|
4
BAB 2
LANDASAN TEORI
Beberapa teori yang terkait dalam skripsi ini adalah sebagai berikut:
Systems Engineering (SE)
Structural Equation Modeling (SEM)
Fuzzy Serqual (Service Quality)
Seperti yang telah dibahas pada bab sebelumnya, bahwa
penelitian ini
difokuskan untuk menguji hubungan antara SE dengan kinerja
dan besar
pengaruhnya
serta
mengukur
kesenjangan antara persepsi dan harapan pengguna.
Dimana pengujian hubungan antara SE dengan kinerja dengan menggunakan metode
Structural Equation Modeling (SEM). Selanjutnya, pengukuran kesenjangan persepsi
dan harapan pengguna diolah dengan metode Fuzzy ServQual.
2.1
Systems Engineering (SE)
Menurut Blanchard and
Fabrycky
(2011, p. 17),
sistem merupakan suatu
kombinasi dari sekumpulan elemen
yang memiliki fungsi yang saling berhubungan
dan membentuk satu kesatuan. Elemen tersebut adalah komponen, atribut dan
hubungan. Komponen itu sendiri adalah bagian dari sistem (Blanchard and Fabrycky,
2011, p. 17). Sedangkan atribut merupakan karakteristik dari komponen seperti
konfigurasi, kualitas, kekuatan, batasan dan kondisi
(Blanchard and Fabrycky, 2011,
p. 17). Elemen yang terakhir yaitu hubungan antara komponen yang satu dengan
komponen lainnya dimana hubungan ini merupakan hasil dari perpaduan antara
atribut komponen yang satu dengan atribut komponen yang lain sehingga komponen-
komponen tersebut dapat beroperasi bersama secara efektif dalam mencapai tujuan
dari sistem itu sendiri (Blanchard and Fabrycky, 2011, p. 17). Systems Engineering
(SE) merupakan
sebuah pendekatan yang dari suatu sistem yang terintegrasi dan
seimbang dari sekumpulan orang, proses
dan hasil
untuk memenuhi kebutuhan
pengguna
(Blanchard and
Fabrycky, 2011, p. 31). SE meliputi usaha yang
berhubungan dengan pengembangan, pengujian, penerapan, operasi, pembuangan
dan pelatihan pengguna dari produk dan proses (Blanchard and Fabrycky, 2011, p.
31). Pentingnya peran SE, membuat efisiensi SE perlu selalu dijaga dimana efisiensi
adalah cara yang tepat dalam menjalankan sesuatu dengan tidak membuang waktu,
tenaga dan biaya (Kemdikbud, 2013).
Pada skripsi ini, efisiensi SE difokuskan pada fasilitas, business process dan
SDM dari pengiriman ekspor di kargo SHIA. Fasilitas adalah sarana untuk
melancarkan pelaksanaan fungsi
(Kemdikbud, 2013). Kemudian,
business
process
adalah kumpulan satu atau lebih aktitivitas bisnis sebagai input
sehingga dapat
menghasilkan output yang bernilai bisnis (Utomo dan Mustofa, 2010). Sedangkan,
Sumber Daya Manusia (SDM) adalah potensi manusia yang
dapat dikembangkan
untuk menghasilkan sesuatu (Kemdikbud, 2013).
2.2
Structural Equation Modeling (SEM)
Structural Equation Modeling
(SEM) adalah suatu analisis multivariate
yang
menguji hubungan antara variabel-variabel di dalam modelnya (Wijanto, 2008, p. 6).
SEM dapat digunakan untuk menganalisa
hubungan yang kompleks antara satu atau
lebih variabel laten dengan variabel laten atau antara satu atau lebih variabel laten
|
|
5
dengan variabel teramatinya (Yang, Yen and Chiang, 2012). Variabel yang termasuk
dalam SEM adalah (Wijanto, 2008, p. 10):
a.
Variabel laten
Variabel laten adalah variabel yang tidak dapat diamati secara langsung,
contohnya adalah motivasi, perasaan, dan perilaku orang. SEM memiliki 2 jenis
variabel laten yaitu variabel eksogen yang merupakan variabel bebas dan
variabel endogen yang merupakan variabel terikat.
b.
Variabel teramati
Variabel teramati adalah variabel yang dapat diamati dengan kasat mata sebagai
indikator. Apabila penelitian menggunakan instrumen kuesioner, maka masing-
masing pertanyaan akan menyangkut penilaian terhadap variabel teramati.
Menurut Tempelaar, Loeff dan Gijselaers
(2007), model dalam metode SEM
terdiri dari 2 jenis model yaitu:
a.
Model Struktural
Model struktural merupakan model yang menggambarkan hubungan antar
variabel laten.
b.
Model Pengukuran
Model pengukuran merupakan model yang menggambarkan hubungan antara
variabel laten dengan variabel teramati atau indikator terkait.
Berikut merupakan variabel laten dan variabel teramati dari penelitian ini:
a.
Variabel Laten Efficiency Systems engineering (SE)
Seperti yang telah dibahas sebelumnya, SE merupakan suatu sistem yang terdiri
dari sekumpulan orang, proses dan hasil untuk memenuhi kebutuhan pengguna
(Blanchard and
Fabrycky, 2011). Berdasarkan definisi tersebut maka pada
penelitian ini variabel laten Efficiency SE diukur dari tiga variabel teramati yaitu
fasilitas (facility), Business Process (BP) dan SDM (Human Resources (HR)).
b.
Variabel Laten Performance Kargo Ekspor SHIA
Variabel ini digunakan untuk mengukur bagaimana tingkat kinerja kargo ekspor
SHIA saat ini. Pengukuran yang dilakukan meliputi pengukuran terhadap dua
variabel teramati yaitu keamanan dan kehandalan dari kargo ekspor SHIA.
Model SEM tersebut diaplikasikan dalam proses desain instrumen penelitian
(kuesioner) dan pengolahan data kuesioner (uji kecocokan). Menurut Hair et.al.
(1998) yang dikutip oleh Wijanto (2008, p. 49), uji kecocokan terbagi menjadi tiga
tahapan, yaitu:
Uji kecocokan model pengukuran
Uji kecocokan keseluruhan model
Uji kecocokan model struktural
Uji kecocokan model dapat dilakukan dengan menggunakan software
LISREL 8.72 (Alavifar, Karimimalayer and
Anuar, 2012). Model SEM baik model
pengukuran maupun model struktural dapat direspesifikasi apabila uji kecocokan
model pengukuran, uji kecocokan keseluruhan model dan uji kecocokan model
struktural menunjukkan hasil yang kurang baik.
2.2.1
Uji Model Pengukuran
Uji model pengukuran atau disebut juga dengan istilah CFA (Confirmatory
Factor Analysis) merupakan analisis terhadap model pengukuran (model hubungan
antara variabel laten dengan variabel teramati) dimana
CFA bertujuan untuk
memastikan bahwa variabel teramati merupakan refleksi atau ukuran dari variabel
laten terkait
(Wijanto, 2008, p. 25).
Pada penelitian ini, uji model pengukuran
dilakukan dengan dua tingkat atau disebut juga dengan Second
CFA. Uji model
|
 6
pengukuran
terdiri dari uji validitas
model pengukuran
dan uji reliabilitas
model
pengukuran, yang dijelaskan sebagai berikut:
a.
Uji Validitas Model Pengukuran
Uji validitas model pengukuran bertujuan untuk mengukur apakah variabel pada
penelitian mengukur apa yang seharusnya diukur. Menurut Rigdon (1991) dan
Doll (1994) yang dikutip oleh Wijanto (2008, p. 65), variabel teramati dikatakan
memiliki validitas yang baik apabila:
T-value = 1.96 atau praktisnya = 2.
Standardized Loading Factor (SLF)
= 0.70.
Igbaria (1997) yang dikutip oleh
Wijanto (2008, p.139) menambahkan apabila nilai SLF
= 0.5 tetapi SLF =
0.30
maka variabel tersebut masih bisa
dipertimbangkan untuk tidak
dihapus sesuai kebijakan peneliti.
b.
Uji Reliabilitas Model Pengukuran
Uji reliabilitas model pengukuran bertujuan untuk mengukur konsistensi dari
model pengukuran. Uji reliabilitas dapat diukur dengan menghitung nilai
Construct Reliability (CR) dan Variance Extracted (VE). Berikut adalah rumus
CR dan VE (Wijanto, 2008, p. 66):
dimana,
std loading
= Standardized Loading Factor
(SLF) dan ej adalah
measurement error
yang dapat diperoleh dari hasil
output Lisrel
8.72. Suatu
variabel dikatakan mempunyai reliabilitas yang baik apabila nilai CR
= 0.70 dan
nilai VE
= 0.50 (Hair
, 1998 dalam Wijanto, 2008, p. 66).
2.2.2
Uji Kecocokan Keseluruhan Model
Uji kecocokan keseluruhan model dilakukan dengan mengevaluasi derajat
kecocokan atau Goodness of Fit
(GOF) (Wijanto, 2008, p. 51). Beberapa ukuran
GOF yang sesuai dengan ukuran sampel yang kecil (n<250) adalah Chi-Square,
RMSEA, RMR,
NNFI, CFI,
IFI, dan Normed Chi-Square
(Shah and
Goldstein,
2006). Ukuran
GOF dan target tingkat kecocokan dari masing-masing GOF tersebut
dijelaskan pada tabel berikut (Wijanto, 2008, p. 49):
Tabel 2.1 Goodness of Fit (GOF)
Ukuran GOF
Target Tingkat Kecocokan
Chi-Square
p-value
Semakin kecil semakin baik
p > 0.05
Root Mean Square Error of
Approximation (RMSEA)
p (close fit)
RMSEA
= 0.08
adalah good fit, RMSEA
=
0.1
adalah poor fit, RMSEA
= 0.05 adalah
close fit.
p
= 0.5
NonNormed Fit Index (NNFI)
NNFI
= 0.90 ada
lah good fit, 0.80
= NNFI <
0.90
adalah marginal fit, NNFI < 0.8 adalah poor fit
Comparative Fit Index (CFI)
CFI
= 0.90 adalah
good fit, 0.80
= CFI <
0.90
adalah marginal fit, CFI < 0.8 adalah poor fit
Incremental Fit Index (IFI)
IFI
= 0.90 adalah
good fit, 0.80
= IFI <
0.90
adalah marginal fit, IFI < 0.8 adalah poor fit
Root Mean Square Residual
Standardized RMR
= 0.05
adalah good fit
(2.1)
(2.2)
|
 7
(RMR)
Normed Chi-Square
Rasio antara Chi-Square dibagi degree of freedom
Nilai yang disarankan: batas bawah: 1.00, batas
atas: 2.00 atau 3.00 dan yang lebih longgar 5.00
Critical N (CN)
CN
= 200 adalah
good fit, yang menunjukkan
bahwa sampel cukup untuk mengestimasi model.
Sumber: Wijanto, 2008, p. 49
2.2.3
Uji Kecocokan Model Struktural
Uji kecocokan model struktural adalah analisis terhadap model struktural
penelitian dimana uji kecocokan ini akan menguji hubungan kausal antara variabel
laten (Wijanto, 2008, p. 66). Suatu nilai koefisien atau estimasi dari hubungan antara
2 variabel laten bersifat signifikan apabila t-value = 1.96. Pada program Lisrel 8.72,
t-value yang
= 1.96 akan ditampilkan dengan warna hitam, sebaliknya jika
t-value <
1.96 akan ditampilkan dengan warna merah. Tanda positif dan negatif
dari nilai
estimasi dan t-value
menunjukkan hubungan positif atau negatif dari kedua variabel
laten terkait (Wijanto, 2008, p. 149).
2.3
Fuzzy ServQual (Service Quality)
Menurut Parasuraman et al (1988) yang dikemukakan kembali oleh Angelova
(2011), service
quality
merupakan penillaian secara umum atau tindakan yang
berhubungan dengan kelebihan dan kekurangan dari pelayanan
dimana service
quality
yang diterima
pengguna
akan berpengaruh pada kepuasan dari pengguna.
Menurut Bitner dan Zeithaml (2003) yang dikutip oleh
Prabhakar dan Ram (2013),
kepuasan pengguna
adalah kesesuaian hasil penilaian dari jasa yang telah diterima
(persepsi) dengan harapan sebelum jasa tersebut diterima (harapan). Apabila persepsi
melebihi dari harapan, dapat dikatakan bahwa kualitas
penyedia jasa sudah
memenuhi harapan pengguna sedangkan apabila persepsi kurang dari harapan maka
kualitas penyedia jasa dapat dianggap buruk (Imawati, 2008)
Tingkat kepuasan pengguna
didasarkan pada ukuran harapan
pengguna.
Menurut Parasuraman et al
(1985) yang dikutip oleh
Urban (2010), harapan dari
pengguna muncul karena adanya faktor kebutuhan pengguna, pengalaman menerima
jasa dengan tipe yang sama, komunikasi antar pengguna dari mulut ke mulut. Maka
dari itu perlu diketahui persepsi dan harapan pengguna terhadap kargo ekspor SHIA
dengan membagikan kuesioner kepada karyawan bagian ekspor dari perusahaan
ekspedisi di Soewarna Businees Park, Komplek SHIA yang menggunakan jasa kargo
SHIA.
Untuk
mengukur nilai kesenjangan persepsi dan harapan, hasil dari kuesioner
perlu diolah dengan metode Fuzzy ServQual. Fuzzy ServQual
berguna untuk
memberikan nilai yang lebih tepat kepada peneliti karena adanya subjektivitas
responden
dalam pengisian kuesioner
(Erdogan, Bilisik, Kaya
and
Barach, 2013).
Contohnya seorang responden memilih pilihan setuju, apakah pilihan tersebut
cenderung ke arah cukup atau ke sangat setuju.
Hal ini menyebabkan perbedaan
tingkat penilaian. Oleh sebab itu, untuk mengatasi subjektivitas responden tersebut
maka digunakan metode Fuzzy ServQual.
Proses perhitungan pada Fuzzy ServQual
terdiri dari fuzzyfikasi
dan
defuzzyfikasi. Fuzzyfikasi yaitu penentuan Triangular Fuzzy Number
(TFN) dan
defuzzyfikasi merupakan penentuan nilai crisp fuzzy.
|
 8
Sumber: Adaptasi dari Suharyanta dan A'yunin, 2012
Gambar 2.1 Penentuan Nilai Fuzzy
Triangular Fuzzy Number
(TFN) merupakan
range
nilai dari bobot jawaban
responden. TFN terdiri dari tiga nilai batas yaitu nilai batas bawah (a), nilai tengah
(b) dan nilai batas atas (c). Setiap pilihan di berikan range nilai yang akan dihitung
menggunakan rumus untuk menentukan TFN.
Berikut merupakan rumus untuk
menentukan Triangular Fuzzy Number (TFN) (Suharyanta dan A'yunin, 2012):
Nilai batas bawah (a)
Nilai tengah (b)
Nilai batas atas (c)
Keterangan:
b
ak
= nilai bobot bawah dari pilihan k
b
bk
= nilai bobot tengah dari pilihan k
b
ck
= nilai bobot atas dari pilihan k
n
k
= jumlah responden dari pilihan k
Setelah melakukan fuzzyfikasi yaitu dengan menentukan nilai TFN,
selanjutnya dilakukan defuzzyfikasi dengan melakukan perhitungan nilai crisp fuzzy
yaitu dengan menghitung nilai rata-rata dari nilai batas bawah (a), nilai tengah (b),
nilai batas atas (c).
Crisp Fuzzy
Nilai crisp fuzzy
inilah yang akan digunakan pada perhitungan selanjutnya yaitu
menghitung kesenjangan persepsi dan harapan pengguna.
Perhitungan kesenjangan persepsi dan harapan pengguna
dapat
dilakukan
dengan menggunakan rumus sebagai berikut
(Govender, Veerasamy and
Noel,
2012):
Dimana skor persepsi dan skor harapan merupakan nilai crisp fuzzy persepsi dan nilai
crisp fuzzy
harapan. Selanjutnya, apabila skor service quality
bernilai negatif maka
hal tersebut menunjukkan adanya kesenjangan antara persepsi dan harapan
pengguna.
Skor
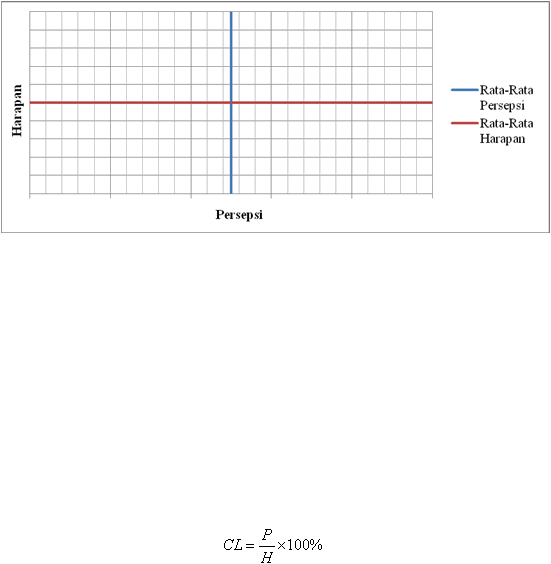
persepsi dan skor harapan perlu dipetakan ke dalam diagram kartesius
agar dapat diketahui indikator-indikator yang perlu diperbaiki terlebih dahulu. Pada
diagram kartesius ini, nilai persepsi berada pada axis dan nilai harapan berada pada
(2.3)
(2.4)
(2.5)
(2.7)
(2.6)
|
 9
ordinate
(Kasim and
Fathurahman, 2011). Sehingga akan terdapat titik-titik
koordinat
dari skor persepsi dan harapan.
Selanjutnya, rata-rata dari persepsi
dan
rata-rata dari harapan akan membagi diagram kartesius menjadi empat kuadran yang
dapat dilihat pada gambar 2.2.
Sumber: Adaptasi dari Kasim and Fathurahman (2011)
Gambar 2.2 Konsep Diagram Cartesius Skor Persepsi dan Skor Harapan
Kuadran I
: Persepsi Rendah, Harapan Tinggi
Kuadran II
: Persepsi Tinggi, Harapan Tinggi
Kuadran III
: Persepsi Rendah, Harapan Rendah
Kuadran IV
: Persepsi Tinggi, Harapan Rendah
Berdasarkan diagram kartesius pada gambar 2.2, diketahui bahwa indikator-
indikator
yang berada pada kuadran I merupakan indikator
yang perlu diperbaiki
terlebih dahulu daripada indikator yang berada
dikuadran lain, karena
indikator
tersebut
memiliki harapan yang tinggi tetapi memiliki penilaian yang rendah dari
pengguna.
Selanjutnya, untuk menentukan urutan indikator
yang perlu diperbaiki
terlebih dahulu, dapat dilakukan dengan menghitung Compatibility Level (Kasim and
Fathurahman, 2011). Compatibility Level adalah perbandingan antara
skor persepsi
dan skor harapan (Kasim and Fathurahman, 2011). Berikut merupakan rumus untuk
menghitung Compatibility Level (Adaptasi dari Kasim and Fathurahman, 2011):
dimana,
CL = Compatibility Level
P
= Skor Persepsi (Crisp Fuzzy Persepsi)
H
= Skor Harapan (Crisp Fuzzy Harapan)
Indikator
yang memiliki nilai CL yang paling kecil perlu diperbaiki terlebih dahulu,
lalu indikator
dengan
nilai CL terkecil
kedua merupakan indikator
yang perlu
diperbaiki selanjutnya, dan seterusnya. Jadi urutan perbaikan ditentukan dari nilai CL
yang terkecil ke yang terbesar.
I
II
III
IV
(2.8)
|