|
BAB 2
LANDASAN TEORI
2.1
Database
2.1.1
Pengertian Database
Menurut Connolly dan Begg (2002, p15)¸ database merupakan
suatu kumpulan data
logikal yang berhubungan satu sama lain dan
deskripsi dari suatu data yang dirancang sebagai informasi yang
dibutuhkan oleh organisasi, sedangkan menurut McLeod dan Schell (2004,
p196), database adalah kumpulan seluruh sumber data berbasis komputer
milik
organisasi. Database yang dikendalikan oleh
sistem
manajemen
database adalah suatu set catatan data
yang
berhubungan
dan
saling
menjelaskan.
Jadi, database adalah kumpulan data yang saling berhubungan
secara logis dan terintegrasi dimana dapat digunakan sebagai sumber
kebutuhan sebuah organisasi.
8
|
|
9
2.1.2 Relational Database
Relational database adalah
representasi
logikal
dari
data.
Data
tersebut dapat diakses tanpa ada ketergantungan dengan struktur fisik dari
database
tersebut.
Relational
database
merupakan sistem
database
yang
paling
banyak
dipakai
saat
ini.
Salah
satu
bahasa
yang
sering
dipakai
untuk
memanipulasi
data
adalah
SQL.
Data
dalam relational
database
disimpan di dalam sebuah tabel dimana terdapat kolom dan baris.
2.2
Data Warehouse
2.2.1
Pengertian Data Warehouse
Menurut Inmon (2005, p389), data warehouse adalah sekumpulan
data yang bersifat subject-oriented, integrated, time-variant
dan non-
volatile untuk mendukung proses pengambilan keputusan.
Menurut
Mcleod dan Schell (2004, p205), data warehouse adalah
perkembangan dari konsep database yang menyediakan suatu sumber
data, data yang lebih baik bagi para pemakai dan memungkinkan pemakai
untuk memanipulasi dan
menggunakan data tersebut secara intuitif.
Data
warehouse
berukuran
sangat
besar, kualitas
datanya
tinggi,
dan
sangat
mudah diambil datanya.
Jadi, data warehouse adalah tempat penyimpanan data historis
yang berorientasi subjek untuk
mendukung proses pengambilan
keputusan.
|
 10
2.2.2
Karakteristik Data Warehouse
Seperti yang telah dikemukakan terlebih dahulu pada sub bagian
pengertian
data
warehouse,
karakteristik
yang
harus
dimiliki
dalam
sebuah data
warehouse antara
lain adalah Subject
Oriented,
Integrated,
Time
Variant,
dan
Non
Volatile. Berikut
ini
dijelaskan lebih
lanjut
mengenai karakteristik ini.
•
Subject Oriented
Data warehouse
berorientasi
subjek
artinya data
warehouse
dirancang
untuk
menganalisis data berdasarkan subjek
–
subjek
tertentu dalam organisasi, bukan pada proses atau fungsi aplikasi
tertentu.
Gambar 2. 1 Subject Orientation Data (Inmon, 2005, p30)
|
 11
•
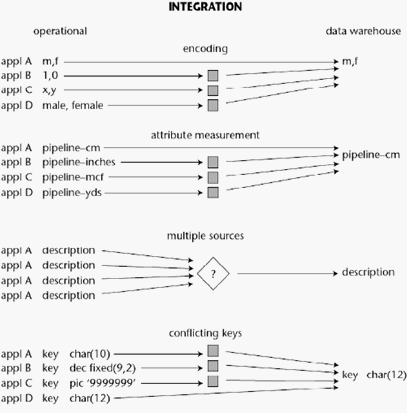
Integrated
Sumber
data berasal
dari
sistem –
sistem
aplikasi perusahaan
yang
berbeda
–
beda.
Sumber
data sering tidak konsisten misalnya
perbedaan
format
data.
Integrasi sumber data
harus
dibuat
konsisten
dalam menampilkan
data
agar
dapat
menyatukan
pandangan user
terhadap data.
Gambar 2. 2 Integration (Inmon, 2005, p31)
|
 12
•
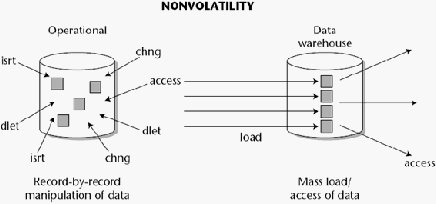
Non volatile
Karakteristik ketiga dari data warehouse adalah non volatile,
yaitu data pada data warehouse
cenderung statis dan berupa data
historical yang digunakan untuk analisis.
Pada gambar 2.3 ini, Inmon (2005, p31-p32) menjelaskan
bahwa
“Data
operasional
pada
tiap
–
tiap record
yang
ada,
umum
diakses dan dimanipulasi, perubahan maupun pembaruan data
merupakan sebuah hal
yang wajar dilakukan pada sistem ini. Namun,
data warehouse
juga dapat
diakses, namun tidak terlalu sering, dan
biasanya diambil dalam jumlah besar. Akan tetapi data yang ada tidak
diperkenankan untuk diperbaharui maupun diubah, apabila terjadi
perubahan
atau
pembaruan,
maka
data
tersebut
akan
masuk
sebagai
data baru. Oleh karena itu, data
yang
tersimpan
pada
sebuah
data
warehouse merupakan data yang bersifat historis”.
Gambar 2. 3 Non Volatile (Inmon, 2005, p32)
|
|
13
•
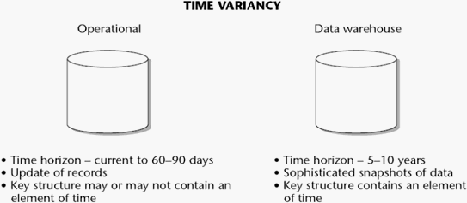
Time Variant
Data warehouse
dibandingkan dengan data operasional,
memiliki
perbedaan
cakupan
pada
aspek time variant. Time
variant
yang membedakan antara data pada data warehouse dengan data
operasional menurut Ponniah (2001, p22) adalah “Data yang disimpan
pada sistem operasional
merupakan keadaan terkini pada perusahaan.
Data
transaksi
lampau
juga
ada yang disimpan,
namun
pada
intinya
sistem
operasi
dirancang
memang
untuk
mendukung
operasi
harian
dari perusahaan sehingga data yang tersimpan harus mencerminkan
keadaan
terkini perusahaan.
Namun
pada data warehouse, data
yang
digunakan merupakan data untuk analisis dan pengambilan keputusan.
Dari
tujuan inilah
data yang
dimiliki
oleh
sebuah
data
warehouse
haruslah berupa data historis, bukan sekedar keadaan terkini dari
perusahaan. Data disimpan sebagai gambaran keadaan perusahaan di
masa
lampau hingga
saat
ini.”
Masih
menurut Ponniah
(2001, p23),
time variant memiliki keuntungan sebagai berikut:
•
Memungkinkan
untuk
menganalisis
hal
yang
terjadi
di
masa
lampau
•
Menghubungkan informasi yang ada ke masa kini
•
Memungkinkan adanya perkiraan atau ramalan
mengenai kondisi
masa yang akan datang.
|
 14
Gambar 2. 4 Time Variant (Inmon, 2005, p33)
|
|
15
2.2.3
Kegunaan Data Warehouse
Data warehouse yang digunakan selama ini memberikan
kemudahan dan keuntungan, karena data warehouse biasanya digunakan
untuk melakukan empat tugas berbeda. Menurut Williams dan Sawyer
(2007, p533), keempat tugas data warehouse
tersebut
adalah sebagai
berikut:
a. Pembuatan laporan
Pembuatan laporan merupakan salah satu kegunaan
data
warehouse yang
paling
umum.
Dengan
menggunakan query
–
query
sederhana dalam data warehouse, dapat dihasilkan informasi per
tahun, per kuartal, per bulan bahkan per hari.
b. Online Analytical Processing (OLAP)
Data warehouse digunakan dalam melakukan analisis bisnis untuk
mengetahui
kecenderungan
pasar
dan faktor –
faktor penyebabnya,
karena
dengan
adanya data
warehouse
semua
informasi
baik
detil
maupun hasil ringkasan yang dibutuhkan dalam proses analisis mudah
didapat.
Dalam hal
ini data
warehouse
merupakan tool
yang
handal
untuk analisis data yang kompleks. Menurut Connolly dan Begg
(2002, p1153), sebuah organisasi
menerapkan beberapa sistem OLTP
yang berbeda untuk menjalankan proses bisnis seperti kendali
inventori, invoicing, dan point-of-sale.
Sistem ini
menghasilkan
data
operasional yang mendetil, up-to-date, dan dapat diubah – ubah. Data
di dalam OLTP, diorganisir berdasarkan kebutuhan transaksi yang
|
|
16
berhubungan dengan aplikasi bisnis serta mendukung pengambilan
keputusan operasional harian.
c. Data mining
Penggunaan data warehouse dalam pencarian pola dan hubungan
data, dengan tujuan membuat keputusan bisnis bagi para pihak
manajemen.
Dalam hal
ini,
perangkat
lunak
dirancang
untuk
pola
statistik dalam data untuk mengetahui kecenderungan yang ada,
misalnya kecenderungan pasar akan suatu produk tertentu.
d. Proses Informasi Eksekutif
Data
warehouse
digunakan
untuk
mencari
informasi summary
kunci yang penting, dengan tujuan membuat keputusan bisnis, tanpa
harus menjelajahi keseluruhan data yang ada.
2.2.4
Anatomi Data Warehouse
Menurut Inmon (2005, p193) anatomi data warehouse adalah data
warehouse fungsional, data
warehouse
terpusat
dan
data
warehouse
terdistribusi.
•
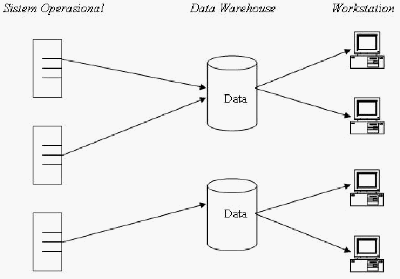
Data Warehouse Fungsional
Data
warehouse
fungsional menggunakan pendekatan
kebutuhan
dari
tiap
bagian
dari fungsi
bisnis
yang
ada.
Misalnya
departemen atau divisi, untuk mendefinisikan jenis data yang
ditampung oleh sistem. Setiap unit fungsi dapat memiliki gambaran
data masing – masing.
|
 17
Pendekatan ini banyak digunakan karena
sistem
memberikan
solusi yang mudah untuk dibangun dengan biaya investasi yang relatif
rendah
dan dapat
memberikan kemampuan
sistem
pengumpulan
data
yang terbatas kepada kelompok pemakai.
Penerapan
jenis sistem pengumpulan
data
seperti
ini beresiko
kehilangan konsistensi data di luar
lingkungan
fungsi
bisnis
yang
bersangkutan. Bila lingkup pendekatan ini diperbesar dari lingkungan
fungsional menjadi lingkup perusahaan, konsistensi data perusahaan
tidak lagi dapat terjamin.
Gambar 2. 5 Data Warehouse Fungsional (Prabowo, 1996)
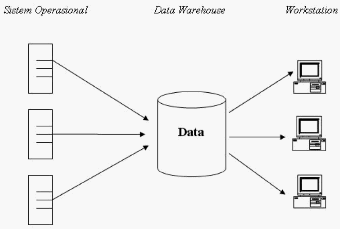
•
Data Warehouse Terpusat
Data warehouse terpusat
adalah pendekatan yang paling baik
digunakan. Hal ini dikarenakan oleh keterbiasaan pengguna dengan
lingkungan mainframe terpusat. Data diambil dari seluruh sistem
|
 18
operasional dan disimpan di dalam pusat penyimpanan data. Pengguna
kemudian menggunakan data yang telah terkumpul tersebut untuk
membangun data warehouse
fungsional, masing –
masing sesuai
dengan kebutuhannya.
Keuntungan
sistem ini
dibanding
dengan
data
warehouse
fungsional
adalah
bahwa
data benar
–
benar
terintegrasi.
Sistem ini
mengharuskan data dikirim tepat pada waktunya, agar tetap konsisten
dengan pemasok data lainnya. Di samping itu, pengguna
hanya dapat
mengambil data dari pusat pengumpulan saja dan tidak dapat
berhubungan secara langsung dengan pemasok datanya sendiri.
Gambar 2. 6 Data Warehouse Terpusat (Prabowo, 1996)
Penerapan
sistem ini
membutuhkan
biaya
pemeliharaan
yang
tinggi atas sistem pengumpulan data yang besar. Selain itu diperlukan
waktu yang lama untuk membangun sistem tersebut.
|
 19
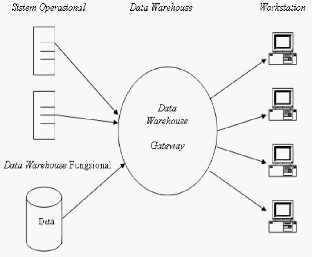
•
Data Warehouse Terdistribusi
Data warehouse terdistribusi dikembangkan berdasarkan
konsep
gateway data warehouse, sehingga memungkinkan pengguna
dapat langsung berhubungan dengan sumber data atau pemasok data
maupun dengan pusat pengumpul data lainnya. Gambaran pengguna
atas
data
adalah
gambaran
logika karena data mungkin diambil dari
berbagai sumber yang berbeda.
Gambar 2. 7 Data Warehouse Terdistribusi (Prabowo, 1996)
Pendekatan
ini
menggunakan
teknologi
client / server
untuk
mengambil data dari berbagai sumber, sehingga memungkinkan tiap
departemen
atau
divisi
untuk
membangun
sistem operasionalnya
sendiri serta dapat membangun pengumpul data fungsionalnya masing
–
masing dan menggabungkan bagian – bagian tersebut dengan
teknologi client / server. Pendekatan
ini
akan
menjadi sangat efektif
|
|
20
bila data tersedia dalam bentuk yang konsisten dan pengguna dapat
menambah data tersebut dengan informasi baru apabila ingin
membangun gambaran baru atas informasi.
Penerapan data warehouse terdistribusi ini memerlukan biaya
yang sangat besar karena setiap pengumpul data fungsional dan sistem
operasinya dikelola secara
terpisah.
Selain
itu,
agar
berguna
bagi
perusahaan,
data
yang
ada
harus
disinkronisasikan
untuk
memelihara
keterpaduan data.
2.2.5
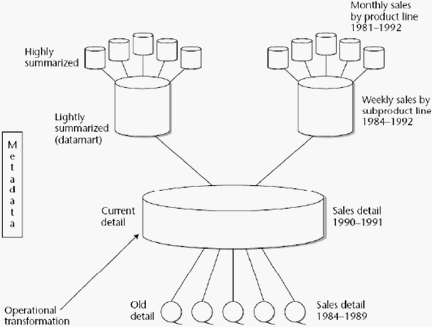
Struktur Data Warehouse
Inmon (2005, p34) mengutarakan pendapat mengenai struktur dari
data warehouse sebagai berikut, “Ada beberapa tingkatan detail pada
lingkungan data warehouse. Tingkatan ini dikategorikan menjadi 4, yaitu:
Older Detail Level, Current Detail Level, Lightly Summarized Data Level,
dan Highly Summarized Data Level.
Aliran data awalnya terjadi dari environment
operasional
menuju
environment data warehouse. Pada aliran data inilah proses transformasi
terjadi.
Aliran data pada data warehouse selanjutnya berada pada
tingkatan detail. Seiring berjalannya waktu, data dari Current Detail Level
mengalir menuju Older Detail Level. Apabila terjadi summarize, data akan
beralih dari Current Detail Level menuju Lightly Summarized Data Level
yang kemudian akan menuju Highly Summarized Data Level.
|
 21
Gambar 2. 8 Struktur Data Warehouse (Inmon, 2005, p34)
2.2.5.1 Current Detail Data
Current Detail Data berisi data yang mencerminkan
keadaan yang sedang berjalan saat ini dan merupakan level
terendah dari data warehouse. Oleh karena itu, data di
tingkat ini belum efisien untuk digunakan sekalipun
datanya lengkap/ detail. Hal ini dikarenakan terlalu
rumit/
kompleks
untuk
melakukan
analisis dengan data yang
banyak.
2.2.5.2 Older Detail Data
Older detail data merupakan data history dari suatu
perusahaan yang berupa hasil backup yang disimpan dalam
media penyimpanan dengan frekuensi akses yang relatif
|
|
22
rendah. Data pada tingkat ini biasanya berupa backup data
dari kurun waktu lama, misalnya dalam ukuran tahunan dan
sudah
hampir
tidak
pernah diakses lagi. Namun
penyusunan directory untuk data ini harus mencerminkan
umur dari data agar mudah untuk pengaksesan kembali.
2.2.5.3 Lightly Summarized Data
Lightly summarized data
merupakan data hasil
ringkasan atau summary dari current detailed data. Pada
tingkat
ini,
data
hasil
ringkasan
masih
belum dapat
digunakan
dalam proses
pengambilan
keputusan
karena
belum bersifat
“total summary”
dan
masih
bersifat
detail.
Lightly summarized data biasanya sering digunakan untuk
gambaran dari keadaan yang sedang berlangsung dan sudah
berlangsung.
2.2.5.4 Highly Summarized Data
Highly summarized data
merupakan hasil proses
summary yang bersifat “totalitas”. Data pada highly
summarized ini sangat mudah diakses. Data pada tingkat
inilah yang pada akhirnya dapat digunakan untuk
mendukung pengambilan keputusan terutama di kalangan
eksekutif perusahaan. Hal ini disebabkan karena data pada
tingkat ini dianggap sudah cukup representatif dan ringkas.
Akan tetapi data ini tetap dapat merepresentasikan keadaan
|
 23
data
secara keseluruhan.
Hal
ini
tentu
saja
sangat
memudahkan kalangan eksekutif karena tidak perlu lagi
membaca
dan
melakukan analisis data
untuk
waktu
yang
cukup lama.
2.2.6
Arsitektur Data Warehouse
Dalam melakukan perancangan data warehouse,
harus ditentukan
terlebih dahulu arsitektur yang paling cocok untuk melakukan
pengembangan data warehouse. Connolly dan Begg (2002, p1053)
memberikan suatu
gambaran typical arsitektur dari data warehouse, yaitu
sebagai berikut:
Gambar
2.9
Typical
Architecture
of
a
Data
Warehouse
(Connolly dan Beg, 2002, p1053)
|
|
24
Connolly dan Begg (2002, p1156-1161) mengidentifikasi
komponen data warehouse yang terdapat pada arsitektur data warehouse,
yaitu:
1. Operational Data
Data operasional berfokus pada fungsi – fungsi transaksional. Data
ini merupakan bagian dari infrastruktur perusahaan, detil, tidak ada
redudansi
(data
tidak
berulang
–
ulang),
dapat
di-update (diubah –
ubah), dan data ini merefleksikan nilai sekarang.
2. Operational Data Source (ODS)
ODS adalah tempat penyimpanan sementara dari data operasional
saat
ini
yang
terintegrasi
yang digunakan
untuk analisis. Membangun
ODS dapat
merupakan
tahap
yang berguna dalam membangun
data
warehouse karena sebuah ODS dapat menyuplai data yang sudah
diekstrak
dari
sistem sumber
dan
dibersihkan.
Ini
berarti
pekerjaan
mengintegrasi
dan
merestrukturisasi
data
untuk data
warehouse
menjadi lebih sederhana.
3. Load manager
Load manager menampilkan semua operasi yang terkait dengan
ekstraksi
dan
loading
data
ke
dalam data
warehouse. Data
bisa saja
diekstrak
secara
langsung
dari
sumber
data
atau
secara
umum dari
ODS.
|
|
25
4. Warehouse manager
Warehouse manager
menampilkan
semua
operasi
yang
terkait
dengan
manajemen
data
dari data warehouse. Operasi yang
ditampilkan oleh warehouse manager meliputi:
a. Analisis data untuk menjamin konsistensi.
b. Transformasi
dan
penggabungan
sumber
data
dari
tempat
penyimpanan sementara ke tabel data warehouse.
c. Pembuatan indeks dan view pada tabel base.
d. Membuat denormalisasi (jika perlu).
e. Membuat agregasi (jika perlu).
f.
Backing-up dan archiving data.
5. Query manager
Query manager
menampilkan semua operasi yang terkait dengan
manajemen query pengguna. Operasi yang ditampilkan oleh
komponen ini meliputi mengarahkan query pada tabel yang cocok dan
menjadwalkan pelaksanaan query.
6. Detailed data
Komponen
ini
menyimpan
semua
detail
data
dalam
skema
database. Detail data terbagi 2 yaitu:
a. Current detail data
Data
ini
berasal
langsung
dari
operasional
database
dan selalu
mengacu pada data perusahaan sekarang. Current detail data
diatur
sepanjang
sisi –
sisi
subjek
seperti
data
profil pelanggan,
|
|
26
data aktivitas pelanggan,
data sales,
data
demografis, dan
lain –
lain.
b. Old detail data
Data ini menampilkan current detail data yang berumur atau
histori dari subyek area. Data ini yang dipakai untuk menganalisis
trend yang akan dihasilkan.
7. Lightly and highly summarized data
Area data warehouse ini menyimpan semua data lightly dan highly
summarized yang sudah terdefinisi sebelumnya yang dibuat oleh
warehouse
manager.
Tujuan
informasi
yang
terangkum ini
adalah
meningkatkan performansi query.
8. Archive / backup data
Area warehouse
ini menyimpan detail data dan summarized data
dengan tujuan mengarsip dan melakukan backup data.
9. Metadata
Metadata
merupakan data mengenai data yang mendeskripsikan
data warehouse. Metadata digunakan untuk membangun, memelihara,
mengatur, dan
menggunakan data warehouse. Metadata mengandung
lokasi dan deskripsi dari komponen –
komponen data warehouse;
nama,
definisi,
struktur,
dan
isi
dari
data
warehouse
dan
end
user
view; identifikasi dari pembuat sumber – sumber data (record system);
aturan –
aturan integrasi dan transformasi yang digunakan untuk
mempopulasikan data warehouse; history dari update dan refresh data
|
|
27
warehouse; pola – pola matriks
yang digunakan untuk performa
menganalisis data warehouse; dan seterusnya.
10. End – user access tool
Tool ini mencakup:
a. Reporting and query tool
Reporting
tools
meliputi
production
reporting
tools dan
report
writers. Productions reporting tools
digunakan untuk
menghasilkan laporan operasional yang teratur atau untuk
mendukung sejumlah pekerjaan dengan volume yang tinggi seperti
pesanan pelanggan dan pembayaran karyawan.
Query tool untuk data warehouse
relasional
dirancang
untuk dapat menerima
SQL atau untuk menghasilkan pernyataan
SQL agar dapat melakukan query pada data yang disimpan di
dalam warehouse.
Query tool sangat populer
di
antara pengguna
bisnis aplikasi.
b. Application development tool
Kebutuhan –
kebutuhan end-users seperti
membangun
kemampuan
untuk
membuat
laporan
dan query
tools
keduanya
sangat tidak memadai karena analisis yang dibutuhkan tidak dapat
dijalankan. Dalam situasi seperti ini, pengguna akan membutuhkan
application development tools
yang dirancang untuk kebutuhan
client-server.
c. Executive information system (EIS) tool
|
|
28
Executive Information System sebenarnya
dikembangkan
untuk mendukung pengambilan keputusan tingkat tinggi. Namun,
semakin
meluas
untuk
mendukung semua
tingkat
pengelolaan.
Sekarang
ini batasan perbedaan antara
EIS dan
decision support
tools lainnya
semakin
tidak
jelas
karena
para
pengembang
EIS
menambahkan
fasilitas query
tambahan dan
menyediakan custom-
built application untuk bisnis adalah seperti penjualan, pemasaran,
dan keuangan.
d. Online analytical processing (OLAP) tool
Online
Analytical
Processing
Tools merupakan
konsep
database
multidimensi
dan
mengijinkan pengguna
untuk
menganalisis data menggunakan view yang kompleks dan
multidimensi.
Contoh
–
contoh
bisnis
aplikasi
OLAP
meliputi
penilaian keefektifan strategi pemasaran, prediksi penjualan
produk, kapasitas perencanaan.
e. Data mining tool
Data mining adalah proses menemukan korelasi, pola, dan
gaya baru yang bermanfaat dengan ‘menggali’ (mining) data dalam
jumlah yang banyak dengan menggunakan teknik statistika,
matematika, intelejensia semu.
|
|
29
2.2.7
Aliran Data Pada Data Warehouse
Data warehouse memfokuskan pada manajemen dari lima aliran
data utama yaitu inflow, upflow, downflow, outflow, dan meta-flow. Proses
yang
berasosiasi
dengan
setiap
aliran data (Connolly dan Begg, 2005,
p1161), yaitu:
a.
Inflow: Proses yang berhubungan dengan pengekstrakan (extraction),
pembersihan (cleansing),
dan
pemuatan
(loading) data
dari
sistem –
sistem sumber ke dalam data warehouse.
b. Upflow: Proses yang berhubungan dengan penambahan nilai dari data
dalam
data warehouse
melalui peringkasan (summarizing),
pengemasan (packaging), dan pendistribusian data.
c. Downflow: Proses yang berhubungan dengan pengarsipan (archiving)
dan pembuatan cadangan (back-up) data dalam data warehouse.
d. Outflow:
Proses
yang
berhubungan
dengan pengadaan
data agar
tersedia bagi end-user.
e. Meta-flow:
Proses
yang
berhubungan
dengan
manajemen
dari
metadata.
|
|
30
2.2.8
Tahapan Perancangan Data Warehouse
Menurut Kimball dan Ross (2010, p210), diperlukan sembilan
tahapan dalam membangun data warehouse. Sembilan langkah (Nine-Step
Methodology) tersebut, yaitu:
•
Choosing the process
Memilih
proses
(fungsi)
bisnis
yang
merujuk
pada
subyek
masalah
atau kebutuhan bisnis dan menganalisa data yang tersedia pada
perusahaan.
•
Choosing the grain
Memilih
grain
memilih
secara
tepat apa yang
direpresentasikan
oleh
record tabel fakta. Grain adalah setiap baris item individual yang ada
di
dalam tabel
fakta.
Ketika
grain
telah
dipilih,
pemilihan
dimensi
sesuai proses bisnis dapat dilakukan.
•
Identifying and conforming the dimensions
Tabel dimensi menyiapkan konteks untuk menanyakan pertanyaan
tentang
fakta
yang ada di dalam tabel fakta. Kumpulan dimensi
yang
dibuat dengan baik akan mempermudah dalam pemahaman serta
menggunakan data mart. Kemudian mengidentifikasikan detail
dimensi yang secukupnya untuk menggambarkan klien dan properti
pada grain yang tepat.
•
Choosing the facts
Grain dari tabel fakta menentukan fakta mana yang bisa dipakai dalam
proses bisnis
yang ditentukan. Semua
fakta
harus dinyatakan secara
|
|
31
pasti oleh grain.
Dengan kata
lain, jika
grain merupakan setiap baris
item individual
pada
tabel
fakta, maka
fakta
adalah
numerik
yang
mengacu pada baris item tertentu.
•
Storing pre-calculations in the fact table
Setelah fakta-fakta yang telah dipilih masing-masing harus dikaji
ulang untuk menentukan apakah ada peluang untuk menggunakan pre-
calculations. Sebuah contoh umum dari kebutuhan untuk menyimpan
pre-calculations terjadi ketika fakta – fakta terdiri dari keuntungan dan
kekurangan.
•
Rounding out the dimension tables
Pada tahap ini, kita kembali ke dalam tabel dimensi dan menambahkan
deskripsi pada tabel dimensi sebanyak – banyaknya. Deskirpsi harus
jelas dan mudah dimengerti.
•
Choosing the duration of database
Memilih durasi database adalah mengukur seberapa lama tabel fakta
tersebut disimpan. Sebagian besar perusahaan, mempunyai kebutuhan
untuk melihat data pada periode tertentu dalam jangka waktu satu atau
dua tahun. Untuk tipe perusahaan lainnya,
seperti
asuransi,
mungkin
membutuhkan data yang periodenya lebih lama yaitu sekitar lima atau
lebih dari lima tahun.
•
Tracking slowly changing dimensions
Perubahan dimensi dapat terjadi dengan seiring berjalannya waktu
pada tabel dimensi. Perubahan yang dimaksud adalah penambahan
|
|
32
data
(insert)
ataupun
perubahan
data
(update).
Untuk
mengatasinya
ada tiga tipe Slowly Changing Dimension (SCD) yaitu :
1. Menulis ulang semua atribut dimensi yang berubah.
2. Menambah atribut dimensi yang berubah menyebabkan record
dimensi baru dibuat.
3. Perubahan atribut dimensi menyebabkan atribut alternatif dibentuk
sehingga baik nilai yang lama dan yang baru dapat di akses secara
bersamaan pada tabel dimensi yang sama.
•
Deciding the query priorities and the query modes
Dalam langkah
ini,
memperkirakan untuk
membuat rancangan fisikal.
Yang
paling
penting
dalam rancangan
fisikal
yang
mempengaruhi
persepsi data mart end-user’s adalah urutan dari perintah fisikal yang
ada
dalam tabel
dan
ketersediaan
ringkasan.
Dibalik
semua
ini
ada
tambahan
rancangan
fisikal
yang
mempengaruhi administration,
backup, indexing performance, dan security.
2.3
Tabel Fakta
Fakta adalah sebuah
ukuran dari kinerja bisnis, biasanya berupa angka –
angka dan penjumlahan (Kimball dan Ross, 2002, p402).
Menurut Kimball dan Ross, tabel fakta pada sebuah skema bintang ialah
tabel pusat dengan pengukuran performa bisnis dalam bentuk angka
yang
memiliki
karakteristik yang
berupa composite
key,
yang tiap -
tiap
elemennya
adalah
foreign key yang didapat dari
tabel dimensi. Sedangkan menurut Inmon
|
|
33
(2005,
p497)
tabel
fakta
adalah
pusat
dari
tabel
star join dimana data
dengan
banyak kepentingan disimpan.
2.4
Tabel Dimensi
Dimensi adalah sebuah entitas independent
pada
sebuah
model
dimensional yang berfungsi sebagai pintu masuk atau mekanisme untuk memecah
–
mecah pengukuran tambahan yang ada pada tabel fakta dari model dimensional
(Kimball dan Ross, 2002, p399).
Pengertian tabel dimensi menurut Kimball dan Ross adalah sebuah tabel
pada
model dimensional
yang
memiliki sebuah
primary key tunggal dan kolom
dengan atribut deskriptif. Pengertian lain dari tabel dimensi adalah tempat dimana
data tambahan yang berhubungan dengan tabel fakta ditempatkan pada sebuah
tabel multidimensional (Inmon, 2005, p495).
2.5
Skema Bintang
Menurut Connolly dan Begg (2005, p1183) skema bintang adalah struktur
logis fakta yang memiliki tabel yang berisi data faktual di tengah, dikelilingi oleh
dimensi tabel yang berisi data atau referensi yang dapat di-denormalized.
Menurut Poe (1996, p33), skema bintang adalah metode perancangan
yang dilakukan dengan struktur yang sederhana dengan menggunakan beberapa
tabel dan jalur yang terhubung dengan baik dan jelas.
Dengan menggunakan skema bintang ini akan menghasilkan waktu respon
yang lebih cepat dalam query
dan dibanding dengan proses transaksional yang
menggunakan struktur normalisasi. Selain itu, skema bintang memudahkan end
user untuk memahami struktur database pada data warehouse yang dirancang.
|
|
34
Dalam skema
bintang terdapat
dua
tipe tabel
yaitu
tabel
fakta
dan
tabel
dimensi. Tabel fakta disebut juga tabel mayor terdiri dari data kuantitatif atau data
fakta mengenai bisnis, informasi yang di-query. Informasi ini sering diukur secara
numerik dan dapat mengandung banyak kolom dan baris.
Tabel dimensi disebut
juga tabel minor karena lebih kecil dan mencerminkan dimensi bisnis.
2.5.1
Perancangan Skema Bintang
Menurut Poe (1996, p121-122), skema bintang terdiri dari dua
jenis tabel, yaitu tabel fakta (fact table) dan tabel dimensi (dimension
table). Tabel fakta terdiri dari data kuantitatif
atau
data
fakta
mengenai
bisnis, informasi yang akan di-query. Informasi sering berupa
pengumpulan
numerik
dan
terdiri
dari
banyak
kolom dan
jutaan
baris
sedangkan tabel dimensi lebih kecil dan menunjang data deskriptif yang
mencerminkan dimensi dari baris. Query SQL kemudian digunakan untuk
pendefinisian awal dan digunakan sebagai jalur penghubung antara tabel
fakta dan tabel dimensi, dengan bantuan pada data untuk mengembalikan
informasi yang terpilih.
2.5.2
Jenis – Jenis Skema Bintang
2.5.2.1 Skema Bintang Sederhana
Pada skema
bintang sederhana, setiap tabel harus mempunyai
primary key yang terdiri atas satu kolom atau lebih. Primary key dari tabel
fakta terdiri dari satu atau lebih foreign key.
|
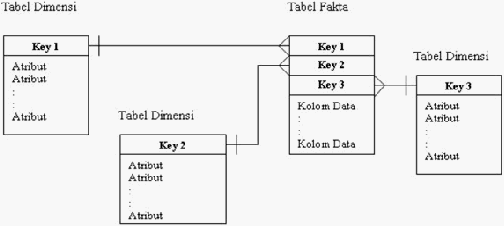 35
Gambar 2. 10 Skema Bintang Sederhana
Pada gambar di atas terlihat hubungan antara tabel fakta dan tabel
dimensi.
Terdapat
satu
tabel
fakta dan
tiga
tabel
dimensi.
Tabel
fakta
memiliki primary key yang terdiri dari tiga foreign key yaitu key-1, key-2,
key-3,
yang
masing
–
masing
merupakan primary key pada ketiga tabel
dimensi yang ada. Terjadi hubungan many to one antara foreign key pada
tabel fakta dengan primary key pada tabel dimensi.
2.5.2.2 Skema Bintang dengan Beberapa Tabel Fakta
Skema bintang juga dapat terdiri dari beberapa tabel fakta. Hal ini
terjadi karena pada tabel fakta berisi kenyataan yang tidak saling
berhubungan atau dikarenakan perbedaan waktu pemuatan data. Skema
bintang juga dapat meningkatkan kinerja (performance), terutama jika
data
tersebut dalam
jumlah
yang besar.
Skema
bintang
dengan
banyak
tabel fakta terlihat seperti pada gambar di bawah ini:
|
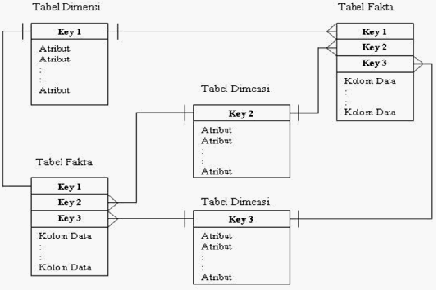 36
Gambar 2. 11 Skema Bintang dengan Beberapa Tabel Fakta
2.6
Skema Snowflake
Menurut Connolly dan Begg (2002, p1080), skema snowflake adalah
bentuk lain dari skema bintang, tabel dimensi tidak berisi data yang
didenormalisasi. Suatu tabel dimensi dapat memiliki tabel dimensi lainnya.
Ciri – ciri snowflake adalah :
1. Tabel dimensi dinormalisasi dengan dekomposisi pada level atribut.
2. Setiap dimensi mempunyai satu key untuk setiap level pada hirarki dimensi.
3. Kunci level
terendah
menghubungkan tabel dimensi
dengan tabel
fakta
dan
tabel atribut berlevel rendah.
|
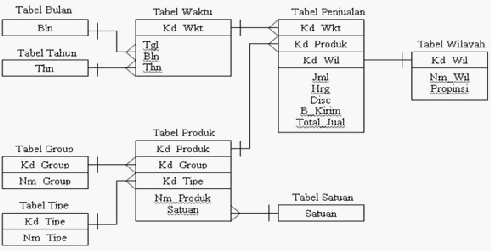 37
2.7
Denormalisasi
Gambar 2. 12 Skema Snowflakes
Berdasarkan Poe (1996, p137), denormalisasi adalah proses penggabungan
tabel
agar
meningkatkan
performance
yang
ada.
Ini
merupakan
sebuah
proses
yang melanggar aturan bentuk normal dalam proses normalisasi. Alasan
melakukan denormalisasi:
•
Mengurangi jumlah dari hubungan yang terjadi antara tabel – tabel, yang
menyebabkan harus mengalami proses pada waktu dilakukan pencarian.
•
Untuk membuat struktur fisik dari database semakin mendekati model dimensi
dari pemakai.
•
Membuat
struktur
tabel sesuai
dengan
yang
ingin
dinyatakan
oleh pemakai,
memungkinkan terjadinya akses langsung.
Sedangkan kelemahan yang timbul bila memakai konsep denormalisasi
tentunya
memerlukan
memory space
(tempat penyimpanan)
yang
besar
sehingga
hal ini secara tidak langsung akan membuat redudansi data.
|
|
38
2.8
OLAP
(On-line Analytical Processing)
Menurut Connoly dan Begg (2005, p1205) OLAP (On-line Analytical
Processing)
adalah
perpaduan dinamis,
analisis, dan konsolidasi dari data
multi-
dimensional yang besar.
Menurut Inmon (2005, p533) OLAP merupakan departemen pengolahan
untuk mart dan lingkupan.
Menurut Ponniah (2001, p352) karakteristik OLAP adalah:
a.
Pengguna
memiliki multidimensional dan
logical view
dari
data di dalam
data warehouse.
b.
Memfasilitasi query yang interaktif dan analisis yang kompleks kepada
pengguna .
c.
Memungkinkan pengguna untuk menelusuri detail yang lebih baik atau untuk
menelusuri agregasi dari matriks sepanjang dimensi bisnis tunggal atau di
beberapa kumpulan dimensi.
d.
Menyediakan
kemampuan
untuk
melakukan perhitungan
rumit dan
perbandingan.
e.
Menyajikan hasil dalam beberapa cara, seperti chart atau grafik.
Jadi,
OLAP
adalah
analisis
data multidimensional
yang
besar
yang
digunakan untuk mengolah mart serta lingkupannya secara dinamis.
|
|
39
2.9
ETL (Extract, Transform, Loading)
Menurut Inmon (2005, p497) Extract, Transform, Loading (ETL) adalah
“the process of finding data, integrating it, and placing it in a data warehouse”.
Proses
ETL
mengambil
data
dari
source
systems menggunakan
query.
ETL berkoneksi dengan
source system database dan mengambil data dengan
query.
Setelah data
hasil query diambil
langkah
selanjutnya
dilakukan eksekusi
proses ETL dan mengirimkannya ke database data warehouse.
ETL
(Extract,
Transform,
and
Load) adalah
proses
–
proses dalam
data
warehouse yang meliputi:
a. Mengekstrak data dari sumber – sumber eksternal.
b. Mentransformasikan data ke bentuk yang sesuai dengan keperluan.
c. Memasukkan data ke target akhir, yaitu data warehouse.
ETL
merupakan
proses
yang
sangat penting,
dengan
ETL
data
dapat
dimasukkan
ke
dalam data
warehouse.
ETL
juga
dapat
digunakan
untuk
mengintegrasikan data dengan sistem yang sudah ada sebelumnya.
Tujuan ETL adalah mengumpulkan, menyaring, mengolah, dan
menggabungkan data yang relevan dari berbagai sumber untuk disimpan ke dalam
data warehouse. Hasil dari proses ETL adalah dihasilkannya data yang memenuhi
kriteria data warehouse seperti data yang historis, terpadu, terangkum, statis, dan
memiliki struktur yang dirancang untuk keperluan proses analisis.
|
|
40
2.9.1
Extract
Langkah
pertama
pada proses
ETL adalah
mengekstrak
data dari
sumber –
sumber data. Kebanyakan proyek data warehouse
menggabungkan data dari sumber – sumber yang berbeda. Sistem – sistem
yang terpisah sangat mungkin menggunakan format data yang berbeda.
Ekstraksi adalah mengubah data ke dalam suatu format yang berguna
untuk proses transformasi.
Pada
hakekatnya
proses
ekstraksi
adalah
proses
penguraian
dari
data yang diekstrak untuk mendapatkan
struktur atau pola data yang
diharapkan. Jika struktur atau pola data tidak sesuai dengan harapan maka
data tidak dimasukkan ke dalam data warehouse.
2.9.2
Transform
Tahapan transformasi menggunakan serangkaian aturan –
aturan
atau
fungsi
–
fungsi
ke
dalam data
yang
telah
diekstraksi,
yang
akan
menentukan
bagaimana
data
akan digunakan
untuk
analisis
dan
dapat
melibatkan
transformasi
seperti
penjumlahan
data, data
encoding,
penggabungan data, pemisahan data, kalkulasi data, dan pembuatan
surrogate key.
Data
akan
disimpan
dalam bentuk
detail
dan
ringkasan
untuk
menyediakan
fleksibilitas
dalam memenuhi
kebutuhan
informasi
yang
beragam pada
pengguna.
Data
tersebut
kemudian
dihubungkan
dengan
surrogate key (sebuah key yang menghubungkan struktur data warehouse
|
|
41
dan terpisah dari sistem sumber) dan diagregasi untuk mempercepat proses
analisis.
Output
dari
transformasi
adalah
data
yang
telah
bersih
dan
konsisten dengan data yang tersimpan pada warehouse, dan lebih jauh lagi
adalah dalam bentuk
yang
telah siap
untuk dianalisis oleh pengguna dari
data warehouse.
2.9.3
Loading
Loading data ke dalam data warehouse dapat terjadi setelah semua
transformasi dilakukan atau sebagai bagian dari proses transformasi.
Ketika
data
dimasukkan
ke
dalam data
warehouse,
batasan
–
batasan
tambahan
yang
didefinisikan
di
dalam skema
database
dan
trigger
diaktivasi ketika loading data akan dilakukan, yang juga akan memberikan
kontribusi pada
keseluruhan
kualitas performa
dari proses
ETL.
Jangka
waktu proses loading bergantung pada kebutuhan organisasi.
Jadi,
ETL
adalah
proses
–
proses
dalam data
warehouse
yang
bertujuan untuk mengumpulkan, menyaring, mengolah, dan
menggabungkan data
yang relevan
dari
berbagai
sumber
untuk
disimpan
ke dalam data warehouse dengan menggunakan query.
|
|
42
2.10
Metadata
Metadata
adalah
data
dari data. Menurut Inmon (2005, p102)
metadata
adalah sebuah komponen penting dalam
data warehouse, yang telah menjadi
bagian dari pengolahan
informasi
selama ada program dan data. Di dalam dunia
data warehouse, metadata berada dalam level yang penting, yaitu mempengaruhi
tujuan paling efektif dalam data warehouse. Dengan bantuan metadata, end user
dapat dengan cepat menuju data yang penting atau menentukan bahwa data
tersebut
tidak
ada. Metadata
juga
bertindak
seperti
indeks
dari
sebuah
data
warehouse.
Menurut Connoly dan Begg (2005, p1159) metadata juga bisa digunakan
untuk hal-hal berikut ini:
a. Proses
pengambilan
dan
pemuatan
data
(metadata
digunakan
untuk
memetakan sumber data ke dalam suatu view data di dalam warehouse).
b. Proses manajemen warehouse (metadata digunakan untuk otomatisasi
produksi dari tabel rangkuman).
c. Sebagai bagian dari proses manajemen query (metadata digunakan untuk
mengarahkan sebuah query ke sumber data yang paling tepat).
2.11
Data Mart
Menurut Connolly dan Begg (2005, p1171) data mart adalah subyek dari
data warehouse yang mendukung kebutuhan suatu departemen atau fungsi bisnis.
Sedangkan menurut Inmon (2005, p370) data mart adalah struktur data
yang didedikasikan
untuk memenuhi kebutuhan analisis
sekelompok orang,
seperti departemen akuntansi atau departemen keuangan.
|
|
43
Menurut Inmon (2005, p371) data mart terdiri dari dua tipe yaitu
independent data mart dan dependent data mart. Independent data mart adalah
data mart yang dibangun langsung dari aplikasi turunannya. Sedangkan
dependent data mart adalah suatu data mart yang dibangun dari data yang berasal
dari data warehouse.
2.12
Granularity
Menurut Inmon (2005, p41) granularity adalah masalah desain paling
penting dalam data warehouse. Karena mempengaruhi volume data yang berada
di
dalam data
warehouse
berbanding
terbalik
dengan
level
detail
dari
sebuah
query.
Semakin
kecil level
dari granularity,
semakin
fleksibel
data
yang
dikeluarkan.
Semakin
tinggi level granularity,
data
yang
dikeluarkan
malah
semakin tidak tetap.
2.13
Business Intelligence
2.13.1 Definisi Business Intelligence
Menurut
Turban,
et. al (2007, p24),
business intelligence
adalah
kerangka
kerja
konseptual
untuk
mendukung
keputusan bisnis. Business
intelligence menggabungkan
arsitektur,
basis
data atau
data warehouse,
analytical tools dan aplikasi.
Menurut
Forrester
Research,
business
intelligence adalah
serangkaian metodologi, proses, arsitektur, dan teknologi yang mengubah
data
mentah
menjadi
informasi
yang bermakna
dan berguna
untuk
|
|
44
menambah wawasan tactical
dan operasional serta untuk pengambilan
Jadi, business intelligence adalah serangkaian metodologi,
arsitektur, dan teknologi yang
mengubah data menjadi informasi yang
berguna untuk mendukung keputusan bisnis perusahaan.
2.13.2 Arsitektur Business Intelligence
Menurut Vercellis (2009, p9), arsitektur dari sebuah business
intelligence system, terdiri dari enam komponen utama yaitu:
1. Data sources
Pada tahap pertama, diperlukan suatu proses untuk mengumpulkan dan
mengintegrasikan data yang disimpan dalam berbagai sumber yang
bervariasi,
yang
mana
saling
berbeda baik itu asal maupun jenisnya.
Sumber ini kebanyakan berasal dari data
yang
terdapat pada operational
systems, tetapi bisa juga berasal dari dokumen yang tidak terstruktur
seperti email dan data yang dikirimkan oleh pihak luar.
2. Data warehouse dan data marts
Dengan
menggunakan
extraction
dan transformation
tool yang
dikenal
sebagai
ETL (extract, transform, load), data
yang
berasal
dari
berbagai
sumber yang berbeda disimpan ke dalam database
yang ditujukan
untuk
mendukung analisis business intelligence. Database inilah yang biasanya
dikenal dengan sebutan data warehouse dan data marts.
|
|
45
3. Data exploration
Pada level ketiga ini, tool yang berfungsi untuk keperluan analisis business
intelligence pasif
digunakan.
Tool ini
terdiri
dari
query
dan
reporting
systems, serta statistical methods. Metodologi ini bersifat pasif karena para
pengambil keputusan harus mengambil keputusan berdasarkan hipotesis
mereka sendiri atau mendefinisikan kriteria dari data extraction, kemudian
menggunakan tools analisis untuk menemukan jawaban dan
mencocokkannya dengan hipotesa awal mereka.
4. Data mining
Level keempat
ini
terdiri dari
sejumlah
metodologi business intelligence
yang
bersifat
aktif
yang
tujuannya
adalah
untuk
mengekstrak
informasi
dan pengetahuan dari data.
Metodologi ini berisi sejumlah model matematika untuk pengenalan pola,
pembelajaran
mesin,
dan
teknik data mining. Tidak seperti tool
yang
digunakan pada
level
sebelumnya,
model
dari business
intelligence
yang
bersifat aktif ini tidak mengharuskan para pengambil keputusan untuk
mengeluarkan hipotesis apapun.
5. Optimization
Pada level ini, solusi terbaik harus dipilih dari sekian alternatif yang ada,
biasanya sangat banyak dan beragam.
6. Decisions
Pada
level terakhir
ini
yang
menjadi persoalan utama
adalah
bagaimana
menentukan keputusan akhir yang akan diambil yang dikenal sebagai
|
|
46
decision making process.
Walaupun
metodologi business intelligence
berhasil diterapkan, pilihan
untuk mengambil sebuah keputusan ada pada
para pengambil keputusan. Pertimbangan untuk mengambil keputusan ini
biasanya
diambil
juga
dari
informasi yang tidak terstruktur serta tidak
formal dan memodifikasi rekomendasi serta kesimpulan yang dicapai
melalui penggunaan model matematika.
2.13.3 Jenis – Jenis Business Intelligence
Menurut Turban, et. al (2007, p257), business intelligence terbagi
ke dalam lima jenis yaitu:
1. Enterprise reporting
Enterprise reporting digunakan untuk menghasilkan laporan – laporan
statis yang didistribusikan ke banyak orang. Jenis laporan ini sangat
sesuai untuk laporan operasional dan dashboard.
2. Cube analysis
Tools cube yang berbasis pada business
intelligence digunakan
untuk
menyediakan analisis OLTP multidimensional yang ditujukan untuk
manajer bisnis dalam lingkungan yang terbatas.
3. Ad hoc querying and analysis
Tools
relational
OLAP digunakan untuk memberikan
akses
kepada
user agar dapat melakukan query
pada
database,
dan
menggali
informasi sampai pada tingkat paling dasar dari informasi
transaksional. Query ini berfungsi untuk mengeksplor informasi yang
dilakukan oleh user.
|
|
47
4. Statistical analysis and data mining
Tools statistic, matematis, dan
data mining digunakan untuk
melakukan
analisis
prediksi
atau menentukan
korelasi
sebab
akibat
diantara dua matrik. Analisis keuangan serta ramalan juga dilakukan
pada jenis ini.
5. Report delivery and alerting
Mesin distribusi laporan digunakan secara proaktif untuk mengirimkan
laporan secara lengkap atau memberikan
peringatan
kepada populasi
user
yang
besar
(internal
dan
eksternal).
Distribusi
ini
berdasarkan
pada jadwal dan event yang disimpan dalam database.
2.13.4 Siklus Hidup Business Intelligence
Menurut
siklus
hidup
untuk
pengembangan
dan
implementasi
untuk
business intelligence,
data
warehousing, dan coorporate performance management yaitu:
1. Perancangan proyek, organisasi dan manajemen.
2.
Bekerja
dengan
bisnis
untuk mengumpulkan
dan
menemukan
kebutuhan
bisnisnya,
membuat
model data
berdasarkan
pada
kebutuhannya
dan
mendesain
fungsional business
intelligence dari
kebutuhan yang telah ditemukan.
3. Mendesain model data dan basis data untuk mengimplementasikan
model ini.
|
|
48
4. Mengintegrasikan data dari aplikasi yang lain seperti CRM (Customer
Relationship Management), ERP (Enterprise Resource Planning), dan
Web.
5. Memilih dan menggunakan tools ETL (Extract, Transform, and Load)
kepada database yang dibutuhkan.
6.
Memilih
dan
menggunakan
tools Business Intelligence
dan OLAP
(Online Analytical Processing) untuk
menyediakan fungsi bisnis yang
berguna bagi perusahaan.
2.13.5 Manfaat Business Intelligence
Menurut
Williams,
et. al
(2007,
p38), business intelligence dapat
digunakan untuk memberikan manfaat bagi sebuah bisnis secara umum
serta menghasilkan contoh - contoh nyata yang berhubungan dengan
fungsi bisnis tersebut. Manfaat tersebut yaitu:
1. Efisiensi transaksi
Efisiensi transaksi ini dapat dicapai karena dapat mengubah
proses - proses yang tidak terstruktur menjadi proses yang terstruktur
dan berulang - ulang. Contohnya adalah model optimisasi pendapatan
yang digunakan pada
industri
hotel dan penerbangan,
model optimasi
jaringan
logistic
dan rantai suplai yang digunakan
pada
industri
penyaluran dan jasa.
|
|
49
2. Otomatisasi proses manual
Proses –
proses yang tadinya dilakukan secara manual dapat
dibuat menjadi otomatis karena keberadaan manusia dapat dihilangkan
atau digantikan dalam sebuah proses. Contohnya adalah perencanaan
operasi dan penjualan, segmentasi
pelanggan, perancangan anggaran,
analisis perubahan, laporan kinerja, analisis produktivitas.
3. Penerapan teknik analisis
Sejumlah mode analisis yang kompleks dapat diintegrasikan ke
dalam proses
-
proses
yang
ada.
Metode
analisis
ini
memiliki
kemampuan analisis yang dapat dipercaya untuk dapat digunakan oleh
user
dengan hanya membutuhkan kurva
pembelajaran yang singkat.
Contohnya
adalah dashboard
dan
scorecard
eksekutif,
aplikasi
pendeteksi kecurangan dan penilaian kredit, analisis pengaturan
kampanye penjualan, ramalan penjualan, segmentasi pelanggan.
4. Pengiriman informasi
Business
intelligence dapat
mengirimkan
rincian
informasi
dalam
jumlah yang besar ke dalam
sebuah proses. Kumpulan
informasi transaksional yang ada pada perusahaan dapat dimanfaatkan
untuk
mendeteksi
penjualan
serta
mengurangi
biaya.
Contohnya
adalah pengenalan pola dan data mining, analisis rantai suplai, analisis
operasi, analisis tren pendapatan, aplikasi manajemen retail.
|
|
50
5. Pelacakan
Business
intelligence memberikan
kebebasan
untuk
melacak
status, input, dan output dari sebuah pekerjaan atau secara terperinci.
Sistem pelacakan
yang
dilakukan
secara
manual
berdasarkan
pada
lembar
kerja
dapat
digantikan
oleh
sistem yang
bersifat
otomatis.
Contohnya adalah dashboard, scorecard pemasok, inventori.
2.14
Teori Pendukung
2.14.1 Retailing
Menurut Berman dan Joel (2006, p4), retailing adalah
aktivitas
bisnis yang meliputi penjualan barang – barang dan jasa kepada konsumen
untuk kebutuhan pribadi mereka, keluarga, ataupun kebutuhan rumah
tangga.
Sedangkan
menurut Ronald dan Ricky (2009, p169) retailers
adalah mereka yang menjual produk secara langsung kepada pelanggan.
2.14.2 Pembelian
Menurut
Mulyadi (2001,
p299),
sistem pembelian digunakan
dalam perusahaan
untuk
pengadaan
barang
yang
diperlukan
oleh
perusahaan. Transaksi pembelian digolongkan menjadi dua yaitu
pembelian lokal dan impor. Pembelian lokal adalah pembelian dari
pemasok dalam negeri sedangkan pembelian impor adalah pembelian dari
pemasok luar negeri. Fungsi yang terkait dalam sistem pembelian adalah:
|
|
51
1. Fungsi
Gudang:
bertanggung
jawab
untuk
mengajukan
permintaan pembelian sesuai dengan posisi persediaan yang
ada di gudang dan untuk menyimpan barang yang telah
diterima oleh fungsi penerimaan.
2.
Fungsi Pembelian: bertanggung jawab untuk memperoleh
informasi
mengenai harga
barang,
menentukan
pemasok
yang
dipilih
dalam pengadaan
barang,
dan
mengeluarkan
order pembelian kepada pemasok yang dipilih.
3. Fungsi Penerimaan: bertanggung jawab untuk memeriksa
mutu, jenis, dan kuantitas barang yang diterima dari pemasok
guna menentukan dapat tidaknya barang tersebut diterima
oleh perusahaan, dan untuk menerima barang dari pembeli
yang berasal dari transaksi retur penjualan.
Menurut Mulyadi (2001, p301), di dalam prosedur order
pembelian,
fungsi
pembelian
mengirim surat
order
pembelian
kepada
pemasok yang dipilih dan memberitahukan kepada unit –
unit organisasi
lain dalam perusahaan (misalnya fungsi penerimaan, fungsi yang meminta
barang) mengenai order pembelian yang sudah dikeluarkan oleh
perusahaan.
Sedangkan dalam prosedur penerimaan barang,
fungsi penerimaan
melakukan pemeriksaan mengenai jenis, kuantitas, dan mutu barang yang
diterima untuk menyatakan penerimaan barang dari pemasok tersebut.
|
|
52
Menurut Mulyadi (2001, p335), retur pembelian adalah barang
yang sudah diterima dari pemasok adakalanya tidak sesuai dengan barang
yang
dipesan
menurut
surat order
pembelian.
Hal
tersebut
terjadi
kemungkinan karena barang yang diterima tidak cocok dengan spesifikasi
yang tercantum dalam surat order pembelian, barang mengalami
kerusakan
dalam pengiriman,
atau
barang
diterima
melewati
tanggal
pengiriman
yang
dijanjikan
oleh
pemasok.
Sistem retur
pembelian
digunakan dalam perusahaan untuk pengembalian barang yang sudah
dibeli kepada pemasoknya.
2.14.3 Service Level Agreement
Menurut Hurwitz, et. al (2009, p152), negosiasi SLA (service level
agreement) merupakan perpaduan antara teknologi
informasi
dan
bisnis.
Beberapa
service-level adalah
non-negotiable.
Teknologi
informasi
dan
bisnis harus bekerja sama untuk membangun SLA tersebut.
Tipe SLA meliputi:
1. Lama respon.
2. Ketersediaan pada hari – hari yang ditentukan.
3. Perfect Order.
4. Adanya persetujuan terhadap suatu prosedur apabila terjadi
penurunan tingkat layanan yang telah disetujui.
2.14.4 Service Metrics
Menurut Ayers dan Odegaard (2008, p137) kebutuhan akan service
metrics didorong oleh keinginan untuk men-deliver dan menghasilkan
|
|
53
kualitas pelayanan yang tinggi. Service metrics merepresentasikan
indikator – indikator. Indikator – indikator yang digunakan adalah:
1. Order fill rate
Order fill rate adalah persentase pemenuhan kuantitas pemesanan
barang oleh supplier.
Order fill rate merupakan salah
satu komponen
yang menentukan perfect order.
2. On-time delivery
On-time delivery adalah pemenuhan ketepatan pengiriman barang oleh
supplier. On-time delivery juga
merupakan
salah satu komponen dari
perfect order
3. Perfect order
Perfect order berarti semua barang yang dipesan, dikirim tepat waktu
dan dokumen pemesanan yang terkait dilaksanakan dengan sempurna.
Perfect order tergantung pada order fill rate dan on-time delivery
|