|
Bab 2
Landasan Teori
2.1
Data, Database, dan DBMS (Database Management System)
2.1.1
Pengertian Data
Menurut Prescott (2005, p5), data adalah sebuah fakta mengenai
objek yang dapat disimpan dalam media komputer. Data memiliki banyak
bentuk, salah satu contoh data adalah nama, alamat, dan nomor telepon
dari pelanggan.
Dalam perkembangan
selanjutnya,
data akan diolah menjadi
bentuk yang lebih kompleks yang disebut dengan informasi. Informasi
adalah
data
yang
sudah
diproses
dengan cara
tertentu
untuk
meningkatkan pengetahuan dari orang
yang menggunakannya (Prescott,
2005, p5).
Informasi dapat digunakan untuk membantu dalam
meningkatkan
pengetahuan yang dimiliki oleh perusahaan. Oleh karena itu penting bagi
perusahaan untuk selalu memperbaharui informasi yang dimilikinya.
2.1.2
Pengertian Database dan DBMS
Istilah
Database atau "basis data" berawal
dari
ilmu computer.
Catatan
yang
mirip
dengan
basis
data sebenarnya sudah ada sebelum
revolusi
industri yaitu dalam bentuk buku besar, kuitansi dan kumpulan
data yang
berhubungan
dengan bisnis.
Istilah
basis
data
mengacu
pada
7
|
|
8
koleksi dari data-data yang saling berhubungan, dan perangkat lunaknya
seharusnya mengacu sebagai sistem manajemen basis data (database
management system/DBMS).
Menurut
Connoly
dan
Begg
(2002,
p16),
DBMS adalah sebuah piranti lunak, yang memungkinkan pengguna
untuk mendefinisikan, membuat,
mengelola dan mengontrol akses
terhadap sebuah database.
Jika
konteksnya
sudah jelas, banyak administrator dan
programmer
menggunakan
istilah
basis
data untuk kedua arti tersebut.
Berikut ini pengertian database menurut para ahli :
-
Connolly
(2002,p14-p15),
database
adalah
kumpulan
data
yang
berelasi secara logikal dan sebuah deskripsi dari data tersebut
yang di desain untuk memenuhi kebutuhan organisasi. Database
adalah sebuah tempat penyimpanan besar dari data yang dapat
digunakan secara terus menerus oleh banyak departemen dan user.
-
Syahrial
(2006, p45), Database
adalah
sekumpulan
obyek
seperti
tabel, view, indeks, trigger, prosedur, dan obyek-obyek
lain
yang
disimpan dalam database file
dengan nama
perluasan MDF
dan
LDF.
-
O’Brien (2005,p141), database adalah kumpulan elemen data
terintegrasi yang berhubungan secara logikal.
-
Turban et al (2005,p446), database adalah kumpulan dari file-file
yang menyimpan data yang saling berelasi dan berasosiasi satu
dengan
yang
lainnya. Dimana
letak data tersebut disimpan dapat
|
|
9
mempengaruhi kecepatan
user untuk
mengakses, query response
times, data entry, security, dan biaya.
Berdasarkan definisi
diatas,
dapat
disimpulkan
bahwa database
adalah
tempat
penyimpanan
dari
data.
Dan
database sendiri
adalah
kumpulan dari elemen, relasi atau file-file yang saling terintegrasi untuk
digunakan bersama dan dapat digunakan untuk memperoleh informasi
yang dibutuhkan oleh perusahaan.
2.1.3
Komponen DMBS
Sebagai sebuah sistem, DBMS juga memiliki komponen yang
saling berinteraksi satu sama lain. Menurut Connoly dan Begg (2002,
pp18-20), ada beberapa komponen utama yang harus dimiliki oleh sebuah
DBMS yaitu :
1.
Perangkat Keras (Hardware)
2.
Piranti Lunak (Software)
3.
Data
4.
Prosedur
5.
Orang (pengguna)
2.1.4
Kelebihan DBMS
Menurut Connoly dan Begg (2002, pp26-29), ada beberapa
kelebihan yang dimiliki oleh DBMS dibandingkan dengan sistem
|
|
10
pengelolaan data tradisional (menggunakan file). Beberapa kelebihan itu
antara lain :
1.
Berkurangnya redundansi.
Redudansi data merupakan kerangkapan data yang terjadi
dalam basis
data,
bukan pada tabel. Dengan
penggunaan DBMS,
terjadi pengurangan redundansi data, sehingga terjadi
penghematan dalam penggunaan piranti penyimpanan.
2.
Konsistensi data
Dengan menghilangkan redundansi, resiko data yang tidak
konsisten dapat dikurangi. Dengan penggunaan DBMS, suatu
data item hanya disimpan sekali dalam database, sehingga proses
update
terhadap
data
item
tersebut
juga
hanya
dilakukan
sekali
dan
nilai
baru
hasil
proses update
tersebut
juga
akan
langsung
tersedia bagi semua pengguna.
3.
Lebih banyak informasi
Dengan terintegrasinya data operasional, organisasi akan
mampu untuk memperoleh lebih banyak informasi dari sejumlah
data yang sama.
4.
Penyebaran data
Database dimiliki oleh seluruh bagian organisasi dan
dapat diakses oleh pengguna-pengguna yang diberikan otorisasi
untuk mengakses data tersebut. Dengan demikian, setiap
|
|
11
pengguna akan memiliki bagian yang lebih banyak dari data yang
ada.
5.
Meningkatnya integritas data
Dengan
adanya
integrasi
yang
dilakukan
oleh DBMS,
database
administrator dapat
memaksa
agar
dilakukan
validasi
terhadap batasan-batasan integritas data yang dihasilkan oleh
suatu proses pada sistem.
6.
Peningkatan keamanan
Dengan adanya integrasi data dalam database, database
administrator dapat memaksa dilaksanakannya batasan-batasan
keamanan tertentu terhadap penggunaan database oleh pengguna-
pengguna tertentu pula.
7.
Standarisasi
Sama seperti pada keamanan, adanya integrasi data juga
memungkinkan dilakukannya standarisasi data antara setiap
bagian dari organisasi.
8.
Penghematan biaya
Dengan mengkombinasikan seluruh data operasional
organisasi
ke
dalam satu
database
dan
membuat
sekumpulan
aplikasi
yang
dapat
mengolah
satu sumber
data
ini,
organisasi
dapat melakukan penghematan biaya.
|
|
12
9.
Meminimalisasi konflik antara pengguna
Setiap pengguna dalam suatu organisasi memiliki
kebutuhan
yang
mungkin
dapat mengakibatkan
konflik
dengan
pengguna
lain.
Karena database
berada
di
bawah
kontrol
database
administrator, database
administrator dapat
membuat
keputusan tentang bagaimana rancangan dan penggunaan
operasional
dari database, yang memungkinkan digunakannya
sumber daya sebaik mungkin bagi keseluruhan perusahaan.
10.
Meningkatkan aksesibilitas data dan mengurangi waktu respon
Dengan adanya DBMS, data-data
yang dimiliki oleh suatu
departemen dapat diakses secara langsung oleh pengguna pada
departemen lainnya. Hal ini akan mengakibatkan sistem memiliki
fungsionalitas-fungsionalitas tambahan yang dapat berguna bagi
perkembangan organisasi.
11.
Peningkatan produktivitas
Banyak
DBMS
yang
menyediakan tool-tool
yang
dapat
memudahkan proses pengembangan aplikasi database. Tool-tool
ini
dapat
meningkatkan
produktivitas programmer
dan
mengurangi waktu pengembangan aplikasi.
12.
Peningkatan konkurensi
Dengan
adanya
DBMS,
adalah
mungkin
bagi database
untuk diakses lebih dari satu pengguna pada waktu yang
bersamaan, tanpa saling menganggu.
|
|
13
13.
Peningkatan pelayanan backup dan recovery
Kebanyakan
DBMS modern
telah
menyertakan
fasilitas
untuk meminimalisasi proses yang hilang apabila terjadi
kesalahan
pada
sistem,
sehingga
mempermudah
dalam proses
recovery dan backup terhadap database.
2.1.5
Kekurangan DBMS
Selain
kelebihan
yang dimilikinya,
DBMS
juga
memiliki
beberapa kekurangan. Menurut
Connoly
dan
Begg
(2002,
pp29-30),
kekurangan dari DBMS antara lain :
1.
Kompleksitas
Perancang dan pengembang database, database dan data
administrator
dan pengguna harus mengerti fungsi-fungsi yang
terdapat
dalam
suatu
DBMS (yang biasanya cukup kompleks)
untuk dapat menggunakan DBMS tersebut dengan baik.
Ketidakmampuan
untuk
mengerti
sistem tersebut
dengan
baik
dapat
mengakibatkan dilakukannya perancangan
yang
buruk,
yang dapat mengakibatkan konsekuensi yang serius terhadap
perusahaan.
2. Ukuran
Kompleksitas dan banyaknya fungsionalitas dari sebuah
DBMS membuat DBMS menjadi sebuah piranti lunak yang
berukuran
besar,
yang
membutuhkan
ruang
penyimpanan
yang
|
|
14
cukup besar dan
membutuhkan
memori
yang
besar
untuk
dapat
bekerja.
3. Biaya
Dengan
digunakannya DBMS,
dibutuhkan
biaya
ekstra
untuk
membeli DBMS itu
sendiri
dan
melakukan
perawatan
terhadap DBMS tersebut.
4. Biaya tambahan untuk kebutuhan perangkat keras
Kebutuhan ruang penyimpanan dari DBMS dan database
mungkin
akan
mengakibatkan dibutuhkannya
perangkat
keras
tambahan. Selain itu, untuk mencapai kinerja yang baik, mungkin
organisasi harus membeli sebuah komputer yang lebih besar, atau
bahkan sebuah komputer yang khusus didedikasikan untuk
menjalankan DBMS tersebut.
5. Biaya konversi
Pada beberapa kasus biaya pembelian DBMS dan
perangkat keras tambahan dapat menjadi jauh lebih kecil
dibandingkan biaya untuk mengkonversi aplikasi yang sudah ada
agar dapat berjalan pada DBMS dan perangkat keras baru. Biaya
konversi ini juga termasuk biaya untuk melatih pegawai agar
dapat menggunakan sistem baru dan biaya untuk memperkerjakan
spesialis
untuk
membantu
dalam proses
konversi
dan
implementasi sistem baru.
|
|
15
6. Kinerja
Karena
DBMS
dibuat
sebagai
solusi
umum
untuk
lebih
dari satu masalah, ada beberapa aplikasi yang berjalan lebih
lambat dari biasanya.
7. Dampak kesalahan yang lebih besar
Karena seluruh kegiatan operasi perusahaan tergantung
pada keberadaan DBMS, adanya kesalahan pada komponen dari
DBMS dapat mengakibatkan terhentinya operasi perusahaan.
2.2
Data Warehouse
2.2.1
Pengertian Data Warehouse
Definisi dari data warehouse telah berevolusi sejak pertama kali
diperkenalkan pada awal tahun 1980. Menurut Connolly dan Begg
(2002,p1047), data warehouse adalah suatu kumpulan data yang bersifat
subject
oriented,
integrated,
time-variant, dan
non-volatile
dalam
mendukung
proses
pengambilan
keputusan. Data
warehouse
bertujuan
agar perusahaan
dapat
menggunakan
arsip
datanya
untuk
mendapatkan
keunggulan bisnis.
Sedangkan menurut Inmon (2002,p31),
data
warehouse
adalah
koleksi data
yang berorientasi subjek, terintegrasi, tidak mengalami
perubahan, dan berdasarkan variasi waktu untuk mendukung keputusan
manajemen.
Namun secara
singkat data warehouse dapat
diartikan
|
|
16
sebagai tempat penyimpanan dari data yang didapat dari sistem
perusahaan dan dapat diakses oleh user.
Data
warehouse
adalah database
yang
dirancang
khusus
untuk
mengerjakan
proses query, membuat laporan dan
analisa. Data yang
disimpan
adalah
data
business history
dari
sebuah
organisasi
atau
perusahaan, dimana data tersebut tidak tersimpan secara rinci atau detil.
Sehingga data dapat bertahan lebih lama berbeda dengan data OLTP
(Online Transactional Processing) yang tersimpan sampai prosesnya
berlangsung secara lengkap.
Sumber data
pada data
warehouse berasal dari berbagai macam
format, software, platform dan jaringan
yang beda. Data
tersebut adalah
hasil
dari proses transaksi perusahan atau organisasi sehari-hari. Karena
berasal dari sumber yang berbeda-beda tadi, maka data pada data
warehouse harus tersimpan dalam sebuah format yang baku.
2.2.2
Karakteristik Data Warehouse
Data
warehouse
juga
merupakan
salah
satu
sistem pendukung
keputusan, yaitu dengan menyimpan data dari berbagai sumber,
mengorganisasikannya dan dianalisa oleh para pengambil kebijakan.
Akan
tetapi data
warehouse
tidak
dapat
memberikan
keputusan
secara
langsung. Namun ia dapat memberikan informasi yang dapat membuat
user
menjadi
lebih
paham
dalam
membuat
kebijakan
strategis. Adapun
|
|
17
karakteristik data warehouse
menurut Imnon (2002,p31) adalah
sebagai
berikut:
1.
Subject oriented
Data warehouse dirancang melakukan analisis data
berdasarkan
subjek-subjek
tertentu
yang
ada
dalam organisasi,
tidak berorientasi kepada proses atau aplikasi fungsional tertentu.
2.
Integrated
Karakteristik
kedua
dan
terpenting
dari
data warehouse
adalah integrasi. Data diambil
dari
banyak
sumber
terpisah ke
dalam data
warehouse.
Data
yang
diambil
itu
akan
diubah,
diformat, disusun kembali, diringkas, dan seterusnya. Data yang
masuk
kedalam data
warehouse
dengan
berbagai
cara
dan
mempunyai
ketidak-konsistenan pada
tingkat aplikasi
tidak
akan
dimasukkan. Contoh konsistensi data antara lain adalah
penamaan, struktur
kunci,
ukuran
atribut, dan karakteristik data
secara spesifik. Hasilnya adalah data dalam data warehouse yang
memiliki satu bentuk.
3.
Non-volatile
Non-volatile dapat
diartikan
bahwa
data
tersebut
tidak
mengalami
perubahan.
Data dilingkungan
oprasional
dapat
dilakukan
perubahan
(update),
dihapus (delete), dan dimasukkan
data baru (insert) tetapi
data
dalam
data
warehouse
hanya
|
|
18
melakukan
loading
dan
accessing.
Dengan
ini
maka
data
yang
lama tetap tersimpan dalam data warehouse.
4.
Time-variant
Karakteristik ini mengimplikasikan bahwa tiap data dalam
data warehouse
itu selalu
akurat dalam periode
tertentu.
Dalam
satu
sisi,
sebuah
record
dalam
database
memiliki
waktu
yang
telah
ditetapkan
secara
langsung. Disisi
lain,
sebuah
record
mempunyai waktu transaksi.
Dalam setiap
lingkungan
baik
oprasional
maupun
data
warehouse
lingkungan tersebut
memiliki
time
horizon.
Time
horizon adalah sebuah parameter waktu yang dipertunjukkan
dalam lingkungan tersebut.
Batas
waktu
pada data warehouse lebih lama daripada
system operasional, karena perbedaan batas waktu tersebut, maka
data
warehouse
mempunyai
lebih
banyak
history daripada
lingkungan lainnya.
2.2.3
Tujuan Data Warehouse
Tujuan pembuatan data warehouse
sendiri sebenarnya beragam.
Namun secara umum data warehouse digunakan untuk menyediakan data
yang lebih mudah diakses oleh pada top level management sehingga
dapat
memberikan
sudut
pandang tersendiri.
Berdasarkan
pandangan
diatas maka kami merumuskan tujuan data warehouse sebagai berikut:
|
|
19
1.
Data warehouse menyediakan suatu pandangan (view) umum,
sehingga data warehouse akan memiliki keleluasaan untuk
mengakomodasi
bagaimana
data
akan ditafsirkan atau
dianalisis
selanjutnya.
2.
Data warehouse merupakan tempat penyimpanan seluruh data
historis. Data warehouse akan bertumbuh menjadi sangat besar
sehingga harus dirancang untuk mengakomodasi pertumbuhan
data.
3.
Data warehouse dirancang untuk menyediakan data bagi berbagai
teknologi analisis dalam komunitas bisnis.
Secara umum ada beberapa hal yang harus diperhatikan dalam
membuat sebuah rancangan datawarehouse. Beberapa pertanyaan umum
seperti
tipe
apa
yang
akan
dimodelkan?
Lalu apa dasar data
dan
level
atom data yang akan disajikan? Dimensi apa yang dipakai untuk masing-
masing record tabel fakta? Pertanyaan-pertanyaan tersebut nantinya akan
membantu dalam menyusun sebuah arsitektur data warehouse. Arsitektur
data warehouse
menyediakan perangkat dengan mengidentifikasi dan
memahami
data akan pindah melalui
sistem
dan
digunakan
dalam
perusahaan. Arsitektur data warehouse mempunyai komponen utama
yaitu database yang hanya dapat dibaca.
|
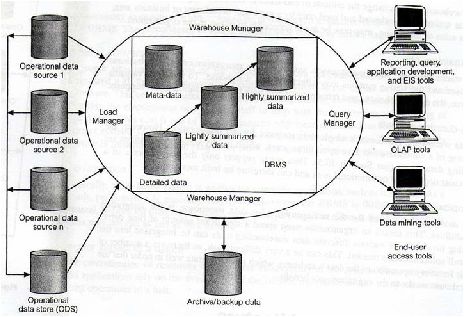 20
Gambar 2.1 Arsitektur Data Warehouse
Sumber : Connoly,2005, p1053
Berikut ini beberapa karakteristik arsitektur data warehouse :
1.
Data
diambil
dari
sistem
asal
atau
sistem
informasi
yang
ada,
database dan file.
2.
Data
dari
sistem
akan
diintegrasikan
dan
ditransformasikan
sebelum disimpan kedalam data warehouse.
3.
Datawahouse
adalah
jenis
database
read
only
yang
diciptakan
untuk mengambil keputusan
4.
User mengakses data warehouse via front – end atau aplikasi.
|
|
21
2.2.4
Komponen Data Warehouse
Untuk menjalankan fungsinya, data warehouse memerlukan data
operasional yang selanjutnya
akan
melalui
beberapa
tahapan
agar
data
tersebut layak dipakai. Berdasarkan
gambar 2.1, komponen
utama dalam
data warehouse menurut Connoly 2005, p1052, yaitu :
1.
Operasional Data
Data Operasional adalah data yang digunakan untuk
mendukung proses bisnis sehari – hari nya. Data operasional
masih berupa data mentah yang kotor. Disebut kotor karena
didalamnya masih ada data yang duplikat, atau tidak sesuai
dengan nilai data yang ditentukan.
2.
Operational Data Store
Operational Data Store adalah tempat penyimpanan data
operational yang bersifat current dan terintegrasi
yang digunakan
untuk
analisis.
Dengan
kata
lain, operational
data
store
mendukung
proses
transaksi
operational maupun proses analisis.
Dengan adanya operational data store, maka pembangunan data
warehouse
menjadi lebih mudah karena operational data store
dapat menyediakan data yang telah diekstrak dari
sumber dan
telah dibersihkan sehingga proses pengintegrasian dan
restrukturisasi data warehouse menjadi lebih sederhana.
|
|
22
3.
Load Manager
Load manager, disebut juga dengan komponen front –
end, melakukan semua operasi yang berhubungan dengan
ekstraksi
dan
load
data
kedalam data
warehouse.
Data
dapat
diekstrak langsung dari sumber data atau lebih biasa dari
operational data store.
Operasi yang dilakukan oleh load manager dapat meliputi
transformasi sederhana dari data untuk mempersiapkan data untuk
dimasukan ke
dalam data
warehouse.
Ukuran dan kompleksitas
dari
komponen
ini
akan bervariasi diantara data
warehouse
dan
dapat dibangun dengan menggunakan kombinasi dari tool
loading data dari vendor dan program yang custom built
4.
Warehouse manager
Warehouse
manager
melakukan semua operasi yang
berhubungan dengan manajemen dari data didalam data
warehouse komponen ini dibangun menggunakan alat manajemen
data vendor dan program custom built.
Operasi yang dilakukan oleh warehouse manager meliputi :
-
Analisis data untuk memastikan konsistensi data
-
Transformasi dan menggabungkan sumber data dari
tempat
penyimpanan
sementara
ke
dalam table
data
warehose
-
Pembuatan index dan view berdasarkan table dasar
|
|
23
-
Melakukan denormalisasi (jika diperlukan)
-
Melakukan agregasi (jika diperlukan)
-
Melakukan back up data
Dalam beberapa
kasus,
warehouse
manager
juga
menghasilkan
profile query untuk menentukan index dan agregasi manakah yang
sesuai.
Sebuah
profile query
dapat
dihasilkan
untuk
tiap user,
sekelompok
user, atau data
warehouse
dan didasarkan pada
informasi
yang
menggambarkan
karakteristik
dari query
seperti
frekuensi, target table, ukuran set hasil.
5.
Query Manager
Query manager, disebut juga dengan komponen back end
melakukan semua operasi yang berhubungan dengan manajement
dari query user. Komponen ini biasanya dibangun menggunakan
tool akses data end user vendor, tool pengawasan data warehouse,
fasilitas database dan program custom built.
Kompleksitas dari query manager ditentukan oleh fasilitas
yang disediakan oleh tool akses end user dan database. Operasi
yang dilakukan oleh
komponen
ini
meliputi
mengarahkan query
ke
tabel
yang
sesuai
dan
menjadwalkan
pengeksekusian query.
Dalam beberapa kasus, query manager juga menghasilkan profile
query
untuk mengizinkan warehouse manager menentukan index
dan agregasi mana yang tepat.
|
|
24
6.
Metadata
Area dari data warehouse ini menyimpan definisi dari semua data
yang
digunakan
oleh
semua
proses
dalam data
warehouse.
Metadata digunakan untuk berbagai tujuan yang meliputi :
•
Ekstraksi
dan
load
process
–
metadata
digunakan
untuk
memetakan sumber kedalam view biasa dari data didalam
warehouse.
•
Proses
manajemen
warehouse
–
metadata
digunakan
untuk mengotomatisasi produksi dari tabel ringkasan.
•
Sebagai bagian dari management query – metadata
digunakan untuk mengarahkan lansung sebuah
query ke
sumber data yang paling tepat. Sehingga proses dalam
processing query menjadi lebih cepat
Sruktur
dari
metadata berbeda
diantara
setiap
proses,
karena tujuannya berbeda. Hal ini berarti copy dari metadata yang
bergambarkan
item
data
yang
sama
disimpan
dalam data
warehouse.
Sebagai
tambahan,
kebanyakan
tool
vendor untuk
management
copy dan akses untuk data end user menggunakan
metadata versi mereka sendiri.
Secara
spesifik,
tool
manajemen
menggunakan metadata
untuk mengerti aturan pemetaan untuk menerapkan dengan tujuan
untuk
mengkonversi
sumber data
ke
dalam bentuk
yang
umum.
Tool akses end user menggunakan metadata untuk
mengerti
|
|
25
bagaimana membangun sebuah query. Manajemen dari metadata
merupakan tugas yang sangat kompleks yang tidak boleh
diremehkan.
7.
End User Access Tool
Tujuan utama dari
data warehouse
adalah menyediakan
informasi kepada user bisnis untuk
membuat keputusan strategis.
User
ini
berinteraksi
dengan data warehouse menggunakan tool
akses end
user.
Data
warehouse
mendukung
secara
efektif
analisis adhoc dan analisis rutin. Performa yang tinggi dapat
dicapai dengan merencanakan terlebih dulu kebutuhan untuk join,
summation,
dan
laporan
periodic oleh
end user.
Ada
lima
kelompok utama dari tool ini:
o
Reporting and query tools
Reporting tools meliputi tool produksi laporan dan
penulis laporan.
Tool
produksi
laporan
digunakan
untuk
menghasilkan laporan operasional regular atau mendukung
tugas batch berkapasitas tinggi, seperti pesanan pelanggan
atau
faktur dan cek pegawai. Penulis
laporan,
merupakan
tool
desktop
yang
murah
yang
didesign
untuk
end
user
tool query untuk data warehouse relational di desain
untuk menerima SQL atau menghasilkan pernyataan SQL
untuk
meng-query
data
yang
disimpan
di
dalam data
warehouse. Tool ini melindungi user dari kompleksitas
|
|
26
dari SQL dan struktur database dengan mengikutsertakan
sebuah layer meta diantara user dan database. Layer meta
adalah perangkat lunak yang menyediakan
view subject
oriented dari
database dan
mendukung pembuatan ‘point
and click’ dari SQL. Sebuah contoh dari tool query adalah
query by example (QBE). Tool query dikenal dengan user
dari aplikasi bisnis seperti analisis demographic dan daftar
mailing pelanggan.
o
Application development tools
Kebutuhan dari end user seperti kapabilitas built in
dari reporting tool dan tool query tidak sesuai baik karena
analisis yang dibutuhkan tidak dapat dilakukan atau karena
interaksi user membutuhkan
expertise tingkat tinggi pada
user. Dalam situasi ini, akses user mungkin membutuhkan
pengembangan
aplikasi in-house
yang
menggunakan tool
akses data
grafikal
yang didesain untuk
lingkungan client
server.
Beberapa
dari tool
pengembangan
aplikasi
ini
berintergrasi
dengan tool
OLAP,
dan
dapat
mengakses
semua
system database,
termasuk
Oracle,
Sybase, dan
Informix.
o
Executive Information System (EIS) Tools
EIS, sering disebut dengan ‘sistem informasi
semua orang’, awalnya di desain untuk mendukung
|
|
27
pembuatan keputusan strategis. Namun,
fokus dari sistem
ini diperluas untuk mendukung semua tingkat dari
manajemen. Tool EIS awalnya berhubungan dengan
mainframe
yang
memungkinkan
user untuk
membangun
aplikasi pembuat keputusan grafikal untuk menyediakan
sebuah
overview dari data organisasi dan mengakses
sumber data eksternal.
o
Online Analytical Processing (OLAP) Tools
Tool
OLAP didasarkan pada konsep database
multidimensi dan
memungkinkan user untuk
menganalisis
data
menggunakan
view
multidimensi
yang kompleks.
Aplikasi
bisnis
untuk tool
ini
meliputi
mempertinggi
efektifitas dari kampanye pemasaran, peramalan penjualan
produk
dan
perencanaan
kapasistas. Tool
ini
mengasumsikan data diorganisir dalam model
multidimensi
yang didukung
oleh MDDB
(Multidimentional Database) atau oleh relational database
yang dirancang memungkinkan query multidimensi
o
Data mining tools
Data mining
adalah
sebuah
proses
menemukan
korelasi, pola, dan tren baru dengan menggali sejumlah
besar data menggunakan teknik statistik, matematis,
intellegensia
buatan.
Data
mining
memiliki
potensial
|
|
28
untuk
memperluas
kapabilitas
dari tool
OLAP
karena
tujuan
utama
dari data mining
adalah
untuk
membangun
model predictive dari pada model retroprective.
2.2.5
Skema Data Warehouse
Komponen database
dari
sebuah data warehouse
dideskripsikan
dengan sebuah teknik yang disebut dimensionality modeling.
Dimensionality
modeling merupakan
suatu
teknik
desain
logikal
yang
bertujuan
untuk
menampilkan
data
dalam bentuk
standar dan
intuitive,
yang memungkinkan akses dengan kecepatan yang tinggi (Connolly dan
Begg, 2005, p1079). Dimentionality modeling untuk desain data
warehouse adalah sebagai berikut :
1.
Star Schema
Menurut Connolly dan Begg (2005, p1079), star
schema
adalah struktur logikal yang mempunyai sebuah tabel fakta berisi
data faktual yang ditempatkan ditengah, dikelilingi oleh tabel
dimensi
berisi
data
acuan
(yang
dapat
didenormalisasi). Star
schema
mengeksploitasi karakteristik dari data faktual dimana
fakta dibuat dari peristiwa yang muncul di masa lalu dan mustahil
untuk diubah, dengan mengabaikan bagaimana mereka dianalisis.
Kebanyakan
fakta
yang
digunakan dalam
tabel
fakta
adalah
angka
dan additive karena
aplikasi data warehouse
tidak
pernah diakses sebagai sebuah record tunggal, tetapi mereka
|
 29
diakses
ratusan,
ribuan
bahkan
jutaan
record
pada
suatu
waktu
dan hal yang paling berguna untuk dilakukan dengan record yang
begitu banyak tersebut adalah mengagregasikan mereka. Tabel
dimensi, berisi deskripsi informasi berupa teks yang dapat
digunakan untuk mempercepat kinerja
query
dengan
denormalisasi informasi kedalam sebuah tabel dimensi.
Denormalisasi
tepat ketika
terdapat
sejumlah entity
yang
berhubungan dengan tabel dimensi yang sering diakses,
menghindari overheat
dari penggabungan tabel tambahan untuk
mengakses
attribute. Denormalisasi tidak tepat dimana data
tambahan tidak sering diakses, karena overheat tabel dimensi
yang diperluas tidak mungkin offset oleh berbagai perolehan
dalam query.
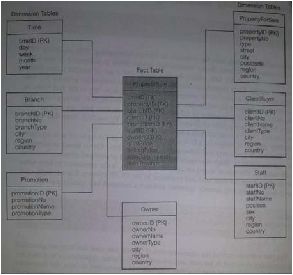
Gambar 2.2 Contoh Star Schema
Sumber : Connolly, 2005, p1080
|
|
30
Keuntungan dari star schema yaitu :
?
Mudah dipahami pengguna
Star schema
menggambarkan dengan jelas
bagaimana pengguna berfikir dan memerlukan data untuk
query
dan analisis. Star
schema
menggambarkan
hubungan antar tabel sama seperti cara pengguna melihat
hubungan tersebut secara normal
?
Mengoptimalkan navigasi
Star schema
mengoptimalisasikan
navigasi
melewati database sehingga lebih mudah dilihat.
Meskipun hasil query terlihat kompleks, tetapi navigasi itu
memudahkan pengguna.
?
Paling cocok untuk pemsrosesan query
Star schema paling cocok untuk pemrosesan query
karena schema ini berpusat pada query. Tanpa bergantung
pada banyak dimensi dan kompleksitas query, setiap query
akan dengan mudah dijalankan pertama dengan memilih
baris dari tabel dimensi dan kemudian menemukan baris
yang sama di tabel fakta.
|
 31
2.
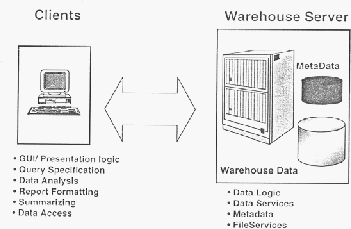
Snowflake schema
Snowflake schema
merupakan
variasi
dari star
schema,
namun
tabel
dimensi
pada schema
ini
tidak
mengandung
denormalisasi yang memungkinkan sebuah dimensi untuk
mempunyai dimensi lagi.
Gambar 2.3 Contoh Snowflake schema
Sumber : Connolly, 2005, p1081
Suatu schema disebut snowflake schema jika satu atau
lebih tabel dimensi tidak berhubungan langsung dengan fact table,
melainkan pada tabel dimensi.
|
 32
2.2.6
Arsitektur Data Warehouse
1.
Arsitektur two-tier
Arsitektur ini memiliki kekurangan yaitu pada skalabilitas
dan
fleksibilitas
yang
dapat diperbaiki
dengan
menggunakan
arsitektur multi-tier.
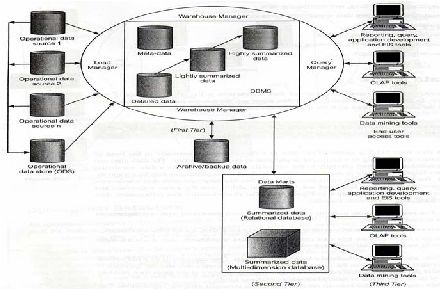
Gambar 2.4 Arsitektur Data Warehouse Two-Tier (Berson, Smith,
dan Thearling, 2000, p32)
2.
Arsitektur multi-tier
Arsitektur ini memperbaiki kelemahan skalabilitas dan
fleksibilitas
pada
arsitektur two-tier.
Server aplikasi melakukan
penyaringan data, pengumpulan, dan akses data, mendukung
metadata, dan memberikan view multidimensi.
|
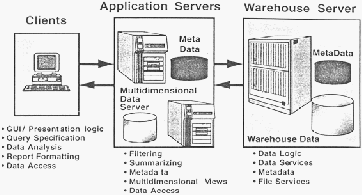 33
Gambar 2.5 Arsitektur Data Warehouse Multi-Tier (Berson,
Smith dan Thearling, 2000, p33)
2.2.7
Keuntungan Penggunaan Data Warehouse
Menurut Connoly dan Begg (2002, p1048), kesuksesan penerapan
sebuah data warehouse
dapat membawa keuntungan besar bagi
perusahaan meliputi :
1.
Potensi ROI (Return On Investment) yang tinggi
Organisasi harus
mengeluarkan
sumber
daya
dan
biaya
dengan jumlah yang sangat besar untuk memastikan penerapan
data warehouse yang sukses. Studi
yang dilakukan IDC
(International Data Corporation) pada tahun 1996 menghasilkan
bahwa
data
warehouse
mencapai
rata-rata
ROI
dalam 3
tahun
sebesar
401%,
dengan
lebih
dari 90%
perusahaan
yang
disurvei
mencapai lebih dari 40% ROI, separuh perusahaan mencapai lebih
|
|
34
dari 160% ROI dan seperempat perusahaan dengan lebih dari
600% ROI.
2.
Keuntungan bersaing (competitive advantage)
ROI yang besar untuk perusahaan yang telah sukses
mengimplementasikan data
warehouse
merupakan bukti
keuntungan bersaing yang sangat
besar. Keuntungan bersaing
tersebut didapatkan dengan memberikan pembuat keputusan akses
ke data sehingga dapat menemukan
informasi
yang
sebelumnya
tidak tersedia, tidak diketahui, dan tidak ditemukan seperti
pelanggan, tren, dan permintaan.
3.
Meningkatkan produktivitas dari pembuat keputusan perusahaan
Data warehouse meningkatkan produktivitas pembuat
keputusan
pada
perusahaan
dengan
membuat database
terintegrasi yang konsisten, berorientasi subyek, dan historis.
Data warehouse mengintegrasikan data dari berbagai sistem yang
berbeda-beda ke suatu bentuk yang memberikan sebuah
pandangan yang konsisten tentang organisasi. Dengan mengubah
data
menjadi
informasi
yang
berguna, data
warehouse
dapat
membuat manajer bisnis untuk melakukan analisis secara lebih
benar, akurat, dan konsisten.
|
 35
2.2.8
Data mart
Data yang terdapat dalam data warehouse dapat dibagi perbagian
sesuai
dengan
kebutuhan
dalam
informasi.
Inilah
yang
dsebut
dengan
data mart. Data mart
memiliki karakteristik yang sama dengan data
warehouse, perbedaannya hanya terdapat pada jumlah data yang dimiliki.
Dalam data mart, data yang ada hanya berasal dari satu bagian atau satu
departemen saja, sedangkan pada data warehouse, data yang ada berasal
dari seluruh bagian dalam perusahaan tersebut. Menurut Vercellis, Carlo
(2009,
p49) data
mart
adalah
sebuah
sistem yang
menarik semua data
yang diperlukan oleh sebuah departemen dalam perusahaan. Data di
dalam data mart biasanya disesuaikan
untuk melakukan
fungsi tertentu,
misalnya digunakan untuk product profitability analysis,
KPI
analysis,
customer demographic analysis, dan sebagainya.
Gambar 2.6 Arsitektur Umum Data Warehouse dan Data Mart
Sumber : Connolly, 2005, p1068
|
|
36
Ada
beberapa karakteristik
yang
membedakan antara
data
mart
dengan data warehouse, yaitu (Connolly and Begg, 2005, p1067):
•
Data
mart lebih
berfokus
kepada
ketentuan
maupun
permintaan
dari pengguna yang berkaitan dengan sebuah departemen ataupun
fungsi-fungsi bisnis organisasi.
•
Secara
normal
data mart tidak
mencakup data
operasional
yang
mendalam tidak seperti halnya dengan data warehouse.
•
Karena data mart
memiliki
jumlah data
yang
lebih
sedikit
dibandingkan
dengan
data warehouse,
data mart
lebih mudah
dimengerti dan diaplikasikan.
Ada
beberapa
alasan
untuk
membangun
sebuah
data
mart
(Connolly dan Begg, 2005, p1069), diantaranya :
•
Member akses kepada user akan data yang diperlukan untuk
melakukan analisis.
•
Menyediakan data dalam bentuk yang disesuaikan dengan
berbagai sudut pandang atas data oleh sekelompok pemakai dalam
sebuah departemen atau fungsi bisnis.
•
Mengurangi waktu respon dari end-user, sehubungan dengan
berkurangnya volume data yang diakses.
•
Menyediakan
struktur
data
yang
sesuai
dengan
kebutuhan
tools
milik end-user, seperti OLAP maupun data mining. Tools tersebut
mungkin
membutuhkan
struktur basis data
internal sendiri. Pada
|
|
37
praktiknya, tools tersebut biasanya membentuk desain data mart
sendiri untuk mendukung fungsionalitas tertentu secara spesifik
•
Data
mart
umumnya
menggunakan
data
lebih
sedikit
sehingga
berbagai
proses
seperti cleaning,
loading,
transformasi
dan
integrasi menjadi jauh lebih mudah. Oleh karena itu pembuatan
serta
implementasi
data
mart
menjadi
lebih sederhana
bila
dibandingkan dengan data warehouse.
•
Biaya
implementasi
data
mart
yang
dibutuhkan
umumnya
jauh
lebih kecil daripada biaya implementasi sebuah data warehouse.
•
Para
pengguna
data
mart yang
ditetapkan sebagai
sasaran untuk
memperoleh dukungan terhadap sebuah proyek data mart
daripada sebuah proyek data warehouse perusahaan.
2.3
Data Mining
2.3.1
Pengertian Data mining
Menurut Han, Jiawei(2006,p5) data mining merupakan pemilihan
atau “menambang” pengetahuan dari jumlah data yang banyak.
Sedangkan
menurut
Berry
(2004,
p7),
data mining
adalah
kegiatan
mengeksplorasi
dan
menganalisis
data dalam jumlah
yang
besar
untuk
menemukan pattern dan rule yang berarti. Data mining digunakan untuk
mencari informasi bisnis yang berharga dari basis data yang sangat besar,
yang
dipakai
untuk
memprediksi
tren dan sifat-sifat
bisnis
serta
menemukan pola-pola yang tidak diketahui sebelumnya.
|
|
38
Menurut Prescott, Hoffer dan McFadden
(2005, p482), data
mining adalah penemuan pengetahuan dengan menggunakan teknik-
teknik yang tergabung dari statistik, tradisional, artificial intelligence dan
grafik komputer. Berdasarkan beberapa pengertian diatas, dapat ditarik
kesimpulan
bahwa data
mining adalah suatu proses analisis untuk
menggali informasi yang berharga yang tersembunyi dengan
menggunakan
statistik
dan artificial
intelligence di
dalam suatu koleksi
data
(database) dengan ukuran sangat besar sehingga ditemukan suatu
pola dari data yang sebelumnya tidak diketahui dan pola tersebut
direpresentasikan dengan grafik komputer agar mudah dimengerti.
2.3.2
Fungsi Data Mining
Menurut JiaweiHan (2006,p21) Fungsi data mining
digunakan
untuk menentukan jenis pola yang terdapat dalam database. Secara
umum fungsi data mining dapat dikelompokan menjadi dua kategori
yaitu deskriptif dan prediktif. Deskriptif berfungsi untuk merincikan sifat
umum dari data yang terdapat dalam database. Prediktif berfungsi untuk
menyediakan referensi yang dapat digunakan untuk merancang rangkaian
prediksi.
Dalam beberapa
kasus,
mungkin
beberapa
pengguna
tidak
tahu
bahwa pola – pola menarik yang terdapat dalam data mereka, dan karena
hal itu mereka ingin mencari beberapa jenis pola data secara paralel.
Karenanya data mining sistem
memiliki peranan penting dalam
|
|
39
menghasilkan jenis –
jenis pola yang berbeda untuk mengakomodasi
keinginan
pengguna
akan
pola
yang
beragam.
Selanjutnya,
sistem data
mining
harus
dapat
menemukan
bermacam
–
macam
pola dari berbagai
macam sumber. Sistem data mining juga harus membantu pengguna
untuk
menemukan
petunjuk
yang
tepat
dan
spesifik.
Karena
beberapa
pola
dalam
data
mining
tidak
menyimpan
seluruh datanya dalam
database,
ukuran
kepastian
atau
kepercayaan biasanya terkait dengan
setiap pola yang ditemukan. Menurut Berson, Smith dan Thearling (2000,
pp37-38) pada dasarnya aplikasi data mining digunakan untuk melakukan
empat macam fungsi, yaitu :
1. Fungsi Klasifikasi (Classification)
Data mining dapat digunakan
untuk
mengelompokkan
data-data yang jumlahnya besar menjadi data-data yang lebih
kecil.
2. Fungsi Segmentasi (Segmentation)
Disini data mining
juga digunakan untuk melakukan
segmentasi (pembagian) terhadap data berdasarkan karakteristik
tertentu.
3. Fungsi Asosiasi (Association)
Pada
fungsi
asosiasi
ini, data
mining
digunakan
untuk
mencari hubungan antara karakteristik tertentu.
|
 40
4. Fungsi Pengurutan (Sequencing)
Pada
fungsi
ini, data
mining
digunakan
untuk
mengidentifikasikan
perubahan
pola
yang
terjadi
dalam jangka
waktu tertentu.
2.3.3
Proses Dalam Data Mining
Data
mining
adalah
sebuah
langkah
dalam proses
mencari
pola
–
pola
yang terdapat dalam setiap informasi. Langkah – langkah tersebut akan di
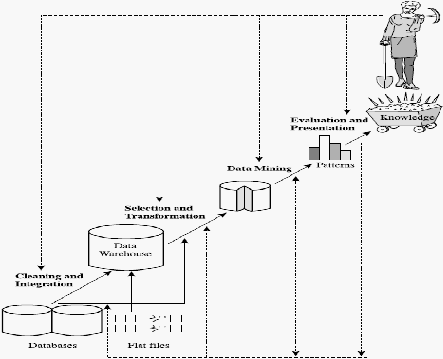
jelaskan pada gambar 2.7 (Han, 2006, p6).
Gambar 2.7 Proses Menghasilkan Pengetahuan Melalui Data Mining
Sumber : Han, Jiawei (2006, p6)
|
|
41
Gambar
2.7
menggambarkan
proses
data
mining
dalam
menghasilkan pengetahuan dan terdiri dari beberapa urutan :
1.
Data
Cleaning,
untuk
menghapus
data
yang
tidak
dipakai
dan
data yang tidak konsisten
2.
Data
Integration, dimana berbagai sumber data dapat
digabungkan
3.
Data
Selection,
data yang
bersangkutan pada
tugas analisis
diseleksi dan diambil kembali dari database
4.
Data Transformation, dimana data diubah atau diperkuat
menjadi
bentuk
yang
seharusnya
untuk diolah
dengan
menganalisis
ringkasan atau jumlah total agregasi
5.
Data mining, sebuah proses penting dimana metode intelijen
diterapkan dengan tujuan untuk mengolah pola – pola data.
6.
Pattern
evaluation,
untuk
mengidentifikasi
pola
–
pola
menarik
yang menjelaskan mengenai ukuran dasar pengetahuan yang ada.
7.
Knowledge
presentation,
dimana visualisasi
dan teknik
representasi
pengetahuan digunakan
untuk
menyajikan
pengetahuan yang telah diolah untuk pengguna.
|
 42
2.3.4
Arsitektur Data Mining
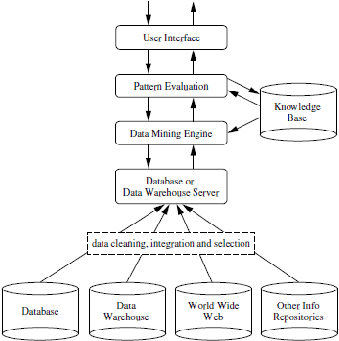
Gambar 2.8 Arsitektur Tipikal Data Mining
Menurut Han, Jiawei (2006,p8) Arsitektur tikipal data mining
memiliki beberapa komponen, diantaranya adalah :
-
Knowledge base : Bidang pengetahuan yang digunakan untuk
memandu pencarian atau mengevaluasi pola – pola yang buruk.
-
Data
mining
engine
:
Hal
ini penting
untuk
sistem
data
mining
dan idealnya terdiri dari sekumpulan fungsionalitas modul seperti
analisi karaktersisasi, asosiasi
dan
korelasi,
klasifikasi, prediksi,
analisis cluster, analisis outlier dan analisis evolusi.
-
Pattern
evaluation
module :
Biasanya
komponen ini
menggunakan langkah – langkah ketertarikan dan berinteraksi
|
|
43
dengan modul data mining agar fokus terhadap pola – pola yang
jelas.
-
Data
mining
:
Modul
ini
menghubungkan
antara
pengguna
dan
sistem data
mining,
yang
memungkinkan
pengguna
untuk
berinteraksi
pada
sistem
dengan cara
menentukan query,
menyediakan
informasi
agar
proses
pencarian
menjadi
lebih
fokus, dan melakukan explorasi
informasi berdasarkan
hasil dari
data mining.
2.3.5
Penerapan Data Mining
Sebagai
ilmu
yang
relatif
baru,
belum banyak
perusahaan
yang
menerapkan
data
mining.
Menurut
Sucahyo
Yudho
Giri
(2003,
pp1-3)
ada beberapa bidang dimana proses data mining dapat diterapkan antara
lain :
1.
Analisa Pasar dan Manajemen
Dengan
menggunakan
data
mining,
ada
beberapa
permasalahan yang dapat diselesaikan, diantaranya :
a.
Menembak target pasar
Data mining dapat melakukan pengelompokkan
dari model-model pembeli dan mengklasifikasikannya
berdasarkan karakteristik yang diinginkan, seperti
kebiasaan membeli dan tingkat penghasilan yang sama.
b.
Melihat pola beli pemakai dari waktu ke waktu
|
|
44
c.
Cross-market analysis
Data mining dapat dimanfaatkan untuk melihat
hubungan antara penjualan satu produk dengan produk
lainnya. Sebagai contoh, dengan
data mining dapat
diketahui pola penjualan indomie
sedemikian
rupa
sehingga dapat diketahui barang apa saja yang juga dibeli
oleh pembeli indomie.
d.
Profil pelanggan
Data mining dapat membantu menganalisa profil
pelanggan/pembeli/nasabah sehingga dapat diketahui
kelompok
pelanggan tertentu
suka
membeli
produk
apa
saja.
e.
Identifikasi kebutuhan pelanggan
Dengan data mining, dapat diidentifikasikan
produk-produk apa saja yang terbaik untuk tiap kelompok
pelanggan, sehingga dapat disimpulkan faktor-faktor apa
saja
yang
kira-kira
dapat
menarik
pelanggan baru untuk
bergabung/membeli.
f.
Menilai loyalitas pelanggan
VISA International Spanyol menggunakan data
mining untuk melihat kesuksesan program-program
pelanggan loyalty mereka.
|
|
45
g.
Informasi Summary
Data mining dapat dimanfaatkan untuk membuat
laporan summary (kesimpulan) yang bersifat multi-
dimensi dan dilengkapi dengan informasi statistik lainnya
2.
Analisa Perusahaan dan Manajemen Resiko
a.
Perencanaan Keuangan dan Evaluasi Aset.
Data Mining dapat membantu pengguna untuk
melakukan analisis dan prediksi cash flow (aliran dana
atau aliran uang) serta melakukan contingent claim
analysis untuk mengevaluasi aset.
b.
Perencanaan Sumber Daya (Resource Planning)
Resource
planning dapat
dilakukan
dengan
memanfaatkan informasi ringkas (summary) serta pola
pembelanjaan dan pemasukan dari masing-masing
resource yang didapatkan dari proses data mining.
c.
Persaingan (Competition)
Data Mining dapat membantu perusahaan-
perusahaan itu untuk memonitor
pesaing-pesaingnya
dan
melihat market direction perusahaan lawan tersebut.
Selain itu, dengan data mining, perusahaan juga
dapat menyusun strategi penetapan harga di pasar yang
sangat kompetitif.
|
|
46
d.
Keuangan
Dalam bidang
keuangan,
data
mining
dapat
digunakan
untuk mendeteksi transaksi-transaksi keuangan
yang mencurigakan (seperti money laundry). Hal ini akan
sulit dilakukan jika menggunakan analisis standar.
e.
Asuransi
Data Mining dapat digunakan untuk
mengidentifikasi layanan kesehatan yang sebenarnya tidak
perlu tetapi
tetap dilakukan oleh
peserta
asuransi.
Selain
itu,
data mining
juga
dapat
digunakan
untuk
mengklasifikasikan pengguna-pengguna asuransi dengan
tingkat resiko tertentu.
2.3.6
Ukuran Kesuksesan Data Mining
Ukuran kesuksesan penerapan data mining cukup beragam.
Menurut
Berson,
Smith,
dan
Thearling
(2000,
p222),
ada
tiga
ukuran
yang merupakan aturan emas untuk pengembangan data mining yaitu:
1. Ketelitian (accuracy)
Sistem data mining harus menghasilkan sebuah model
yang seteliti mungkin, tetapi perlu diketahui bahwa penambahan
ketelitian yang dirasa kecil antara teknik-teknik yang berbeda
mungkin
memberikan
efek
yang
besar
atau
mungkin
efek
yang
|
|
47
buruk,
yang disebabkan karena
contoh acak
yang
berubah-ubah
dalam lingkungan pasar yang berubah-ubah.
2. Kejelasan (explanation)
Sistem data mining
harus
mampu menjelaskan bagaimana
model
bekerja
bagi end
user
dengan
cara
yang
jelas
sehingga
membangun intuisi, dan memungkinkan intuisi-intuisi dan
pemahaman
umum untuk
diuji
dan
ditegaskan
secara
mudah.
Sistem tersebut
sebaiknya
juga
memungkinkan
adanya
suatu
kejelasan
tentang
keuntungan
atau ROI
(Return
On
Investment)
yang dapat
diperoleh
dengan
diimplementasikannya sistem data
mining.
3. Integrasi (integration)
Sistem data mining harus terintegrasi dengan proses bisnis
yang ada, dan aliran data dan informasi pada perusahaan. Sistem
ini membutuhkan penggandaan data dan pemrosesan data secara
keseluruhan
sehingga
membuat
banyak proses dimana kesalahan
dapat muncul. Dengan integrasi yang kuat, beberapa kesalahan
yang mungkin terjadi dapat diperkecil.
Jika
ketiga
ukuran
tersebut
terpenuhi
maka
sistem data
mining
yang
dibangun
akan
menghasilkan model
yang
sangat
menguntungkan
yang cenderung tetap stabil selama jangka waktu yang lama.
|
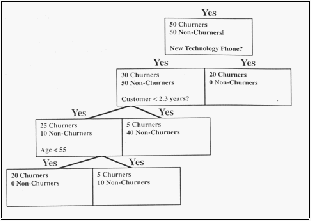 48
2. 4
Teknik Data Mining
Ada banyak teknik dalam data mining. Teknik analisa tersebut umumnya
terbagi menjadi teknik generasi lama dan teknik generasi baru. Adapun beberapa
teknik yang dapat digunakan untuk melakukan data mining, diantaranya :
2.4.1
Teknik Decision Tree
Menurut Berson, Smith, dan Thearling (2000, pp156-162), seperti
namanya,
algoritma
decision tree adalah
model
perkiraan
yang
dapat
dilihat
sebagai
sebuah pohon.
Secara
spesifik,
setiap
cabang (branch)
dari pohon
ini adalah pertanyaan klasifikasi, dan daun (leaf) dari pohon
ini adalah bagian dari kumpulan data dengan klasifikasi tertentu. Sebagai
contoh,
untuk
membagi-bagi pelanggan
yang
melakukan churning
(memperbaharui kontrak telepon mereka) dalam industri telepon seluler,
dapat dibuat decision tree seperti yang terlihat pada gambar 2.10.
Gambar 2.9 Contoh decision tree (Berson, Smith, dan Thearling,
2000, p157)
|
|
49
Karena decision tree termasuk teknik generasi baru, belum
banyak orang menggunakannya. Namun secara garis besar ada beberapa
cara dalam menggunakan decision tree, yaitu :
1.
Untuk eksplorasi.
Algoritma
decision tree
dapat
digunakan
untuk
mengeksplorasi data
dan
masalah-masalah dalam
bisnis. Hal
ini
sering
dilakukan
dengan
melihat
perkiraan-perkiraan yang
dihasilkan dan nilai-nilai
yang terdapat dalam setiap percabangan
pohon.
2.
Untuk melakukan pemrosesan awal terhadap data.
Disini algoritma decision tree digunakan untuk melakukan
pemrosesan
awal
terhadap
data
(tahap cleaning
and
extracting
data) yang akan diprediksi
dengan algoritma lain (misalnya :
neural network).
3.
Untuk melakukan prediksi.
Decision tree
juga
telah
digunakan
untuk
melakukan
prediksi terhadap kemungkinan-kemungkinan keadaan atau
kondisi di masa yang akan datang.
Untuk membuat model data mining dengan menggunakan
decision tree, kita perlu
membuat pohon pertanyaan. Pohon pertanyaan
ini nantinya akan digunakan untuk membagi-bagi data menjadi kelompok
yang lebih spesifik atau lebih kecil. Hal ini akan terus dilakukan sampai
|
|
50
bagian paling terkecil atau sampai data tersebut sudah tidak dapat dipecah
menurut karakteristiknya lagi.
Untuk
menentukan
pertanyaan
seperti
apa
yang akan digunakan
untuk memecah pohon, perlu diketahui terlebih dahulu mengenai konsep
pertanyaan yang baik dan yang buruk. Pertanyaan yang baik dan pantas
digunakan untuk memecah pohon menjadi bagian-bagian yang lebih kecil
adalah
pertanyaan-pertanyaan
yang
mampu
membagi record-record di
dalam pohon
menjadi
bagian-bagian
yang
seimbang besarnya, sehingga
membuat
record
menjadi
lebih terorganisir ke
dalam cabang-cabang
di
dalam
pohon.
Menurut
Berry
dan
Linoff
(1997,
pp282-284)
kelebihan
dari teknik decision tree adalah sebagai berikut :
1.
Decision tree mampu menghasilkan aturan-aturan yang dapat
dimengerti.
Maksudnya disini adalah bahwa aturan-aturan yang
dihasilkan dari algoritma decision tree ini dapat diterjemahkan ke
dalam bahasa
Inggris
atau
bahasa SQL
yang
dapat
dimengerti.
Bahkan
walaupun
apabila decision tree
yang
dihasilkan
sangat
kompleks
dan
besar,
secara
umum sangatlah
mudah
untuk
mengikuti salah satu jalur di dalam pohon yang dihasilkan.
2.
Decision tree mampu melakukan klasifikasi tanpa membutuhkan
banyak komputasi.
Walaupun decision tree dapat mengambil berbagai macam
bentuk, pada kenyataannya, algoritma
yang digunakan
untuk
|
|
51
menghasilkan decision tree umumnya menghasilkan pohon
dengan faktor pencabangan yang kecil dan proses pengujian yang
mudah pada setiap node-nya.
Pengujian-pengujian yang umum
meliputi perbandingan numerik, keanggotaan himpunan, dan
perintah-perintah
konjungsi sederhana.
Pada saat
diimplementasikan
ke
dalam komputer,
pengujian-pengujian
ini
diterjemahkan
menjadi
suatu
operasi
boolean dan
integer
yang
cepat dan murah. Hal ini sangat penting karena pada lingkungan
komersial,
model-model prediktif
seperti
ini
biasanya digunakan
untuk
mengklasifikasikan sejumlah
besar record
(jutaan bahkan
miliaran record).
3.
Kemampuan untuk
menangani data dalam bentuk kontinyu atau
kategoris
Metode decision tree dapat menangani variabel kontinyu
atau kategoris dengan baik.
Variabel
kategoris,
yang
menjadi
masalah pada teknik
neural network dan teknik statistik, dapat
dipisahkan dengan baik pada teknik ini (masing-masing kategori
menjadi 1 cabang pohon).
Variabel kontinyu dapat dipisahkan
dengan sama mudahnya, yaitu dengan memilih salah satu angka
diantara jangkauan angkanya.
|
|
52
4.
Kemampuan untuk dengan jelas melihat field yang paling baik
Algoritma pembuatan decision tree mengambil field
dengan kemampuan memisahkan data yang paling baik dan
meletakkannya di node akar dari pohon tersebut.
Selain kelebihannya, ternyata decision tree juga memiliki
beberapa
kekurangan. Menurut
Berry
dan
Linoff
(1997,
pp284-285)
kekurangan dari teknik decision tree ini adalah sebagai berikut :
1.
Kemungkinan kesalahan semakin besar seiring dengan banyaknya
kelas
Beberapa algoritma decision tree hanya dapat menangani
kelas-kelas dengan
nilai biner (ya/tidak,
terima/tolak).
Beberapa
algoritma
lainnya
dapat
membagi record-record
menjadi
beberapa kelas, tetapi pada algoritma ini, kemungkinan kesalahan
membesar saat jumlah contoh pada setiap kelas menjadi semakin
kecil.
Hal ini dapat terjadi
dengan
cepat
pada
pohon
yang
memiliki
banyak
tingkatan
atau
banyak
cabang
di
setiap
node-
nya.
2.
Sulit dan mahal untuk dilatih
Proses pembuatan decision tree sangat mahal. Pada setiap
node,
setiap
kandidat
field yang akan
dipecah harus diurutkan
terlebih dahulu sebelum pecahan terbaiknya dapat ditemukan.
Pada beberapa algoritma, digunakan kombinasi dari field-field
|
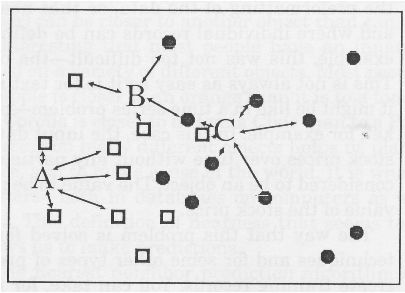 53
tersebut,
dan
berat
kombinasi
optimal
dari
pohon harus
dicari
terlebih dahulu. Algoritma penyederhanaan (prunning) juga dapat
menjadi sangat mahal, karena banyak kandidat sub-pohon yang
harus dibentuk dan dibandingkan.
3.
Adanya masalah dengan daerah-daerah yang tidak berbentuk segi
empat
Kebanyakan algoritma decision tree hanya memeriksa satu
field pada satu
waktu.
Hal
ini
mengakibatkan
terciptanya kotak-
kotak klasifikasi yang berbentuk segi empat, yang mungkin tidak
secara
baik
merepresentasikan distribusi
record yang
sesungguhnya dalam ruang keputusan.
2.4.2
Teknik Nearest Neighbor
Gambar 2.10 Ilustrasi Teknik Memory Based Reasoning atau Nearest
Neighbor (Berson, Smith, dan Thearling, 2000, p138)
|
|
54
Menurut Berson, Smith dan Thearling (2000, p136), algoritma
nearest neighbor adalah objek-objek
yang
“dekat” satu
sama
lain,
juga
akan
memiliki
nilai prediksi yang
hampir sama.
Dengan demikian,
jika
nilai prediksi dari salah satu objek diketahui, maka dapat diketahui
nilai
prediksi dari nearest neighbor-nya.
Pada gambar 2.10, apabila nilai prediksi dari titik A, pada
algoritma
ini,
dilakukan
dengan melihat titik-titik lainnya yang
berdekatan dengan titik A. Hal yang sama berlaku untuk titik B dan C).
Menurut Berry dan Linoff (1997, pp184-185), ada beberapa kelebihan
yang dapat diperoleh dari penggunaan algoritma nearest
neighbor ini,
yaitu:
1.
Hasil mudah dimengerti.
2.
Dapat diterapkan pada tipe data yang berubah-ubah, bahkan dapat
diterapkan juga pada data non relasional.
3.
Dapat bekerja secara efisien pada jumlah field yang banyak.
4.
Dapat mengelola training set dengan jumlah effort yang minimal.
Selain kelebihannya, ada juga kekurangan dari nearest neighbor.
Menurut
Berry dan Linoff
(1997, pp185-186) kekurangan dari nearest
neighbor yaitu :
1.
Mahal dari segi komputasional saat melakukan klasifikasi dan
prediksi.
2.
Membutuhkan jumlah penyimpanan yang besar untuk training
set.
|
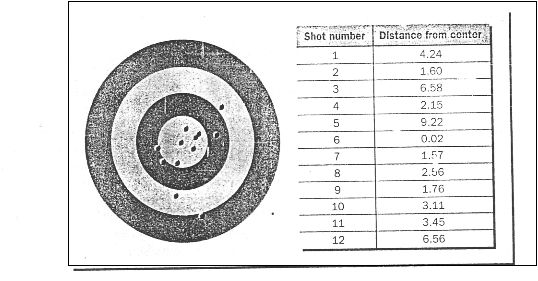 55
3.
Hasil
dapat
tergantung
pada
pemilihan
fungsi
jarak,
fungsi
kombinasi, dan jumlah neighbor.
2.4.3
Teknik Clustering
Algoritma cluster, tidak seperti decision tree, tidak membagi data
ke
dalam
garis-garis,
tetapi
menempatkan
data
dalam cluster-cluster,
seperti yang terlihat pada gambar 2.11 di halaman berikut ini :
Gambar 2.11 Salah Satu Contoh Bentuk Visualisasi Teknik
Clustering (Seidman, 2001, p13)
Teknik clustering ini umumnya berguna untuk representasi secara
visual, karena data dikelompokkan berdasarkan kriteria-kriteria umum.
Banyak piranti lunak yang menampilkan kelompok-kelompok ini sebagai
sebuah lubang peluru pada sebuah target.
Dari representasi
target
tersebut, dapat dilihat adanya kecenderungan lebih tingginya jumlah
lubang pada bagian-bagian atau kelompok-kelompok tertentu dari target
|
|
56
tersebut.
Menurut Berson, Smith, dan Thearling (2000, p148),
kelemahan utama dari teknik ini adalah :
1.
Hasil yang diperoleh sulit dimengerti
Tidak
seperti
pada
teknik decision tree,
pada
teknik
ini
tidak ada node-node yang dapat ditelusuri, dan tidak ada aturan
yang bisa
diikuti.
Pada
kenyataannya, tidak ada prediksi nyata
yang dihasilkan (oleh karena itu, teknik ini lebih condong
dilakukan untuk kebutuhan eksplorasi terhadap data dan
visualisasi terhadap data yang dihasilkan teknik lain). Akibatnya
hasil yang diperoleh dari penggunaan teknik ini akan sulit
dimengerti.
2.
Karakteristik data sangat sulit dibandingkan
Karena teknik ini mengandalkan data-data numerik untuk
menentukan titik-titik yang akan dibuat pada sumbu koordinat,
membandingkan angka-angka yang digunakan untuk mengukur
data-data yang berbeda dapat menjadi sangat sulit.
2.4.4
Teknik Neural Network
Neural network
(jaringan syaraf) yang sebenarnya merupakan
sistem biologis yang
mencari pola,
membuat prediksi dan dapat belajar.
Sedangkan
jaringan
syarat
tiruan
merupakan
program komputer
yang
dapat
mencari pola, dan membangun model prediksi dari database
historis
yang
besar dengan
cara
menerapkan
algoritma
yang
dapat
|
|
57
membuat
komputer
belajar.
Kekurangan neural
network yaitu
sulit
digunakan dan dikembangkan. Tetapi neural network memiliki kelebihan
yang
berarti
yaitu
memiliki
akurasi
yang tinggi, yang
dapat
diterapkan
pada berbagai jenis permasalahan (Berson, Smith dan Thearling, 2000,
p173).
2.4.5
Teknik Association Rules
Association rules merupakan salah satu bentuk utama dari data
mining dan
merupakan bentuk paling umum
mengenai proses penemuan
pengetahuan
dalam sistem
unsupervised
learning.
Teknik
ini
juga
merupakan bentuk data mining
yang paling mendekati apa yang
dipikirkan
orang
mengenai
data mining,
yaitu
menambang
emas
dari
sebuah data yang besar.
Yang
menjadi emas adalah sebuah aturan
yang
menarik,
dan
dapat
memberikan
suatu gambaran tentang data yang
mungkin tidak diketahui dan dapat dengan mudah dikemukakan. Teknik
association rules melibatkan
pemrosesan
data
secara
besar-besaran,
dimana semua pola yang memungkinkan secara sistematis akan diambil
dari data, kemudian dilakukan pengukuran terhadap pola tersebut untuk
mengetahui kemungkinan pola tersebut muncul kembali.
|