|
4
BAB II
LANDASAN TEORI
2.1 Kajian Kepustakaan
2.1.1 Survey
Survei digunakan untuk mengumpulkan informasi kuantitatif tentang suatu hal dalam
populasi. Survei pada masyarakat dan perusahaanpada umumnya terjadi dalam pemilu,
kesehatan, ilmu sosial dan penelitian pemasaran. Survei dapat difokuskan pada pendapat atau
informasi faktual tergantung pada tujuannya, dan banyak survei memberikan pertanyaan-
pertanyaan kepada beberapa orang. Bila pertanyaan diberikan kepada peneliti, survei ini disebut
wawancara terstruktur atau researcher-administered survey.Bila pertanyaan diberikan kepada
responden, survei ini disebut sebagai kuesioner atau self-administered survey.
Kelebihan-kelebihan dari penggunaan survey adalah:
•
Survey lebih efisien untuk meneliti data dari responden dalam jumlah yang sangat besar.
Teknik statistik dapat digunakan untuk memastikan validitas, realibilitas, dan signifikansi
statistik dari data tersebut.
•
Survey sangat fleksible, dalam arti berbagai informasi dapat dikumpulkan. Survey dapat
digunakan untuk mempelajari sikap manusia, nilai, kepercayaan, dan perilaku masa lalu.
•
Karena survey sudah distandarisasi, pada umumnya survey bebas dari kesalahan /
kekeliruan.
•
Pada umumnya survey mudah untuk diselenggarakan.
|
|
5
•
Adanya ekonomi pada koleksi adalah akibat dari fokus pertanyaan yang di standardisasi.
Hanya pertanyaan yang menarik bagi peneliti ditanya, dicatat, dikodifikasikan, dan
dianalisis. Waktu dan uang tidak dihabiskan untuk pertanyaan tidak penting.
•
Survey dari sample biasanya lebih murah daripada sensus secara keseluruhan.
Sementara itu kekurangan-kekurangan dari penggunaan survey adalah:
•
Survey bergantung kepada motivasi, kejujuran, daya ingat, dan kemampuan untuk
memberikan respon dari seseorang. Mereka mungkin tidak menyadari alasan
diadakannya survey. Mereka mungkin tidak termotivasi untuk memberikan jawaban yang
akurat, bahkan mungkin mereka lebih termotivasi untuk memberikan jawaban yang lebih
menguntungkan bagi mereka.
•
Survey terstruktur, khususnya survey dengan 1 jawaban pasti, bisa memiliki validitas
yang kecil ketika meneliti variabel yang berpengaruh.
•
Meskipun individu yang dipilih dalam survey adalah acak, kemungkinan kesalahan tetap
tidak bisa dihindari. Data dari orang-orang yang memilih untuk menjawab survey bisa
berbeda dengan orang-orang yang memilih untuk tidak menjawabnya. Dan hal itu bisa
mengakibatkan ketidakcocokan formula perkiraan hasil survey.
•
Survey dengan pilihan jawaban dapat menghasilkan data yang kurang tepat bila pilihan
jawabannya kurang luas. Misalnya jika pilihan jawabannya hanya ya atau tidak,
responden akan memilih untuk menjawab tidak karena jawaban sangat jarang tidak
tersedia.
Cara-cara pengumpulan data pada suatu survey:
•
Telepon: peneliti akan menelepon responden satu per-satu untuk memperoleh data yang
diinginkan
|
|
6
•
Surat: peneliti akan mengirimkan surat ke alamat responden, yang kemudian akan
dijawab oleh responden dan dikirim kembali ke peneliti.
•
Survey online: peneliti dapat menggunakan e-mail atau website untuk mengadakan
survey.
•
Survey langsung ke rumah: peneliti akan pergi ke rumah responden untuk
mengumpulkan datanya.
•
Survey langsung di suatu tempat: peneliti akan pergi ke suatu tempat untuk mencari
responden dan mengumpulkan datanya.
2.1.2 Sampling
Pemilihan Sampel sangat penting untuk validitas informasi yang mewakili populasi yang
sedang dipelajari. Pendekatan sampling membantu untuk menentukan fokus penelitian dan
memungkinkan penerimaan yang lebih baik dari penelitian yang sedang dibuat. Penggunaan
sampling yang diarahkan dapat digunakan selama itu dicatat bahwa sampel yang dihasilkan tidak
mungkin menjadi representasi yang benar dari populasi penelitian. Ada dua pendekatan yang
berbeda untuk sampling dalam penelitian survei:
•
Nonprobability sampling, dalam pendekatan ini peneliti tidak tahu probabilitas masing-
masing elemen seleksi dalam sampel. Nonprobability sampling yang paling sering
digunakan adalah metode sampling convenience sampling. Dengan metode ini, hanya
sampel mereka yang tersedia dan bersedia untuk berpartisipasi dalam survei. Penggunaan
pendekatan ini memungkinkan untuk memudahkan bagi peneliti sementara
ada
kemungkinan kehilangan data validitas karena kurangnya representasi.
•
Probability sampling memberikan setiap elemen kesempatan untuk diikutsertakan dalam
sampel. Metode ini lebih baik dalam representasi yang benar dari populasi. Metode ini
|
|
7
lebih sulit karena butuh biaya lebih tinggi, dan kesulitan dalam memperoleh cakupan
penuh dari populasi yang diinginkan, namun hasil dari penelitian cenderung lebih
memrepresentasikan populasi dengan benar. Berbagai bentuk probability sampling
dirancang untuk berbagaikeuntungan,misalnya kesederhanaan teoritis, kesederhanaan
operasional, informasi rinci tentang sub-populasi, atau biaya minimal. Beberapa bentuk
dari probability sampling yang umum:
o
Equal probability of selection (EPS), di mana setiap elemen dari populasi
memperoleh kesempatan yang sama untuk dimasukkan ke dalam sample. Survei
EPS relatif sederhana untuk ditafsirkan. Bentuk-bentuk yang termasuk EPS
adalah Simple Random Sampling (SRS) dan sampling sistematik.
o
Probability-proportional-to-size designs(PPS), di mana elemen yang lebih besar
(berdasarkan berbagai metode pengukuran) memiliki
kesempatan yang lebih besar
untuk menjadi sample. Pendekatan ini umum digunakan dalam survei bisnis di
mana tujuannya adalah untuk menentukan total sektor. Dibandingkan dengan
EPS, berkonsentrasi pada unsur-unsur yang lebih besar dapat menghasilkan
akurasi yang lebih baik untuk biaya / ukuran sampel yang sama.
o
Stratified random sampling, di mana populasi dibagi menjadi sub-
populasi(disebut strata) dan sampel acak kemudian digambarkan secara terpisah
dari masing-masing strata, dengan menggunakan metode probability sampling
(kadang-kadang ada sub-sub-populasi lagi). Ini dilakukan untuk memberikan
kontrol yang lebih baik atas ukuran sampel di setiap sub-populasi.
|
|
8
2.1.3 Regresi Linier
Dalam statistik, regresi linier adalah segala bentuk pemodelan variabel Y skalar terhadap
satu atau lebih variabel X. Dalam regresi linier, model parameter yang tidak diketahui
diperkirakan dari data menggunakan fungsi linear. Model seperti ini disebut model linier.Pada
umumnya, regresi linier mengacu pada model di mana rata-rata bersyarat dari Y diberi nilai X
adalah fungsi X. Kadang-kadang, regresi linier bisa dilihat dari median, atau beberapa kuantil
lainnya dari distribusi bersyarat dari X y diberikan dinyatakan sebagai fungsi linear dari X.
Seperti semua bentuk analisis regresi, regresi linier berfokus pada distribusi probabilitas bersyarat
dari X y diberikan, bukan pada distribusi probabilitas gabungan y dan X, yang merupakan
domain analisis multivariat.
Regresi linier memiliki banyak manfaa. Sebagian besar aplikasi regresi linier digunakan
dalam salah satu dari dua kategori berikut:
•
Jika tujuannya adalah prediksi, atau peramalan, regresi linier dapat digunakan untuk
cocok dengan model prediktif untuk data yang diamati set y dan nilai-nilai X. Setelah
mengembangkan model seperti itu, jika nilai tambah dari X kemudian diberi tanpa nilai
yang menyertainya y, model dipasang dapat digunakan untuk membuat prediksi nilai y.
•
Mengingat y variabel dan sejumlah variabel X1, ..., Xp yang mungkin berhubungan
dengan y, maka analisis regresi linier dapat diterapkan untuk mengukur hubungan antara y
dan Xj, untuk menilai bagaimana hubungan Xj dengan y sama, dan untuk mengidentifikasi
apakah data dari Xj berisi informasi yang cukup tentang y, sehingga jika salah satunya
adalah dikenal, yang lain tidak lagi diperlukan.
Kekurangan dari menggunakan metode regresi linier adalah data-data yang diukur harus
linear untuk memperoleh hasil yang baik.
|
 9
i i
2
2.1.3.1 Regresi Linier Sederhana
Regresi linier sederhana adalah perkiraan kuadrat terkecil dari model regresi linier
dengan variabel prediksi tunggal. Dengan kata lain, regresi linier sederhana cocok untuk
persamaan garis lurus melalui titik n sedemikian rupa yang menentukan jumlah kuadrat residual
dari model tersebut (yaitu, jarak antara titik dari himpunan data dan garis dipasang) sekecil
mungkin.
Berikut adalah rumus yang digunakan pada regresi linier sederhana:
Y
i
=
ß
0
+
ß
1
x
i
i
=
1, 2,..., n
Rumus (2.1)
Pada rumus ini Y merupakan variabel terikat, dan x merupakan variabel bebas. Koefisien
regresi ß0 dab ß1 diperoleh dari rumus:
n
n
ß
0
=
?
y
i
i
=1
n
-
ß
1
?
X
i
i
=1
n
?
n
?
?
n
?
n
?
?
X
i
?
?
?
Y
i
?
?
X
Y
-
? =1
i =1
?
? =1
i =1
?
ß
=
i
=1
n
1
?
n
?
n
?
?
?
X
²
-
? =1
i =1
X
i
?
?
i
=1
n
Rumus (2.2)
Dengan rumus 2.2 persamaan regresi pada rumus 2.1 dapat dihasilkan.
|
 10
i
i
1
1
2
2
i
i
?
?
?
2.1.3.2 Korelasi Pearson
Dengan rumus korelasi Pearson berikut, dapat diketahui apakah korelasi data X dan Y
linier atau tidak:
?
n
?
?
n
?
n
?
?
X
i
?
?
?
Y
i
?
?
X
Y
-
?
i
=¹
?
?
i
=1
?
r
(
X
,Y ) =
i
=1
n
?
?
n
?
?
2
?
?
n
?
?
2
?
n
?
?
X
i
?
?
?
n
?
?
Y
i
?
?
?
?
X
2
-
?
=¹
i =¹
?
?
?
?
Y
2
-
?
=1
i
?
?
i
=1
n
i
=¹
n
?
?
?
?
?
?
?
?
?
?
?
?
?
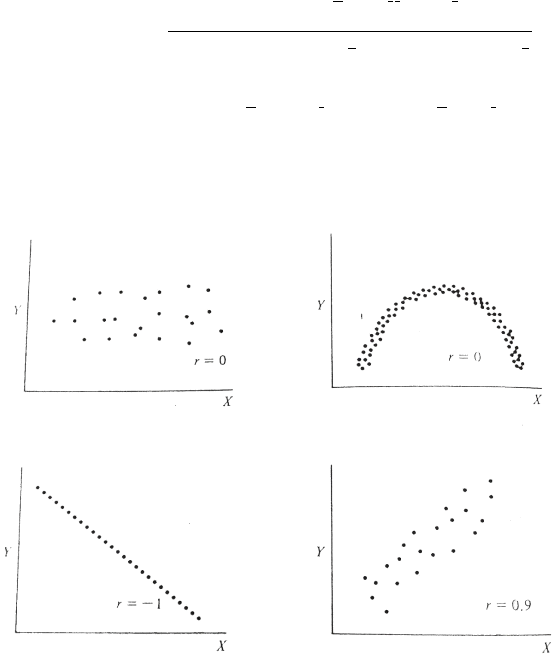
Berikut adalah contoh grafik dengan hasil perhitungan nilai r nya:
|
 11
Gambar 2.1 Korelasi Pearson
Tabel berikut adalah hubungan antara nilai korelasi pearson dengan kelinieran dari 2 data yang
dibandingkan:
Tabel 2.1 Korelasi Pearson
Korelasi
Negatif
Positif
Tidak Ada
-0.09 sampai 0.0
0.0 sampai 0.09
Kecil
-0.3 sampai -0.1
0.1 sampai 0.3
Sedang
-0.5 sampai -0.3
0.3 sampai 0.5
Besar
-1.0 sampai -0.5
0.5 sampai 1.0
2.1.3.3 Regresi Linier Berganda
Regresi linier berganda adalah regresi linier dengan satu variabel terikat Y dan lebih dari
1 variabel bebas X. Bentuk umum dari regresi linier berganda:
Y
=
ß
0
+
ß
1
X
1
+
ß
2
X
2
+
... +
ß
n
X
n
Rumus (2.3)
Untuk regresi linier berganda dengan 2 variabel X memiliki bentuk umum sebagai
berikut:
Y
=
ß
0
+
ß
1
X
1
+
ß
2
X
2
Rumus(2.4)
Nilai dari ß
0
dapat diperoleh dengan rumus:
^
^
^
ß
0
=
Y
-
ß
1
X
1
-
ß
2
X
2
Rumus (2.5)
|
 12
?
?
?
-
X
Y
-
Y
)
?
Sementara itu untuk ß
1
dan ß2
,
dapat diperoleh dari invers matrix (X
+
)’X
+
,
dengan X
+
adalah matriks dari regressor terpusat.
^
-1
?
+
+
?
+
+
ß
=
?
(
X
)
'
X
?
(
X
)
'Y
Nilai dari matriks (X
+
)’X
+
dan (X
+
)’Y
+
dapat diperoleh dari rumus berikut:
Rumus (2.6)
?
(
X
-
X
)2
(
X - X
)(
X
-
X
)
?
?
?
1
1
?
1
1
2
2
?
(
X
+
)
'
X
+
=
?
?
?
(
X
-
X
)(
X
-
X
)
(
X
-
X
)
2
?
?
?
1
1
2
2
?
2
2
?
?
?
(
X
+
)
'Y
+
?
?
(
X
1
1
)(
?
=
?
?
?
?
(
X
2
-
X
2
)(
Y
-
Y
)
?
?
?
Rumus (2.7)
2.1.4 Metode Kuadrat Terkecil
Perhitungan nilai ß
0
,
ß1
,
ß2, … ß
k
menggunakan metode kuadrat terkecil (least square
method) dengan persamaan sebagai berikut:
?
Y
i
= n
ß
0
+ß
1
?
X
i1
+
ß
2
?
X
i
2
+
... +
ß
k
?
X
ik
?
i
i1
0
?
i1
1
?
i 1
2
?
i
2 i1
k
?
ik
i1
YX = ß
X +ß
X
²
+
ß
X
X + ... +
ß
X
X
?
i
i
2
0
?
i
2
1
?
i1 i 2
2
?
i 2
k
?
ik
i
2
YX
=
ß
...
X
+ß
X X
+
ß
X
2
+
... +
ß
X
X
?
Y
i
X
ik
=
ß
0
?
X
ik
+ß
1
?
X
i1
X
ik
+
ß
2
?
X
i
2
X
ik
+
... +
ß
k
?
X
i
k
|
|
13
2.1.5 Tingkat Signifikansi
Tingkat signifikansi biasanya dilambangkan oleh simbol a. Tingkat signifikansi yang
biasa digunakan adalah 10% (0,1), 5% (0.05), 1% (0,01) dan 0,1% (0,001). Jika uji signifikansi
memberikan p-value yang lebih rendah daripada tingkat signifikansi a, hipotesis nol ditolak.
Hasil tersebut secara informal disebut sebagai signifikan secara statistik. Sebagai contoh, jika
seseorang berpendapat bahwa "hanya ada satu kesempatan dalam seribu ini bisa terjadi secara
kebetulan," tingkat 0,001 signifikansi statistik sedang tersirat. Semakin rendah tingkat
signifikansi, semakin kuat bukti-bukti yang dibutuhkan. Memilih tingkat signifikansi adalah
tugas yang bebas, tetapi untuk kebanyakan aplikasi, level 5% yang dipilih.
2.1.6 SPSS
SPSS adalah program komputer yang digunakan untuk analisis statistik. Antara 2009 dan
2010 perangkat lunak utama untuk SPSS disebut PASW (Predictive Analytics Software)
Statistics. Pada tanggal 28 Juli 2009 perusahaan ini diakuisisi oleh IBM sebesar US $ 1,2 miliar.
Pada Januari 2010, namanya berubah menjadi "SPSS: An IBM Company".
SPSS (pada mulanya, Statistical Package for the Social Sciences) diluncurkan pada versi
pertama pada tahun 1968 setelah dikembangkan oleh Norman H. Nie dan C. Hadlai Hull.
Norman Nie yang kemudian menjadi master ilmu politik di Stanford University, dan sekarang
telah menjadi Profesor Riset di Departemen Ilmu Politik di Stanford dan Profesor Emeritus Ilmu
Politik di Universitas Chicago. SPSS adalah salah satu program yang paling banyak digunakan
untuk analisis statistik dalam ilmu sosial. Hal ini digunakan oleh peneliti pasar, peneliti
kesehatan, perusahaan survei, pemerintah, peneliti pendidikan, organisasi pemasaran dan lain-
lain. Manual SPSS asli (Nie, Bent & Hull, 1970) telah digambarkan sebagai salah satu "buku
sosiologi paling berpengaruh". Selain analisis statistik fitur lain SPSS adalah manajemen data
|
|
14
(seleksi kasus, file membentuk kembali, membuat data turunan) dan dokumentasi data (kamus
metadata disimpan di datafile itu).
Fitur statistik yang termasuk dalam software ini adalah:
•
Statistika deskriptif: Cross tabulation, Frequencies, Descriptives, Explore, Descriptive
Ratio Statistics
•
Statistika Bivariat: Rata-rata, t-test, ANOVA, Korelasi (bivariat, parsial, jarak), test
nonparametrik
•
Prediksi data numerik: Regresi linier
•
Prediksi data berkelompok: Analisis faktor, Analisis cluster (two-step, K-means,
hierarchical), Diskriminan
2.1.7 Faktor-Faktor yang Mempengaruhi Performa Kerja Karyawan
Dewasa ini, masalah rendahnya produktivitas kerja menjadi fokus perhatian pada hampir
semua institusi di Indonesia. Hal ini dapat dilihat dari berbagai aspek faktual yang muncul,
misalnya: terjadinya pemborosan sumberdaya (inefisiensi) dan ketidaktercapaian target, baik
secara kelompok maupun individual.
Masalah produktivitas kerja dalam suatu organisasi merupakan faktor yang penting,
terutama bila dihubungkan dengan masalah penggunaan sumber daya input. Menurut
Muchdarsyah, secara umum produktivitas suatu organisasi dipengaruhi oleh manusia, modal,
metode (proses), produksi, umpan balik, lingkungan internal organisasi, dan lingkungan
eksternal(baik lokal, regional, nasional, maupun internasional).
Faktor-faktor yang mepengaruhi performa kerja karyawan:
a. Pekerjaan yang menarik.
b. Upah yang baik.
|
|
15
c. Keamanan dan perlindungan dalam pekerjaan.
d. Penghayatan atas maksud dan makna pekerjaan.
e. Lingkungan atau suasana kerja yang baik.
f.
Promosi dan perkembangan diri merasa sejalan dengan perkembangan perusahaan /
organisasi.
g. Merasa terlibat dalam kegiatan organisasi-organisasi.
h. Pengertian dan simpati atas persoalan-persoalan pribadi.
i.
Kesetiaan pimpinan pada diri si pekerja.
j.
Disiplin kerja yang keras.
2.1.8 C++ Programming Language
C++ adalah bahasa pemrograman komputer C++ dikembangkan di Bell Labs (Bjarne
Stroustrup) pada awal tahun 1970-an, Bahasa itu diturunkan dari bahasa sebelumnya, yaitu BCL,
Pada awalnya, bahasa tersebut dirancang sebagai bahasa pemrograman yang dijalankan pada
sistem Unix, Pada perkembangannya, versi ANSI (American National Standart Institute) Bahasa
pemrograman C menjadi versi dominan, Meskipun versi tersebut sekarang jarang dipakai dalam
pengembangan sistem dan jaringan maupun untuk sistem embedded, Bjarne Stroustrup pada Bell
labs pertama kali mengembangkan C++ pada awal 1980-an, Untuk mendukung fitur-fitur pada
C++, dibangun efisiensi dan sistem support untuk pemrograman tingkat rendah (low level
coding). Pada C++ ditambahkan konsep-konsep baru seperti class dengan sifat-sifatnya seperti
inheritance dan overloading. Salah satu perbedaan yang paling mendasar dengan bahasa C
adalah dukungan terhadap konsep pemrograman berorientasi objek (Object Oriented
Programming).
|
|
16
Perbedaan Antara Bahasa pemrograman C dan C++ meskipun bahasa-bahasa tersebut
menggunakan sintaks yang sama tetapi mereka memiliki perbedaan, C merupakan bahasa
pemrograman prosedural, dimana penyelesaian suatu masalah dilakukan dengan membagi-bagi
masalah tersebut kedalam su-submasalah yang lebih kecil, Selain itu, C++ merupakan bahasa
pemrograman yang memiliki sifat Pemrograman berorientasi objek, Untuk menyelesaikan
masalah, C++ melakukan langkah pertama dengan menjelaskan class-class yang merupakan anak
class yang dibuat sebelumnya sebagai abstraksi dari object-object fisik, Class tersebut berisi
keadaan object, anggota-anggotanya dan kemampuan dari objectnya, Setelah beberapa Class
dibuat kemudian masalah dipecahkan dengan Class.
Untuk mengubah kode-kode C++ program menjadi suatu program aplikasi yang
dimengerti oleh sistem operasi dan komputer, diperlukan sebuah kompilator C++. Berikut ini
adalah beberapa kompilator C++ yang dapat digunakan secara gratis,
*
Microsoft Visual C++ Express
* Turbo C++ Explorer
* Apple Xcode for Mac OS X
* Open Source Watcom / OpenWatcom C/C++ Compiler
* Digital Mars C/C++ Compiler (Symantec C++ Replacement)
* Bloodshed Dev-C++ C++ Compiler
* Free Microsoft .NET Framework Software Development Kit (SDK) / Free Microsoft
Visual C++ Compiler
* Intel C++ Compiler for Linux Non-Commercial Version
* Sun Studio Compilers and Tools
* Open64 Compiler Tools
|
|
17
* Apple's Macintosh Programmer's Workshop (C and C++ compilers)
* TenDRA C/C++ Compiler
* GNU C/C++ Compiler
* Ch Embeddable C/C++ Interpreter (Standard Edition)
* DJGPP C and C++ Compilers
* CINT C and C++ Interpreter
* SDCC C Cross-compiler
* Cygwin Project (C & C++ Compilers)
* SDCC C Cross-compiler
2.1.9 Microsoft Visual Studio
Microsoft Visual Studio merupakan sebuah perangkat lunak lengkap (suite) yang dapat
digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal,
ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun
aplikasi Web. Visual Studio mencakup kompiler, SDK, Integrated Development Environment
(IDE), dan dokumentasi (umumnya berupa MSDN Library). Kompiler yang dimasukkan ke
dalam paket Visual Studio antara lain Visual C++, Visual C#, Visual Basic, Visual Basic .NET,
Visual InterDev, Visual J++, Visual J#, Visual FoxPro, dan Visual SourceSafe.
Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native
code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam
bentuk Microsoft Intermediate Language di atas .NET Framework). Selain itu, Visual Studio
juga dapat digunakan untuk mengembangkan aplikasi Silverlight, aplikasi Windows Mobile
(yang berjalan di atas .NET Compact Framework).
|
|
18
Visual Studio kini telah menginjak versi Visual Studio 9.0.21022.08, atau dikenal dengan
sebutan Microsoft Visual Studio 2008 yang diluncurkan pada 19 November 2007, yang
ditujukan untuk platform Microsoft .NET Framework 3.5. Versi sebelumnya, Visual Studio 2005
ditujukan untuk platform .NET Framework 2.0 dan 3.0. Visual Studio 2003 ditujukan untuk
.NET Framework 1.1, dan Visual Studio 2002 ditujukan untuk .NET Framework 1.0. Versi-versi
tersebut di atas kini dikenal dengan sebutan Visual Studio .NET, karena memang membutuhkan
Microsoft .NET Framework. Sementara itu, sebelum muncul Visual Studio .NET, terdapat
Microsoft Visual Studio 6.0 (VS1998).
2.2 Kajian Penelitian Terdahulu
Ada cukup banyak penelitian yang telah dilakukan dengan melakukan survey dan
mengolah datanya menggunakan regresi linier untuk pengolahan datanya. Berikut adalah
beberapa jurnal yang pernah dilihat oleh penulis:
•
Alcohol Retail Density and Demographic Predictors of Health Disparities: A Geographic
Analysis, yang dilakukan oleh Ethan M. Berke, MD, MPH, Susanne E. Tanski, MD,
Eugene Demidenko, PhD, Jennifer Alford-Teaster, MA, Xun Shi, PhD, dan James D.
Sargent, MD di Amerika pada tahun 2010.
•
The relationship between unimanual capacity and bimanual performance in children with
congenital hemiplegia, yang dilakukan oleh Leanne Sakzewski, Jenny Ziviani, dan
Roslyn Boyddi Australia pada tahun 2009.
•
The Relationship between Parental Corporal Punishment, Frustration Tolerance, And
Cognitive Development, yang dilakukan oleh William F. Gordon di Amerika pada tahun
2005.
|
|
19
•
Influence of breast cancer histology on the relationship between ultrasound and
pathology tumor size measurements, yang dilakukan oleh Bobbi Pritt, Takamaru
Ashikaga, Robert G Oppenheimer, dan Donald L Weaver di Amerika pada tahun 2004
•
Stock Market Forecasting: Artificial Neural Network And Linear Regression Comparison
In An Emerging Market, yang dilakukan oleh Erdinç Altay dan M Hakan Satman di Turki
pada tahun 2005
|