yang harus diperhatikan adalah ketika validasi data yang dilakukan
berhubungan dengan area geografis. (Vieira, et all, 2000, p92)
2.4
OLAP (Online Analytical Processing)
OLAP
(Online
Analytical
Processing) merupakan
suatu
istilah
yang
menggambarkan
suatu teknologi
yang
menggunakan
gambaran
multidimensi
dari
sejumlah data untuk menyediakan atau memberikan akses dan analisis yang lebih cepat
untuk strategi informasi. (Connolly dan Begg, 2002, p111)
OLAP
(Online
Analytical
Processing) merupakan
suatu
pemrosesan
database
yang menggunakan tabel fakta dan dimensi untuk dapat menampilkan berbagai macam
bentuk laporan, analisis, query dari data yang berukuran besar.
OLAP (Online Analytical Processing) juga merupakan suatu proses
mekanisme
untuk menganalisa data dengan menyediakan definisi, proses dan pengiriman suatu
objek
analisis.
Jika data
warehouse
adalah media
penyimpanan
data
dari
suatu
perusahaan,
maka
OLAP
(Online
Analytical
Processing) adalah
cara
user
untuk
mengakses data tersebut.
OLAP
(Online
Analytical
Processing) bersifat
natural
dan
intuitif,
sehingga
memberikan navigasi dan pengertian yang lebih baik akan data.
|
|
18
Solusi OLAP (Online Analytical Processing) yang baik harus memenuhi hal-hal
berikut ini.
-
Fast, dimana pemakai
memperoleh respond dalam hitungan detik sehingga tidak
terputus rantai pemikirannya.
-
Analysis, dimana sistem menyediakan fungsi-fungsi analisis, lingkup
intuitif dan
fungsi-fungsi
ini
dapat
mensuplai
logika bisnis
dan
analisis
statistikal
yang
relevan dengan aplikasi user.
-
Shared, dimana sistem mendukung user yang banyak secara konkurensi.
-
Multi-dimensional, merupakan kebutuhan utama sehingga sistem mensuplai
view konseptual multidimensional dari data termasuk pendukung untuk hirarki
multiple.
-
Information,
merupakan data dan informasi yang diwariskan, dimana dibutuhkan
oleh aplikasi user.
2.5
Alasan Penggunaan Data mining
Suatu fakta yang kini cukup jelas terlihat
pada
suatu
manajemen
perusahaan
adalah
pentingnya
informasi
untuk
dapat meningkatkan
kinerja
mereka.
Tentunya
peningkatan kinerja inilah yang diharapkan
mampu
membuat
perusahaan
tersebut
bersaing dengan perusahaan lainnya ditengah iklim usaha yang ketat saat ini. Hal
tersebut
menjadi alasan utama penggunaan data mining
yang
mampu
memberi solusi
bagi kebutuhan di atas.
Data mining sebagai tool, dapat menggali informasi tersembunyi yang mungkin
terdapat pada sekumpulan database sehingga akan membawa dampak positif yang
cukup signifikan bagi perusahaan. Data mining dapat dikatakan sebagai hasil dari
|
|
19
evolusi teknologi informasi. Yaitu mulai dari sistem data collection, database creation,
data management (termasuk storage dan retrieval serta database transaction
processing), dan data analysis and understanding.
Dengan dasar tersebutlah, dapat dilihat bermacam manfaat yang dapat dilakukan
oleh
tools
data
mining tersebut
secara
langsung
maupun
tidak
langsung
yang
dapat
meningkatkan kinerja perusahaan. Kecepatan berkembangnya pengumpulan dan
penyimpanan data dalam jumlah yang luar biasa banyaknya mengakibatkan data tersebut
menjadi sulit untuk dianalisis oleh seorang manusia tanpa bantuan alat bantu/powerfull
tools yang dapat meng-extract informasi penting yang terkubur di sejumlah besar data
yang tersedia. Sebagai akibatnya, seringkali keputusan-keputusan penting yang diambil
pun dibuat tidak berdasarkan informasi yang didapatkan dari data yang ada, melainkan
berdasarkan intuisi pengambil keputusan semata. Hal ini sering terjadi karena para
pengambil
keputusan
tidak
memiliki tools
yang
memadai
untuk
melakukan
pencarian
informasi yang akurat dari data yang tersedia.
Program data mining dapat melakukan analisis data dan menemukan informasi
penting yang tersembunyi
mengenai suatu pola data. Hal
ini dapat memberikan
kontribusi yang sangat besar pada strategi bisnis, knowledge base, dan penelitian serta
riset medikal.
Kehadiran data mining dilatar belakangi dengan problema data explosion yang
dialami
akhir-akhir
ini
dimana
banyak
perusahaan
telah
mengumpulkan
data
sekian
tahun lamanya (data pembelian, data penjualan, data nasabah, data transaksi, dan
sebagainya). Hampir semua data tersebut dimasukkan dengan menggunakan aplikasi
komputer yang digunakan untuk menangani transaksi sehari-hari yang kebanyakan
adalah OLTP (Online Transaction Processing). Bayangkan berapa banyak transaksi
|
|
20
yang
dimasukkan
dari
transaksi
kartu
kredit
dari
sebuah
bank
dalam seharinya
dan
bayangkan betapa besarnya ukuran data mereka jika nanti telah berjalan beberapa tahun.
Pertanyaannya
sekarang, apakah data tersebut akan dibiarkan
menggunung,
tidak
berguna lalu dibuang, ataukah dapat di‘tambang’ untuk mencari ‘emas’, ‘berlian’ berupa
informasi yang berguna untuk perusahaan. Banyak perusahaan yang kebanjiran data
namun miskin informasi.
Sebagai cabang ilmu baru di bidang komputer,
namun sudah cukup banyak
penerapan yang dapat dilakukan oleh
data mining. Apalagi ditunjang kekayaan dan
keanekaragaman
berbagai
bidang ilmu
(artificial intelligence,
database,
statistik,
pemodelan
matematika,
pengolahan
citra, dan
sebagainya)
membuat
penerapan
data
mining menjadi makin luas.
2.1.1 Penerapan Data mining untuk Analisis Pasar
Untuk analisis pasar, banyak sekali sumber data yang dapat digunakan seperti
transaksi
kartu
kredit,
kartu
anggota
club
tertentu,
kupon diskon,
keluhan
pembeli,
ditambah dengan studi tentang gaya hidup masyarakat.
Sebagai
contoh,
jika
seseorang
mempunyai
kartu
kredit,
sudah
pasti
ia
akan
sering menerima surat berisi brosur penawaran barang atau jasa. Jika bank pemberi kartu
kredit mempunyai 1.000.000 nasabah, dan mengirimkan sebuah surat penawaran kepada
setiap
nasabahnya
dengan
biaya pengiriman sebesar
Rp.
1.000,-
per
buah
maka biaya
yang
dihabiskan
adalah
1
milyar
rupiah.
Jika bank
tersebut
mengirimkan
penawaran
sekali sebulan yang berarti 12 kali dalam setahun. Maka, anggaran yang dikeluarkan per
tahunnya adalah 12 milyar rupiah. Dari dana 12 milyar rupiah yang dikeluarkan,
|
|
21
mungkin hanya 10% dari nasabah saja yang benar-benar membeli. Secara harfiah,
berarti 90% dari dana tersebut terbuang sia-sia.
Persoalan di atas
merupakan salah
satu persoalan
yang dapat diatasi oleh data
mining
dari
sekian
banyak
potensi permasalahan
yang ada. Data
mining
dapat
menambang data transaksi belanja kartu kredit untuk melihat manakah nasabah yang
memang potensial
untuk
membeli produk tertentu. Mungkin tidak sampai
presisi 10%,
tapi bayangkan jika dapat disaring menjadi 30% saja, tentunya 70% dana dapat
digunakan untuk hal lainnya.
Beberapa fungsi lainnya dari data mining untuk analisis pasar adalah sebagai
berikut.
•
Menembak target pasar
Data
mining
dapat
melakukan pengelompokan
(clustering) dari
model-
model pembeli dan melakukan klasifikasi terhadap setiap pembeli sesuai dengan
karakteristik yang diinginkan seperti kesukaan yang sama, tingkat penghasilan
yang sama, kebiasaan membeli dan karakteristik lainnya.
•
Melihat pola beli pemakai dari waktu ke waktu
Data mining dapat digunakan untuk melihat pola beli seseorang dari
waktu ke waktu. Sebagai contoh, ketika seseorang menikah dapat saja ia
kemudian
memutuskan
pindah
dari
single
account
ke joint
account (rekening
bersama)
dan
kemudian
setelah
itu pola
beli-nya
berbeda dari
ketika
ia masih
bujangan.
|
|
22
•
Cross-Market Analysis
Data mining dapat digunakan untuk melihat hubungan antara penjualan
satu produk dengan produk lainnya.
Berikut ini adalah beberapa contohnya.
-
Cari pola penjualan Coca Cola sedemikian rupa sehingga dapat diketahui
barang apa sajakah yang harus disediakan untuk meningkatkan penjualan
Coca Cola.
-
Cari pola
penjualan
IndoMie
sedemikian
rupa sehingga
dapat
diketahui
barang apa saja yang juga dibeli oleh pembeli IndoMie. Dengan demikian
dapat diketahui dampaknya jika IndoMie tidak dijual lagi.
•
Profil Customer
Data
mining
dapat
membantu
untuk
melihat
profil customer
sehingga
dapat diketahui kelompok customer tertentu suka membeli produk apa saja.
•
Identifikasi Kebutuhan Customer
Data mining dapat digunakan untuk mengidentifikasi produk-produk apa
saja yang terbaik untuk tiap kelompok customer dan menyusun faktor-faktor apa
saja yang kira-kira dapat menarik customer baru untuk bergabung/membeli.
•
Menilai Loyalitas Customer
VISA
International Spanyol
menggunakan
data
mining
untuk
melihat
kesuksesan program-program customer loyalty mereka.
•
Informasi Summary
Data
mining
dapat
digunakan
untuk
membuat
laporan summary
yang
bersifat multi-dimensi dan dilengkapi dengan informasi statistik lainnya.
|
|
23
2.1.2
Penerapan Data mining untuk Analisis Perusahaan dan Manajemen Resiko
•
Perencanaan Keuangan dan Evaluasi Aset
Data mining dapat membantu untuk melakukan analisis dan prediksi cash
flow serta melakukan contingent claim analysis untuk mengevaluasi aset. Selain
itu dapat juga digunakan untuk analisis trend.
•
Perencanaan Sumber Daya (Resource Planning)
Dengan
melihat
informasi
ringkas
(summary)
serta
pola
pembelanjaan
dan
pemasukkan
dari
masing-masing
resource, data mining dapat digunakan
untuk melakukan resource planning.
•
Persaingan (Competition)
Sekarang ini banyak perusahaan yang berupaya untuk dapat melakukan
competitive
intelligence. Data mining dapat membantu untuk memonitor
pesaing-pesaing dan melihat market direction mereka.
-
Data mining dapat digunakan untuk melakukan pengelompokan customer
dan memberikan variasi harga/layanan/bonus untuk masing-masing grup.
-
Data
mining
dipakai
dalam
menyusun
strategi penetapan
harga
di
pasar
yang sangat kompetitif. Hal ini diterapkan oleh perusahaan minyak
REPSOL di Spanyol dalam menetapkan harga jual gas di pasaran.
•
Telekomunikasi
Sebuah
perusahaan
telekomunikasi
menerapkan
data
mining
untuk
melihat jutaan data transaksi yang masuk, transaksi mana sajakah yang masih
harus
ditangani
secara manual
(dilayani
oleh
manusia).
Tujuannya
tidak
lain
adalah untuk menambah layanan otomatis khusus untuk transaksi-transaksi yang
|
|
24
masih dilayani secara manual. Dengan demikian jumlah operator penerima
transaksi manual tetap bisa ditekan minimal.
•
Keuangan
Financial Crimes Enforcement Network di Amerika Serikat baru-baru ini
menggunakan data mining untuk menambang trilyunan dari berbagai subyek
seperti property, rekening bank dan transaksi keuangan lainnya untuk
mendeteksi
transaksi-transaksi
keuangan
yang
mencurigakan
(seperti money
laundry). Mereka menyatakan bahwa hal tersebut akan susah dilakukan jika
menggunakan analisis standar.
•
Asuransi
Australian
Health Insurance
Commision
menggunakan
data
mining
untuk
mengidentifikasi
layanan
kesehatan
yang
sebenarnya
tidak
perlu
tetapi
tetap dilakukan oleh peserta asuransi. Dengan strategi tersebut, mereka berhasil
menghemat
satu
juta
dollar
per
tahunnya. Tentu
saja
ini
tidak
hanya
bisa
diterapkan untuk asuransi kesehatan, tetapi juga untuk berbagai jenis asuransi
lainnya.
•
Olah Raga
IBM Advanced Scout menggunakan data mining untuk menganalisis
statistik permainan NBA (jumlah shots blocked, assists dan fouls) dalam rangka
mencapai
keunggulan
bersaing
(competitive
advantage) untuk
tim New
York
Knicks dan Miami Heat.
|
|
25
•
Astronomi
Jet
Propulsion Laboratory (JPL) di
Pasadena,
California dan Palomar
Observatory berhasil menemukan 22 quasar dengan bantuan data mining .
Hal
ini merupakan salah satu kesuksesan penerapan data mining di bidang astronomi
dan ilmu ruang angkasa.
•
Internet Web Surf-Aid
IBM Surf-Aid menggunakan algoritma data mining untuk mendata akses
halaman Web khususnya yang berkaitan dengan pemasaran guna melihat prilaku
dan minat customer serta melihat keefektifan pemasaran melalui Web.
Dengan
melihat
beberapa
aplikasi
yang
telah disebutkan sebelumnya, terlihat
sekali
potensi
besar
dari
penerapan
data
mining
di
berbagai
bidang.
Bisa
dikatakan
bahwa data mining merupakan salah satu aktivitas di bidang perangkat lunak yang dapat
memberikan
ROI (return
on
investment) yang
tinggi.
Namun demikian, perlu diingat
bahwa data mining
hanya melihat keteraturan atau pola dari sejarah, tetapi tetap saja
sejarah tidak sama dengan masa datang. Sebagai contoh, jika orang terlalu banyak
minum Coca Cola bukan berarti dia pasti akan kegemukan, jika orang
terlalu banyak
merokok bukan berarti dia pasti akan kena kanker paru-paru atau mati muda.
Bagaimanapun juga data mining
tetaplah hanya alat bantu yang dapat membantu
manusia
untuk
melihat
pola,
menganalisis
trend,
dan
sebagainya
dalam rangka
mempercepat pembuatan keputusan.
Berbagai pemaparan tersebut merupakan suatu fakta yang tidak dapat dipungkiri
lagi oleh setiap perusahaan pada masa kini maupun
masa
mendatang. Oleh karena itu,
|
|
26
pada skripsi
ini menggunakan
sistem database
yang
menerapkan aplikasi data mining
untuk clustering item. Topik utama yang disampaikan akan menggunakan bantuan
metode Clustering Large Application based on Randomized Search sebagai tool untuk
sistem clustering data perusahaan. Dengan begitu, manajer dapat menindaklanjuti
dengan cepat dan tepat terhadap kemungkinan munculnya informasi yang tergali setelah
dilakukan proses clustering pada data-data yang ada.
Clustering sebenarnya merupakan teknik data mining yang digunakan untuk
mencari
pengelompokan
data,
yang
tidak
memiliki
pengelompokan
alami. Pada
algoritma
clustering,
data
akan
dikelompokan
menjadi cluster-cluster
berdasarkan
kemiripan satu data dengan data
yang
lain.
Dalam
hal
ini, tidak ada patokan tertentu
yang digunakan pada algoritma clustering untuk mencari pengelompokan data yang ada
pada
sekumpulan data
tersebut.
Data
yang dikelompokan dalam satu
cluster
memiliki
similaritas
tinggi,
sedangkan
antara
satu cluster
dengan
cluster
lainnya
memiliki
similaritas rendah.
2.6 Definisi Data Mining
Data
mining
merupakan
proses
untuk
menggali (mining) pengetahuan dan
informasi
baru
dari
data
yang
berjumlah
banyak
pada data
warehouse,
dengan
menggunakan kecerdasan buatan (Artificial Intelegence), statistik dan matematika. Data
mining merupakan teknologi yang diharapkan dapat
menjembatani
komunikasi
antara
data
dan
pemakainya. Data mining
seringkali disebut juga dengan
knowledge
mining
from databases, knowledge extraction, data pattern analysis, data archeology, dan data
dredging.
|
|
27
Selain itu data mining juga sering digunakan oleh banyak orang sebagai sinonim
dari Knowledge Discovery in
Databases atau KDD. Teknik analisis data mining
pada
umumnya diorentasikan untuk dapat mengerjakan data yang ada dalam jumlah sebanyak
mungkin, dengan tujuan mining terhadap data tersebut
dapat
menghasilkan keputusan
dan kesimpulan yang terjamin keakuratannya.
Arsitektur utama dari
sebuah
sistem
data mining,
pada
umumnya
mengandung
unsur-unsur sebagai berikut :
-
Database, datawarehouse, atau media penyimpanan informasi.
Media
dalam hal
ini
bisa
jadi
berupa database,
datawarehouse,
spreadsheets,
atau
jenis-jenis
penampungan
informasi
lainnya.
Data
cleaning
dan data integration dapat dilakukan pada data tersebut.
-
Database atau datawarehouse server.
Database atau
datawarehouse
server
bertanggung
jawab
untuk
menyediakan data yang relevan berdasarkan permintaan dari user pengguna data
mining .
-
Data mining engine.
Bagian
dari
program aplikasi
yang
menjalankan
program
berdasarkan
algoritma yang ada.
-
Pattern evaluation module
Bagian
dari
program aplikasi
yang
berfungsi
untuk
menemukan pattern
atau pola-pola yang terdapat di dalam database yang diolah sehingga nantinya
proses data mining dapat menemukan knowledge yang sesuai.
|
|
28
-
Graphical user interface
Bagian
ini merupakan sarana antara
user dan sistem
data mining untuk
berkomunikasi,
di
mana
user
dapat
berinteraksi
dengan
sistem melalui data
mining
query,
untuk
menyediakan
informasi
yang
dapat
membantu dalam
pencarian
knowledge.
Lebih
jauh lagi, bagian
ini
mengijinkan
user
untuk
melakukan
browsing pada
database dan
datawarehouse,
mengevaluasi pattern
yang
telah dihasilkan, dan
menampilkan pattern tersebut dengan tampilan
yang
berbeda-beda.
Suatu sistem data
mining
yang
baik,
seharusnya
dibangun dengan
algoritma
yang baik, terstruktur, cepat, dan juga dapat
menangani
data
dalam
jumlah
besar,
sehingga ketika menangani suatu database dengan ukuran besar maupun kecil, running
time-nya
pun
akan berkembang
secara
proporsional.
Dengan
melakukan data mining,
knowledge
yang
menarik, high level information dapat
di-extract
dari database
atau
ditampilkan dari berbagai sudut pandang. Data mining pada umumnya dapat dilakukan
terhadap
segala
macam
data
yang
tersimpan
baik
pada relational
database,
datawarehouse, transactional databases, dan tidak tertutup kemungkinan pada sebuah
sistem database pada internet, seperti misalnya, mining informasi transaksi online.
|
 29
2.7
Tahapan-tahapan pada Data Mining
Ringkasan dari tahapan-tahapan serta proses yang dilakukan pada saat
melakukan data mining
dan proses untuk menemukan knowledge dapat dilihat pada
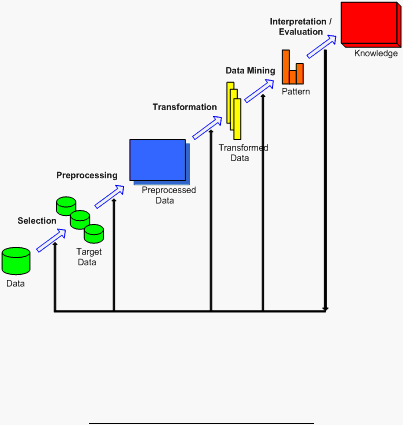
Gambar 2.1.
Gambar 2.1. Tahap-tahapan dalam Data mining (Sumber : Data
mining : Concepts and Techniques, Jiawei Han) Sumber:
Tahap-tahapnya dimulai dari pemrosesan raw data atau data mentah sampai pada
penyaringan hingga ditemukannya knowledge, dijabarkan sebagai berikut.
1.
Selection, yaitu proses memilih dan memisahkan data berdasarkan beberapa
kriteria, misalnya berdasarkan kota tempat tinggal konsumen.
2.
Preprocessing, yaitu mempersiapkan data,
dengan
cara
membersihkan
data,
informasi
atau field
yang
tidak
dibutuhkan,
yang
jika
dibiarkan
hanya
akan
memperlambat proses query, misalnya nama pelanggan jika sudah diketahui
|
|
30
kode pelanggannya. Selain itu juga, ditahap ini dilakukan penyeragaman format
terhadap
data-data
yang
tidak
konsisten,
misalnya
pada
suatu field
dari
suatu
tabel, data jenis kelamin diinputkan dengan “L” atau “M”, sedangkan pada tabel
yang lain, data tersebut diinputkan sebagai “P” atau “W”.
3. Transformation, data yang telah melalui proses select dan pre-processing tidak
begitu saja langsung digunakan, tapi ditransformasikan terlebih dahulu ke bentuk
yang
lebih navigable
dan
useable,
misalnya
dengan
menambahan
field-field
tertentu
yang bersifat
demografi,
seperti propinsi, kota, atau informasi apapun
yang biasanya digunakan pada riset pemasaran.
4. Data mining, tahap ini dipusatkan untuk mendapatkan pola dari data (extraction
of data).
5. Interpretation
and
evaluation,
dalam
proses
ini
pattern
atau
pola-pola
yang
telah
diidentifikasi
oleh
sistem kemudian di
terjemahkan/diintepretasikan
ke
dalam bentuk
knowledge
yang
lebih
mudah
dimengerti
oleh
user
untuk
membantu
pengambilan
keputusan,
misalnya
menunjukan item
yang
saling
berasosiasi melalui grafik atau bentuk lain yang lebih mudah dimengerti.
Pada umumnya, data mining dapat digunakan untuk menganalisis dan
menemukan empat tipe relasi berikut.
-
Classes,
data
yang
tersedia
dapat
digunakan
untuk
menemukan
hubungan dari
beberapa hal yang ingin diketahui. Sebagai contoh, sebuah restauran dapat
melakukan mining terhadap data penjualannya selama periode-periode tertentu,
untuk
menemukan
pada
waktu-waktu
kapan,
restauran tersebut
menerima
kunjungan paling banyak dan kunjungan paling sedikit, setelah menemukan,
|
|
31
restoran
mungkin
dapat
menawarkan paket-paket
istimewa
untuk
menarik
pelanggan lebih banyak lagi pada jam-jam sepi tersebut, sehingga nantinya dapat
meningkatkan penjualan dari restauran tersebut secara keseluruhan.
-
Clusters,
data
item
dapat
dikelompokan/dipecah-pecah
kedalam
beberapa
grup,
berdasarkan
algoritma
yang
sudah
ditentukan.
Misalnya, data
mining
dapat
langsung mencari dan mengelompokan konsumen di daerah yang mana saja yang
mempunyai daya beli tinggi, dan yang mana memiliki daya beli rendah.
-
Associations,
data
dapat
di-mine
untuk
menemukan
item-item
apa
saja,
yang
dibeli
konsumen,
yang
saling
berasosiasi. Misalnya;
bila
seorang
konsumen
membeli secangkir kopi, ternyata konsumen tersebut juga membeli makanan
ringan seperti biskuit ataupun cake.
-
Sequential patterns, data dapat di-mine untuk menemukan “patterns and trends”
yaitu pola belanja konsumen dan juga trend yang terjadi secara berurutan.
Sebagai contoh adalah, konsumen yang membeli sebuah komputer, dapat
diperkirakan konsumen tersebut akan membeli juga software-software game atau
installer maupun tinta printer.
2.8
Clustering
Analisis cluster adalah upaya menemukan sekelompok objek yang mewakili
suatu karakter
yang sama atau
hampir
sama
(similar) antar
satu
objek
dengan objek
lainnya pada suatu kelompok dan memiliki perbedaan (not similar) dengan objek-objek
pada kelompok lainnya. Tentunya persamaan dan perbedaan tersebut diperoleh berdasar
informasi yang diberikan oleh objek-objek tersebut beserta hubungan (relationship)
|
|
32
antar
mereka.
Dalam berbagai
kesempatan,
clustering
juga
sering
disebut
sebagai
Unsupervised Classification yaitu, pengelompokan data yang tidak memiliki
pengelompokan alami. Beberapa hal yang tidak termasuk dalam analisis cluster adalah
-
Klasifikasi
yang
telah tervisikan (misal,
pengelompokan
hewan
berdasar
cara
perkembangbiakannya),
-
Pemisahan sederhana (misal, pengelompokan nama siswa berdasar abjad),
-
Hasil suatu Query (misal, grouping suatu spesifikasi tertentu),
-
Partisi grafik, dan sebagainya.
2.8.1 Konsep dasar Clustering
Konsep terpenting yang harus disadari adalah bahwa proses clustering yang baik
akan menghasilkan cluster dengan kualitas tinggi bila memiliki :
-
Tingkat kesamaan yang tinggi dalam satu class (high intra-class similarity).
-
Tingkat kesamaan yang rendah antar class (low inter-class similarity).
Similarity
yang
dimaksud
merupakan
pengukuran
secara numerik terhadap
dua
buah objek. Nilai similarity ini akan semakin
tinggi bila dua objek yang dibandingkan
tersebut memiliki kemiripan yang tinggi pula. Tentunya, perbedaaan kualitas suatu hasil
clustering ini bergantung pada metode yang dipakai untuk mengukur kesamaan
(similaritas)
tersebut
serta
implementasinya. Dalam hal
ini,
diperlukan kesebandingan
antara
data
yang
hendak
di-cluster.
Oleh
karena
itu,
digunakan
metode Min-Max
Normalization untuk mengatasi hal tersebut. Rumus selengkapnya dari metode ini dapat
dilihat sebagai berikut.
|
|
33
V =
' =
V
-
min
A
max
A
-
min
A
* new _ max
(new _ max
A
-
new _ min
A
)+ new _ min
A
di mana,
V’
= Nilai dari data hasil Min-Max Normalization
V
= Nilai dari data yang akan dinormalisasi
minA
= Nilai minimum dari suatu field data yang sama
maxA
=
Nilai maksimum dari suatu field data yang sama
new_minA = Nilai minimum terbaru yang diinginkan
new_maxA = Nilai maksimum terbaru yang diinginkan
Selain itu pula, suatu metode clustering juga harus dapat diukur kemampuannya
dalam usahanya
untuk
menemukan
suatu
pola
tersembunyi
pada
data
yang
tersedia.
Dalam mengukur nilai similarity ini, ada beberapa metode yang dapat dipakai. Namun,
hanya
akan dijelaskan
metode
yang dipakai dalam pembuatan
skripsi
ini, yaitu
Euclidean Distance.
Pada metode ini, dua buah point dapat dihitung jaraknya bila diketahui nilai dari
masing-masing atribut pada kedua point tersebut. Berikut adalah
rumus distance yang
dipakai.
Distance = (
n
?
µ
k
k
=1
|
p
k
-
q
k
|r )¹ r
/ r
dimana, n = Jumlah record data
k = Urutan field data
r = 2
|
 34
µ
k
= Bobot field yang diberikan oleh user
•
(0 <= µ
k
<= 1)
•
p
k
,
q
k
e
R
Yang dimaksud dengan bobot field (
µ
k
)
adalah ukuran kemampuan suatu field
ke-k dalam
mempengaruhi jarak antara kedua point. Semakin besar nilai
µ
k
, akan
semakin besar pula pengaruhnya terhadap jarak antara kedua
point, dan sebaliknya
semakin kecil
nilai
µ
k
,
akan
semakin
kecil pengaruhnya terhadap
jarak
antar
kedua
point.
2.8.2
Tipe Clustering
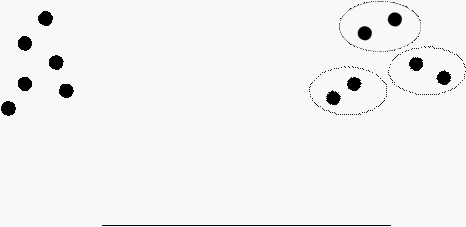
Pada dasarnya terdapat 2 tipe Clustering, yaitu:
-
Partitional Clustering: Tipe cluster yang benar-benar terpisah antara sekelompok
objek dengan sekelompok objek lainnya.
Original Points
A Partitional Clustering
Gambar 2.2. Tipe-tipe Cluster
|
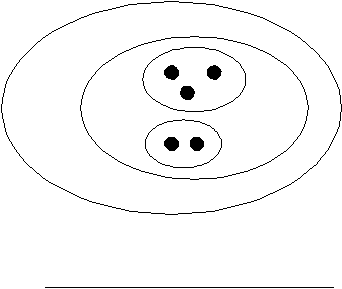 35
-
Hierarchical
Clustering:
Sekelompok
cluster
yang
terorganisasi sebagai
suatu
pohon hirarki (hierarchical tree).
Gambar 2.3. Traditional Hierarchical Clustering
2.8.3
Penggunaan Aplikasi Clustering
Berbagai macam aplikasi penggunaan clustering, dapat meliputi sebagai berikut :
-
Pengenalan pola
-
Analisis data spasial (Spatial Data)
•
Membuat Map GIS (Geographic Information System)
•
Mendeteksi cluster spasial dan menjelaskannya pada data mining spasial
-
Memroses image tertentu
-
Ilmu Pengetahuan Ekonomi (analisis pasar)
-
Meng-cluster weblog data
|
|
36
Contoh penggunaan aplikasi cluster :
-
Marketing:
Membantu
para
pelaku
pasar
menemukan
kelompok
tertentu
pada
basis
customer mereka
dan
menggunakan
pengetahuan
tersebut
untuk
mengembangkan program target marketing mereka.
-
Land use: Mengidentifikasi setiap area yang ada di permukaan bumi untuk
keperluan observasi pada database.
-
Insurance: Mengidentifikasi sekelompok pemegang polis asuransi
yang
memiliki tingkat biaya klaim rata-rata tertentu.
-
City
Planning:
Mengidentifikasi
sekelompok
rumah
berdasar
tipe,
nilai
serta
letak geografisnya.
-
Earth-quake
Studies:
mengobservasi
berbagai
macam
titik
episentrum
gempa
bumi yang terjadi pada berbagai benua.
2.9
Clustering Large Applications based On Randomized Search
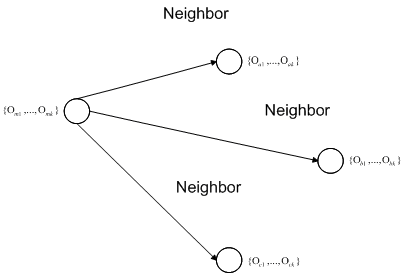
Metode ini dapat dijelaskan sebagai berikut :
-
Clustering Large Application based on Randomized Search menggambarkan
contoh pasangan set (neighbor) secara dinamis
-
Proses
clustering
dapat
menggambarkan pencarian suatu graph, di
mana
setiap
node pada graph tersebut merupakan solusi yang potensial, yaitu sekumpulan k
medoids.
-
Jika optimum lokal ditemukan, Clustering Large Application based on
Randomized
Search
memulai
lagi
dengan
memilih
node
baru
secara
random
untuk menemukan optimum lokal yang baru.
|
 37
Tahapan dalam algoritmanya adalah sebagai berikut.
1. Input
parameter
numlocal
dan
maxneighbor.
Inisialisasi
i
=
1
dan
mincos t = nilai numerik yang besar (misal : 1000).
2.
Set current_node = arbitrary node pada Gn, k.( Graph )
3. Set j = 1.
4. Tentukan random neighbor S dari current_node, dan kalkulasikan cost
differential dari dua node.
5. Jika S
memiliki cost yang
lebih
rendah, set current_node = S, dan kembali ke
Step 3.
6. Jika tidak, increament j ( j = j + 1 ). Jika j _ maxneighbor, kembali ke Step 4
7. Selain
itu, saat j > maxneighbor, bandingkan cost dari current dengan mincost.
Jika nilai cost yang didapat dari perhitungan current_node lebih kecil dari
mincost, set mincost = cost dari current_node dan set bestnode = current_node.
8. Increament i ( i = i + 1). Jika i >numlocal, output bestnode dan halt . Jika tidak,
kembali ke Step 2.
Gambar 2.4 Grafik Cluster
|
 38
2.10
Flowchart
Flowchart merupakan
suatu
cara
penggambaran
alur
kontrol
eksekusi
sebuah
program dengan menggunakan simbol-simbol tertentu. Tujuan penggambaran flowchart
adalah
untuk memudahkan orang
lain dalam mempelajari alur logika sebuah program.
Simbol-simbol
yang digunakan dalam
menggambarkan
flowchart
adalah
sebagai
berikut:
a. Terminator
Digunakan untuk mengawali dan mengakhiri sebuah alur flowchart.
Untuk
mengawali
sebuah
alur
program digunakan
kata
“Start”,
dan
untuk
mengakhiri alur tersebut digunakan kata “End”. Untuk mengawali dan
mengakhiri sebuah modul atau suatu bagian dari program, digunakan kata
“Enter” dan “Return”.
Gambar 2.5 Terminator
b. Preparation
Digunakan untuk menginisialisasi nilai sebuah variabel, record, atau field
lainnya yang diperlukan dalam program.
Gambar 2.6 Preparation
|
 39
c. Process
Digunakan untuk menampilkan proses-proses yang terjadi dalam alur
program, seperti penambahan, pengurangan, dan lain-lain.
Gambar 2.7 Process
d. Decision
Digunakan untuk menggambarkan proses percabangan (branching) yang
terjadi dalam alur program.
Gambar 2.8 Decision
e. Input/Output
Digunakan untuk menggambarkan proses yang melibatkan input dan
output data, seperti meminta input-an dan menampilkan hasil output kepada user.
Gambar 2.9 Input/Output
|
 40
f.
Predefined Process
Digunakan untuk menggambarkan proses pemanggilan prosedur lain yang
terpisah dari alur
utama program. Prosedur
tersebut dijabarkan dalam flowchart
lain.
Gambar 2.10 Predefined Process
g. Connector
Digunakan untuk menghubungkan ujung-ujung percabangan dalam
aprogram.
Gambar 2.11 Connector
h. Arrow
Digunakan untuk menggambarkan arah alur program antara dua simbol.
Gambar 2.12 Arrow
|
 41
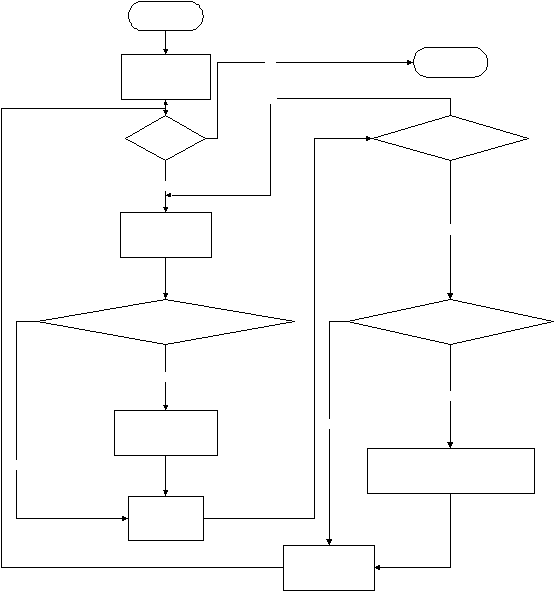
Berikut
ini adalah flowchart dari algoritma Clustering Large Application based
on Randomized Search.
Start
MinCost=1000
Count_Neighbor=0
i=1
No
Yes
End
i<=NumLocal
Count_Neighbor<=Max_Neighbor
Yes
Inc(Count_Neighbor)
No
CountMedoid(Current_Node)<=CountMedoid(Neighbor)
best_count_medoid_so_far<=current_value
No
No
Count_Neighbor=0
Current_Node=Neighbor
Yes
Yes
best_node=current_node
best_count_medoid_so_far=current_value
Set Neighbor
Select Arbitrary Node
Set Neighbor Inc(i)
Gambar 2.13 Flowchart of Data Clustering’s Procedure
|
|
42
2.11
Naive Bayes Classification
Metode
ini
dipakai
untuk
mengklasifikasikan
item baru
yang
tidak
mengalami
proses clustering. Jadi, setelah
hasil akhir cluster terbentuk, bila ada data
terbaru
yang
ingin di-input-kan, user dapat
langsung
mengetahui data baru
tersebut terklasifikasikan
pada cluster yang mana (tanpa harus mengulangi proses Clustering). Berikut ini adalah
rumus yang dipakai :
?
(x1,..., xk | C
)
=
?
(
x1 C
| C
)
*...* ?
(xk | C
)
Dimana, P(xi|C) adalah perkiraan frekuensi relativitas dari sampel yang memiliki
nilai xi seperti pada atribut yang ada pada class C.
|