|
BAB 2
LANDASAN TEORI
2.1 Pengertian Data
Menurut Inmon (2002, p388), data adalah rekaman dari fakta-fakta, konsep-
konsep, atau instruksi-instruksi pada media
penyimpanan
untuk
komunikasi,
pengambilan, dan pemrosesan dengan cara otomatis dan presentasi sebagai informasi
yang dapat dimengerti oleh manusia.
Menurut Turban et al (2005, p38), data adalah deskripsi dasar tentang sesuatu,
kejadian,
kegiatan,
dan
transaksi
yang ditangkap,
direkam,
disimpan,
dan
diklasifikasikan, namun tidak terorganisir untuk menyampaikan suatu arti khusus.
Menurut Hoffer, Prescott dan McFadden (2002,p5), data adalah sebuah
representasi
dari
objek-objek
dan
kejadian-kejadian
yang berarti dan penting di
lingkungan pemakai.
Berdasarkan pengertian–pengertian di
atas, dapat disimpulkan bahwa data
merupakan
rekaman
dari
fakta-fakta
tentang sesuatu, kejadian,
dan
transaksi
yang
disimpan pada media penyimpanan sebagai informasi yang dapat dimengerti oleh
manusia.
2.2 Pengertian Database
Menurut Inmon (2002, p388), database adalah sebuah koleksi data yang disimpan
yang saling berhubungan berdasarkan sebuah
skema. Sebuah database dapat
melayani
satu atau banyak aplikasi.
5
|
|
Menurut Connoly dan Begg (2002, p14), database adalah sekumpulan dari data
yang terhubung secara logis, dan deskripsi dari data
ini,
yang dirancang
untuk
memenuhi kebutuhan informasi dari sebuah organisasi
Berdasarkan pengertian–pengertian di
atas, dapat disimpulkan bahwa database
adalah sekumpulan data yang disimpan yang saling berhubungan secara logis
berdasarkan sebuah skema.
2.3 Database Management System (DBMS)
Menurut Connolly dan Begg (2002, p16), Database Management System (DBMS)
adalah sistem perangkat lunak yang memungkinkan pengguna untuk mendefinisikan,
membuat, menjaga, dan mengontrol akses ke database.
Berdasarkan pengertian di
atas, dapat disimpulkan bahwa Database Management
System (DBMS) adalah system perangkat lunak yang digunakan untuk
mendefinisikan,
membuat, menjaga, dan mengontrol akses ke database.
2.4 Pengertian OLTP (Online Transaction Processing)
Menurut Turban et al (2005, p241), OLTP adalah Transaction Processing System
(TPS)
beroperasi
pada
arsitektur client/server,
memperbolehkan
pemasok
organisasi
untuk
masuk TPS
melalui
ekstranet dan
memperhatikan tingkat persediaan perusahaan
atau jadwal produksi.
Berdasarkan
pengertian
di
atas,
dapat
disimpulkan
bahwa
OLTP adalah
sistem
yang mengatur transaction processing yang mengunakan arsitektur client/server.
6
|
|
7
2.5 Pengertian OLAP (Online Analytical Processing)
Menurut Connolly dan Begg (2002, p1101), OLAP (Online Analytical Processing)
adalah
sintesis,
analisis dan konsolidasi dinamis
dari sejumlah
besar multidimensional
data.
Berdasarkan pengertian di
atas, dapat disimpulkan bahwa OLAP adalah analisis
dari sejumlah besar multidimensional data.
2.6 Pengertian Data Warehouse
Menurut Inmon (2002, p31), data warehouse adalah koleksi data yang berorientasi
subjek
(subject
oriented),
terintegrasi
(intergrated), tidak berubah (non
volatile),
memiliki variasi waktu (time variant) yang mendukung keputusan manajemen.
Menurut
Connolly
dan Begg
(2002, p1047), data warehouse
adalah
suatu
kumpulan data yang bersifat subject-oriented, integrated, time-variant, dan non-volatile
dalam mendukung proses pengambilan keputusan.
Menurut Berson dan Smith (2001,p4), data warehouse adalah gabungan teknologi
yang bertujuan mengefektifkan integrasi database operasional ke dalam lingkungan yang
memungkinkan penggunaan secara strategis.
Menurut
Poe
(1996,p24)
data
warehouse adalah
database yang
bersifat
analisis
yang digunakan sebagai landasan dalam sistem pendukung keputusan.
Berdasarkan
pengertian–pengertian
di
atas, dapat disimpulkan bahwa
data
warehouse adalah suatu kumpulan data yang bersifat berorientasi subjek (subject
oriented), terintegrasi (intergrated), tidak berubah (non volatile), memiliki variasi waktu
(time variant) yang mendukung proses pengambilan keputusan.
|
 8
2.7 Perbandingan Data Operasional dan Data Warehouse
Secara umum, perbandingan antara data operasional dan data warehouse:
Tabel 2.1 Perbandingan Umum antara Data Operasional
dan Data warehouse (Inmon, 2002, p15)
Data Operasional
Data Warehouse
•
Berorientasi aplikasi
•
Detail
•
Dapat di-update
•
Disajikan untuk komunitas operasional
•
Sesuai
dengan
SDLC
(System
Development Life Cycle)
•
Jumlah data yang diproses kecil
•
Non-redundancy (Normalisasi)
•
Struktur yang tetap / statis
•
Mendukung operasional sehari-hari
•
Pengaksesan data besar
•
Berorientasi subjek
•
Ringkas dan telah disaring
•
Tidak dapat di-update
•
Disajikan untuk komunitas manajerial
•
Siklus hidup yang lebih lengkap
•
Jumlah data yang diproses besar
•
Redundancy (Denormalisasi)
•
Struktur yang fleksibel
•
Mendukung kebutuhan manajerial
•
Pengaksesan data kecil / sedang
2.8 Karakteristik Data Warehouse
Menurut Inmon (2002, p31), beberapa karaketeristik data warehouse antara lain :
2.8.1 Subject Oriented
Pada
awalnya
sistem pengoperasian
diatur
berdasarkan aplikasi
dari perusahaan.
Contohnya untuk perusahaan asuransi, aplikasi yang digunakan adalah kesehatan,
kehidupan, dan kecelakaan. Subjek dari perusahaan tersebut adalah pelanggan,
kebijakan,
premi,
dan
klaim.
Jadi
pada
data warehouse
tidak
berdasarkan
aplikasi
melainkan berdasarkan subjek.
2.8.2 Integrated
Karakteristik
kedua
dari
data
warehouse adalah
terintegrasi.
Dari
semua
aspek
data warehouse, integrasi adalah yang terpenting. Data diambil dari beberapa sumber ke
dalam data warehouse. Data tersebut diubah, diformat
ulang, disusun ulang, diringkas
|
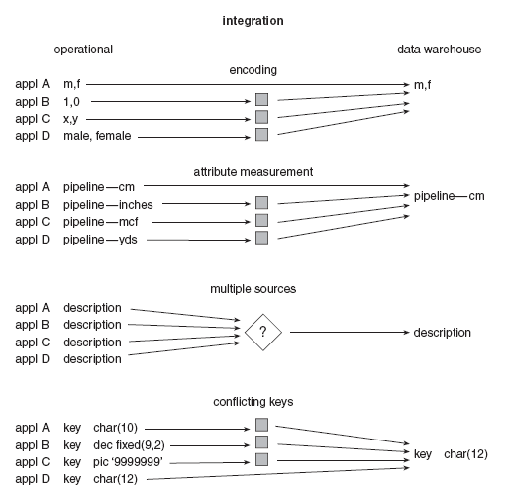 9
dan seterusnya. Hasil dari data tersebut
tinggal di data warehouse
mempunyai sebuah
gambar fisik perusahaan.
Gambar 2.1 Permasalahan dalam integrasi (Inmon, 2005, p31)
2.8.3 Non volatile
Karakter penting ketiga dari data warehouse adalah
tidak berubah (non volatile).
Data dapat diakses, dimanipulasi (update) pada lingkungan operasional akan tetapi, pada
data warehouse data hanya dapat di-load dan diakses tetapi tidak dapat di-update.
|
 10
2.8.4 Time variant
Karakteristik terakhir dari data warehouse adalah variasi waktu. Maksudnya
adalah setiap unit data dalam data warehouse akurat dalam suatu momen dalam waktu.
Tabel 2.2 Perbandingan Time Variant antara Data Operasional
dan Data Warehouse (Inmon, 2002, p35)
Data Operasional
Data Warehouse
•
Mempunyai time horizon 60-90 hari
•
Data atau record dapat di-update
•
Key
structure
dapat
termasuk
atau
tidak termasuk elemen waktu
•
Mempunyai time horizon 5-10 tahun
•
Data atau record tidak dapat di-update
•
Key structure termasuk elemen waktu
2.9 Struktur Data Warehouse
Menurut
Inmon
(2002,
p35),
data
mengalir
ke
dalam data
warehouse
dari
lingkungan operasional. Biasanya data mengalami transformasi signifikan dari tingkat
operasional ke tingkat data warehouse. Data dilewatkan dari current detail data ke older
detail.
Setelah
data
diringkas,
data
tersebut
dilewatkan
dari
current
detail
ke lightly
summarized data, kemudian dari lightly summarized data ke highly summarized data.
|
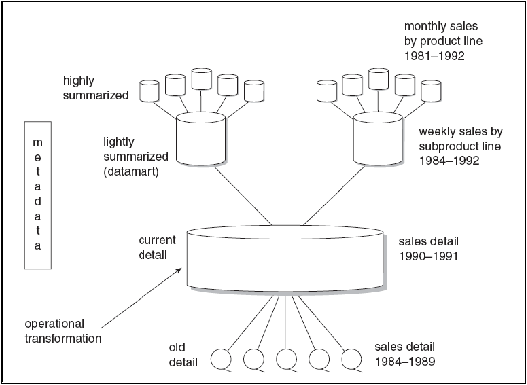 11
Gambar 2.2 Struktur Data Warehouse (Inmon, 2002, p36)
Current Detailed Data
Current detailed data merupakan data yang sekarang yang diperoleh dari database
operasional. Data ini sangat banyak dan detail.
Old Detailed Data
Old detailed data merupakan ringkasan data atau summary didapat
dari current
detail data yang di-backup dan disimpan dalam media penyimpanan yang terpisah. Data
disimpan dalam sebuah penyimpanan seperti magnetic tape atau optical disk.
|
|
12
Lightly Summarized Data
Lightly
summarized
data
merupakan
data
ringkasan
atau summary
dari current
detailed data yang bersifat "total summary" dan rinci. Lightly summarized data biasa
disebut data mart.
Highly Summarized Data
Highly summarized data
merupakan data
yang telah diringkas secara menyeluruh
dan digunakan untuk mendukung pengambilan keputusan.
Metadata
Menurut Inmon (2002, p393), metadata adalah data tentang data, deskripsi dari
struktur, isi, kunci, indeks, dan lain-lain dari data.
Menurut Inmon (2005, p269-270), hal-hal penting dari metadata meliputi:
a. ID dokumen
b. Tanggal entri ke warehouse
c. Deskripsi dari dokumen
d. Sumber dari dokumen
e. Tanggal sumber dari dokumen
f.
Klasifikasi dokumen
g. Indeks kata
h. pembersihan tanggal
i.
Lokasi fisikal
j.
Panjang dokumen
k. Referensi terkait
|
|
13
Menurut Connolly dan
Begg
(2002, p1055),
metadata digunakan untuk berbagai
tujuan meliputi :
a. Proses ekstraksi dan loading
Metadata digunakan untuk
memetakan sumber data ke dalam pandangan
umum dari data dalam warehouse.
b. Proses manajemen warehouse
Metadata digunakan untuk mengotomatiskan pembuatan tabel ringkasan.
c. Sebagai bagian dari proses manajemen query
Metadata digunakan untuk
menghubungkan suatu query dengan sumber data
yang tepat.
2.10 Arsitektur Data warehouse
Arsitektur data warehouse merupakan suatu kerangka yang dirancang dengan cara
memahami
bagaimana
data
dipindahkan
di
dalam sistem.
Karakteristik
arsitektur dari
data warehouse adalah:
a. Data diambil dari sistem informasi yang telah ada, database, dan file.
b. Data tersebut diintegrasikan dan ditransformasikan sebelum disimpan ke dalam
data warehouse.
c. Data warehouse adalah read-only database yang diciptakan untuk mengambil
keputusan.
d. User mengakses data warehouse melalui front-end tool atau aplikasi.
|
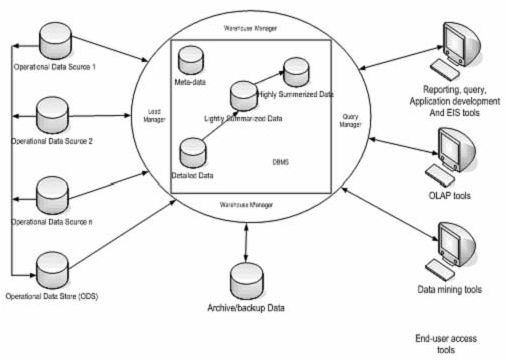 14
Gambar 2.3 Gambar Arsitektur Data warehouse (Connolly dan Begg , 2002, p1053)
Komponen
utama data
warehouse
menurut
Connolly dan Begg
(2002,
p1053)
adalah:
a. Operational
Data, sumber data
ini didapat
dari
data
operasional yang
dilakukan pada database awal.
b.
Operational Data Store (ODS), tempat penyimpanan data operasional yang
sedang terjadi dan yang terintegrasi digunakan untuk analisa.
c. Load Manager (sering juga disebut komponen front-end), menampilkan semua
operasi yang diasosiasikan dengan
data yang telah diekstrak dan di-load ke
dalam warehouse.
d. Warehouse Manager, menampilkan semua operasi yang diasosiasikan dengan
manajemen data dalam warehouse.
|
|
15
e. Query Manager (disebut juga dengan komponen back-end), menampilkan
semua operasi yang diasosiasikan dengan manajemen dari queries pengguna.
f.
Archive/
Backup
Data,
area
warehouse
yang
menyimpan
detailed
dan
summarized data yang bertujuan sebagai arsip dan backup data.
g.
End-User Access Tools,
dapat dikategorikan
menjadi
lima
grup
utama: data
reporting
and
query tools,
application development tools,
executive
information systems (EIS) tools, online analytical processing (OLAP) tools and
data mining tools.
h.
Detailed Data, Meta-data, Lightly and Hightly Summarized Data, untuk
komponen ini sudah dijelaskan pada bagian struktur data warehouse.
2.11 Aliran Data Pada Data Warehouse
Menurut Connolly dan Begg (2002, p1057), Data warehouse memfokuskan pada
manajemen dari
lima
aliran
data
utama
yaitu
inflow,
upflow, downflow,
outflow, dan
meta-flow. Proses yang berasosiasi dengan setiap aliran data, yaitu:
a. Inflow:
Proses
yang
berhubungan
dengan
pengekstrakan
(extraction),
pembersihan (cleansing), dan pemuatan (loading) data dari sistem sumber ke
dalam data warehouse.
b. Upflow: Proses yang berhubungan dengan penambahan
nilai dari data dalam
data warehouse melalui peringkasan (summarizing), pengemasan (packaging),
dan pendistribusian data.
c.
Downflow: Proses yang berhubungan dengan pengarsipan (archiving)
dan
pembuatan cadangan (back-up) data dalam data warehouse.
|
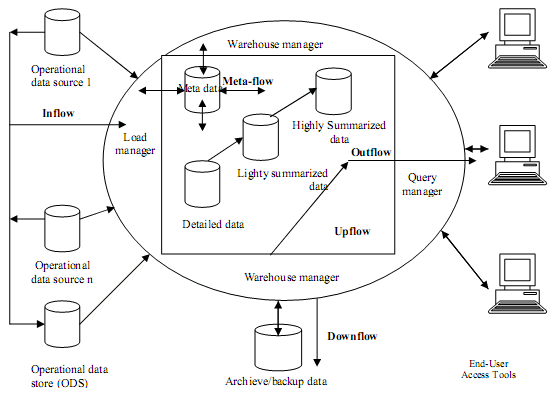 16
d. Outflow: Proses yang berhubungan dengan pengadaan data agar tersedia bagi
end-user.
e. Meta-flow: Proses yang berhubungan dengan manajemen dari metadata.
Gambar 2.4 Gambar Aliran Data warehouse (Connolly dan Begg , 2002, p1058)
2.12 Keuntungan Data warehouse
Menurut Connolly dan Begg (2002, p1048), pengimplementasian yang sukses dari
sebuah data warehouse dapat memberikan keuntungan besar bagi perusahaan, yaitu:
1. Keuntungan potensial yang besar dalam investasi.
Suatu
organisasi
harus
memiliki
sumber
daya
dalam jumlah
besar
untuk
memastikan kesuksesan pengimplementasian data warehouse dan jumlah biaya
yang dikeluarkan bervariasi
besarnya tergantung dari solusi teknis yang
|
|
17
tersedia. Tetapi investasi dalam data warehouse dapat memberikan keuntungan
yang besar setelah pengimplementasiannya.
2. Keuntungan yang kompetitif
Keuntungan kompetitif didapatkan dengan memperbolehkan para pengambil
keputusan untuk mengakses data yang dapat mengungkapkan data-data yang
sebelumnya tidak tersedia, tidak diketahui dan informasi yang tidak tercatat.
3. Meningkatnya produktivitas dari pengambil keputusan perusahaan
Dengan
mentransformasikan
data menjadi
informasi
yang
berarti, data
warehouse memungkinkan para
manajer bisnis melakukan analisa
yang
lebih
konsisten,
akurat
dan
substantive
sehingga
terjadi
peningkatan
produktivitas
dari pengambilan keputusan perusahaan.
Menurut Mallach (2000,p182), kerugian dari penerapan data warehouse yaitu :
•
Terdapat beban tambahan pada sistem pusat karena perlunya melakukan transfer
data diantara dua sistem (sistem operasional dan data warehouse) untuk menjaga
data tetap update.
•
Harus mempunyai karyawan yang mengerti kedua sistem tersebut.
•
User yang mengakses kedua sistem memerlukan dua tipe terminal.
•
Transfer data dari sistem operasional kedata warehouse memerlukan waktu yang
relatif
lama.
2.13 Data Mart
Menurut Connoly
(2002, p 1067), data mart adalah bentuk atau versi yang lebih
kecil dari data warehouse, biasanya mengandung data yang berhubungan dengan sebuah
|
|
18
area fungsional dari perusahaan atau memiliki lingkup yang terbatas. Berikut
karakteristik yang membedakan antara data mart dengan data warehouse:
a. Data mart berfokus pada kebutuhan pengguna yang berhubungan dengan satu
bagian departemen atau fungsi bisnis.
b. Data mart tidak berisi data operasional yang bersifat detail.
c. Data mart lebih mudah dimengerti dan digunakan karena berisi data yang lebih
sedikit dari data warehouse.
2.14 Teori Permodelan Data warehouse
Untuk
pemodelan data warehouse, lebih digunakan teknik pemodelan
dimensional. Dengan teknik ini, dapat dibuat tabel fakta, tabel dimensi, dan membangun
relasi
antara
masing-masing
tabel dimensi
dan tabel
fakta.
Ada beberapa
hasil
pemodelan tersebut, antara lain :
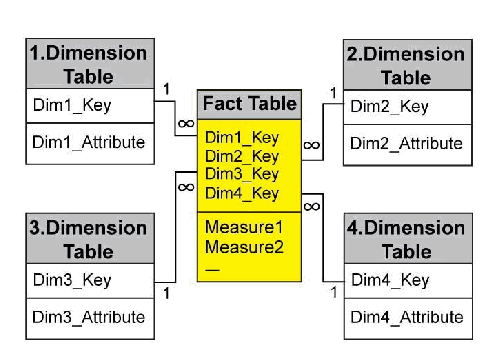
2.14.1 Skema Bintang (Star Schema)
Menurut Ponniah (2001, p210-216), skema bintang (star schema) adalah teknik
dasar desain data untuk data warehouse. Struktur skema bintang adalah suatu struktur
yang dapat dengan mudah dipahami dan digunakan oleh pengguna seperti yang terlihat
pada Gambar 2.5. Struktur tersebut mencerminkan bagaimana pengguna biasanya
memandang ukuran-ukuran kritis mengikuti dimensi-dimensi bisnis yang ada.
|
 19
Gambar 2.5 Contoh Skema Bintang
Karakteristik dari komponen skema bintang:
1. Tabel dimensi
a. Key tabel dimensi
Key tabel dimensi
merupakan
primary
key dari
tabel dimensi
yang
mengidentifikasi setiap baris dalam tabel secara unik.
b. Merupakan tabel yang lebar
Tabel dimensi memiliki jumlah kolom atau atribut yang banyak, oleh
karena itu tabel dimensi bersifat lebar.
|
){kind=link}
|
20
c. Atribut berupa teks
Dalam tabel dimensi,
jarang ditemukan
nilai
numerik
untuk
perhitungan,
atribut
umumnya
berupa
teks
yang
merepresentasikan
deskripsi
tekstual
dari komponen-komponen dalam dimensi bisnis.
d. Atribut-atribut tidak berhubungan secara langsung
Sebagai contoh, ukuran paket dan merek produk tidak saling berhubungan,
namun sama-sama dapat menjadi atribut tabel dimensi produk.
e. Tidak dinormalisasi
Untuk kinerja query
yang
efisien, paling baik jika
query
mengambil dari
tabel
dimensi dan
langsung
ke
tabel
fakta tanpa
melalui
tabel
perantara
yang akan terbentuk jika tabel dimensi dinormalisasi.
f.
Kemampuan drill-down dan roll-up
Atribut-atribut
dalam tabel
dimensi
menyediakan
kemampuan
untuk
mendapatkan detail dari tingkat tinggi agregasi sampai tingkat detail
yang
rendah. Sebagai contoh, jumlah penjualan dapat dilihat berdasarkan
propinsi, lalu dapat drill-down ke kota dan kode pos atau total penjualan
berdasarkan kode pos dapat roll-up ke kota dan propinsi.
g. Terdapat beberapa hirarki
Berbagai bagian
perusahaan dapat mengelompokkan dimensi dengan cara
yang berbeda, sehingga terbentuk lebih dari 1 hirarki.
h. Jumlah record yang lebih sedikit
Tabel
dimensi
umumnya
memiliki
jumlah record atau baris yang lebih
sedikit dari tabel fakta.
|
|
21
2. Tabel fakta
a. Concatenated key
Baris
dalam
tabel
fakta
diidentifikasi
dengan
menggunakan
primary
key
dari
tabel-tabel
dimensi,
maka primary
key
dari
tabel
fakta
merupakan
gabungan primary key dari semua tabel dimensi.
b. Data grain
Data
grain merupakan
tingkat
detail
untuk
pengukuran. Sebagai
contoh,
jumlah pemesanan berhubungan dengan jumlah produk tertentu pada suatu
pesanan,
tanggal
tertentu,
untuk
pelanggan
spesifik
dan diperoleh
oleh
seorang perwakilan penjualan spesifik tertentu. Jika jumlah pesanan dilihat
sebagai jumlah untuk suatu produk perbulan, maka data grain-nya berbeda
dan pada tingkat yang lebih tinggi.
c. Fully additive measures
Agregasi dari fully additive measures dilaksanakan dengan penjumlahan
sederhana nilai-nilai atribut tersebut.
d. Semiadditive measures
Semiadditive measures
merupakan nilai yang tidak dapat langsung
dijumlahkan, sebagai contoh persentase keuntungan.
e. Tabel besar, tidak lebar
Tabel fakta umumnya memiliki lebih sedikit atribut daripada tabel dimensi,
namun memiliki jumlah record yang lebih banyak.
f.
Sparse data
Tabel fakta tidak perlu menyimpan record
yang nilainya null, maka tabel
fakta dapat memiliki gap.
|
|
22
g. Degenerate dimensions
Terdapat
elemen-elemen
data
dari
sistem operasional
yang
bukan
merupakan fakta ataupun dimensi, seperti nomor pesanan, nomor tagihan,
dan
lain-lain.
Namun
atribut-atribut
tersebut
dapat
berguna
dalam jenis
analisis
tertentu.
Sebagai
contoh, mencari
rata-rata
jumlah
produk
per
pesanan, maka produk harus dihubungkan
ke
nomor
pesanan
untuk
mendapatkan
nilai
rata-rata.
Atribut-atribut
tersebut
disebut degenerate
dimension dan disimpan sebagai atribut dari tabel fakta.
Keuntungan skema bintang:
1. Mudah dipahami pengguna
Skema
bintang
menggambarkan
dengan
jelas
bagaimana
pengguna
berpikir
dan memerlukan data untuk query dan analisa. Skema bintang menggambarkan
hubungan antar tabel sama seperti cara pengguna melihat hubungan tersebut
secara normal.
2. Mengoptimalkan navigasi
Skema bintang mengoptimalisasikan navigasi melewati database sehingga
lebih mudah dilihat. Meskipun hasil query terlihat kompleks, tetapi navigasi itu
memudahkan pengguna.
3. Paling cocok untuk pemrosesan query
Skema bintang paling cocok
untuk pemrosesan query karena skema
ini
berpusat pada query. Tanpa bergantung pada banyak dimensi dan kompleksitas
query, setiap query akan dengan
mudah dijalankan, pertama dengan memilih
|
|
23
baris dari table dimensi dan kemudian
menemukan baris
yang sama di tabel
fakta.
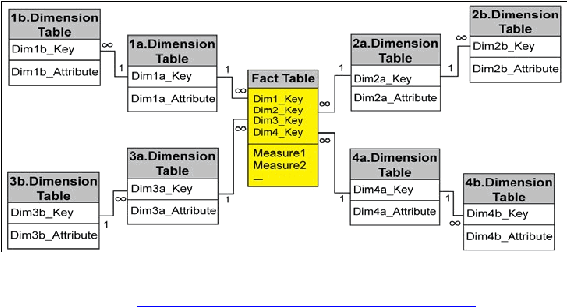
2.14.2 Skema Snowflake (Snowflake Schema)
Menurut
Ponniah
(2002,
p235),
Snowflake merupakan
variasi
lain
dari
skema
bintang dimana tabel dimensi dari skema
bintang dinormalisasi, seperti yang
digambarkan pada
Gambar
2.6.
Prinsip
dasar
dari
skema
ini
tidak jauh
berbeda dari
skema
bintang.
Dalam menormalisasi
tabel
dimensi,
ada
beberapa pilihan
yang dapat
diperhatikan, antara lain :
1. Secara parsial, lakukan normalisasi hanya beberapa tabel dimensi saja, dan
sisakan yang lain tetap utuh.
2. Secara lengkap atau parsial, lakukan normalisasi hanya pada beberapa tabel
dimensi, dan tinggalkan yang tersisa dengan utuh.
3. Secara parsial, lakukan normalisasi pada setiap tabel dimensi.
4. Secara lengkap, lakukan normalisasi pada setiap tabel dimensi.
Keuntungan dari skema snowflake:
1. Ukuran penyimpanan kecil di dalam tempat penyimpanan.
2. Struktur yang normal lebih mudah untuk di-update dan dijaga.
Kerugian dari skema snowflake :
1. Skemanya kurang intuitif / jelas dan pengguna akhir terhambat oleh
kompleksitas.
2. Sulit untuk mencari isi skema karena terlalu kompleks.
3. Performa query menurun karena adanya tambahan gabungan tabel.
|
 24
Gambar 2.6 Contoh Skema Snowflake
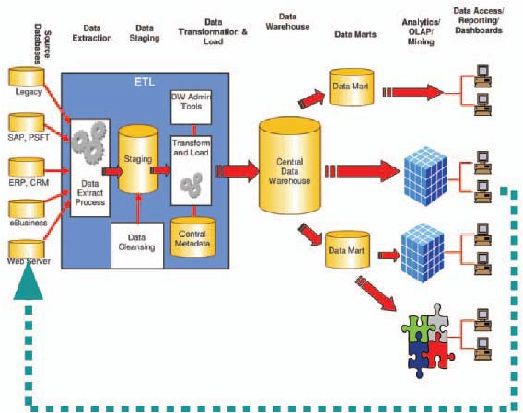
2.15 ETL (Extract, Transform, Loading)
ETL (Extract, Transform, and Load) adalah proses-proses dalam data warehouse
yang meliputi:
1. Mengekstrak data dari sumber-sumber eksternal.
2. Mentransformasikan data ke bentuk yang sesuai dengan keperluan.
3. Memasukkan data ke target akhir, yaitu data warehouse.
ETL merupakan proses yang sangat penting, dengan ETL, data dapat dimasukkan
ke
dalam data
warehouse.
ETL
juga
dapat
digunakan
untuk
mengintegrasikan
data
dengan sistem yang sudah ada sebelumnya.
Tujuan ETL adalah mengumpulkan, menyaring, mengolah, dan menggabungkan
data-data yang relevan dari berbagai sumber untuk disimpan ke dalam data warehouse.
Hasil
dari
proses
ETL
adalah dihasilkannya
data
yang
memenuhi
kriteria data
warehouse seperti data yang historis, terpadu, terangkum, statis, dan memiliki struktur
yang dirancang untuk keperluan proses analisis.
|
|
25
2.15.1 Extract
Langkah pertama pada proses ETL adalah mengekstrak data dari sumber-sumber
data.
Kebanyakan
proyek
data
warehouse
menggabungkan
data
dari
sumber-sumber
yang
berbeda. Sistem-sistem yang
terpisah sangat
mungkin
menggunakan
format data
yang berbeda.
Ektraksi adalah mengubah data ke dalam suatu format yang berguna untuk proses
transformasi. Pada hakekatnya proses ekstraksi adalah proses penguraian dari data yang
diekstrak untuk mendapatkan struktur atau pola data yang diharapkan. Jika struktur atau
pola
data
tidak
sesuai
dengan
harapan
maka
data
tidak
dimasukkan
ke
dalam data
warehouse.
2.15.2 Transform
Tahapan transformasi
menggunakan serangkaian aturan atau fungsi untuk
mengekstrak
data
dari
sumber dan selanjutnya akan dimasukkan ke data warehouse.
Berikut adalah hal-hal yang dapat dilakukan dalam tahapan transformasi:
1. Hanya
memilih
kolom
tertentu
saja
untuk
dimasukkan
ke
dalam data
warehouse.
2.
Menterjemahkan nilai-nilai yang berupa kode (contohnya apabila database
sumber menyimpan nilai 1 untuk laki-laki dan nilai 2 untuk perempuan, tetapi
data warehouse yang telah ada menyimpan M untuk laki-laki dan F untuk
perempuan,
ini
disebut
dengan automated
data
cleansing,
tidak
ada
pembersihan secara manual yang ditunjukkan selama proses ETL).
3. Mengkodekan
nilai-nilai ke dalam bentuk bebas (Contohnya
memetakan
“Male” , “1” dan “Mr” ke dalam M).
|
|
26
4. Melakukan perhitungan
nilai-nilai baru (Contohnya sale_amount = qty *
unit_price).
5. Menggabungkan data secara bersama-sama dari berbagai sumber.
6. Membuat
ringkasan
dari
sekumpulan
baris
data
(Contohnya
total
penjualan
untuk setiap toko atau setiap bagian).
7. Men-generate nilai surrogate key.
8. Transposing atau pivoting (Mengubah sekumpulan kolom menjadi sekumpulan
baris atau sebaliknya).
9.
Memisahkan sebuah
kolom menjadi berbagai kolom (Contohnya
meletakkan
sebuah comma-separated list yang dispesifikasikan sebagai sebuah string
dalam satu kolom sebagai nilai yang tersendiri dalam kolom yang berbeda).
10. Menggunakan berbagai bentuk validasi data baik yang sederhana maupun
kompleks.
2.15.3 Loading
Fase
load
merupakan
tahapan yang berfungsi untuk
memasukkan
data
ke
dalam
target akhir, yang biasanya ke dalam suatu
data warehouse. Jangka waktu proses ini
tergantung
pada kebutuhan
organisasi.
Beberapa data
warehouse dapat
setiap
minggu
menulis keseluruhan informasi yang ada secara kumulatif, data diubah, sementara data
warehouse yang lain (atau bagian lain dari data warehouse
yang sama) dapat
menambahkan data baru dalam suatu bentuk yang historikal, contohnya setiap jam.
Waktu dan jangkauan untuk mengganti atau menambah data tergantung dari
perancangan data warehouse pada waktu menganalisis keperluan informasi.
|
|
27
Fase load berinteraksi dengan suatu database, constraint didefinisikan dalam
skema
database
sebagai
suatu trigger
yang
diaktifkan
pada
waktu
me-load
data
(Contohnya uniqueness, referential integrity, mandatory fields), yang juga berkontribusi
untuk keseluruhan performance dan kualitas data dari proses ETL.
Masalah-masalah yang terjadi dalam ETL adalah sumber-sumber data umumnya
sangat bervariasi diantaranya:
1. Platform mesin dan operating system yang berlainan.
2. Mungkin melibatkan sistem kuno dengan teknologi basis data yang sudah
ketinggalan zaman.
3. Kualitas data yang berbeda-beda.
4. Aplikasi sumber data mungkin menggunakan nilai data (representasi) internal
yang sulit dimengerti.
|
 28
Gambar 2.7 Extract, Transform, Loading (ETL)
|