|
BAB 2
LANDASAN TEORI
2.1. Teori-Teori Umum
2.1.1. Pengertian Data
Menurut
O’Brien
(2005,p38)data adalah fakta atau
observasi
mentah
yang
biasanya mengenai transaksi bisnis.
2.1.2. Pengertian Informasi
Menurut McLeod and Schell (2001,p12), informasi merupakan data yang
telah diproses atau data yang memiliki makna.
2.1.3. Pengertian Database
Menurut Connoly dan Begg (2005,p15), database adalah kumpulan data-data
yang saling berhubungan satu sama lain yang digunakan secara bersama-sama dan
dirancang untuk memenuhi kebutuhan informasi perusahaan atau organisasi.
2.1.4. Pemodelan Entity Relationship
Menurut
Connoly
dan
Begg
(2005,p342),
pemodelan
ER adalah pendekatan
dari atas ke bawah untuk merancang
database
yang
dimulai
dengan
mengidentifikasi data yang penting yang dikenal dengan sebutan entitas dan
hubungan
antara
data
harus
diperlihatkan
dalam model
ini.
Konsep
dasar
dari
pemodelan ER antara lain:
a)
Entitas (Entity)
Menurut Connoly dan Begg
(2005,p343), entity
type adalah sekumpulan
objek dengan properti
yang sama, dimana diidentifikasikan oleh perusahaan
karena mempunyai keadaan bebas. Menurut Connoly dan Begg (2005,
|
 p333),
entity
occurence adalah
objek
yang
didefinisikan
secara
unik
dari
entity
type.
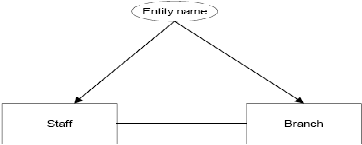
Entity
type
digambarkan
dalam bentuk
bujur
sangkar
dengan
diberi nama entitas, yang umumnya adalah kata benda tunggal, dapat dilihat
pada gambar 2.1
Gambar 2.1 Diagram dari Entity Type Branch dan Staff
(Sumber : Connoly dan Begg, 2005, p345)
b)
Hubungan (Relationship)
Menurut Connoly dan Begg (2005, p346),
relationship type
adalah
sekumpulan asosiasi berarti antara entity types.
Setiap relationship type digambarkan dengan garis yang menghubungkan
entity
type,
dan
diberi
nama
hubungannya
seperti
pada
gambar 2.2
Pada
umumnya, hubungannya menggunakan kata kerja atau frase pendek yang
mengandung kata kerja. Jika memungkinkan, nama hubungannya harus
bersifat unik. Secara umum, nama
hubungan hanya mempunyai arti untuk
satu arah saja. Contohnya
:
pada
gambar dibawah
ini
menyatakan
bahwa
Branch memilliki Staff.
|
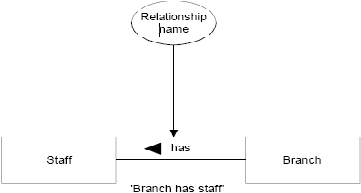 Gambar 2.2 Diagram dari Relationship Type Branch mempunyai Staff
(Sumber : Connoly dan Begg ,2005, p347)
c)
Atribut (Attribute)
Menurut Connoly dan Begg (2005, p350), atribut adalah properti dari
sebuah entitas atau relationship type. Contohnya, Staff memiliki atribut
StaffNo, nama, posisi, dan gaji.
d)
Multiplicity
Menurut
Connoly
dan
Begg
(2005,
p356), multiplicity
adalah
sejumlah
kemunculan
yang
mungkin
ada
dalam sebuah
entitas
yang
berhubungan
dengan kemunculan tunggal dari entitas yang berhubungan dengannya.
Tiga tipe hubungan multiplicity adalah :
|
 •
1:1 (One-to-One)
Contoh dari hubungan ini ádalah :
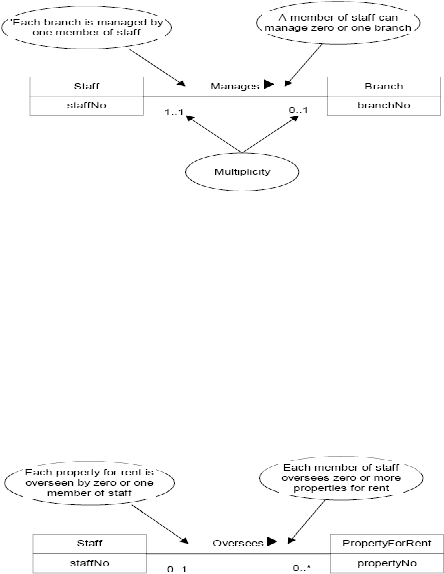
Gambar 2.3 Multiplicity hubungan satu ke satu dari staff yang mengatur Branch
(Sumber : Connoly dan Begg,2005, p358)
Artinya,
seorang
staff
dapat mengatur nol atau satu cabang dan
masing-masing cabang di atur oleh satu staff.
•
1:* (One-to-Many)
Contoh dari hubungan ini adalah :
Gambar 2.4 Multiplicity hubungan satu ke banyak dari staff yang mengawasi property for
rent
(Sumber : Connoly dan Begg, 2005, p359)
|
 Artinya, seorang staff dapat mengawasi nol atau lebih properti yang
akan disewa dan sebuah properti yang akan disewa diawasi oleh nol
atau satu staff.
•
*:* (Many-to-Many)
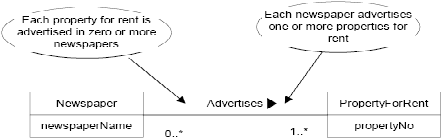
Contoh dari hubungan ini adalah :
Gambar 2.5 Multiplicity hubungan banyak ke banyak dari newspaper yang
mengiklankan property for rent
(Sumber : Connoly dan Begg, 2005, p360)
Artinya, satu koran mengiklankan satu atau lebih properti yang akan
disewa dan satu properti yang akan disewa diiklankan oleh nol atau
lebih koran.
2.1.5. Konsep Data warehouse
2.1.5.1 Pengertian Data Warehouse
Menurut Inmon (2005,p29), data warehouse merupakan kumpulan
dari database yang memiliki sifat berorientasi subjek, terintegrasi, yang
dirancang untuk dapat mendukung pengambilan keputusan dalam
organisasi, dimana tiap datanya berhubungan dengan suatu kejadian yang
terjadi pada suatu waktu tertentu.
|
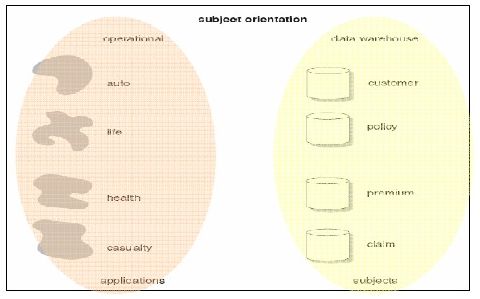 2.1.5.2 Karakteristik Data Warehouse
Menurut Inmon (2005,p29), sebuah data warehouse
memiliki
karakteristik sebagai berikut :
1.
Subject Oriented
Data warehouse bersifat subject oriented berarti bahwa
data
warehouse
bukan
berorientasikan
pada proses atau fungsi
aplikasi
tertentu,
melainkan
pada subyek-subyek
tertentu
dalam
perusahaan, yang mana biasanya memiliki subyek-subyek yang
unik
untuk
tiap
perusahaannya. Misalnya
:
untuk
perusahaan
asuransi subyeknya adalah pelanggan, kebijakan, premi, dan
keluhan; dalam pabrik subyeknya adalah produk, pesanan, vendor,
tagihan material, bahan baku; dan sebagainya.
Gambar 2.6 Aspek Subject Oriented dari Data Warehouse
(Sumber : Inmon, 2005, p30)
|
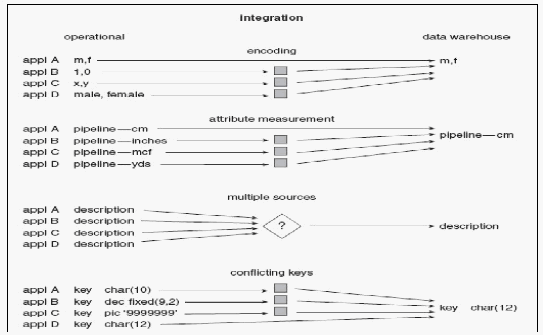 2.
Integrated
Karakteristik integrasi ini dapat dikatakan merupakan aspek
terpenting dari
data warehouse.
Integrasi
disini dimaksudkan
bahwa
data
dalam data warehouse
memiliki satu
bentuk
tunggal
fisikal yang sama dan konsisten walau berasal dari sumber
yang
berbeda-beda. Termasuk juga konsistensi pada aplikasi yang
mengaksesnya, aturan pengentrian
data, aturan penamaan atribut,
dan karakteristik fisikal data lainnya. Jadi pengkodean pada data
warehouse
dilakukan secara
konsisten
tanpa
terpengaruh pada
metode
maupun
sumber
aplikasinya berjalan seperti
bagaimanapun.
Gambar 2.7 Integrasi Data Warehouse
(Sumber : Inmon, 2005, p31)
|
 3.
Time Variant
Variasi waktu disini diartikan bahwa data di dalam sebuah
data warehouse berhubungan dengan suatu titik atau point dalam
suatu periode waktu tertentu. Misalnya semester, kwartalan, tahun
fiskal, atau periode pembayaran. Sebagai contoh, data yang
menunjukkan penjualan produk yang terlaris per tahun, jumlah
pembelian per kwartal, dan sebagainya.
Tabel 2.1 Perbandingan time variant antara data opersional dan data warehouse
(Inmon, 2005, p32)
Data Operasional
Data Warehouse
Mempunyai time horizon 60 - 90
hari
Data atau record dapat di-update
Key structure dapat termasuk atau
tidak termasuk elemen waktu
Mempunyai time horizon 5 - 10
tahun
Data atau record tidak dapat di-
update
Key structure termasuk elemen
waktu
4.
Nonvolatile (Tidak dapat berubah)
Karakteristik data
warehouse
nonvolatile dapat diartikan
bahwa
ketika
data
sudah
disimpan
ke
dalam
sebuah data
warehouse, data harus tidak boleh berubah atau tidak boleh ada
perubahan didalamnya.
|
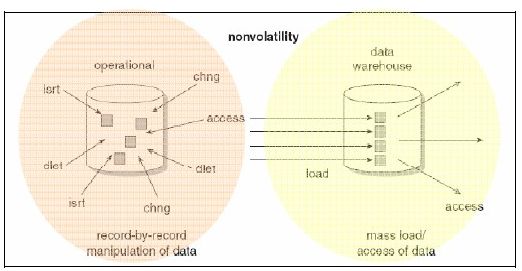 Gambar 2.8 Aspek Non-Volatile dari Data Warehouse
(Sumber : Inmon, 2005, p32)
2.1.5.3 Struktur Data Warehouse
Data warehouse mempunyai struktur yang spesifik dan
mempunyai
perbedaan
dalam tingkatan
ringkasan (summary)
dan
detail
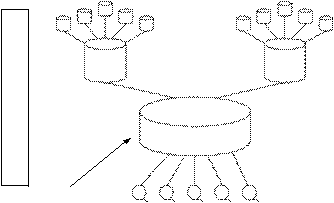
data serta perbedaan dalam tingkatan umur data. Menurut
Inmon(2005,p33) terdapat beberapa level
of
detail yang berbeda dalam
dalam data warehouse, yaitu :
•
Current detail data (data detail saat ini)
•
Old detail data (data detail historis)
•
Lightly summarized data (data ringkasan level menengah)
•
Highly summarized data (data ringkasan level tinggi)
|
 M
E
T
A
D
A
T
Current Detail
A
Highly
Summarized
Lightly Summarized
(Data Mart)
Operational
Transformation
Old Detail
Gambar 2.9 Struktur Data Warehouse
(Sumber : Inmon, 2005, p34)
1.
Current detailed data
Pada bagian ini current detail data disimpan dalam skema
database. Data ini
tidak disimpan secara
langsung, tetapi data
ini
ditambahkan
dalam warehouse
untuk
melengkapi
data
yang
terkumpul. Data ini menjadi berguna saat detil data terkumpul pada
tahap berikutnya.
2.
Old detailed data
Old detailed data merupakan
data detil
dan
ringkas
yang
berguna
untuk
arsip
dan back
up.
Meskipun
ringkasan
data
atau
summary
didapat
dari current detailed data, tetapi masih
memungkinkan untuk menyimpan ringkasan data tersebut secara
langsung jika data berada diluar periode
current detailed data.
Data
disimpan
dalam sebuah
penyimpanan seperti magnetic
tape
atau optical disk.
|
|
3.
Lightly summarized data
Lightly summarized data
merupakan
data
ringkasan
atau
summary
dari
current
detailed
data.
Pada
tingkat
ini,
data hasil
ringkasan
masih
belum dapat
digunakan
dalam proses
pengambilan keputusan karena belum bersifat ‘total summary’ dan
menjadi bersifat rinci.
Lightly summarized data biasanya sering digunakan untuk
gambaran dari keadaan yang sedang berlangsung dan sudah
berlangsung.
4.
Highly summarized data
Highly summarized data merupakan hasil proses summary
yang
bersifat
‘totalitas’.
Data pada highly
summarized ini
sangat
mudah diakses. Data pada tingkat inilah yang pada akhirnya
digunakan untuk mendukung pengambilan keputusan terutama
dikalangan eksekutif dalam dunia bisnis.
Hal ini disebabkan karena data pada tingkat ini dianggap
sudah cukup representative dan ringkas. Akan tetapi tetap dapat
merepresentasikan keadaan data secara keseluruhan. Hal ini
tentu
saja sangat memudahkan kalangan pimpinan atau eksekutif karena
tidak perlu lagi membaca dan melakukan analisis data untuk waktu
yang cukup lama.
|
|
2.1.5.4 Keuntungan Data Warehouse
Menurut Connolly dan Begg (2005, p1152), keuntungan data
warehouse adalah:
1.
Potensial ROI (Returns on Investment) yang tinggi. Organisasi
harus menjalankan jumlah yang besar dari sumber untuk menjamin
kesuksesan implementasi dari data warehouse
dan biaya yang
sangat
besar bagi solusi technical support yang tersedia.
Penyelidikan dari International Data Corporation (IDC) pada
tahun 1996 menjalankan rata-rata ROI dalam 2 tahun dengan data
warehousing mencapai
401%, diatas 90% perusahaan yang
disurvei mencapai diatas 160% ROI, dan seperempatnya lebih dari
600% ROI.
2.
Competitive Advantage. ROI yang besar bagi perusahaan-
perusahaan diperoleh dari kesuksesan data warehouse
merupakan
fakta bahwa competitive advantage yang besar menyertai teknologi
ini. Competitive advantage diperoleh dengan menyediakan akses
pembuatan keputusan ke data yang dapat mengungkapkan
ketidaksediaan, ketidakpahaman, dan ketidakterbukaan informasi
sebelumnya, sebagai contoh customer, trend, dan permintaan.
3.
Meningkatkan produktivitas
pembuatan
keputusan
perusahaan.
Data warehouse meningkatkan produktivitas pembuatan keputusan
perusahaan
dengan
menciptakan
integrasi database yang
konsisten, subject-oriented, data historikal.
|
|
2.1.5.5 Komponen Data Warehouse
Komponen data warehouse terdiri atas:
1.
Operational Data Source
Sumber data untuk data warehouse didapat dari main frame
operasional data, data tiap departemen, data pribadi, dan dari
sistem eksternal seperti internet.
2.
Operational Data Store
Merupakan
tempat
menyimpan
current
data dan
data
operasional dan terintegrasi untuk dianalisa.
3.
Load Manager (Frontend Component)
Melakukan semua operasi yang berhubungan dengan
pengekstrakan dan pemuatan data ke data warehouse.
4.
Warehouse Manager
Warehouse manager berupa:
•
Melakukan analisa data untuk menjaga konsistensi data.
•
Melakukan transformasi dan penggabungan sumber data
dari
penyimpanan
sementara
ke
dalam tabel-tabel
data
warehouse
•
Menciptakan index dan view pada base tables
•
Melakukan denormalisasai (jika diperlukan)
•
Melakukan agregasi (jika diperlukan)
•
Melakukan back-up dan archive / back-up data
|
|
5.
Query Manager
Query manager melakukan semua operasi yang
berhubungan
dengan
management user
queries.
Kemampuan
ini
dibangun dengan menggunakan vendor end-user data access tools,
data warehouse monitoring tools, falisilitas basis data, dan custom
build-in program. Kompleksitas queries manager ditentukan oleh
fasilitas yang disediakan oleh end-user access tools dan basis data.
Operasi
yang
dilakukan
komponen
ini
berupa
pengarahan query
pada tabel-tabel yang tepat dan penjadwalan eksekusi query.
6.
Detailed Data
Komponen
ini menyimpan semua data detil dalam skema
basis
data.
Pada
umumnya
beberapa
data
tidak
disimpan
secara
fisik tetapi dapat dilakukan dengan cara agregasi. Secara periodik
data
detil
ditambahkan
ke data
warehouse
untuk
mendukung
agregasi data.
7.
Lightly and Highly Summarized Data
Komponen ini menyimpan semua data yang diringkas oleh
warehouse manager.
Data
perlu
diringkas
dengan
tujuan
untuk
mempercepat
performa query. Rangkuman data turut diperlukan
seiring dengan adanya data yang baru yang masuk ke dalam data
warehouse.
|
|
8.
Archive / Back-up Data
Komponen
ini
menyimpan
data detil
dan
ringkasan
data
dengan
tujuan
untuk
menyimpan
dan
back-up data.
Walaupun
ringkasan yang
diperoleh
dari
data
mendetil,
ringkasan perlu
di
back-up
juga
apabila
data
tersebut disimpan
melampaui
periode
penyimpanan
data
detil.
Data kemudian
digunakan
ke
media
penyimpanan seperti magnetic tape atau optical disc.
9.
Metadata
Komponen
ini
menyimpan
semua
definisi metadata
(informasi
mengenai
data)
yang
digunakan
dalam
proses
dalam
data
warehouse.
Metadata
digunakan
untuk
berbagai
tujuan,
antara lain:
•
Proses
extracting
dan
loading,
metadata
digunakan
untuk
menentukan sumber data dalam warehouse.
•
Proses
manajemen
warehouse,
metadata
digunakan
untuk
menghasilkan tabel ringkasan.
•
Sebagai bagian dari proses manajemen query, metadata
digunakan untuk mengarahkan sebuah query pada sumber
data yang tepat.
10.
End-user Access Tools
Tujuan utama
dari
data warehouse
adalah menyediakan
informasi bagi pengguna untuk pembuatan keputusan yang
strategis dalam berbisnis. Para pengguna berinteraksi dengan data
|
|
warehouse menggunakan end-user access tools. Berdasarkan
kegunaan data warehouse, terdapat
lima kategori end-user access
tools, yaitu:
•
Reporting and Query Tools
Reporting tools meliputi production reporting tools dan
report writers.
Production reporting tools digunakan untuk
menghasilkan
laporan operasional secara berkala.
Query
Tools
untuk relasional data warehouse
dirancang
untuk menerima SQL, dan proses query data yang
tersimpan di warehouse.
•
Application Development Tools
Application Development
Tools
menggunakan
graphical
data access tools yang dirancang khusus untuk
lingkungan
client-server. Beberapa aplikasi tersebut diintegrasikan
dengan OLAP tools, dan dapat mengakses semua sistem
basis data utama.
•
Executive Information System (EIS) Tools
EIS sering dikenal sebagai “everyone’s information system”
(sistem informasi
setiap
orang).
Awalnya
dikembangkan
untuk
mendukung
pembuatan
kebutuhan top-level
yang
strategis.
Akan tetapi, kemudian
meluas
untuk mendukung
semua tingkat
manajemen. EIS tools pada awalnya
|
|
berhubungan dengan mainframes yang memungkinkan para
pengguna untuk membangun aplikasi pendukung keputusan
yang bersifat grafik untuk menyediakan sebuah
overview
mengenai data perusahaan dan akses pada sumber data
eksternal. Kini, EIS banyak
dilengkapi dengan fasilitas
query dan menyediakan custom-build applications untuk
area bisnis seperti penjualan, pemasaran dan keuangan.
•
Online Analytical Processing (OLAP) Tools
OLAP
tools didasarkan
pada
konsep
basis
data
yang
bersifat multi-dimensional dan memperbolehkan pengguna
untuk menganalisis data dari sudut pandang yang kompleks
dan multi-dimensi. Alat Bantu ini mengasumsikan bahwa
data
diatur dengan
model
multi-dimensi
yang
khusus
(MDDB) atau oleh sebuah relational basis data yang
dirancang untuk memungkinkan query multi dimensi.
•
Data Mining Tools
Data mining adalah proses menemukan korelasi, pola dan
tren yang baru, yaitu dengan melakukan penggalian
sejumlah data menggunakan teknik statistik, matematis,
dan artificial intelligent (AI). Data mining memiliki potensi
untuk menggatikan kemampuan OLAP tools.
|
|
2.1.5.6 OLTP (Online Transaction Processing)
Menurut
Connoly dan Begg (2005, p1153), Online Transaction
Processing (OLTP) is the systems that have been designed to handle high
transaction throughput, with transactions typically making small changes
to the organization’s operational data, that is, data that the organization
requires to handle its day-to-day operations ”, yang berarti OLTP adalah
suatu
sistem
yang
telah
dirancang
untuk
menangani
jumlah
hasil
transaksi yang tinggi, dengan transaksi yang pada umumnya membuat
perubahan yang kecil bagi data operasional organisasi. Oleh karena itu,
data organisasi memerlukan penanganan operasinya setiap hari.
Data pada database operasional bersifat volatile, dirancang untuk
membuat perubahan baru dan termutakhir terhadap data didalamnya,
menjaga integrasi data dan melaksanakan transaksi data secepat mungkin.
Pemakai dapat melihat informasi,
mungkin memanipulasi informasi
tersebut pada layar komputer, tetapi pemakai tidak dapat merubah isi data
dari data
yang ada pada database analisis. Sedangkan database analisis
dirancang untuk sejumlah besar data yang bersifat read only serta
menyediakan informasi yang digunakan untuk membuat keputusan. Pada
pemerosesan
database analisis, tidak terdapat pemerosesan data secara
satuan record setiap
kali
terjadi
perubahan
isi record. Perubahan pada
database analisis dilakukan sesuai jadwal yang sudah ditentukan. Karena
organisasi menggunakan banyak aplikasi piranti lunak dan banyak
database,
maka
data
warehouse
digunakan
untuk
mengumpulkan
dan
|
 mengatur data yang diperoleh dari aplikasi-aplikasi bertahun-tahun dalam
suatu tempat.
2.1.5.6.1 Perbandingan antara OLTP dan Data Warehouse
Tabel 2.2 Perbandingan antara OLTP dengan Data Warehouse
(Connoly dan Begg, 2005, p1153)
3.
TABEL
OLTP
DATA WAREHOUSE
Tujuan
Menjalankan operasi
sehari-hari
Mengambil dan menganalisa
informasi
Management database
RDBMS
RDBMS
Metode Pemodelan Data
Normalisasi
Skema Bintang
Akses
SQL
SQL ditambah dengan
kemampuan analisa data
Kegunaan data
Digunakan untuk
menjalankan kegiatan
bisnis harian
Digunakan untuk
menganalisa dan menyiasati
strategi bisnis
2.1.5.7 OLAP (Online Analytical Processing)
Menurut Connoly dan Begg (2005,p1205),
OLAP
adalah
sintesis
dinamis, analisis dan konsolidasi dari sekumpulan besar data
multidimensi. OLAP merupakan proses departmental untuk lingkungan
data mart. OLAP mendeskripsikan sebuah teknologi yang menggunakan
view multi-dimensi dari sekumpulan data untuk menyediakan akses yang
|
 cepat ke informasi strategis untuk analisis lebih lanjut. Aplikasi OLAP
tergantung dengan
data warehouse
dan
system OLTP
untuk merefresh
source level data.
OLAP adalah teknologi yang memperbolehkan para user
untuk
menganalisa
basis
data
yang
besar
untuk
mendapatkan
sistem informasi
yang
lebih
spesifik.
Basis
data
untuk
sistem
OLAP disusun
terstruktur
agar
lebih
efisien
dalam penyimpanan
data
statis.
Karena
penyimpanan
OLAP adalah
multidimensi, biasa disebut cube, yang berlawanan dengan
tabel.
Yang
membuat
OLAP
unik adalah kemampuannya untuk
menyimpan kumpulan data
secara
hirarki. Dimensi-dimensi memberikan
informasi secara kontekstual dalam bentuk bilangan atau perhitungan yang
lebih teliti.
2.1.5.6.1 Perbandingan OLAP dan OLTP
Tabel 2.3 Perbandingan OLAP dan OLTP
(Connoly dan Begg , 2005,p1153 )
OLAP
OLTP
Digunakan untuk mendukung kegiatan
analisis
Digunakan untuk mendukung kegiatan
transaksi sehari-hari
Menggunakan view multi dimensi
Menggunakan view single
Mendukung keputusan untuk masa
depan
Mendukung keputusan per hari
Bergantung pada data yang tesimpan
pada OLTP
Tidak bergantung pada OLAP
|
 Melayani manajerial user
Melayani operasional user
Operasi query-nya lebih rumit, adhoc
dan tidak melibatkan operasi data
update
Operasi query-nya sederhana dan
berulang-ulang
Memakai data yang terangkum dalam
data cube
Memakai data sehari-hari
2.1.5.6.2 Perbandingan OLAP dan Data Warehouse
Tabel 2.4 Perbandingan OLAP dan Data Warehouse
(Connoly dan Begg,2005,p1049)
OLAP
DATA WAREHOUSE
Merupakan end-user access tools dari data
sederhana
Merupakan basis data untuk menyimpan
data syarat dan menyediakan data cube
yang akan digunakan untuk OLAP
Mendukung manajerial user dan analytical
user
Mendukung manajerial user
Bergantung pada data yang tersimpan pada
data warehouse
Tidak bergantung pada OLAP dalam
penyediaan datanya
Menggunakan teknologi data warehouse
dalam penggunaannya
Menyediakan teknologi yang digunakan
untuk melakukan OLAP
|
|
2.1.6. Metodologi Perancangan Data Warehouse
Menurut Connolly dan Begg (2005,p1187-1193), metodologi yang
dikemukakan
oleh
Kimball
dalam membangun data
warehouse
ada
9
tahapan,
yang dikenal dengan Nine-step Methodology. Sembilan tahap tersebut adalah :
1.
Memilih Proses ( choosing the process )
Proses (fungsi) merujuk pada subjek masalah dari data mart tertentu.
Datamart yang akan dibangun harus sesuai anggaran dan dapat menjawab
masalah-masalah yang penting.
2.
Memilih Grain ( choosing the grain )
Memilih grain berarti menentukan hal yang sebenarnya dihadirkan
oleh
tabel
fakta.
Setelah
menentukan grain-grain
tabel
fakta,
dimensi-
dimensi untuk setiap fakta dapat diidentifikasi.
3.
Mengidentifikasi dan Membuat Dimensi yang Sesuai ( Identifying and
Comforming the Dimentions )
Mengidentifikasi dimensi disertai
deskripsi detail yang secukupnya.
Ketika
table
dimensi
berada
pada
dua
atau
lebih data
mart
maka
tabel
dimensi tersebut harus mempunyai dimensi yang sama atau salah satu
merupakan subset dari yang lainnya. Jika suatu tabel dimensi digunakan
oleh lebih dari satu data mart, maka dimensinya harus disesuaikan.
4.
Memilih Fakta ( Choosing the Facts )
Memilih fakta yang akan digunakan dalam data mart.
Semua
fakta
harus ditampilkan pada tingkat yang diterapkan oleh grain dan fakta juga
harus numerik dan aditif.
|
|
5.
Menyimpan pre- kalkulasi salam tabel Fakta ( Storing pre-calculation in
the Fact Table )
Ketika
fakta
telah
dipilih,
maka
setiap fakta tersebut harus diuji
apakah
ada
fakta
yang
dapat
menggunakan pre-kalkulasi, setelah itu
lakukan penyimpanan pada tabel fakta.
6.
Melengkapi Tabel Dimensi ( Rounding Out the Dimension Table )
Menambahkan sebanyak mungkin deskripsi teks pada tabel dimensi.
Deskripsi tersebut harus intuitif dan dapat dimengerti oleh user.
7.
Memilih Durasi Dari Database ( Choosing the Duration of the Database )
Menentukan batas waktu dari umur data yang diambil dan akan
dipindahkan
ke
dalam tabel
fakta. Misalnya,
data
perusahaan
dua
tahun
lalu atau lebih diambil dan dimasukkan ke dalam tabel fakta.
8.
Melacak Perubahan Dari Dimensi Secara Perlahan ( Tracking Slowly
Changing Dimensions )
Perubahan dimensi yang lambat menjadi sebuah masalah ada tiga tipe
dasar dari perubahan dimensi yang lambat, yakni :
a.
Perubahan atribut dimensi yang ditulis ulang (overwrite).
b.
Perubahan atribut dimensi yang mengakibatkan pembuatan suatu
record dimensi baru.
c.
Perubahan atribut dimensi yang mengakibatkan sebuah atribut
alternative dibuat, sehingga kedua atribut tersebut yakni atribut
yang lama dan yang baru dapat diakses secara bersamaan dalam
sebuah dimensi yang sama.
|
|
9.
Memutuskan Prioritas dan cara Query ( Deciding the Query Priorities and
the Query Modes)
Mempertimbangkan pengaruh dari perancangan fisikal yang akan
mempengaruhi persepsi user terhadap
datamart.
Selain
itu,
perancangan
fisikal
ini
akan
mempengaruhi
masalah
administrasi, backup,
kinerja
pengideksan dan keamanan.
2.1.7. Konsep Pemodelan Data Warehouse
Menurut Connoly dan Begg (2005, p1187), merancang
data warehouse
merupakan suatu pekerjaan yang sangat kompleks. Untuk
memulai sesuatu
proyek
data warehouse mula-mula perlu dilakukan pengumpulan analisis
kebutuhan pengguna, yang bisa dilakukan dengan cara melakukan wawancara
terhadap anggota yang sesuai, contohnya pengguna dibidang pemasaran,
keuangan, penjualan, operasional, dan manajemen untuk mengidentifikasi satu set
kebutuhan yang terprioritaskan bagi perusahaan yang harus dipenuhi oleh data
warehouse. Hasil wawancara menyediakan informasi yang penting bagi top-down
view
(kebutuhan pengguna ) dan bottom-up view
(dimana sumber data tersedia)
dari
data warehouse.
Dengan
dua
pandangan
diatas
proses
merancang data
warehouse sudah dapat dimulai.
Salah
satu
komponen
basis
data
dalam data
warehouse
dideskripsikan
dengan
menggunakan
permodelan
dimensionalitas (dimensionality
modelling),
yaitu suatu teknik desain secara logis yang bertujuan untuk menyajikan data
dalam suatu
bentuk
standar
dan
intuitif
yang
memungkinkan
akses
dengan
performansi tinggi. Konsep permodelan dimensionalitas menggunakan konsep
|
|
dari permodelan
entity-relationship (ER) dengan
beberapa
pembatasan penting.
Setiap model dimensionalitas terdiri dari satu tabel dengan satu composite
primary key (PK) yang dikenal sebagai tabel fakta (fact tabel), serta satu lagi tabel
yang lebih kecil yang dikenal sebagai tabel dimensi (dimension tabel).
Setiap
tabel
dimensi
memiliki
satu primary key
yang
berkorespondensi
dengan satu komponen dari composite key dalam tabel fakta. Dengan kata lain,
primary key dari tabel
fakta terdiri dari dua atau lebih foreign key. Karakteristik
yang
memiliki bentuk
seperti bintang
ini dikenal sebagai star schema atau star
join atau skema bintang.
2.1.7.1 Skema Bintang (Star Schema)
Menurut Connolly (2005, p1183), skema
bintang
adalah
struktur
logikal
yang
mempunyai
sebuah
tabel fakta
yang
berisi
data
fakta
di
tengah dan dikelilingi oleh tabel-tabel dimensi yang berisi data referensi
atau keterangan yang biasanya dapat denormalisasi.
|
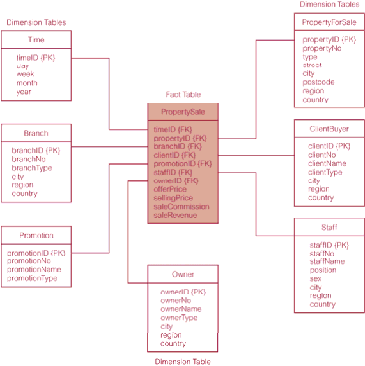 Gambar 2.10 Star Schema
(Sumber : Connolly, 2005, p1184)
2.1.7.1.1 Tabel Facta (Fact Table)
Menurut Connolly dan Begg (2005, p1183), “Every
dimensional model (DM) is composed of one table with a
composite primary key, called the fact table”, yang berarti tabel
fakta
adalah
suatu
tabel
pada
Dimensional Model
(DM)
yang
isinya
composite
primary
key (PK).
Jadi
PK
pada
tabel
fakta
merupakan beberapa foreign key.
2.1.7.1.2 Tabel Dimensi (Dimenstion Table)
Menurut Connolly dan Begg (2005, p1183), “Dimensional
table is a set of smaller tables called dimension tables”,
yang
berarti tabel dimensi adalah sekumpulan tabel-tabel yang lebih
|
|
kecil
dari
tabel
fakta
pada
dimensional
model
(DM).
Setiap
tabel dimensi mempunyai non-composite Primary Key.
2.1.7.1.3 Surrogate key
Menurut
http 1, A surrogate key is an artificially produced
value, most often a system-managed, incrementing counter
whose
values
can
range
from
1
to
n,
where
n
represents
a
table's
maximum number
of
rows.
In
SQL
Server,
create
a
surrogate
key
by
assigning
an
identity
property
to
a
column
that
has
a
number
data
type.
A
natural
key is
a naturally
occurring descriptor of the data and one of a table's attributes
that has no duplicate values. When use a natural key as a table's
primary key, each of the table's rows is uniquely identified.
Artinya, sebuah nilai yang dihasilkan secara buatan, sistem
yang paling sering dikelola, penambahan nilai-nilai yang dapat
berkisar dari 1 hingga n, dimana n merupakan jumlah angka
maksimum dari baris yang ada pada tabel. Dalam SQL Server,
membuat surrogate key dengan menetapkan identitas pada
kolom
yang memiliki
sejumlah
tipe
data.
Kunci
yang
secara
alami
menjadi
deskripsi
dari data dan
salah
satu
atribut dari
tabel tidak bernilai ganda. Ketika
menggunakan kunci tersebut
sebagai sebuah primary key dari tabel, masing-masing baris
pada tabel secara unik teridentifikasi.
|
|
2.1.7.2 Keuntungan Skema Bintang
Skema
bintang
memiliki
keuntungan yang
tidak didapat
oleh
skema
relasional biasa. Keuntungan skema bintang, antara lain:
•
Respon data yang lebih cepat dihasilkan dari perancangan
database.
•
Kemudahan dalam
mengembangkan atau
memodifikasi data
yang
terus berubah.
•
End user dapat menyesuaikan cara berpikir dan menggunakan
data, konsep ini dikenal juga dengan istilah pararel dalam
perancangan database.
•
Menyederhanakan pemahaman dan penelusuran metadata bagi
pemakai dan pengembang.
2.1.8
Arsitektur Data Warehouse
2.1.8.1 Centralized Data Warehouse
Centralized data warehouse ini
merupakan database fisikal
tunggal
yang memuat semua data untuk area fungsional yang khusus, departemen,
divisi,
atau
perusahaan.
Data warehouse ini
digunakan
ketika
terdapat
kebutuhan
akan
data informasional
dan
terdapat
banyak
end-user
yang
sudah terhubung ke komputer pusat atau jaringan.
Bentuknya
menyerupai functional
data
warehouse,
akan tetapi
sumber datanya
lebih dahulu dikumpulkan atau diintegrasikan pada suatu
tempat
terpusat, baru
kemudian
data tersebut
dibagi
berdasarkan
fungsi-
fungsi yang dibutuhkan oleh perusahaan. Bentuk data warehouse terpusat
|
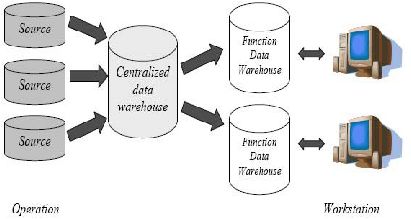 ini sering digunakan oleh perusahaan-perusahaan yang belum mempunyai
jaringan eksternal.
Keuntungan bentuk centralized data warehouse ini adalah data
benar-benar
terpadu
karena
konsistensi
yang
tinggi. Namun
demikian
membutuhkan waktu yang lama dan biaya yang mahal dalam membentuk
data warehouse seperti ini.
Gambar 2.11 Centralized Data Warehouse
2.1.9 ETL (Extract,Transform,Loading)
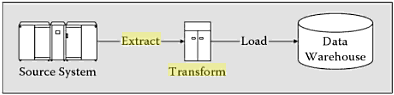
Menurut Silvers(2008,p150) ETL (Extract, Transform, Load) adalah
proses-proses dalam data warehouse yang meliputi:
•
Mengekstrak data dari sumber-sumber eksternal.
•
Mentransformasikan data ke bentuk yang sesuai dengan keperluan bisnis.
•
Memasukkan data ke target akhir, yaitu data warehouse.
ETL
merupakan
proses
yang
sangat penting,
dengan
ETL
data
dapat
dimasukkan
ke
dalam data
warehouse.
ETL
juga
dapat
digunakan
untuk
mengintegrasikan data dengan sistem yang sudah ada sebelumnya.
|
|
Tujuan ETL adalah mengumpulkan, menyaring, mengolah, dan
menggabungkan data yang relevan dari berbagai sumber untuk disimpan ke dalam
data warehouse. Hasil dari proses ETL adalah dihasilkannya data yang memenuhi
kriteria data warehouse seperti data historis, terpadu, terangkum, statis, dan
memiliki struktur yang dirancang untuk keperluan proses analisis.
¾
Extract
Langkah
pertama
pada
proses
ETL adalah
mengekstrak
data dari
sumber-sumber data. Kebanyakan proyek data warehouse
menggabungkan data dari sumber-sumber yang berbeda. Pada hakekatnya,
proses ekstraksi adalah proses penguraian, pembersihan dari data yang
diekstrak untuk mendapatkan struktur atau pola data yang diharapkan.
¾
Transform
Tahapan transfomasi
menggunakan serangkaian aturan atau fungsi
untuk mengekstrak data dari sumber dan selanjutnya akan dimasukkan ke
dalam data warehouse. Berikut adalah hal- hal yang dapat dilakukan
dalam tahap transformasi :
o
Hanya
memilih
kolom
tertentu
saja
untuk
dimasukkan
ke dalam
data warehouse.
o
Menterjemahkan
nilai-nilai
yang berupa kode
(contohnya
apabila
database sumber menyimpan nilai 1
untuk laki-
laki dan
nilai 2
untuk
perempuan, tetapi data
warehouse
yang telah
ada
menyimpan M untuk laki-laki dan F untuk perempuan, ini disebut
|
 dengan
automated
data cleansing,
tidak ada pembersihan secara
manual yang ditunjukkan selama proses ETL.
o
Mengkodekan nilai-nilai ke dalam bentuk bebas (contohnya
memetakan “Male”, “1” dan “Mr” ke dalam M).
o
Melakukan perhitungan nilai-nilai baru (contohnya sale_amount =
qty * unit_price).
o
Menggabungkan data secara bersama-sama dari berbagai sumber.
o
Membuat
ringkasan
dari
sekumpulan baris
data
(contohnya total
penjualan untuk setiap toko atau setiap bagian).
¾
Loading
Fase load merupakan tahapan yang berfungsi untuk memasukkan
data ke dalam target akhir, yang biasanya ke dalam suatu data warehouse.
Jangka waktu proses ini tergantung pada kebutuhan organisasi.
Beberapa
data warehouse dapat setiap minggu menulis keseluruhan informasi yang
ada secara kumulatif, data diubah, sementara
data
warehouse
yang
lain
(atau
bagian
lain
dari
data
warehouse
yang
sama)
dapat
menambahkan
data baru dalam suatu bentuk historikal, contohnya setiap jam. Waktu dan
jangkauan untuk mengganti atau menambah data tergantung dari
perancangan data
warehouse
pada
waktu
menganalisis
keperluan
informasi.
|
|
Gambar 2.12 Extract, Transform, Load (ETL)
(Sumber : Silvers, 2008, p152)
2.1.10 Metadata
Menurut
Paulraj
Ponniah(2001,p36),
metadata
dalam
sebuah
datawarehouse di bagi ke dalam
3 kategori utama :
•
Operational Metadata
Data
untuk data warehouse berasal dari beberapa sistem operasional
dari
perusahaan.
Sumber
sistem ini
mengandung
struktur
data
yang
berbeda. Elemen data yang dipilih untuk data warehouse
mempunyai
bermacam-macam field lengths
dan
tipe
data.
Dalam memilih
data dari
sumber
sistem untuk
data
warehouse,
record
harus
dipisahkan,
menggabungkan bagian-bagian records dari sumber file yang berbeda dan
membuat kesepakatan dengan skema
pengkodingan
ganda
dan field
lengths. Ketika informasi dikirim kepada end user, harus dapat
menghubungkan kembali ke kumpulan sumber data yang asli. Operasional
metadata mengandung semua informasi mengenai operasional sumber
data.
•
Extraction and Transformation Metadata
Extraction dan Transformation Metadata mengandung data mengenai
ekstraksi data dari sumber sistem, yakni ekstraksi frekuensi, ekstraksi
metode dan aturan-aturan bisnis
untuk ekstraksi data. Juga, kategori dari
metadata ini mengandung informasi tentang semua transformasi data yang
mengambil tempat dalam data staging area.
|
|
•
End-User Metadata
End-User
Metadata
merupakan
peta
navigasi
dari
data
warehouse.
Hal ini memungkinkan end-user
untuk menemukan informasi dari data
warehouse. End-user
metadata mengijinkan end-user untuk
menggunakan terminologi bisnis milik mereka sendiri dan mencari
informasi dalam cara itu dimana mereka secara normal berpikir mengenai
bisnis.
2.1.11 Fact Finding
Menurut Connolly dan Begg (2005, p317- 321), fact finding adalah proses
formal yang menggunakan teknik-teknik seperti wawancara dan kuesioner untuk
mengumpulkan fakta-fakta mengenai sistem, persyaratan dan preferensi. Metode yang
digunakan fact finding adalah :
1.
Wawancara
Wawancara adalah yang paling sering digunakan, dan biasanya
paling berguna, teknik pencarian fakta.
Kita
dapat
wawancara
untuk
mengumpulkan informasi dari individu melalui tatap muka. Ada beberapa
tujuan dapat menggunakan wawancara, seperti mencari tahu fakta,
memverifikasi fakta, mengklarifikasi fakta, menghasilkan antusiasme,
mendapatkan pengguna akhir yang terlibat, mengidentifikasi kebutuhan,
dan mengumpulkan ide -
ide dan pendapat. Akan tetapi, dengan
menggunakan teknik wawancara membutuhkan keterampilan komunikasi
yang baik untuk berurusan secara efektif dengan orang -
orang yang
memiliki
nilai
yang berbeda, prioritas, opini,
motivasi, dan kepribadian.
|
|
seperti fakta lain teknik wawancara tidak selalu merupakan metode terbaik
untuk semua situasi.
Terdapat
dua
macam
tipe interview:
tidak terstruktur dan
terstruktur.
Wawancara tidak
terstruktur
dilakukan
hanya
dengan
tujuan
umum dalam pikiran dan dengan sedikit, jika ada, pertanyaan - pertanyaan
spesifik. Pewawancara menghitung pada orang yang diwawancara untuk
menyediakan kerangka kerja dan arah untuk wawancara. Wawancara jenis
ini sering kehilangan
fokus, karena alasan ini, sering kali tidak berfungsi
dengan baik untuk analisis dan desain database.
Wawancara terstruktur, pewawancara memiliki serangkaian
pertanyaan khusus untuk meminta diwawancarai. tergantung pada respon
orang yang diwawancara, pewawancara akan langsung menambah
pertanyaan-pertanyaan untuk mendapatkan klarifikasi atau ekspansi.
Untuk
memastikan
kesuksesan wawancara
meliputi memilih
individu yang sesuai untuk wawancara, mempersiapkan secara ekstensif
untuk wawancara, dan melakukan wawancara yang efisien dan efektif.
|
 Tabel 2.5 Keuntungan dan Kelemahan Menggunakan Wawancara sebagai Teknik Fact
Finding (Connolly dan Begg, 2005, p318)
2.
Mengamati perusahaan beroperasi
Pengamatan adalah salah satu yang paling efektif teknik pencarian
fakta untuk memahami
sebuah sistem. Dengan teknik ini, mungkin baik
untuk berpartisipasi , atau menonton, orang yang melakukan kegiatan
untuk belajar tentang sistem. Teknik ini terutama bermanfaat bila validitas
data yang dikumpulkan melalui metode lain yang terkait atau ketika
kompleksitas aspek-aspek
tertentu dari sistem mencegah penjelasan
yang
jelas oleh pengguna akhir, seperti dengan fakta lain teknik, pengamatan
yang sukses membutuhkan persiapan. Untuk memastikan bahwa
pengamatan berhasil, sangat penting untuk mengetahui sebanyak mungkin
tentang individu dan kegiatan yang harus diperhatikan mungkin.
|
 Tabel 2.6 Keuntungan dan Kelemahan Menggunakan Observasi sebagai Teknik Fact
Finding
(Sumber : Connolly, 2005, p319)
2.2. Teori-teori khusus
2.2.1. Sistem Penjualan
Menurut Anita S. Hollander et al. (2000, p230), penjualan adalah kumpulan
kejadian yang secara kolektif melayani untuk menarik pelanggan, membantu
pelanggan
untuk
memilih
barang
dan
layanan,
mengantar
barang
dan
layanan
yang diminta, dan mengumpulkan pembayaran untuk barang dan layanan.
2.2.2. Sistem Pembelian
Menurut
Mulyadi
(2001,
p301),
sistem pembelian
digunakan
dalam
perusahaan untuk pengadaan barang yang diperlukan oleh perusahaan. Fungsi
pembelian pada sistem pembelian bertanggung jawab untuk memperoleh
informasi mengenai harga barang, menentukan pemasok yang dipilih dalam
pengadaan barang, dan
mengeluarkan
order
pembelian
kepada
pemasok
yang
dipilih.
|
|
2.2.3. Sistem Pemasaran
Menurut Hendro, & Widhianto, C.W. (2006, p419), Pemasaran adalah
proses kegiatan dalam perusahaan dan
manajerial dimana
individu, kelompok atau
perusahaan mendapatkan apa yang mereka butuhkan atau harapkan melalui
penciptaan,
penawaran
dan
pertukaran
segala
sesuatu
yang
bernilai
dengan
orang
lain atau kelompok yang lain.
|