 BAB 2
LANDASAN TEORI
Pada
bab
ini
diuraikan
beberapa landasan
teori
dan
konsep-konsep
yang
mencakup
biometrik,
verifikasi
tanda
tangan, pengenalan pola,
image
pre-processing,
image processing, dan metode FCM.
2.1 Biometrik
2.1.1 Pengertian Biometrik
Biometrik (berasal
dari
bahasa
Yunani
bios
yang
artinya
hidup dan
metron
yang
artinya
mengukur)
adalah
studi
tentang
metode
otomatis
untuk
mengenali manusia
berdasarkan satu atau lebih bagian tubuh manusia atau kelakuan dari manusia itu sendiri
2.1.2 Jenis-jenis Sistem Biometrik
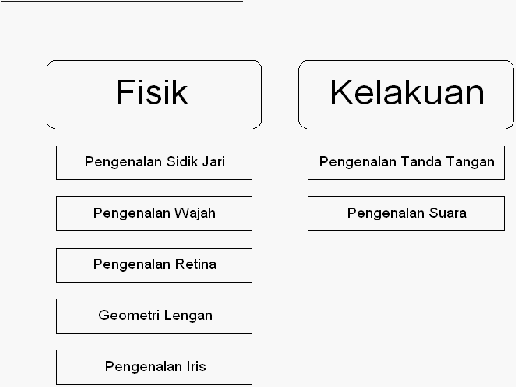
Gambar 2.1 Jenis Biometrik
6
|
|
7
Dalam
dunia
teknologi informasi,
biometrik relevan
dengan
teknologi yang
digunakan untuk menganalisa fisik dan kelakuan manusia untuk autentifikasi. Biometrik
terbagi menjadi dua bagian besar, yaitu biometrik fisik dan biometrik kelakuan.
2.1.2.1 Biometrik Fisik
2.1.2.1.1 Pengenalan sidik jari
Sistem
ini
meliputi
sebuah
perangkat keras
scanner
dan
perangkat
lunak.
Merekam karakteristik sidik jari
yang spesifik,
menyimpan data tiap-tiap user ke dalam
sebuah
template,
ketika
user
mencoba
lagi
menguatkan
akses
maka
perangkat
lunak
akan
membandingkan data
yang tersimpan pada
template
dengan pembacaan sidik
jari
dari scanner. Sistem
sidik jari
sangat
akurat
tetapi
dapat
dipengaruhi oleh
perubahan-
perubahan di dalam sidik jari (terbakar, bekas luka dan sebagainya), kotoran dan faktor-
faktor lain yang menimbulkan gangguan pada gambar.
2.1.2.1.2 Pengenalan wajah
Pengenalan bentuk-bentuk dan posisi dari ciri-ciri wajah seseorang adalah tugas
yang
kompleks.
Pertama
sebuah
kamera
menangkap gambar
dari
sebuah
wajah
dan
kemudian software memilah-milah pola informasi
yang
selanjutnya dibandingkan
dengan template user.
2.1.2.1.3
Pengenalan retina
Mungkin
dari
semua
itu
yang
paling
aman
dari
bekerjanya sistem
biometrik
adalah retina, dan lapisan-lapisan pembuluh yang dilokasikan di belakang mata. Gambar
retina sulit
untuk ditangkap dan selama pendataan user
harus
memusatkan sebuah titik
serta
mempertahankannya
sehingga kamera
dapat
melaksanakan
penangkapan
gambar
dengan
baik.
Hal
yang
sebenarnya ditentukan
adalah
pola
dari
pembuluh-pembuluh
|
|
8
darah. Tetapi ketika pola-pola
ini
unik pada tiap-tiap orang,
identifikasi dapat
menjadi
lebih
presisi.
Sistem
yang
didasarkan pada
dua
bagian
mata,
iris,
dan
retina
adalah
dipertimbangkan untuk menawarkan tingkat keamanan terbaik.
2.1.2.1.4 Geometri lengan
Dengan
sistem
ini, pengguna
meluruskan
lengan
menurut petunjuk
tanda
pada
perangkat keras pembaca lengan (reader), menangkap gambar tiga dimensi dari jari-jari
dan
tulang
kemudian
menyimpan data
dalam sebuah template.
Geometri
lengan
telah
digunakan
selama
beberapa
tahun
dan
dimanfaatkan untuk
sistem
keamanan
pada
perlombaan Olympiade 1996.
2.1.2.1.5 Geometri jari
Peralatan
ini
sama
untuk
sistem-sistem
geometri.
Pengguna
menempatkan satu
atau dua jari di bawah sebuah kamera yang menangkap bentuk dan panjang wilayah jari
serta
tulang-tulangnya. Sistem
menangkap gambar tiga dimensi dan
mencocokkan data
dengan template-template yang disimpan untuk menentukan identitas.
2.1.2.1.6 Pengenalan telapak tangan
Sama dengan pengenalan sidik jari, biometrik telapak tangan memusatkan pada
susunan-susunan yang beragam, misalnya bagian-bagian
tepinya dan bagian-bagian
garis tangan yang ditemukan pada telapak tangan.
2.1.2.2 Biometrik Kelakuan
2.1.2.2.1 Pengenalan suara
Metode
ini
menangkap suara
dari
microphone
menurut
sifat-sifat
bahasa.
Penggunaan utamanya adalah aplikasi keamanan berbasis telepon. Keakurasiannya dapat
dipengaruhi
oleh
beberapa
hal seperti suara
gaduh
dan
pengaruh
dari
penyakit atau
|
|
9
kelelahan
pada suara orang tersebut. Satu masalah nyata dengan pengenalan
suara
adalah
sistem
dapat
dikelabui
oleh suara
tape
dari
suara seseorang. Untuk
alasan
ini
sistem suara
lanjutan
harus
mampu
memperluas atau
memperpanjang proses
verifikasi
dengan
memberikan
perkataan-perkataan yang
lebih
sulit
dan
panjang,
membacanya
dengan keras atau meminta sebuah perkataan yang berbeda yang dibaca setiap waktu.
2.1.2.2.2 Pengenalan tanda tangan.
Sistem
verifikasi
tanda
tangan
memerlukan satu
hal
utama
yaitu
penerimaan
masyarakat umum (publik). Di segala hal dari deklarasi kemerdekaan sampai slip sebuah
kartu
kredit.
Masyarakat
cenderung
untuk
menerima
tanda
tangan
seseorang
sebagai
bukti dari identitasnya. Sebenarnya sistem pengenalan tanda tangan betapa pun terlihat
sederhana sebuah
tanda
tangan,
peralatan mengukur baik
ciri-ciri
yang
membedakan
tanda tangan dan ciri-ciri yang membedakan dari proses penulisan tanda tangan. Ciri-ciri
ini
mencakup
rasio
persebaran
garis,
rasio
panjang
dan
lebar,
arsitektur
bentuk
pada
tanda tangan.
Pola-pola
ini
ditangkap
melalui sebuah
image
yang
telah
di
proses
dan
dibandingkan
dengan
pola-pola
template.
Permasalahannya adalah
tanda
tangan
kita
berbeda secara berarti dan dari satu contoh ke contoh
yang
lain,
sehingga keakurasian
yang sangat kuat membutuhkan banyak contoh dan sebuah proses verifikasi lanjutan.
2.2 Tanda Tangan
Tanda
tangan
atau dalam bahasa inggris disebut
signature
berasal dari
latin
signare
yang berarti tanda adalah tulisan
tangan, terkadang diberi
gaya tulisan tertentu
dari nama seseorang atau tanda identifikasi lainnya yang ditulis pada dokumen sebagai
sebuah bukti dari identitas dan kemauan. Tanda tangan berlaku sebagai segel.
|
|
10
2.3 Pengenalan Pola
Pola adalah bentuk atau model (atau, lebih abstrak, suatu set peraturan) yang bisa
dipakai
untuk
membuat
atau
menghasilkan
suatu
atau
bagian
dari sesuatu,
khususnya
jika sesuatu
yang
ditimbulkan
cukup
mempunyai
suatu
yang
sejenis
untuk
pola
dasar
yang
dapat
ditunjukkan
atau
terlihat,
yang
mana
sesuatu
itu
dikatakan
memamerkan
pola. Deteksi
pola dasar disebut
pengenalan
Pola adalah entitas yang terdefinisi dan dapat diberi suatu
identifikasi atau nama (Murni
dan Setiawan, 1992).
Pengenalan pola digunakan untuk mengenali objek kompleks dari suatu sifat dari
objek yang akan dikenali
ciri-ciri dari objeknya. Pengenalan pola secara
formal dapat
dideskripsikan sebagai
sebuah
proses
yang
menerima
pola
(pattern)
atau
sinyal
berdasarkan hasil pengukuran yang kemudian diklasifikasikan ke dalam suatu atau lebih
kategori / kelas tertentu (Haykin, 1999, p67).
Suatu
sistem
pengenalan
pola
pada dasarnya
terdiri atas
beberapa
tahap,
yaitu
penerimaan data,
pengolahan data,
dan
pengenalan objek
atau
pembuat
keputusan.
Adapun
pendekatan utama
dalam
pengenalan pola adalah pendekatan geometrik
dan
pendekatan struktural.
Pendekatan
struktural
dilakukan
dengan penentuan
dasar
yang
mendeskripsikan objek yang akan dikenali. Sedangkan pendekatan geometrik dilakukan
berdasarkan ciri objek dan pola yang terjadi.
|
|
11
2.4
Soft Computing
Menurut
I
Made
Wiryana,
Ssi,
Skom,
Msc(2004,
Penggunaan Metoda
Softcomputing untuk
Aplikasi
Bisnis),
Metoda
soft
computing
menempati posisi
yang
menarik dalam perkembangan metoda komputasi dan pemecahan masalah pada saat ini.
Hal ini karena ditawarkan solusi yang menarik dan kemudahan implementasi
dari
metoda
ini
untuk
memecahkan
masalah-masalah yang
tadinya sangat sulit
dipecahkan
dengan
komputer dengan
menggunakan
metoda
komputasi konvensional. Metoda
soft
computing tersebut antara
lain
adalah: Artificial Neural Network
(ANN),
Fuzzy Logic
(FL), dan Genetic Algortihm (GA).
Metoda soft
computing
ini
diinspirasikan oleh
cara
manusia
memecahkan
suatu
masalah.
Namun
pendekatan soft
computing
ini
berbeda
dengan
metoda
Artificial
Intelligence
yang
menggunakan pendekatan
simbolik.
Pada pendekatan
simbolik
yang
bertumpu pada Physical
Symbol
System
(PSS), jawaban
suatu masalah
harus
berdasarkan dari keadaan
yang konsisten dari data yang ada (Newel and Simon, 1976)
karena Physical Symbol System tak dapat memberikan solusi bila keadaan chaos.
Dengan kata lain knowledge base yang menjadi basis dari pencarian solusi harus bersifat
koheren, konsisten, dan reasonable (Delgrande and Mylopulos, 1986).
Pada
sistem
konventional, jawaban
akan
diberikan
apabila
seluruh
syarat
dari
permasalahan terpenuhi. Ini menyebabkan sebagian besar dari pendekatan simbolik akan
berakhir
pada
sistem
yang
bersifat
semi-decidable. Sistem
tidak
akan
memberikan
jawaban bila seluruh kondisi
yang diketahui tidak dipenuhi.
Bila keadaan
tidak
terpenuhi, atau
jawaban
tidak
tertemukan sistem
ini
akan
memberikan jawaban
yang
bersifat negatif, sifat inilah yang dikenal dengan sifat semi-decidable dari sistem ini.
|
|
12
Tahun
1990,
merupakan era
baru
dalam
dunia
komputer. Terutama
dengan
diintroduksinya istilah Machine Intelligent Quotient (MIQ) (Zadeh, 1994). Penggunaan
metoda
soft
computing menaikkan MIQ
dari
sistem.
Hal
ini
akan
terasa
manfaatnya
terutama
untuk
aplikasi
yang
dekat
dengan
manusia
sebagai
konsumennya. Pada
pendekatan komputasi
tradisional, syarat dari
seluruh
proses
harus
dilakukan dengan
presisi, certaint, dan sulit dianalisa. Kebalikannya dengan pendekatan "soft computing",
daam hal ini presisi dan kepastian tidak menjadi tuntutan. Sehingga proses pengambilan
keputusan dapat dilakukan dan bertoleransi dengan keadaan yang
impresisi dan
uncertain.
Pada
sistem
yang
berdasarkan dengan
metoda
soft
computing,
karena
pencarian solusi
tidak
melalui
suatu
metoda yang
rigid.
Keadaan
dari
syarat-syarat
problem tidaklah
semuanya
harus dipenuhi.
Ini
akan
sangat
sesuai dengan
pemecahan
masalah sehari-hari
2.5
Verifikasi tanda tangan
Verifikasi
adalah
proses
membandingkan sebuah
sample
biometrik
terhadap
sebuah
refrensi
dari
seorang
pengguna
untuk
memastikan identitas
seseorang
yang
berhubungan dengan
akses
ke
sistem,
pada
sistem
keamanan
dengan
biometrik (
Verifikasi
tanda
tangan
adalah
verifikasi
berdasarkan pada
tanda
tangan
seseorang, dimana tanda tangan yang diberikan dicocokkan dengan sample tanda tangan
yang telah disimpan pada data sebelumnya.
Dalam
proses
verifikasi tanda
tangan
menurut Griess
(2000,p1)
dapat
dibagi
menjadi dua bagian, yaitu :
1. Off-line signature verification (Verifikasi tanda tangan secara off-line)
|
|
13
2. On-line signature verification (Verifikasi tanda tangan secara on-line)
Verifikasi tanda tangan secara off-line
merupakan sebuah signature verification
yang
mengambil sebuah
image
tanda tangan sebagai
input
yang
nantinya akan
digunakan dalam proses selanjutnya. Berbeda dengan verifikasi tanda tangan secara On-
line
dimana
input
berupa
tanda
tangan
yang
di-capture
langsung
dari
digitizer
yang
dapat menghasilkan nilai-nilai dinamik, seperti nilai koordinat dan waktu tanda tangan.
Pada gambar tanda tangan secara
Off-line biasanya memiliki tingkat noise
yang
cukup tinggi dibandingkan dengan gambar image yang di-capture langsung oleh
digitizer
yang
dipakai pada verifikasi
tanda
tangan
secara
On-line,
tetapi
hal
tersebut
tergantung juga pada alat scanning dan background kertas yang digunakan.
Verifikasi tanda
tangan
secara
Off-line
lmemeiliki kelebihan
dari
segi
biaya,
karena biaya yang diperlukan lebih murah dari pada pengenalan tanda tangan secara on-
line,selain
itu
pengenalan tanda
tangan
secara
off-line
lebih diperlukan
dalam
bidang
perbankan, oraganisai atau lembaga dan sebagian besar bank, organisasi, atau
lembaga
di Indonesia.
|
 14
2.6 Jaringan Saraf Tiruan
2.6.1 Cara Kerja Otak Manusia
Gambar 2.2 Otak Manusia
Otak manusia
terdiri atas sel – sel saraf
yang saling berhubungan dan setiap sel
bekerja sebagai prosesor sederhana.
|
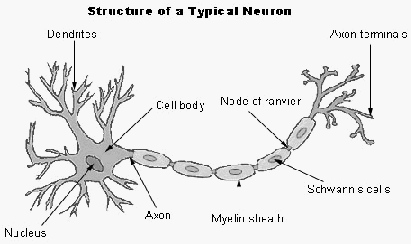 15
Gambar 2.3 Struktur Neuron
Setiap
sel
saraf
akan
memiliki
satu
inti
sel,
inti
sel
inilah
nanti
yang
bertugas
untuk
melakukan pemrosesan
informasi,
informasi
yang
datang
akan
diterima
oleh
dendrit. Selain menerima informasi dendrit juga
menyertai axon akan sebagai keluaran
dari suatu pemrosesan informasi. Informasi hasil olahan yang diterima ini akan menjadi
masukkan bagi
neuron lain
yang mana antar dendrit itu dipertemukan dengan synapsis.
Synapsis adalah struktur dasar yang menghubungkan dua neuron ketika sinyal mencapai
synapsis maka synapsis akan melepaskan suatu bahan kimia yang biasa disebut dengan
neuro transmiter. Neuro
transmiter ini
akan
masuk dan
mengisi celah synapsis dengan
tujuan
untuk
memperkuat
atau
melemahkan sinyal,
tergantung
dari
tipe
synapsis
itu
sendiri. Dikarenakan
bagian receptor dari neuron dapat memancarkan
sinyal listrik
maka, keefektifan sebuah synapsis dapat disesuaikan berdasarkan sinyal yang
melaluinya. Informasi – informasi yang datang akan disalurkan melalui dendrit lalu oleh
dendrit dijumlahkan dan dikirim melalui axon ke dendrit akhir yang bersentuhan dengan
dendrit dari neuron yang lain. Informasi ini diterima oleh neuron lain dan jika memenuhi
|
|
16
batasan tertentu, yang sering dikenal dengan nama nilai ambang / threshold maka neuron
akan dikatakan
teraktivasi. Hubungan antara neuron terjadi secara adaptif,
yang berarti
struktur hubungan tersebut terjadi secara dinamis. Sehingga dapat dikatakan kalau otak
manusia selalu memiliki kemampuan untuk belajar atau beradaptasi.
2.6.2
Definisi Saraf Tiruan
Menurut
DARPA Neural
Network Study
(1988, AFCEA Internasional
Press
P60), Jaringan Saraf
tiruan
adalah
sebuah
system
yang
terdiri atas
banyak
processing
element yang sederhana dalam jumlah yang sangat besar dan terhubung secara parallel
dimana fungsinya ditentukan oleh struktur jaringan tersebut, jenis
hubungannya dengan
proses yang dikerjakan pada masing – masing node.
Jaringan saraf ini meniru kemampuan proses otak dalam dua hal :
1. Jaringan saraf tiruan memperoleh kemampuan berdasarkan proses belajar.
2. Kekuatan hubungan dari masing – masing neuron yang disebut juga dengan
bobot (weight) synapsis berperan dalam menyimpan pengetahuan.
Jaringan saraf tiruan bisa dikatakan sebuah permrosesan informasi yang
mencontoh analogi
sistem
kerja
saraf
biologis
otak
manusia.
Hal
terpenting
yang
dicontoh jaringan
saraf
tiruan
ini
adalah
struktur
dari
sistem
pemrosesan
informasi.
Dimana struktur
tersebut terdiri dari
sejumlah neuron (processing element) yang saling
terhubung erat dan bekerja sebagai suatu kesatuan untuk menyelesaikan masalah
tertentu.
Karena
mencontoh jaringan
saraf
manusia
maka
jaringan
saraf
tiruan
juga
melakukan
pembelajaran
dengan
menggunakan contoh.
Sebuah
jaringan
saraf
tiruan
dapat
digunakan
pada
sebuah
aplikasi
yang
spesifik
seperti
pengenalan pola
atau
klasifikasi dengan
melalui proses
pembelajaran terlebih dahulu. Seperti pada
jaringan
|
|
17
saraf
manusia
yang
berupa
penyesuaian pada
hubungan
synapsis
atau
neuron,
pada
jaringan saraf tiruan juga terdapat tiga karakteristik, yaitu neuron, topologi dan
learning
rules.
2.6.3 Sejarah Jaringan Saraf Tiruan
Menurut Sri Kusuma
Dewi(2003,
Artificial Intelegence Teknik dan Aplikasinya
P208),
jaringan
saraf
tiruan
mulai
mengalami
perkembangannya sejak
tahun
1940,
dimana para ilmuwan
menemukan bahwa psikologi otak sama dengan pemrosesan yang
dilakukan
oleh komputer.
Lalu tahun 1943 McCulloch
dan Pitts merancang
model
model
formal
yang
pertama
kali
sebagai
hitungan
dasar
neuron.
Sehingga
kemudian
Hebb menyatakan informasi dapat disimpan dalam koneksi – koneksi dan
mengusulkan
skema sistem pembelajaran, dan yang kemudian di setup model – modelnya untuk relasi
adaptif
stimulus – respon dalam jaringan random.
Lalu
pada
tahun
1958
Rosenblatt
mengembangkan
konsep
dasar tentang
perceptron
untuk
pengelompokan
pola.
Dan
tahun 1960,
Widrow
dan
Hoff
mengembangkan kendali
adaptif
dan
pencocokan pola
dengan aturan pembelajaran Least Mean Square(LMS).
Tahun
1974, Werbos
mulai
memperkenalkan algoritma back propagation untuk
melatih
perceptron
yang
memiliki
banyak
lapisan.
Pada
tahun
berikutnya,
Little
dan
Shaw mengambarkan jaringan saraf yang menggunakan metode probabilistik.
Pada tahun 1982, Kohenen mengembangkan unsupervised learning(jaringan
saraf
tidak
terawasi)
untuk
proses
pemetaan, pada
tahun
yang
sama
juga
Grossberg
mengembangkan teori jaringan yang diinsipirasikan oleh perkembangan psikologi. Dan
bersama Carpenter mereka
memperkenalkan sejumlah
arsitektur jaringan, antara
lain
:
Adaptive Resonance
Theory(ART), ART2,
dan ART3.
Tahun
itu juga
Hopfield
|
 18
memperkenalkan pengembangan jaringan saraf
reccurent yang dapat digunakan
untuk
menyimpan informasi dan optimasi.
Tiga
tahun
kemudia
pada
tahun
1985
mulai
dikembangkan algoritma
pembelajaran dengan menggunakan mesin Boltzmann. Dan puncaknya pada tahun 1987
yang diperkenalkan oleh Kosko
yang
mengembangkan jaringan
Adaptive
Bidirectional
Associative Memory (BAM). Dan pada tahun 1988 mulai dicoba peengembangan fungsi
radial basis.
2.6.4 Komponen Jaringan Saraf Tiruan
Jaringan saraf
tiruan
terdiri
dari
tiga
lapisan
layer
yaitu
layer
input,
layer
tersembunyi, layer
layer
output.
Walaupun
terkadang
tidak
semua
layer
mempunyai
hidden layer.
2.6.5 Arsitektur Jaringan Saraf Tiruan
Menurut Sri Kumala Dewi, ada beberapa arsitektur jaringan saraf antara lain :
a. Jaringan lapisan tunggal(single-layer net)
b. Jaringan lapisan banyak(multi-layer net)
c. Jaringan lapisan kompetitif (competitive layer net)
2.6.5.1 Jaringan Lapisan Tunggal
Gambar 2.4 Jaringan Lapisan Tunggal
|
 19
Jaringan dengan
lapisan
tunggal
hanya
memiliki satu
lapisan dengan bobot
–
bobot terhubung. Jaringan ini hanya menerima input dan langsung mengolahnya menjadi
output tanpa melalui lapisan tersembunyi (Gambar 2.2).
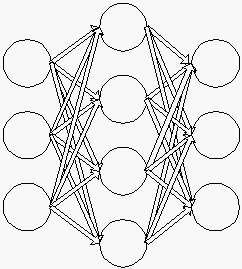
2.6.5.2 Jaringan Lapisan Banyak
Gambar 2.5 Jaringan Lapisan Banyak
Jaringan
dengan
lapisan
banyak
memiliki
satu
atau
lebih
lapisan
tersembunyi.
Jaringan pada
lapisan banyak
ini
daoat
menyelesaikan
permasalahan
yang
lebih
sulit
daripada
lapisan
dengan
lapisan
tunggal, dan
juga
memiliki pembelajaran yang
lebih
rumit.Namun demikian pada banyak kasus, pembelajaran pada jaringan dengan banyak
lapisan ini lebih sukses dalam menyelesaikan masalah.
|
 20
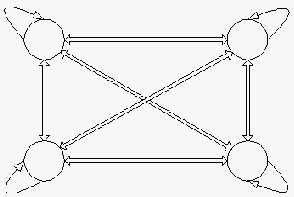
2.6.5.3 Jaringan Lapisan Kompetitif
Gambar 2.6 Jaringan Lapisan Kompetitif
Biasanya
hubungan
antar
neuron
dalam
lapisan
ini
tidak
diperlihatkan pada
diagram arsitektur. Salah satu contoh arsitektur jaringan dengan lapisan kompetitif yang
memiliki bobot -n.
2.6.6
Metode Pembelajaran
Pada
otak
manusia,
proses
pembelajaran terjadi
pada
neuron
dan
dendrit.
Informasi
yang
diterima ini
berupa
suatu
reaksi
yang
terjadi
pada
dendrit. Proses
pembelajaran
pada otak
manusia
sangatlah
sulit
untuk dipahami, proses pembelajaran
pada otak manusia tergantung pada bobot yang
terdapat pada neuron – neuron, apabila
rangsangan
yang
diterima
berbeda
maka
bobot
neuron
juga
akan
berbeda
sehingga
terjadi adaptasi dari neuron.
Proses pembelajaran pada jaringan saraf tiruan juga tersusun atas neuron-neuron
dan
dendrit.
Proses
pembelajaran pada
jaringan
syaraf
terjadi
ketika
terjadi perubahan
nilai bobot. Ketika waktu pembelajaran dilakukan dengan input yang berbeda sehingga
|
|
21
mencapai suatu nilai yang cukup seimbang. Nilai dikatakan cukup seimbang jika tiap –
tiap input telah berhubungan dengan input yang diharapkan.
Ada dua tipe proses pembelajaran :
a. Pembelajaran terawasi (supervised learning)
b. Pembelajaran tak terawasi (unsupervised learning)
2.6.6.1 Pembelajaran Terawasi
Metode
pembelajaran ini
disebut
terawasi
jika
output
yang
diharapkan
telah
diketahui sebelumnya. Maksudnya adalah pada proses pembelajaran satu pola input akan
diberikan
kepada
satu
neuron
pada
satu pola
input.
Lalu
pola
ini
dirambatkan pada
sepanjang jaringan saraf. Lalu lapisan output ini akan membangkitkan pola outpun yang
kemudian akan
dicocokkan
dengan pola
output
dari
target.
Apabila
terjadi perbedaan
antara pola output hasil pembelajaran
dengan pola output target, maka akan
menghasilkan nilai error. Dan bila
nilai error cukup besar maka akan dilakukan proses
pembelajaran sekali
lagi.
Ada
beberapa
metode
dalam
supervised
learning
atau
pembelajaran terawasi.
2.6.6.1.1 Hebb Rule
Hebb rule
adalah
metode
pembelajaran yang
paling
sederhana. Pembelajaran
pada
metode
ini
dilakukan
dengan
cara
memperbaiki nilai
bobot
sedemikian
rupa
sehingga jika ada dua neuron yang terhubung dan keduanya berada dalam kondisi nyala
/
on pada waktu yang sama,
maka bobot antara keduanya akan dinaikkan, perbaikkan
bobot dapat dirumuskan sebagai berikut :
W
i
(baru) = W
i
(lama) + X
i
* Y
|
|
22
Dengan : W
i
:
bobot input ke-i;
X
i
:
input data ke-i;
Y : output data.
2.6.6.1.2 Perceptron
Perceptron
juga
termasuk
salah
satu bentuk
jaringan saraf
yang
sederhana.
Perceptron
pada dasarnya
digunakan
untuk
mengklasifikasikan suatu
tipe pola tertentu
atau biasa dikenal dengan pemisahan secara linear. Pada dasarnya, perceptron memiliki
bobot yang bisa diatur dan suatu nilai ambang.
2.6.6.1.3 Delta Rule
Pada
delta
rule
akan
mengubah bobot
yang
menghubungkan
antara
jaringan
input
ke unit
output dengan
nilai
target.
Hal
ini dilakukan untuk
meminimalkan error
selama pelatihan
pola.
Delta rule
untuk
memperbaiki bobot
ke-i
(untuk
setiap
pola)
adalah:
?W
i
=
a
(t – y_in)*X
i
Dengan :
x
=
vektor input.
Y_in =
input jaringan ke unit output Y.
t
=
target (output).
Kemudian nilai baru akan didapat dari nilai w lama ditambahkan dengan ?w.
W
i
= W
i
+
?W
i
|
|
23
2.6.6.1.4 Backpropagation
Backpropagation merupakan
algoritma
pembelajaran
yang
terawasi
dan
biasanya
digunakan
oleh perceptron
dengan banyak
lapisan
untuk
mengubah
bobot
–
bobot
yang
terhubung dengan
neuron
–
neuron
yang
ada
pada
lapisan
tersembunyi.
Backpropagation menggunakan error output untuk mengubah nilai bobotnya dalam arah
mundur.
Hanya
saja
demi
mendapatkan error
ini
harus
dilakukan
perambatan
maju
terlebih dahulu.
2.6.6.1.5 Heteroassociative memory
Jaringan ini adalah jaringan yang bobot – bobotnya ditentukan sedemikian rupa
sehingga jaringan tersebut dapat menyimpan kumpulan pengelompokan pola.
2.6.6.1.6 Bidirectional Associative Memory (BAM)
BAM
adalah
model
jaringan
saraf
yang
memiliki
dua
lapisan dan terhubung
penuh
dari
suatu
lapisan
ke
lapisan
lainnya.
Pada
jaringan
ini
dimungkinkan adanya
hubungan timbal balik antara lapisan input dan lapisan output. Namun demikian bobot
yang
menghubungkan
antara
satu neuron
di satu lapisan
dengan
neuron
di lapisan
lainnya akan sama dengan bobot yang menghubungkan neuron kebalikkannya atau dapat
dikatakan, matriks bobot yang
menghubungkan neuron – neuron pada lapisan output ke
lapisan input sama dengan transpose matriks bobot neuron neuron yang menghubungkan
lapisan input ke lapisan output.
2.6.6.1.7 Learning Vector Quantization
Learning
Vector
Quantization adalah
suatu
metode
untuk
melakukan
pembelajaran pada
lapisan
kompetitif
yang
terawasi.
Lapisan
kompetitif
akan
secara
otomatis belajar untuk
mengklasisfikasikan vektor – vektor
input. Kelas – kelas
yang
|
|
24
didapatkan sebagai hasil dari
lapisan kompetitif ini
hanya tergantung pada jarak antara
vektor – vektor input. Karena jika ada dua vektor input mendekati sama makan lapisan
kompetitif akan meletakkan kedua vektor tersebut dalam kelas yang sama.
2.6.6.2 Metode Pembelajaran Tak Terawasi
Metode pembelajaran yang tak terawasi ini tidak memerlukan target output. Pada
metode
pembelajaran ini
tidak
ditentukan
hasil
apa
yang
diharapkan
selama
proses
pembelajaran, nilai bobot disusun dalam suatu range tertentu tergantung pada nilai input
yang diberikan. Tujuan pembelajaran ini biasanya
adalah
mengelompokkan unit –
unit
yang
hampir
sama
dalam
suatu
area
tertentu.
Pembelajaran
ini biasanya
digunakan
dalam klasifikasi / pengelompokan pola.
2.7 Image Processing
2.7.1 Pengertian image processing
Citra atau
image adalah angka (image
is just
a
number), dari
segi estetika,
citra
atau gambar adalah kumpulan warna yang bisa terlihat indah, memiliki pola, berbentuk
abstrak
dan
lain
sebagainya.
Image
dapat
dikatakan
juga
sebagai
sebuah
gambar atau
foto
yang ditampilkan
atau
bentuk
lain
yang
memberikan representasi
visual tentang
sebuah
objek
atau
pemandangan (
digital-image-processing.html).
Image processing
adalah suatu proses
yang menganalisis dan
memanipulasi
gambar
dengan
menggunakan komputer.
Image
processing
umumnya
melibatkan
3
langkah dalam prosesnya, yaitu :
•
Mengimport suatu gambar dengan optical scanner atau langsung dengan
digital photography. Hasilnya berupa digital image.
|
 25
•
Memanipulasi
atau menganalisis
suatu gambar dengan teknik tertentu.
Memanipulasi
gambar
berarti
termasuk
image
Enchanment
dan
data
Compression, sedangkan menganalisis suatu gambar berarti mencari pola
tertentu yang tidak tampak oleh mata manusia.
•
Mengeluarkan hasilnya. Mengeluarkan hasilnya bisa suatu gambar yang telah
diubah dengan cara tertentu atau berupa laporan hasil analisa gambar tersebut.
2.7.2 Citra digital
Citra digital adalah representasi dari citra dua dimensi sebagai sebuah set dari nilai
digital, yang disebut dengan picture elements atau pixel. Citra digital ini berisi nilai dari
kolom dan baris dari pixel. Pixel adalah elemen
terkecil dari sebuah citra,
yang berisi
nilai yang merepresentasikan kecerahan warna yang di spesifikasikan pada titik tertentu.
Biasanya, pixel yang tersimpan di
memory computer sebagai citra raster atau peta
raster, sebuah array dua dimensi dari interger kecil. Nilai ini lalu disimpan dalam bentuk
yang telah di compressed.
Citra digital dapat dibentuk dengan berbagai jenis alat dan teknik, seperti kamrea
digital, scanners, coordinate-measuring machines, seismographic profiling, airbone
radar, dan
lain
lain. Citra digital
juga dapat di sintesis dari data
yang
tidak berbentuk
gambar, seperti fungsi matematik, atau model geometri tiga dimensi, selanjut bidang ini
akan
menjadi
bagian
dari
grafik
komputer.
Dimana
akan
mempelajari bagaimana
Citra
digital
dibagi
menjadi
3
menurut
jumlah
tingkat
kuantitas
dan
warnanya
|
|
26
a. Citra biner (binary image)
Merupakan citra dimana setiap pixel hanya punya 2 nilai biasanya 0 dan 1 atau
hitam
dan
putih.
Terkadang
ada
yang
menyebutnya 0
dan
255
(sebagai
pengganti 1).
b. Citra keabuan (gray image)
Merupakan citra yang mempunyai jumlah tingkat kuantitas yang lebih dari 2.
c. Citra warna (color image)
Citra dimana setiap pixel selain punya nilai tingkat kuantitas juga mempunyai
warna. Citra warna mempunyai komponen RGB (Red Green Blue).
Berdasarkan jumlah
tingkat kuantisasi untuk setiap jumlah warna
yang dapat
ditampilkan
ditentukan.
Sesuai
dengan
namanya
warna
ini
terdiri
dari
tiga
warna
dasar
yaitu
merah
(red),
hijau
(green),
biru (blue), dimana
masing –
masing warna tersebut memiliki tingkat intensitas warna yang berkisar antara 0
–
255, dimana menunjukkan keterangan warna dimulai dari warna yang paling
gelap hingga warna yang paling terang. Banyaknya warna yang dapat dibentuk
oleh
model warna
RGB
ini
adalah
sebanyak 256 (intensitas piksel merah) x
256 (intensitas piksel
hijau) x 256 (intensitas piksel biru). Sehingga totalnya
kurang lebih adalah sebanyak enam belas juta tujuh ratus ribu warna, dan ini
merupakan variasi warna yang sangat banyak. (
Sebuah piksel berwarna akan terbentuk dari gabungan warna dasar yang tersedia.
Arsitektur warna dari RGB dapat dilihat sebagai berikut :
|
|
27
1. Warna merah akan terbentuk jika piksel
hijau dan biru bernilai 0 sedangkan
piksel merah berukuran antara 1 – 254.
2. Warna hijau akan terbentuk jika piksel
merah dan biru bernilai 0 sedangkan
piksel hijau bernilai antara 1 – 254.
3. Warna biru akan terbentuk jika piksel
merah dan
hijau bernilai 0 sedangkan
piksel biru bernilai antara 1 – 254.
4. Warna kuning akan terbentuk jika hanya piksel biru saja yang yang bernilai 0,
sedangkan piksel merah dan hijau bernilai sama besar.
5.
Warna
magenta akan terbentuk jika
hanya piksel
hijau saja
yang bernilai 0,
sedangkan piksel merah dan biru bernilai sama besar.
6. Warna cyan akan terbentuk jika hanya merah saja yang bernilai 0, sedangkan
piksel biru dan hijau bernilai sama besar.
7. Warna keabuan akan terbentuk jika semua dasar RGB bernilai sama.
8. Warna hitam akan terbentuk jika semua dasar RGB bernilai 0.
9. Warna putih akan terbentuk jika semua warna dasar RGB bernilai 255.
10. Selain kesembilan penjelasan diatas
warna
yang terbentuk merupakan varian
model warna dari RGB.
Berikut adalah jenis-jenis format grafik :
a. BMP
merupakan
format file
format dasar
untuk
Windows.
Format
file
ini
mendukung RGB, gray scale, Bitmap, maupun indexed color tetapi tidak medukung
alpha
channel.
BMP
terdiri
atas
dot-dot atau
bit-bit
yang
tersusun
yang
akan
terbentuk dalam suatu gambar.
|
 28
b. JPEG (Join Photographic Expert Group)
Merupakan format gambar yang banyak digunakan untuk menyimpan gambar-
gambar dengan ukuran lebih kecil. Beberapa karakteristik gambar JPEG :
•
Mempuyai ekstensi *.JPG atau *.JPEG
•
Mampu menayangkan warna dengan kedalaman 24-bit true color.
•
Umumnya digunakan untuk menyimpan gambar hasil foto.
c. GIF (Graphic Interchange Format)
Format GIF
pertama kali diperkenalkan oleh CompuServe pada tahun 1987.
Beberapa karakteristik format GIF :
•
Mampu
menayangkan
maksimum sebanyak 256
warna karna format
GIF
menggunakan 8-bit untuk setiap pixelnya.
•
Mengkompresi gambar dengan sifat lossless
•
Mendukung warna transparan dan animasi sederhana.
d. PNG (Portable Network Graphic)
Merupakan
salah satu
format penyimpanan citra
yang
menggunakan metode
pemadatan yang tidak menghilangkan bagian dari citra tersebut.
Untuk Web format PNG mempunyai 3 keuntungan dibandingkan format GIF :
•
Channel Aplha (Transparansi)
•
Gamma (pengaturan terang gelapnya citra atau Brightness)
•
Penayangan citra secara progresif (Progressive Display)
|
|
29
e. TIFF (Tagged Image File Format)
Merupakan
format file yang
biasa
digunakan
pada
desktop publishing dan
juga
percetekan.
f.
PICT merupakan format file untuk Mac yang mana dapat menanmpung objek vector
dan bitmap.
g. EPS (Encapsulated PostScript)
Merupakan format file
unt
mentransfer graphic (vector atau bitmap) dalam bahasa
postscript antar aplikasi.
h. PSD
merupakan
format
standart
photoshop
yang
mana
mendukung
semua
mode
citra dan tidak terkompresi.
i.
Dan Sebagainya.
2.8
Image Pre-Processing
Sebuah tanda tangan merupakan kumpulan dari beberapa spesial karakter yang di
mana terkadang sulit
untuk dibaca.
Hal tersebut disebabkan karena adanya
variasi dan
perbedaan-perbedaan tiap bentuknya.
Menurut Griess (2000,p30), untuk mencegah pengaruh dari perbedaan ukuran pada
hasil
matching,
maka
tanda
tangan
harus
dinormalisasikan terlebih
dahulu.
Untuk
membandingkan
Special
Features
dari
sebuah
tanda
tangan.
Berikut
ini
merupakan
tahap proses untuk vertifikasi sebuah tanda tangan :
|
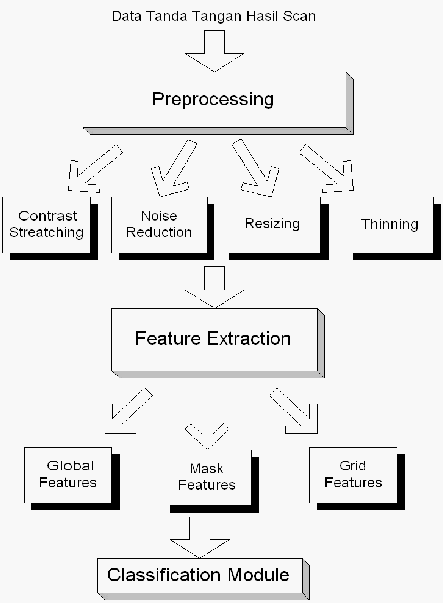 30
Gambar 2.7 Bagan Proses Vertifikasi Tanda Tangan
Pada awalnya dalam proses pengenalan tanda tangan, terlebih dahulu kita harus
memiliki tanda
tangan.
Tanda
tangan
dapat diperoleh dengan cara
scan
ataupun
foto
dengan
hasil
berupa
image
yang
dimana
nantinya
image
tersebut
akan
diproses,
dan
hasil
pemprosesannya menjadi
inputan dalam proses pengenalan ataupun pembelajaran
nantinya. Setelah image diperoleh berikut tahap-tahap yang kita bisa lakukan :
|
 31
Gambar 2.8 Image Hasil Scan
2.8.1 Contrast Streching
Pada
tahapan ini
image
yang
didapat dari
hasil
scan
atau
foto
akan
di
ubah
menjadi
gray
image
lalu diatur contrast gray
nya, setelah
itu pada
image tersebut akan
dilakukan binerisasi yaitu diubah
ke
black
and
white
image.
Contrast
stretching
ini
berguna untuk melihat noise-noise
yang terdapat pada
image serta
memperjelas garis –
garis yang terdapat pada tanda tangan.
Gambar 2.9 Contrast Streching
|
 32
2.8.2 Noise Reduction
Noise reduction berguna untuk menghilangkan titik yang terdapat pada background
yang dianggap sebagai sebagai noise. Dari pixel yang di pilih akan kami gunakan metode
nearest neighbour, jika pixel hitam lebih besar dari pixel putih maka pixel tersebut akan
berwarna hitam dan juga sebalik nya.
Gambar 2.10 Menghapus Noise
2.8.3
Resizing
Pada tahap resizing ukuran image akan di ubah sesuai ukuran yg di tentukan agar
semua
image
yang
akan
di
uji
seragam
ukurannya
sehingga
menghasilkan output
yg
sesuai,
menurut
Desi
Alex
Lestari
(1998,
Implementasi
Teknik Watermarking
Digital
Pada
Domain
DCT
Untuk
Citra
Berwarna
P33-34),
Ada
beberapa
teknik
interpolasi
yang
biasa
dipakai
untuk
pengubahan
ukuran (resizing),
teknik-teknik
tersebut
adalah
nearest
neighbor, bilinear
dan
bicubic. Pada
interpolasi
nearest
neighbor,
nilai piksel
|
 33
yang baru diisi dengan nilai piksel terdekat yang sudah ada. Sehingga ketika sebuah citra
diperbesar, teknik ini
menggandakan piksel, dan ketika citra ukurannya diperkecil maka
ia
akan
menghapus
piksel.
Cara
ini
memang
lebih
cepat
dibandingkan dua
teknik
interpolasi lainnya, meskipun demikian kelemahan utama teknik ini terlihat pada operasi
perbesaran, tepian obyek didalam citra terlihat bergerigi. Pada operasi pengecilan, citra
yang
dihasilkan terlihat
kurang
halus.
Teknik
kedua,
bilinear,
bekerja
dengan
menggunakan nilai dari keempat piksel-piksel disekitarnya, yaitu : atas, bawah, kiri dan
kanan dari titik dimana piksel baru akan dibuat. Nilai dari piksel ini ditentukan dengan
menghitung bobot rata-rata dari empat piksel (array 2x2) yang menurut jaraknya paling
dekat.
Hasil
dari
teknik
ini
memang
lebih
halusdibandingkan dengan
teknik
yang
pertama. Pada teknik terakhir, bicubic,
nilaipiksel baru ditentukan dengan menghitung
bobot rata-rata 16 piksel (array 4x4) yang menurut jaraknya paling dekat. Citra hasil dari
teknik ini jauh lebih halus dibandingkan dengan menggunakan teknik yang pertama.
2.8.4 Thinning
Di
tahap
ini
bertujuan
untuk
menghilangkan
perbedaan
ketebalan
pada
tanda
tangan. Metode yang digunakan pada tahap ini adalah metode skeletoning.
Gambar 2.11 Thinning
|
 34
2.8.5
Cropping
Cropping
adalah
memotong
satu
bagian
dari citra
sehingga
memperoleh citra
yang berukuran lebih kecil. Cropping juga berarti pemotongan dari bagian image untuk
meningkatkan konsentrasi gambar yang diutamakan cropping biasa dilakukan pada foto
yang berbentuk fisik, benda seni, atau citra digital yang ingin didapatkan agar. Croping
pada photography meliputi menghilankan area yang tidak diinginkan pada citra, sedang
pada
bagian persiaran / broadcasting cropping dapat
berarti penghilangan image
tanpa
adanya
stretchin
gambar
pada
bagian
ini
biasanya
citra
dipotong
agar
dapat
tampil
sesuai
dengan
standar
telvisi.Operasi ini
pada
dasarnya adalah operasi
translasi
yang
menggeser koordinat titik citra, rumus yang digunakan yaitu:
X’ = X - X
L
untuk X = X
L
sampai XR
Y’ = Y - Y
T
untuk Y = Y
T
sampai Y
B
Gambar 2. 12 Gambar Cropping
2.9 Tahap Ekstraksi Fitur
Dalam mengekstraksi fitur dapat dilakukan berbagai macam tahap, diantaranya :
|
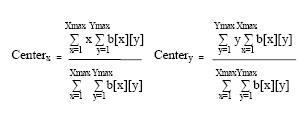 35
2.9.1
Global Feature
Pada
global
feature
menyediakan
informasi
spesifik
mengenai bentuk
tanda
tangan,yang meliputi:
2.9.1.1 Signature area
Yaitu jumlah pixel pixel yang terdapat pada tanda tangan. Feature ini berfungsi
untuk mendapatkan informasi tentang kepadatan tanda tangan.
2.9.1.2 Signature height to width ratio
Feature
ini untuk mendapatkan
ratio lebar dan tinggi tanda tangan.
Hal ini
disebabkan karena terkadang tinggi dan lebar tanda tangan seseorang suka berbeda-beda.
2.9.1.3 Maximum horizontal histogram dan maximum vertical histogram
Pada feature ini akan dicari tinggi dan lebar maksimal dari tanda tangan dengan
menggunakan histogram
2.9.1.4 Horizontal dan vertical center of the signature
Dihitung dengan rumus
2.9.1.5 Local maximum of the signature
Nilai local maxima dari perhitungan
histogram garis vertical dan horizontal
2.9.1.6 Edge point number of signature
Edge point adalah pixel yang
hanya berpasangan dengan 1 pixel
lainnya,dapat
dicari dengan menggunakan metode 8-neighbour.
|
 36
Gambar 2.13 Global Features (a) Signature Area (b) Height Ratio
(c) Maximum Vertical Histogram (d) Maximum Horizontal Histogram
(e) Horizontal Center (f) Vertical Center (g) Horizontal Local Maxima Numbers
(h) Vertical Local Maxima Numbers (i) Edge Points
2.9.2
Mask Features
Mask
features
menyediakan
informasi
tentang
arah
garis
pada
tanda
tangan
,setiap orang
memiliki sudut tanda tangan yang berbeda.
Contoh:
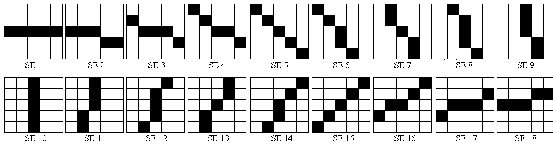
Dengan
Signature
stroke orientation:
sebuah
sistem
yang
mengunakan
beberapa
komponen
yang
membentuk structuring
elements
(SEs)
yang
merepresentasikan potongan
garis pendek
dengan
kecenderungan sudut
yang berbeda.
Menurut Luan Lee (1999, A Prototype For Brazilian Bankcheck Recognition).
Gambar 2.14 Contoh Struktur Elements (SEs) 3 x 3
|
 37
Gambar 2.15 Contoh Struktur Elements (Ses) 5 x 5
Setelah
dicocokan dengan
structuring
element
maka
akan
dilihat
frekuensi
kesamaannya.
2.9.3
Grid Feature
Pada
grid
feature,
image
tanda
tangan
akan
dibagi-bagi
menjadi
kotak-kotak
untuk
mendapatkan
nilai tiap kotaknya
yang
nantinya
akan digunakan
dalam
Proses
Learning
dan classification module.
2.10
Matching / Comparison
Menurut Griess,
pada proses
verifikasi tanda
tangan
yang
dimasukkan
adalah
dengan membandingkan
tanda tangan tersebut dengan data referensi yang terdapat
dalam
sistem.
Data
tanda
tangan
yang
dimasukkan ke
dalam
sistem
biasanya
berkisar
antara 3 – 10 tanda tangan.
Sebuah tanda tangan yang
ingin di
uji
akan dibandingkan dengan refrensi tanda
tangan yang telah terdapat dalam sistem, dan menggunakan nilai-nilai feature-featurenya
sebagai penentu apakah tanda tangan tersebut asli atau palsu.
|
 38
2.11
Fuzzy Logic
2.11.1 Pengertian Logika Fuzzy
Logika fuzzy adalah salah
satu cara
yang tepat untuk memetakan suatu ruang
input ke dalam suatu ruang output (Kusumadewi dan Purnomo,2004).sebagai contoh:
1.
Manajer
pergudangan
mengatakan pada
manajer
produksi
seberapa
banyak
persediaan
barang
pada
akhir
minggu
ini.kemudian manajer
produksi
akan
menetapkan jumlah barang yang harus di produksi esok hari
2.
Pelayanan restoran
memberikan pelayanan terhadap
tamu,
kemudian
tamu
akan
memberikan tip yang sesuai atas baik tidaknya pelayanan yang di berikan.
3. Anda
mengatakan
pada saya
seberapa
sejuk
ruangan
yang anda
inginkan,saya
akan mengatur putaran kipas yang ada pada ruangan ini.
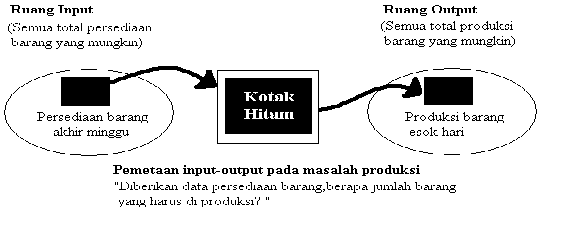
Salah satu contoh pemetaan suatu input – output dalam bentuk grafis seperti pada
gambar berikut:
Gambar 2.16 Contoh Pemetaan Input Output
Antara input dan output terdapat satu kotak hitam yang harus memetakan input
ke output yang sesuai.
|
|
39
2.11.2 Alasan Penggunaan Logika Fuzzy
Ada beberapa alasan orang menggunakan logika fuzzy, diantaranya :
•
Konsep
logika fuzzy mudah dimengerti. Konsep
matematis yang mendasari
penalaran fuzzy sangat sederhana dan mudah dimengerti.
•
Logika fuzzy bersifat sangat fleksibel.
•
Logika fuzzy juga memiliki toleransi terhadap data – data yang tidak tepat.
•
Logika
fuzzy
mampu
memodelkan
fungsi –
fungsi
non–linear yang
sangat
kompleks.
•
Logika
fuzzy dapat membangun
dan mengaplikasikan pengalaman
–
pengalaman para pakar secara langsung tanpa harus melalui proses pelatihan.
•
Logika fuzzy dapat bekerjasama dengan teknik – teknik kendali secara
konvensional.
•
Logika fuzzy didasarkan pada behasa alami.
2.11.3 Fungsi Keanggotaan
Fungsi keanggotaan adalah suatu kurva yang menunjukkan pemetaan titik – titik
input ke dalam nilai keanggotaan.
Fungsi keanggotaan
sering juga disebut dengan
derajat keanggotaan.
Fungsi keanggotaan biasanya memiliki interval antara 0 sampai dengan 1. salah
satu cara
yang
dapat
digunakan
untuk
mendapatkan
nilai
keanggotaan adalah dengan
melalui pendekatan fungsi.
Ada beberapa fungsi yang dapat digunakan untuk menggambarkan keanggotaan,
seperti :
|
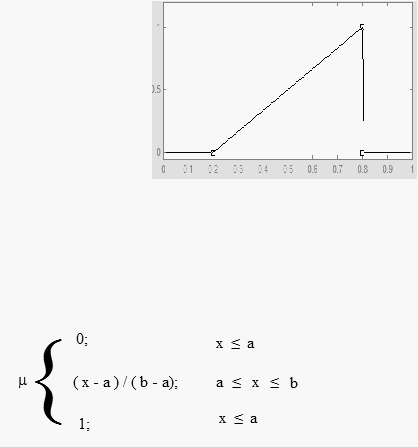 40
a.
Representasi Linear
Pada representasi
linear, pemetaan
input
kederajat anggotanya digambarkan
sebagai suatu garis lurus. Bentuk ini paling sederhana dan menjadi pilihan terbaik untuk
mendapatkan suatu konsep yang kurang jelas.
Terdapat dua keadaan
himpunan fuzzy yang
linear. Pertama, kenaikan
himpunan
dimulai
pada
nilai
domain
yang
memiliki
derajat
keanggotaan
nol
(0).
Bergerak
ke
kanan menuju domain yang lebih tinggi.
Gambar 2.17 Representasi Linear Naik
Fungsi keanggotaan :
Himpuanan
fuzzy
yang kedua
merupakan
kebalikan
yang pertama.
Garis
lurus
dimulai dari
nilai domain dengan derajat keanggotaan tertinggi pada
sisi kiri,
kemudia
bergerak menurun ke nilai domain yang memiliki derajat keanggotaan yang lebih
rendah.
|
 41
Gambar 2.18 Representasi Linear Turun
Fungsi keanggotaan :
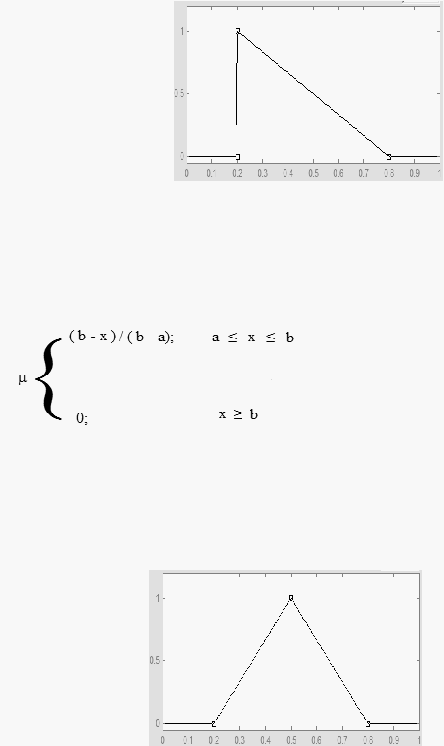
b.
Representasi Kurva segitiga
Kurva
segitiga pada dasarnya merupakan
gabungan antara dua garis yang
lurus
atau linear.
Gambar 2.19 Representasi Kurva Segitiga
|
 42
Fungsi keanggotaan :
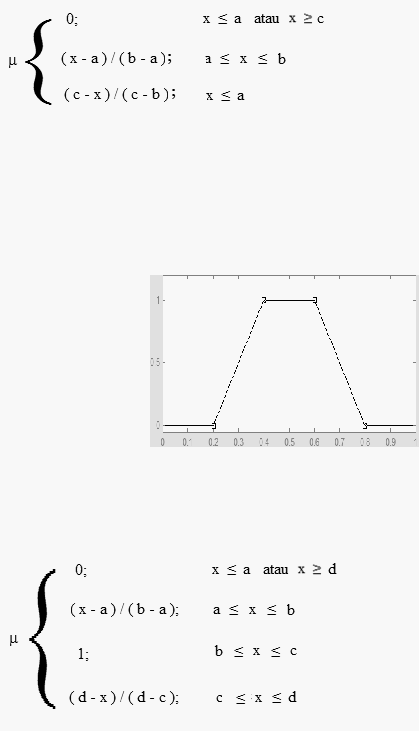
c.
Representasi Kurva Trapesium
Kurva
trapesium pada dasarnya seperti bentuk segitiga,
hanya saja ada beberapa
titik yang memiliki nilai keanggotaan 1.
Gambar 2.20 Representasi Kurva Trapesium
Fungsi keanggotaan :
|
 43
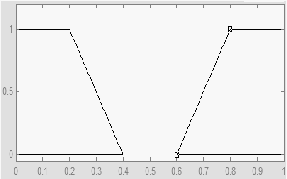
d.
Representasi Kurva Bahu
Daerah
yang
terletak
di
tengah
–
tengah
suatu
variabel yang
direpresentasikan
dalam bentuk
segitiga, pada
sisi
kanan
yang
kirinya
akan
naik
dan
turun.
Tetapi
terkadang salah satu sisi dari variabel tersebut tidak mengalami perubahan.
Gambar 2.21 Representasi Kurva Bahu
Himpunan
fuzzy
’bahu’,
bukan
segitiga,
digunakan
untuk
mengakhiri variabel
suatu
daerah fuzzy. Bahu kiri bergerak dari benar ke salah dan bahu kanan bergerak dari salah
ke benar.
e.
Representasi kurva S
kurva – S atau sigmoid adalah kurva yang mampu merepresentasikan kenaikan dan
penurunan permukaan secara tidak linear.
Kurva – S naik akan bergerak dari sisi paling kiri (nilai keanggotaan = 0) ke sisi
paling kanan ( nilai keanggotaan = 1) fungsi keanggotaannya akan bertumpu pada 50%
nilai keanggotaannya yang sering disebut dengan titik infleksi.
|
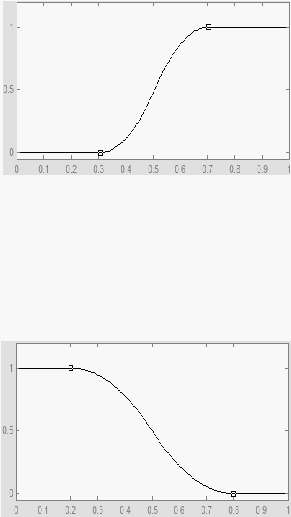 44
Gambar 2.22 Representasi Kurva – S Naik
Kurva – S akan bergerak dari sisi paling kanan ( nilai keanggotaan = 1) ke sisi
paling kiri (nilai keanggotaaan = 0).
Gambar 2.23 Representasi Kurva – S Turun
Kurva – S didefinisikan dengan menggunakan tiga (3) parameter, yaitu :
•
Nilai keanggotaan nol (a ),
•
Titik infeksi atau crossover (ß), dan
•
Nilai keanggotaan lengkap (?).
Fungsi keanggotaan pada kurva – S naik :
|
 45
Fungsi keanggotaan pada kurva – S turun :
f.
Representasi Kurva Bentuk Lonceng ( Bell Curve)
Untuk merepresentasikan bilangan
fuzzy,
biasanya
digunakan
kurva
berbentuk
lonceng. Kurva bentuk lonceng dibagi menjadi tiga (3) kelas, yaitu :
•
Kurva p
Kurva
p
berbentuk
lonceng
dengan
derajat
keanggotaan 1,
terletak
pada
pusat
dengan domain (?) dan lebar kurva (ß).
Gambar 2.24 Representasi Kurva p
|
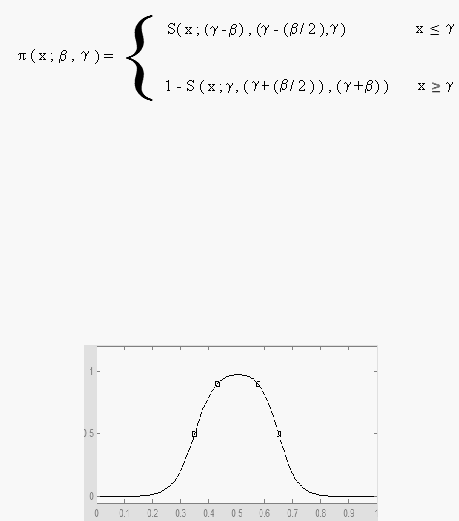 46
Fungsi Keanggotaan pada kurva p
•
Kurva BETA
Seperti halnya kurva p, kurva BETA juga berbentuk lonceng, namun lebih rapat.
Kurva
in
juga
didefinisikan dengan
2
parameter,
yaitu
nilai
pada
domain
yang
menunjukkan pusat
kurva
(?),
dan
setengah
lebar
kurva
(ß).
Salah
satu
perbedaan
mencolok kurva BETA bila dibandingkan dengan kurva p adalah fungsi keanggotaanya
akan mendekati nol jika dan hanya jika nilai (ß) sangat besar.
Gambar 2.25 Representasi Kurva BETA
Fungsi Keanggotaan pada kurva BETA
B
( x ; ? , ß ) = 1 / ( 1 + ( ( x – ? ) -
ß
)²
|
 47
•
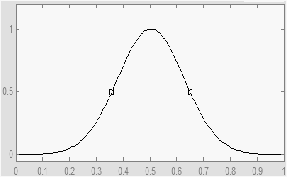
Kurva GAUSS
Jika kurva p dan kurva BETA menggunakan dua parameter, yaitu (?) dan (ß) kurva
GAUSS juga
menggunakan (?)
untuk
menunjukkan nilai domain pada pusat, dan (k)
yang menunjukkan lebar kurva.
Gambar 2.26 Representasi Kurva GAUSS
Fungsi Keanggotaan pada kurva GAUSS
G
( x ; k , ? ) = e
–k(?–x)^2
g.
Koordinat Keanggotaan
Himpunan fuzzy berisi berisi
urutan pasangan berurutan yang berisi domain dan
kebenaran nilai keanggotaanya dalam bentuk :
Skalar(i) / derajat(i)
’Skalar” adalah suatu nilai yang digambar dari domain himpunan fuzzy, sedangkan
’Derajat’ skalar merupakan derajat keanggotaan himpunan fuzzynya.
|
 48
2.11.4 Definisi Cluster
Cluster adalah beberapa gabungan dari individual yang mirip yang terjadi secara
bersamaan (http://fuzzy.iau.dtu.dk/download/nfmod.pdf), misal
a. dua atau lebih konsonan yang berkelanjutan atau vokal dalam sebuah pidato
b. sekelompok rumah
c. sebuah agregasi dari bintang atau galaksi yang muncul berdekatan pada
cakrawala dan saling berhubungan dalam gravitasi.
Data cluster juga dapat disebut sebagai pengklusteran data dan
merupakan suatu
teknik umum dalam menganalisis
data statistik dan juga digunakan dalam banyak
bidang,
seperti
machine
learning,
data
mining,
pengenalan
pola
(pattern
recognition),
analisis
citra
dan
bioinformatics.
Clustering
atau
disebut
juga
pengklusteran adalah
penggolongan objek – objek serupa ke dalam kelompok – kelompok berbeda, atau lebih
tepatnya penyekatan dari suatu set data ke dalam kluster – kluster, sehingga data pada
setiap
kluster
berbagi beberapa
ciri
umum
dan
memiliki
tingkatg kedekatan menurut
beberapa ukuran jarak.
2.11.5 Analisis Cluster
Analisis
Cluster
merupakan sebuah
teknik
klasifikasi
secara
teknikal
untuk
menemukan apakah
individu
dari
populasi
termasuk
ke
dalam
grup
mana
dengan
menggunakan komparasi secara kuantitatif dari banyak karakter
|
|
49
2.11.6 Tipe – Tipe Cluster
Ada
dua
sifat
algoritma
pengklusteran data,
yaitu
hirarkis
dan
partisional.
Algoritma hirarkis menemukan kluster baru dengan menggunakan kluster – kluster yang
telah terbentuk sebelumnya. Sedangkan algoritma partisional menentukan semua kluster
dalam satu kali proses. Algoritma hirarkis dapat bersifat agglomerative (”dari bawah ke
atas”) atau dapat juga bersifat divisive (”dari atas ke bawah”). Algoritma agglomerative
dimulai dengan masing – masing unsur sebagai kluster terpisah, lalu menggabungkannya
ke dalam kluster
yang
lebih besar. Algoritma divisive dimulai dengan keseluruhan set
data, lalu mulai membaginya ke dalam kluster baru yang lebih kecil.
Co-clustering,
bi-clustering
atau clustering dua arah
adalah
sebutan –
sebutan
untuk
teknik
–
teknik
pengklusteran
yang
tidak
hanya
objek
–
objek
yang
dikluster,
tetapi juga fitur – fitur dari objek tersebut. Contohnya, jika data berbentuk matriks, maka
kolom dan baris akan di kluster secara serempak.
Perbedaan lainnya
yang
cukup
signifikan
adalah
teknik
klustering yang
menggunakan jarak yang simetris ataukah asimetris.
2.11.6.1 Pengklusteran Secara Hirarki
Algoritma ini
menemukan kluster baru dengan menggunakan kluster – kluster
yang telah terbentuk sebelumnya. Algoritma hirarkis dapat bersifat agglomerative (”dari
bawah
ke
atas”)
atau
dapat
juga bersifat
divisive
(”dari
atas ke
bawah”). Algoritma
agglomerative
dimulai
dengan masing –
masing unsur
sebagai
kluster
terpisah,
lalu
menggabungkannya ke
dalam
kluster
yang
lebih
besar.
Algoritma
divisive
dimulai
dengan keseluruhan set data, lalu
mulai membaginya ke dalam kluster baru yang lebih
kecil.
|
|
50
2.11.6.1.1 Menghitung Jarak
Hal penting dalam sebuah pengklusteran secara hirarki adalah memilih suatu
ukuran
jarak.
Ukuran
yang
umum
digunakan adalah
jarak
Euclidean, dihitung dengan
menemukan penyiku dari jarak antara masing – masing variabel. Penjumlahan penyiku,
dan menemukan akar pangkat dua dari penjumlahan tersebut. Dalam kasus two variabel,
jarak adalah pengertian dalam menemukan panjang hipotenusa suatu segitiga, itu adalah
jarak lurus.
2.11.6.1.2 Menciptakan Cluster
Dengan suatu
ukuran
jarak,
unsur
–
unsur
dapat
dikombinasikan.
Pengklusteran secara
hirarkis
membangun(agglomerative), atau
pemisahan
(divisive),
suatu hirarki dari kluster. Penyajian tradisional dari hirarki ini adalah suatu struktur data
pohon
atau disebut
juga
dendogram. Dengan
memiliki
unsur
–
unsur
individudi
salah
satu ujungnya dan sebuah kluster tunggal pada ujung lainnya. Algoritma agglomerative
dimulai dari puncak pohon data, sedangkan algoritma divisive dimulai dari dasar pohon
data.
2.11.6.1.3 V-Means Clustering
V-means
Clustering
menggunakan analisis cluster dan
statistik
nonparametric
sebagai
sebagai
kunci
para
peneliti
ke
dalam segmen
data
yang
boleh
berisi
subset
homogen
yang
berbeda.
Metodologi
yang
digunakan oleh
V-means
Clustering banyak
berbelit
dari
permasalahan yang
secara
tradisional
mengepung
teknik
standar
dalam
pengelompokan data. Pertama, sebagai pengganti ramalan analisis untuk beberapa subset
berbeda
(K-Means
Clustering), V-Means
Clustering
menghasilkan jumlah
subset
yang
optimal. V-Means Clustering menghasilkan jumlah subset yang optimal. V-Means
|
|
51
Clustering dikalibrasi untuk tingkatan user – defined level p, dimana algoritma membagi
data
dan kemudian menggabukan kembali kelompok
hasil
hingga kemungkinan bahwa
semua kelompok berasal dari distribusi
yang
sama
ketika tetangga –
tetangganya yang
lain kurang dari p.
Kedua,
V
–
Means
Clustering
menggunakan iterasi
dari
tes
nonparametric
Kolmogorov-Smirnov.
Metode
standar
dalam
memisahkan data
ke
dalam
bagian
utamanya
sering
melibatkan
definisi
jarak
(ukuran
jarak
pengklusteran) atau
dalam
asumsi
tentang
kewajaran
data
(maksimasi ekspektasi
pengklusteran), tetapi
analisa
nonparametric menarik kesimpulan dari fungsi distribusi set – set data.
Ketiga,
metode
yang
secara
konseptual
sederhana. Beberapa
metode
mengkombinasikan berbagai
teknik dalam
urutan
untuk
menghasilkan hasil
yang
lebih
sempurna. Dari suatu sudut pandang praktis, metode
ini
menggabungkan arti dari
hasil
dan sering mengarahkan pada kesimpulan yang khas dari data dredging.
2.11.6.2 Pengklusteran Partisional
Seperti
yang
telah
dijelaskan sebelumnya,
algoritma
pertitional menemukan
semua kluster
dalam
satu
kali
proses.
C-Means
Clustering
termasuk
dalam
pengklusteran partisional tetapi akan dijelaskan pada bagian berikutnya.
2.11.6.2.1 K – Means Clustering
Algoritma K
–
Means
memetakan
masing –
masing
titik
pada
cluster
yang
memiliki pusat terdekat. Pusat adalah rata – rata dari semua poin – poin dalam cluster,
yang
berarti koordinatnya adalah rata – rata aritmatik dari tiap dimensi secara
terpisah
dari seluruh poin – poin dalam kluster.
|
|
52
2.11.6.2.2 Algoritma QT Clustering
QT
(Quality Threshold) Clustering(Heyer et
al,1999)
adalah
suatu
metode
alternatif dalam pemisahan data, diciptakan untuk pengklusteran
gen. Hal ini
memerlukan
penetapan
yang
banyaknya
kluster
awal,
dan
selalu
menghasilkan
hasil
yang sama ketika dijalankan berkali – kali.
2.11.7 Definisi Fuzzy clustering
Fuzzy clustering adalah
salah
satu
teknik
untuk
menentukan
cluster optimal
dalam suaptu ruang vector yang di dasarkan pada bentuk normal Euclidian
untuk jarak
antar
vektor. Fuzzy clustering sangat berguna bagi pemodelan
fuzzy
terutama dalam
mengidentifikasi atura-aturan fuzzy (Kusumadewi dan Purnomo,2004).
Ada beberapa
algoritma
Clustering data,
diantaranya
adalah
Fuzzy
C-means.
FCM atau Fuzzy C-Means, dan
Subtractive Clusterin.
FCM
adalah suatu teknik peng-cluster-an data yang mana keberadaan tiap-tiap
titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Teknik ini pertama
kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
Fuzzy C – Means ( FCM ) adalah algoritma pengclusteran yang terawasi, sebab
pada FCM kita perlu tahu terlebih dahulu jumlah cluster yang akan dibentuk. Apabila
jumlah cluster yang akan dibentuk belum diketahui sebelumnya, maka kita harus
menggunakan algoritma yang tidak terawasi. Subtractive clustering didasarkan atas
ukuran densitas ( potensi ) titik – titik data dalam suatu ruang ( variabel ). Konsep dasar
dari subtractive clustering adalah menentukan daerah – daerah dalam suatu variabel
|
|
53
yang memiliki densitas tinggi terhadap titik – titik di sekitarnya. Titik dengan jumlah
tetangga terbanyak akan dipilih sebagai pusat cluster. Titik yang sudah terpilih sebagai
pusat cluster ini kemudian akan dikurangi densitasnya. Kemudian algoritma akan
memilih titik lain yang memiliki tetangga terbanyak untuk dijadikan pusat cluster yang
lain. Hal ini akan dilakukan berulang – ulang hingga semua titik diuji.
2.11.8 Konsep Dasar FCM
Konsep
dasar
FCM, pertama
kali
adalah
menentukan
pusat
cluster,
yang
akan
menandai
lokasi
rata-rata
untuk
tiap-tiap
cluster.
Pada
kondisi
awal,
pusat
cluster
ini
masih
belum akurat.
Tiap-tiap
titik data
memiliki derajat keanggotaan
untuk
tiap-tiap
cluster.
Dengan cara
memperbaiki pusat
cluster
dan
derajat keanggotaan tiap-tiap titik
data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju
lokasi
yang
tepat.
Perulangan ini
didasarkan pada
minimasi
fungsi
obyektif
yang
menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh
derajat keanggotaan titik data tersebut.
Output dari FCM bukan merupakan fuzzy inference system, namun merupakan
deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data.
2.11.9 Algoritma FCM
Algoritma FCM
menurut Sri
Kusuma
Dewi
dan
Hari Purnomo (2004,p84-85)
diberikan sebagai berikut :
1. Input data yang akan di-cluster X, berupa matriks yang berukuran n x m
(n = jumlah
sample data , m = atribut setiap data). X
ij
=
data sample ke -i (i = 1,2, ... , n), atribut
ke -j (j = 1,2, ... , m).
|
 54
n
n
?
Q
w
2. Tentukan jumlah cluster (c), pangkat (w), maksimum iterasi (MaxIter), error terkecil
yang diharapkan (?), fungsi objektif awal (P
0
=
0), dan iterasi awal (t = 1).
3. Bangkitkan bilangan random µ
ik
,
i
=
1,2, … , n; k = 1,2, … , c; sebagai elemen –
elemen matriks partisi awal U. Hitung jumlah setiap kolom (atribut) :
c
Q
j
=
?
µ
ik
k
=1
dengan j= 1,2,…,m.
Hitung:
µ
=
µ
ik
ik
j
4. Hitung pusat cluster ke-k : V
kj
,
dengan k = 1,2, ... ,c; dan j = 1,2, ... , m.
?
(
(µ
ik
)
*
X
ij
)
V
kj
=
i
=1
`
?
(
µ
ik
)
i
=1
5. Hitung fungsi obyektif pada iterasi ke – t, P
t
n
c
?
m
2
?
?
w
?
P
t
=
??
?
?
?
X
ij
-
V
kj
?
(
µ
ik
)
?
i
=
1
k
=1
?
?
j
=1
?
?
6. Hitung perubahan matriks partisi
|
 55
-1
?
m
2
?
w-1
µ
ik
?
?
(
X
ij
=
?
j
=
1
-
V
kj
)
?
?
-
1
c
?
m
2
?
w
-
1
?
?
?
(X
ij
k
=
1
?
j
=
1
-
V
kj
)
?
?
Dengan : i = 1,2,...,n; dan k = 1,2,...,c
7. Cek kondisi berhenti :
•
Jika (| P
t
–
P
t-1
|
< ?) atau (t > MaxIter), maka berhenti;
•
Jika tidak, t= t+1, ulangi langkah ke – 4.
|