|
7
BAB 2
LANDASAN TEORI
2.1 Pengertian Data Warehouse
Menurut Inmon (2002, p389), “A data warehouse is a collection of
integrated, subject oriented database designed to support the DSS function, where
each unit of data is relevant
to some moment in time”, atau kurang lebih dapat
diartikan bahwa data warehouse adalah kumpulan basis data yang mempunyai sifat
berorientasi subyek, terintegrasi, mempunyai rentang waktu, yang dirancang untuk
mendukung
fungsi
sistem pendukung
pengambilan
keputusan
dimana
tiap
data
berhubungan dengan suatu kejadian pada suatu waktu.
Berdasarkan
sumber
informasi
yang
lain, data
warehouse
adalah
kumpulan dari
data
yang tertransformasi dan terintegrasi, disimpan dengan tujuan
untuk
menyediakan
informasi
yang bersifat strategis
untuk keseluruhan perusahaan
(Ponniah, 2001, p504). Menurut Ponniah (2001,p13), data warehouse adalah suatu
lingkungan informasi yang:
•
Menyediakan
sudut
pandang
yang
terintegrasi
dan
bersifat
meyeluruh
dari
suatu perusahaan.
•
Membuat
informasi baru
maupun
historis tersedia secara
mudah
untuk
pengambilan keputusan.
•
Memungkinkan proses pengambilan keputusan tanpa mengganggu sistem
operasional.
•
Memberikan informasi tentang organisasi secara konsisten.
|
|
8
•
Memberikan sumber informasi strategis secara fleksibel dan interaktif.
2.2 Karakteristik Data Warehouse
Data
warehouse
adalah
suatu
kumpulan
data
yang
bersifat subject-
oriented,
integrated,
time-variant,
dan
non-volatile
dalam mendukung
proses
pengambilan keputusan (Connolly dan Begg, 2002, p1047; Inmon, 2002, p31).
2.2.1 Subject Oriented
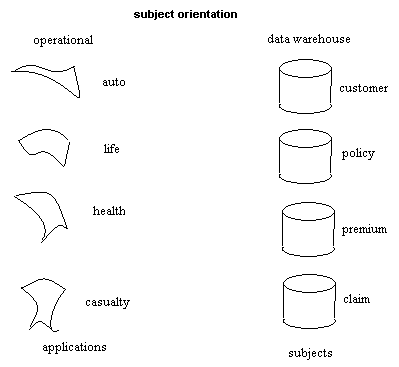
Data disusun berdasarkan subyek-subyek area utama perusahaan,
tidak seperti OLTP (OnLine Transaction Processing) yang diatur berdasarkan
aplikasi-aplikasi
operasional
perusahaan.
Contohnya
dalam perusahaan
asuransi
data warehouse
akan berorientasi pada subyek utama perusahaan
antara
lain customer,
kebijakan,
premi,
dan
klaim sedangkan
OLTP
lebih
berorientasi pada aplikasi-aplikasi operasional perusahaannya antara lain
asuransi mobil, asuransi kesehatan, asuransi jiwa, asuransi kecelakaan.
|
 9
Gambar 2.1 Contoh data berorientasi subyek (Inmon ,2002, p32)
2.2.2 Integrated
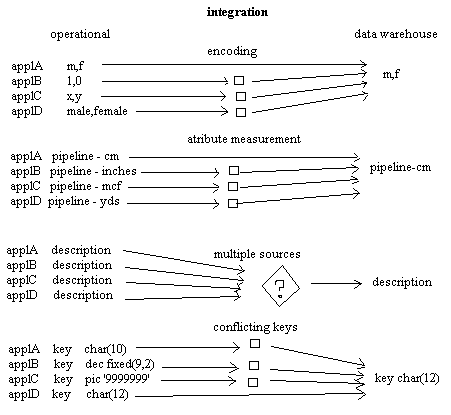
Karakteristik data warehouse selanjutnya adalah terintegrasi.
Terintegrasi
merupakan
aspek
yang
paling
penting
dalam data
warehouse.
Terintegrasi
berarti
data
konsisten.
Integrasi merupakan suatu masalah bagi
organisasi, khususnya jika menggunakan banyak
tipe
teknologi
yang berbeda.
Sebelum data dimasukkan ke dalam data warehouse, data harus diintegrasikan.
Maka proses integrasi adalah suatu proses yang dilalui data setelah
meninggalkan database aplikasi untuk masuk ke data warehouse.
Berikut adalah hal-hal yang perlu standarisasi (Ponniah, 2001, p22):
•
Penamaan (naming conventions)
•
Kode (codes)
|
 10
•
Atribut data (data attributes)
•
Pengukuran
(measurements)
Gambar 2.2 Contoh integrasi data (Inmon ,2002, p33)
2.2.3 Non-Volatile
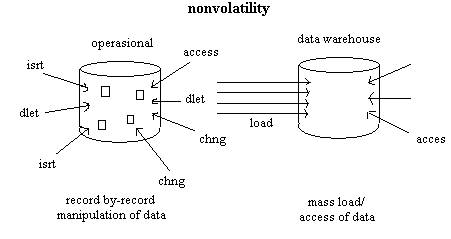
Data warehouse bersifat read-only, pengguna tidak dapat
mengubah data. Tidak seperti sistem database operasional yang bersifat untuk
mengumpulkan data (data
capture),
data
warehouse
berfungsi
untuk
mendukung system
reporting.
Pada
sistem
database
operasional
terdapat
tiga
operasi, yaitu insert, update, dan delete. Sedangkan pada data warehouse
|
 11
terdapat dua operasi, yaitu loading data dan akses data (query data). Artinya
user hanya boleh melakukan proses read, bukan write. Tujuannya adalah untuk
menjaga keaslian dan integrasi data di dalam sistem, dan juga sifat
ini
membedakan data warehouse dengan OLTP.
Gambar 2.3 Persoalan dalam non volatile (Inmon,2002, p34)
2.2.4 Time-Variant
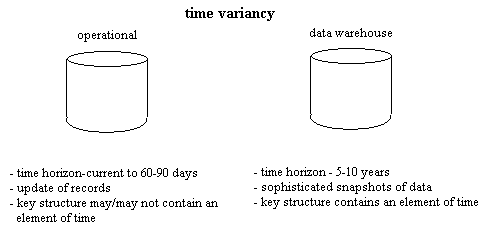
Time-variant
berarti data
historis disimpan.
Hampir
seluruh query
yang
dieksekusi
pada data
warehouse
berhubungan
dengan
elemen
waktu.
Umumnya sistem operasional tidak menyimpan informasi historis, dan hampir
tidak
mungkin meramalkan kejadian di masa depan tanpa
meneliti kejadian di
masa
lalu. Maka data warehouse membantu
mengatasi
masalah tersebut
dengan menambahkan dimensi historis pada data yang diambil dari database
operasional.
Data
warehouse
berisikan
record-record yang
bersifat
historis.
Record dalam data warehouse berjangka 5-10 tahun, sehingga record-record
|
 12
yang lama tetap akan ada di dalam
sistem. Hal
ini digunakan sebagai bahan
analisis
untuk pengambilan
keputusan dalam
menentukan trend bisnis
yang
ada di masa lalu. Namun record yang terlalu lama juga tidak baik disimpan,
sebab dapat memberikan hasil analisis yang kurang tepat. Dalam OLTP,
record-nya
merupakan
record
yang
terbaru.
OLTP
tidak
menyimpan
data
yang lama, dengan maksud untuk mempercepat proses. Semakin sedikit data
yang disimpan maka waktu yang diperlukan untuk pemrosesan data semakin
kecil.
Data dalam data warehouse berhubungan dengan
suatu
titik atau
point dalam suatu periode tertentu (semester, kuartal, tahun fiskal). Data
tersebut merupakan data hasil summary. Hal ini membantu dalam menentukan
performa query data warehouse serta dalam membentuk pengertian bisnis.
Gambar 2.4 Persoalan dalam variasi waktu (Inmon,2002, p35)
2.3 Struktur Data Warehouse
Menurut
Inmon (2005, p35), data
mengalir dari lingkungan operasional
ke dalam data warehouse dimana data mengalami transformasi dari tingkatan
|
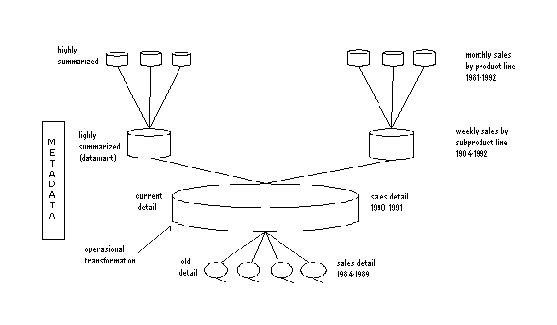 13
operasional ke
tingkatan data
warehouse. Pada
perumusan
data,
data
disampaikan
dari current detail data ke older detail. Setelah data diringkas, data tersebut
disampaikan dari
current
detail ke lightly summarized
data,
kemudian
dari
lightly
summarized data ke highly summarized data.
Gambar 2.5 Struktur data warehouse (Inmon,2002, p36)
2.3.1 Current Detailed Data
Current detailed data berisi data yang mencerminkan keadaan yang
sedang berjalan saat ini dan merupakan level terendah dari data warehouse.
Oleh karena
itu, data di tingkat ini belum efisien
untuk digunakan
sekalipun
datanya lengkap/detail.
Hal
ini
dikarenakan
terlalu
rumit/kompleks
untuk
melakukan analisis dengan data yang banyak.
|
|
14
2.3.2 Old Detailed Data
Old
detailed
data merupakan merupakan data history
dari suatu
perusahaan yang berupa hasil backup yang
disimpan
dalam
media
penyimpanan
yang frekuensi akses
relatif
jarang.
Data
pada
tingkat
ini
biasanya berupa backup data-data dari kurun waktu
lama
misalnya
dalam
ukuran tahunan dan sudah hampir tidak pernah diakses lagi. Namun
penyusunan directory
untuk data
ini
harus
mencerminkan
umur dari data agar
mempermudah untuk pengaksesan kembali.
2.3.3 Lightly Summarized Data
Lightly
summarized data
merupakan data
ringkasan
atau
summary
dari current detailed data. Pada tingkat
ini, data hasil
ringkasan
masih belum
dapat digunakan
dalam proses pengambilan keputusan karena belum bersifat
"total summary" dan masih bersifat detail. Lightly summarized data biasanya
sering digunakan
untuk gambaran dari keadaan yang sedang berlangsung dan
sudah berlangsung.
2.3.4 Highly Summarized Data
Highly
summarized
data merupakan
merupakan
hasil
proses
summary yang bersifat "totalitas". Data-data pada highly summarized ini sangat
mudah diakses. Data pada tingkat inilah yang pada akhirnya digunakan untuk
mendukung pengambilan keputusan terutama di kalangan eksekutif dalam
|
|
15
dunia bisnis. Hal ini disebabkan karena data pada tingkat ini dianggap sudah
cukup
representatif
dan
ringkas.
Akan tetapi
data
ini
tetap
dapat
merepresentasikan keadaan data secara keseluruhan.
Hal
ini
tentu
saja sangat
memudahkan kalangan pimpinan atau eksekutif karena tidak perlu lagi
membaca dan melakukan analisis data untuk waktu yang cukup lama.
2.4 Metadata
Metadata bukan merupakan hasil kegiatan operasional seperti keempat
jenis data
di atas.
Metadata
memuat
informasi
yang penting
mengenai
data
dalam
data warehouse yang berfungsi sebagai:
•
Direktori
yang akan dipakai oleh user dalam
mencari
lokasi dalam data
warehouse.
•
Merupakan penuntun pemetaan
(mapping) dalam
proses
transformasi
dari
operasional ke data warehouse.
•
Suatu panduan untuk proses summary data dari detail data menjadi lightly
summarized data dan kemudian menjadi highly summarized data.
Metadata
merupakan
bentuk
suatu
jaringan yang sangat penting bagi
pengguna data warehouse. Data yang tersedia harus dapat digunakan oleh user
dengan istilah yang sesuai dengan cara user dalam melakukan pekerjaannya. Karena
data
warehouse harus melayani banyak fungsi,
maka metadata penting untuk
menjawab kebutuhan dari suatu fungsi
tertentu. Karena setiap departemen biasanya
menggambarkan struktur data yang spesifik meskipun asal datanya sama.
|
 16
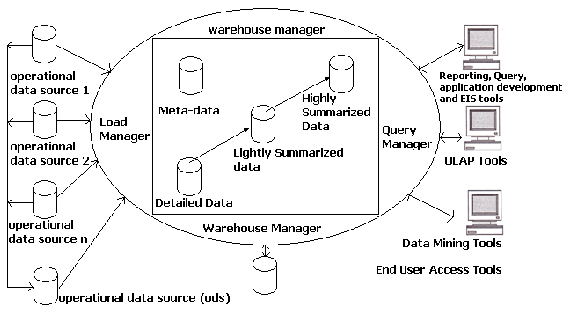
2.5 Arsitektur Data Warehouse
Dalam
melakukan
perancangan
data
warehouse
harus
ditentukan
arsitektur yang cocok untuk pengembangan data warehouse.
Gambar 2.6 Arsitektur Data Warehouse (Connolly dan Begg ,2002, p1053)
Komponen-komponen
utama
data
warehouse
(Connolly
dan
Begg,2002,pp1052-1057):
1. Operational Data Source (ODS)
ODS
merupakan
tempat
penyimpanan data
operasional
terkini
dan
terintegrasi
yang
digunakan
untuk analisis. Seringkali
mempunyai struktur dan
data seperti data warehouse, namun pada faktanya hanya bertindak sebagai
staging area bagi data untuk dipindahkan ke dalam warehouse.
2. Load manager/komponen frontend
|
|
17
Load manager bertugas melaksanakan semua operasi yang berhubungan
dengan extraction dan loading data ke dalam warehouse, termasuk transformasi
data sederhana sebagai persiapan data untuk dimasukkan ke dalam warehouse.
3. Warehouse manager
Warehouse manager
melaksanakan
semua
operasi
yang
berhubungan
dengan
manajemen
data
dalam warehouse.
Operasi
yang
dilaksanakan
oleh
komponen ini antara lain analisis data untuk memastikan konsistensi,
transformasi
dan
menggabungkan
berbagai sumber data, pembuatan index
dan
view, denormalisasi, archiving dan backup data.
4. Query manager/komponen backend
Query manager melaksanakan semua operasi yang berhubungan dengan
manajemen
query pengguna,
termasuk
mengarahkan query ke
tabel-tabel
yang
tepat, menjadwalkan eksekusi query.
5. End-user access tools
Dapat dikategorikan menjadi 5 kelompok:
•
Data reporting dan query tool
•
Application development tool
•
Executive Information System (EIS) tool
•
Online analytical processing (OLAP) tool
•
Data mining tool
|
|
18
2.6 Anatomi Data Warehouse
2.6.1 Data Warehouse Terpusat
Berdasarkan W.H. Inmon (2002, p201), sebagian besar organisasi
membangun
dan
memelihara
lingkungan data
warehouse
terpusat
tunggal.
Pengaturan ini dilakukan karena memiliki beberapa alasan yaitu:
1. Data dalam warehouse terintegrasi antar perusahaan dan gambaran
terintegrasi digunakan hanya pada kantor pusat.
2. Perusahaan mengoperasikan sebuah model bisnis terpusat.
3. Volume data
dalam data
warehouse
seperti sebuah
penyimpanan
tunggal yang terpusat.
4. Sekalipun data dapat diintegrasikan, jika data diedarkan melalui banyak
local sites, maka akan mempersulit pengaksesan.
2.6.2 Data Warehouse Terdistribusi
Menurut Inmon (2002, p202), tiga tipe dari data warehouse terdistribusi:
1.
Bisnis terdistribusi secara geografis
atau
dibedakan
menurut
garis
produk.
Oleh
karena
hal
tersebut, maka
disebutlah
data
warehouse
lokal
dan
data
warehouse
global.
Data
warehouse
lokal
mewakili
data dan proses di lokasi yang terpencil dan data warehouse
global
mewakili bagian dari bisnis yang diintegrasikan melalui keseluruhan
bisnis.
2. Lingkungan data warehouse akan memegang banyak data dan volume
data
akan didistribusikan
melalui
beberapa
prosesor.
Secara
logikal
|
|
19
hanya ada
satu data warehouse, tetapi secara fisikal terdapat banyak
data warehouse yang semuanya mempunyai hubungan yang dekat
tetapi diletakkan
pada
prosesor
yang terpisah. Konfigurasi ini dapat
disebut dengan teknologi data warehouse terdistribusi.
3.
Lingkungan
data
warehouse tumbuh
dalam sebuah
kebiasaan
yang
tidak terorganisasi. Data warehouse yang pertama muncul, kemudian
diikuti
yang
lainnya.
Kurangnya koordinasi
dari
pertumbuhan
data
warehouse
yang berbeda biasanya menghasilkan sebuah perbedaan
secara
politik
dan
organisasi.
Kasus
ini
dapat
disebut
dengan data
warehouse terdistribusi yang secara bebas berkembang.
2.7 Metodologi Perancangan Data Warehouse
Berdasarkan Kimball seperti yang dikutip oleh Connolly dan Begg (2002,
p1083), terdapat 9 tahap metodologi dalam membangun data warehouse yang
dikenal dengan nine-step methodology yakni:
1. Memilih proses (Choosing the process)
Proses (fungsi) merujuk pada subyek masalah dari data mart
tertentu.
Data
mart
yang
akan
dibangun
harus
sesuai anggaran
dan
dapat
menjawab
masalah-masalah bisnis yang penting.
2. Memilih grain (Choosing the grain)
Memilih grain berarti menentukan hal yang sebenarnya dihadirkan oleh
tabel
fakta. Setelah menentukan grain-grain tabel
fakta, dimensi-dimensi untuk
setiap fakta dapat diidentifikasi.
|
|
20
3. Identifikasi dan
membuat dimensi yang sesuai (Identifying and conforming the
dimensions)
Mengidentifikasi
dimensi
disertai
deskripsi detail
yang secukupnya.
Ketika tabel dimensi berada pada dua atau
lebih data mart, maka tabel dimensi
tersebut harus mempunyai dimensi yang sama atau salah satu merupakan subset
dari
yang
lainya.
Jika suatu tabel
dimensi
digunakan oleh
lebih
dari
satu data
mart, maka dimensinya harus disesuaikan.
4. Memilih fakta (Choosing the facts)
Memilih fakta yang akan digunakan dalam data mart. Semua fakta harus
ditampilkan pada level yang diterapkan oleh grain dan fakta juga harus numerik
dan aditif.
5. Menyimpan pre-kalkulasi dalam tabel fakta (Storing pre-calculations in the fact
table)
Ketika
fakta
telah dipilih,
maka setiap fakta tersebut harus diuji apakah
ada fakta yang dapat menggunakan pre-kalkulasi, setelah itu lakukan
penyimpanan pada tabel fakta.
6. Melengkapi tabel dimensi (Rounding out the dimension tables)
Menambahkan sebanyak mungkin deskripsi teks pada tabel dimensi.
Deskripsi tersebut harus intuitif dan dapat dimengerti oleh user.
7. Memilih durasi dari database (Choosing the duration of the database)
Menentukan
batas
waktu
dari
umur
data
yang
diambil
dan
akan
dipindahkan ke dalam tabel fakta. Misalnya, data perusahaan dua tahun lalu atau
lebih diambil dan dimasukkan dalam tabel fakta.
|
|
21
8. Melacak perubahan dari dimensi secara perlahan (Tracking slowly changing
dimensions)
Perubahan
dimensi
yang
lambat
menjadi
sebuah
masalah.
Ada
3
tipe
dasar dari perubahan dimensi yang lambat, yakni:
Perubahan atribut dimensi yang ditulis ulang (overwrite).
Perubahan atribut dimensi
yang mengakibatkan pembuatan suatu record
dimensi baru.
Perubahan atribut
dimensi
yang
mengakibatkan
sebuah atribut
alternatif
dibuat, sehingga kedua atribut tersebut yakni atribut yang lama dan yang
baru dapat diakses secara bersamaan dalam sebuah dimensi yang sama.
9. Memutuskan
prioritas
dan
cara
query
(Deciding
the
query
priorities
and
the
query modes)
Mempertimbangkan
pengaruh
dari perancangan fisikal yang akan
mempengaruhi persepsi user terhadap data mart. Selain itu, perancangan fisikal
akan
mempengaruhi
masalah
administrasi, backup,
kinerja
indexing
dan
keamanan.
2.8 Konsep Pemodelan Data warehouse
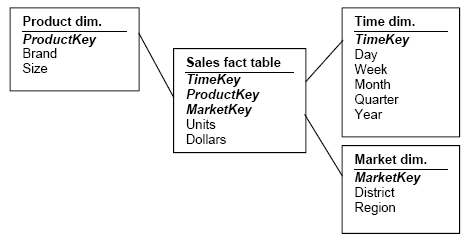
2.8.1 Skema Bintang (Star Schema)
Menurut Ponniah (2001, pp210-216), skema bintang (star schema)
adalah teknik dasar desain data untuk data warehouse. Struktur skema bintang
adalah suatu struktur yang dapat dengan mudah dipahami dan digunakan oleh
pengguna. Struktur tersebut mencerminkan bagaimana pengguna biasanya
memandang ukuran-ukuran kritis mengikuti dimensi-dimensi bisnis yang ada.
|
 22
Karakteristik dari komponen skema bintang:
1.
Tabel dimensi
•
Key tabel dimensi
Key tabel dimensi
merupakan primary key dari tabel dimensi
yang mengidentifikasi setiap baris dalam tabel secara unik.
•
Merupakan tabel yang lebar
Tabel
dimensi
memiliki
jumlah
kolom atau
atribut
yang
banyak, oleh karena itu tabel dimensi bersifat lebar.
•
Atribut berupa teks
Dalam tabel
dimensi, jarang
ditemukan
nilai
numerik
untuk
perhitungan, atribut umumnya berupa teks yang merepresentasikan
deskripsi tekstual dari komponen-komponen dalam dimensi bisnis.
•
Atribut-atribut tidak berhubungan secara langsung
|
|
23
Sebagai contoh, besar paket dan merek produk tidak saling
berhubungan, namun sama-sama dapat menjadi atribut tabel dimensi
produk.
•
Tidak dinormalisasi
Untuk
kinerja
query
yang
efisien,
paling
baik
jika query
mengambil dari tabel dimensi dan langsung ke tabel fakta tanpa melalui
tabel perantara yang akan terbentuk jika tabel dimensi dinormalisasi.
•
Kemampuan drill-down dan roll-up
Atribut-atribut
dalam tabel
dimensi
menyediakan
kemampuan
untuk mendapatkan detail dari level tinggi agregasi sampai
level detail
yang rendah. Sebagai contoh, jumlah penjualan dapat dilihat
berdasarkan propinsi, lalu dapat drill-down ke kota dan kode pos. Atau
total penjualan berdasarkan kode pos dapat roll-up ke kota dan propinsi.
•
Terdapat beberapa hirarki
Berbagai
bagian
perusahaan dapat
mengelompokkan
dimensi
dengan cara yang berbeda, sehingga terbentuk lebih dari 1 hirarki.
•
Jumlah record yang lebih sedikit
Tabel dimensi umumnya memiliki jumlah record atau baris
yang lebih sedikit dari tabel fakta.
2. Tabel fakta
Concatenated key
Baris
dalam
tabel
fakta
diidentifikasi
dengan
menggunakan primary key dari tabel-tabel dimensi,
maka primary key
|
|
24
dari tabel
fakta
merupakan
gabungan
primary key dari semua
tabel
dimensi.
Data grain
Data grain merupakan tingkat detail untuk pengukuran.
Sebagai contoh, jumlah pemesanan berhubungan dengan jumlah produk
tertentu pada suatu pesanan, tanggal tertentu,
untuk pelanggan spesifik
dan diperoleh oleh seorang perwakilan sales spesifik tertentu. Jika
jumlah pesanan dilihat sebagai jumlah untuk suatu produk perbulan,
maka data grain-nya berbeda dan pada tingkat yang lebih tinggi.
Fully additive measures
Agregasi dari fully additive measures dilaksanakan dengan
penjumlahan sederhana nilai-nilai atribut tersebut.
Semiadditive measures
Semiadditive measures merupakan nilai yang tidak dapat
langsung dijumlahkan, sebagai contoh persentase keuntungan.
Tabel besar, tidak lebar
Tabel
fakta umumnya
memiliki
lebih
sedikit
atribut
daripada
tabel
dimensi,
namun
memiliki
jumlah record
yang
lebih
banyak.
Sparse data
Tabel
fakta tidak perlu menyimpan record
yang nilainya
null. Maka tabel fakta dapat memiliki gap.
Degenerate dimensions
|
|
25
Terdapat
elemen-elemen data
dari
sistem operasional
yang
bukan merupakan fakta ataupun dimensi, seperti nomor pesanan, nomor
tagihan,
dan
lain-lain. Namun
atribut-atribut
tersebut
dapat
berguna
dalam jenis analisis tertentu. Sebagai contoh,
mencari rata-rata
jumlah
produk
per
pesanan,
maka produk
harus
dihubungkan ke
nomor
pesanan
untuk
mendapatkan
nilai
rata-rata. Atribut-atribut
tersebut
disebut degenerate dimension dan disimpan sebagai atribut dari tabel
fakta.
Keuntungan skema bintang:
1.
Mudah dipahami pengguna.
2.
Mengoptimalkan navigasi.
3.
Paling cocok untuk pemrosesan query.
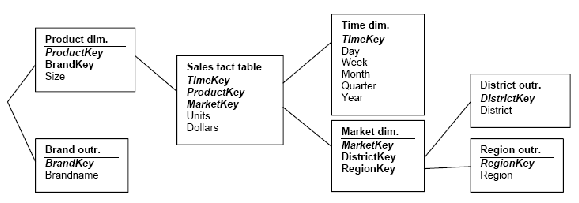
2.8.2 Skema Snowflake
Snowflake merupakan variasi lain dari skema bintang dimana
tabel
dimensi
dari
skema
bintang
diorganisasikan menjadi suatu hirarki
dengan melakukan normalisasi. Prinsip dasar dari skema ini tidak jauh
berbeda dari skema bintang. Penggunaan tabel dimensi sangatlah mendasar,
karena itulah perbedaan mendasar
dari skema bintang dan skema
snowflake. Skema snowflake menggunakan beberapa tabel fakta dan tabel
dimensi yang sudah mengalami
normalisasi, sedangkan
skema bintang
menggunakan
tabel dimensi yang
masih denormalisasi. Skema snowflake
|
 26
dibuat berdasarkan OLTP sehingga semua data akan termuat detail dalam
setiap tabel fakta dan tabel dimensi.
Keuntungan dari skema snowflake:
•
Kecepatan memindahkan data dari data OLTP ke dalam Metadata.
•
Sebagai kebutuhan dari alat pengambil keputusan tingkat
tinggi dimana
dengan tipe yang seperti ini seluruh struktur dapat digunakan sepenuhnya.
•
Banyak
yang
beranggapan
lebih
nyaman
merancang
dalam
bentuk
normal ketiga.
Sedangkan kerugiannya adalah mempunyai masalah yang besar
dalam hal kinerja, hal ini disebabkan karena semakin banyaknya join antar
tabel–tabel yang digunakan dalam snowflake, maka kinerja juga semakin
lambat.
|
 27
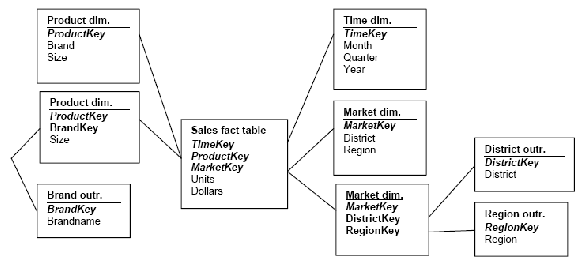
2.8.3 Skema Starflake
Menurut Connolly dan Begg(2002, p1081), skema
starflake
merupakan
struktur hybrid yang berisi kombinasi antara skema bintang yang
telah didenormalisasi dan snowflake yang telah dinormalisasi.
Beberapa dimensi dapat menggunakan bentuk tertentu untuk
memenuhi berbagai kebutuhan query.
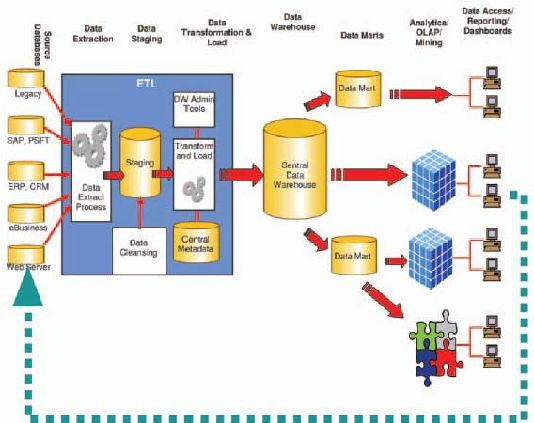
2.9 ETL (Extract, Transform, Load)
ETL
(Extract,
Transform,
and
Load)
adalah
proses-proses
dalam data
warehouse yang meliputi:
•
Mengekstrak data dari sumber-sumber eksternal.
•
Mentransformasikan data ke bentuk yang sesuai dengan keperluan bisnis.
•
Memasukkan data ke target akhir, yaitu data warehouse.
ETL merupakan proses yang sangat penting, dengan ETL data dapat
dimasukkan ke dalam data
warehouse. ETL juga dapat digunakan untuk
mengintegrasikan data dengan sistem yang sudah ada sebelumnya.
|
|
28
Tujuan
ETL
adalah
mengumpulkan, menyaring, mengolah, dan
menggabungkan
data-data
yang
relevan
dari berbagai sumber untuk disimpan ke
dalam data
warehouse.
Hasil
dari
proses
ETL
adalah
dihasilkannya
data
yang
memenuhi
kriteria data warehouse seperti
data
yang
historis,
terpadu,
terangkum,
statis, dan memiliki struktur yang dirancang untuk keperluan proses analisis.
2.9.1 Extract
Langkah pertama pada proses ETL adalah
mengekstrak data dari
sumber-sumber data. Kebanyakan proyek data warehouse menggabungkan
data
dari
sumber-sumber
yang
berbeda.
Sistem-sistem yang
terpisah
sangat
mungkin menggunakan format data yang berbeda. Ektraksi adalah mengubah
data ke dalam suatu format yang berguna untuk proses transformasi.
Pada hakekatnya proses ekstraksi adalah proses penguraian dari
data yang diekstrak untuk mendapatkan struktur atau pola data yang
diharapkan. Jika struktur atau pola data tidak sesuai dengan harapan maka data
tidak dimasukkan ke dalam data warehouse.
2.9.2 Transform
Tahapan transformasi menggunakan serangkaian aturan atau fungsi
untuk mengekstrak data dari sumber dan selanjutnya akan dimasukkan ke data
warehouse.
Berikut
adalah
hal-hal
yang
dapat
dilakukan
dalam tahapan
transformasi:
•
Hanya memilih kolom tertentu saja untuk dimasukkan ke dalam data
warehouse.
|
|
29
•
Menterjemahkan
nilai-nilai
yang berupa kode (contohnya apabila database
sumber
menyimpan
nilai
1
untuk
laki-laki dan nilai 2 untuk perempuan,
tetapi data warehouse yang telah ada menyimpan M untuk laki-laki dan F
untuk perempuan,
ini disebut dengan automated data cleansing, tidak ada
pembersihan secara manual yang ditunjukkan selama proses ETL).
•
Mengkodekan
nilai-nilai ke
dalam bentuk bebas
(Contohnya
memetakan
“Male” , “1” dan “Mr” ke dalam M).
•
Melakukan perhitungan
nilai-nilai
baru (Contohnya sale_amount =
qty
*
unit_price).
•
Menggabungkan data secara bersama-sama dari berbagai sumber.
•
Membuat ringkasan dari sekumpulan baris data (Contohnya total penjualan
untuk setiap toko atau setiap bagian).
•
Men-generate nilai surrogate key.
•
Transposing atau pivoting (Mengubah sekumpulan kolom
menjadi
sekumpulan baris atau sebaliknya).
•
Memisahkan
sebuah
kolom
menjadi
berbagai
kolom
(Contohnya
meletakkan
sebuah
comma-separated
list yang
dispesifikasikan
sebagai
sebuah string dalam satu kolom sebagai
nilai
yang
tersendiri dalam kolom
yang berbeda).
•
Menggunakan berbagai
bentuk
validasi
data
baik
yang
sederhana
maupun
kompleks.
|
|
30
2.9.3 Loading
Fase load merupakan tahapan yang berfungsi untuk memasukkan
data
ke
dalam target
akhir,
yang biasanya
ke
dalam suatu
data
warehouse.
Jangka waktu proses ini tergantung pada kebutuhan organisasi. Beberapa data
warehouse dapat setiap minggu menulis keseluruhan informasi yang ada secara
kumulatif, data diubah, sementara data warehouse yang lain (atau bagian lain
dari data
warehouse
yang sama)
dapat
menambahkan
data baru
dalam suatu
bentuk yang historikal, contohnya setiap jam. Waktu dan jangkauan untuk
mengganti atau menambah data tergantung dari perancangan data warehouse
pada waktu menganalisis keperluan informasi.
Fase load berinteraksi dengan suatu
database, constraint
didefinisikan dalam
skema
database
sebagai
suatu trigger
yang diaktifkan
pada
waktu
me-load data (Contohnya uniqueness, referential integrity,
mandatory fields), yang juga berkontribusi untuk keseluruhan performance dan
kualitas data dari proses ETL.
Masalah-masalah yang terjadi dalam ETL adalah sumber-sumber
data umumnya sangat bervariasi diantaranya:
•
Platform mesin dan operating system yang berlainan.
•
Mungkin melibatkan sistem kuno dengan teknologi basis data yang sudah
ketinggalan zaman.
•
Kualitas data yang berbeda-beda.
•
Aplikasi sumber data mungkin menggunakan nilai data (representasi)
internal yang sulit dimengerti.
|
 31
2.9 Definisi Penjualan dan Pembelian
2.9.1 Penjualan
Secara umum, pengertian penjualan dapat dikatakan sebagai ilmu
mempengaruhi pribadi yang dilakukan penjual untuk mengajak orang lain
membeli barang atau jasa yang ditawarkan. Jadi adanya penjualan dapat
tercipta suatu proses pertukaran barang atau jasa antara penjual dan pembeli.
Penjualan dapat dibagi menjadi dua jenis, yaitu:
|
|
32
1.
Penjualan Kredit
Jika order pelanggan telah dipenuhi dengan dikirimnya
barang
atau
penyerahan jasa, untuk jangka waktu tertentu perusahaan
mempunyai
piutang terhadap pelanggan.
2.
Penjualan Tunai
Kegiatan yang dilaksanakan perusahaan dengan cara mewajibkan
pembeli melakukan pembayaran barang dahulu terhadap perusahaan
sebelum barang diserahkan oleh perusahaan kepada pembeli. Setelah
uang diterima, barang kemudian diserahkan oleh perusahaan kepada
pembeli dan transaksi penjualan tersebut dicatat.
2.9.2 Pembelian
Menurut Mulyadi (2001,p299), pembelian adalah suatu usaha
pengadaan barang yang diperlukan perusahaan. Transaksi dapat digolongkan
menjadi dua, yaitu pembelian lokal dan pembelian impor. Pembelian lokal
adalah
pembelian
dari
pemasok
dalam negeri,
sedangkan
impor
adalah
pembelian dari pemasok luar negeri. Fungsi yang terkait dengan pembelian
adalah :
1. Fungsi Gudang
Bertanggung jawab untuk mengajukan permintaan pembelian sesuai
dengan posisi persediaan barang yang ada di gudang dan untuk menyimpan
barang yang telah diterima oleh fungsi penerimaan.
2. Fungsi Pembelian
Bertanggung jawab
untuk memperoleh
informasi
mengenai
harga barang.
|
|
33
Menentukan pemasok
yang
dipilih
dalam pengadaan
barang
dan
mengeluarkan order pembelian kepada pemasok yang dipilih.
3. Fungsi Penerimaan
Bertanggung
jawab
untuk
melakukan
pemeriksaan
terhadap
jenis,
mutu,
dan kuantitas barang yang diterima dari pemasok guna menentukan dapat
atau tidaknya barang tersebut diterima oleh perusahaan. Fungsi ini juga
bertanggung jawab untuk menerima barang dari pembeli yang berasal dari
transaksi retur penjualan.
4. Fungsi Akuntansi
Fungsi
yang terkait adalah fungsi pencatatan utang dan persediaan barang.
Fungsi pencatatan utang berfungsi untuk mencatat transaksi ke dalam
register bukti kas keluar. Fungsi persediaan barang bertanggung jawab
untuk
mencatat
harga
produksi
barang
yang
dibeli
ke
dalam kartu
persediaan.
|