|
7
BAB 2
LANDASAN TEORI
2.1
Pengertian Data Mining
Menurut Han dan Kamber (2011, p36), data mining
adalah proses
menemukan pola yang menarik dan pengetahuan dari data yang berjumlah besar.
Sedangkan menurut Linoff dan Berry (2011, p7) Data mining adalah suatu pencarian
dan analisa dari jumlah data yang sangat besar dan bertujuan untuk mencari arti dari
pola dan aturan. Lalu menurut Connolly dan Begg,(2010), Data mining adalah suatu
proses ekstraksi atau penggalian data yang belum diketahui sebelumnya, namun
dapat dipahami dan berguna dari database
yang besar serta digunakan untuk
membuat suatu keputusan bisnis yang sangat penting. Dan menurut Vercellis (2009,
p77), Data mining adalah aktivitas yang menggambarkan sebuah proses analisis yang
terjadi secara iteratif pada database
yang besar, dengan tujuan mengekstrak
informasi dan knowledge
yang akurat dan berpotensial berguna untuk knowledge
workers yang berhubungan dengan pengambilan keputusan dan pemecahan masalah.
Dari beberapa teori yang dijabarkan oleh para ahli diatas, bahwa Data mining
adalah suatu pencarian dan analisa pada suatu koleksi data (database)
yang sangat
besar sehingga ditemukan suatu pola yang menarik
dengan tujuan mengekstrak
informasi dan knowledge yang akurat dan berpotensial, serta dapat dipahami dan
berguna dari database
yang besar serta digunakan untuk membuat suatu keputusan
bisnis yang sangat penting.
Menurut Han dan Kamber, (2011, p24), secara garis besar data mining dapat
dikelompokkan menjadi 2 kategori utama, yaitu:
Predictive
Predictive merupakan proses untuk menemukan pola dari data dengan
menggunakan beberapa variabel lain di masa depan. Salah satu teknik yang terdapat
dalam predictive mining adalah klasifikasi. Tujuan dari tugas prediktif adalah untuk
memprediksi nilai dari atribut tertentu berdasarkan pada nilai atribut-atribut lain.
Atribut yang diprediksi umumnya dikenal sebagai target atau variable tak bebas,
sedangkan atribut-atribut yang digunakan untuk membuat prediksi dikenal sebagai
explanatory atau variable bebas.
Contohnya, perusahaan retail
dapat menggunakan
|
 8
data mining untuk memprediksikan penjualan dari produk mereka di masa depan
dengan menggunakan data-data yang telah didapatkan dari beberapa minggu.
Descriptive
Descriptive
dalam data mining merupakan proses untuk menemukan
karakteristik penting dari data dalam suatu basis data. Tujuan dari tugas deskriptif
adalah untuk menurunkan pola-pola (korelasi, trend, cluster, teritori, dan anomali)
yang meringkas hubungan yang pokok dalam data. Tugas data mining deskriptif
sering merupakan penyelidikan dan seringkali memerlukan teknik post-processing
untuk validasi dan penjelasan hasil.
Menurut Hoffer, Ramesh & Topi (2012), tujuan dari adanya data mining adalah:
explanatory, yaitu untuk menjelaskan beberapa kegiatan observasi atau suatu
kondisi.
confirmatory, yaitu untuk mengkonfirmasi suatu hipotesis yang telah ada.
exploratory, yaitu untuk menganalisis data baru suatu relasi yang janggal.
Karakteristik data Mining menurut Turban (2007, p230):
a.
Seringnya data terpendam dalam
database
yang sangat besar dan kadang
datanya sudah bertahun-tahun.
b.
Lingkungan data mining biasanya berupa arsitektur client-server
atau
arsitektur system informasi berbasis web.
c.
Tool baru yang canggih, termasuk tool visualisasi tambahan, membantu
menghilangkan lapisan informasi yang terpendam dalam file-file
yang
berhubungan atau record-record arsip publik.
d.
Pemilik biasanya seorang end user,
didukung dengan data drill dan tool
penguasaan query yang lain untuk menanyakan pertanyaan dan
mendapatkan jawaban secepatnya, dengan sedikit atau tidak ada
kemampuan pemrograman.
e.
Tool data mining dengan kesediannya dikombinasikan dengan spreadsheet
dan tool software pengembangan yang lainnya.
f.
Karena besarnya jumlah data dan usaha pencarian yang besar-besaran,
kadang-kadang diperlukan penggunaan proses parallel untuk data mining.
Kelebihan Data Mining sebagai alat analisis :
a.
Data mining mampu menangani data dalam jumlah besar dan kompleks.
b.
Data mining dapat menangani data dengan berbagai macam tipe atribut.
|
 9
c.
Data mining
mampu mencari dan mengolah data secara semi otomatis.
Disebut semi otomatis karena dalam beberapa teknik data mining,
diperlukan parameter yang harus di-input oleh user secara manual.
d.
Data mining dapat menggunakan pengalaman ataupun kesalahan terdahulu
untuk meningkatkan kualitas dan hasil analisa sehingga mendapat hasil
yang terbaik.
2.2
Fungsi Data Mining
Menurut Maclennan, Tang, & Crivat (2009, p6). Berikut adalah fungsi data
mining secara umum :
1.
Classification
Classification adalah proses untuk mencari
model atau fungsi yang
menggambarkan dan membedakan kelas-kelas atau konsep data. Fungsi dari
Classification
adalah untuk mengklasifikasikan suatu target class
ke dalam
kategori yang dipilih.
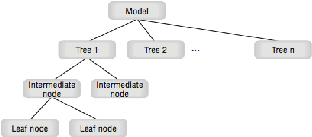
Gambar 2.1 Classification - Decision Tree
Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
Decision tree
adalah sebuah flowchart yang menyerupai struktur
pohon, dimana tiap node
menunjukkan sebuah test
dari nilai atribut, tiap
cabang merepresentasikan sebuah hasil dari test,
dan decision tree
merepresantasikan kelas-kelas atau distribusi kelas. Decision trees
dapat
dengan mudah di konversi ke aturan klasifikasi.
Neural network ketika digunakan untuk klasifikasi, biasanya koleksi
dari neuron seperti unit pengolahan dengan pertimbangan koneksi antara tiap
unit. Ada banyak
metode untuk membangun model klasifikasi seperti naïve-
bayesian classification, support vector machine (SVM)
dan k-nearest
neighbor classication.
|
 10
2.
Clustering
Fungsi dari clustering adalah untuk mencari pengelompokkan atribut
ke dalam segmentasi-segmentasi berdasarkan similaritas.
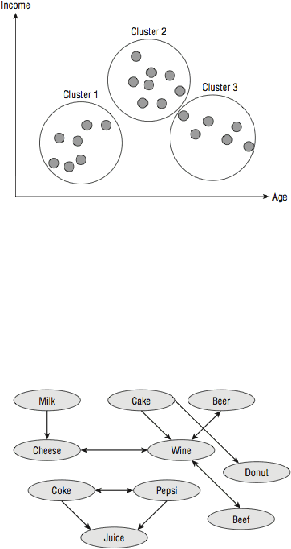
Gambar 2.2 Clustering
Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
3.
Association
Fungsi dari association
adalah untuk mencari keterkaitan antara
atribut atau item set, berdasarkan jumlah item
yang muncul dan rule
association yang ada.
Gambar 2.3 Product Association
Sumber: (Maclennan, Tang, & Crivat, 2009, p7)
4.
Regression
Fungsi dari regression hampir sama dengan klasifikasi. Fungsi dari
regression adalah bertujuan untuk mencari prediksi dari suatu pola yang ada.
5.
Forecasting
Fungsi dari forecasting
adalah untuk peramalan waktu yang akan
datang berdasarkan trend yang telah terjadi di waktu sebelumnya.
|
 11
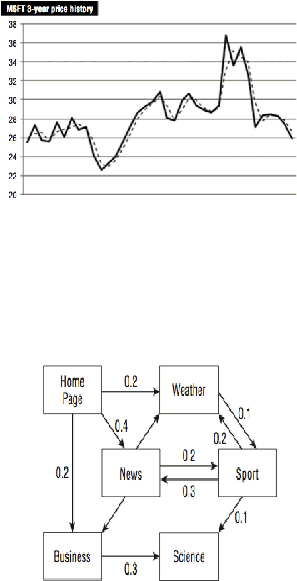
Gambar 2.4 Time Series
Sumber: (Maclennan, Tang, & Crivat, 2009, p8)
6.
Sequence Analysis
Fungsi dari sequence analysis
adalah untuk mencari pola urutan dari
rangkaian kejadian.
Gambar 2.5 Web Navigation Sequence
Sumber: (Maclennan, Tang, & Crivat, 2009, p9)
7.
Deviation Analysis
Fungsi dari deviation analysis
adalah untuk mencari kejadian langka
yang sangat berbeda dari keadaan normal (kejadian abnormal).
2.3
Data Preprocessing
Menurut Han dan Kamber (2011, p83), Tahapan Data Preprocessing terbagi
menjadi:
2.3.1
Data Preprocessing : An Overview
Pada bagian ini menyajikan gambaran dari data preprocessing. Pada
bagian data quality, mengilustrasikan banyak unsur yang menentukan
|
 12
kualitas data. Ini memberikan insentif balik bagi Data preprocessing
dan
selanjutnya menguraikan tugas utama dalam data preprocessing .
Data Quality: Data memiliki kualitas jika data tersebut memenuhi
persyaratan
dari penggunaan yang data yang dimaksudkan. Faktor-faktor
yang terdiri dari kualitas data seperti akurasi, kelengkapan, konsistensi,
ketepatan waktu, kepercayaan, dan interpretability. Banyak alasan yang
memungkinkan untuk data yang tidak akurat (yaitu, memiliki nilai atribut
yang salah). Kesalahan dalam transmisi data juga dapat terjadi. Kualitas data
tergantung pada tujuan penggunaan data. Ketepatan waktu juga
mempengaruhi kualitas data.
Major Tasks in Data Preprocessing: Langkah-langkah utama yang
terlibat dalam preprocessing
data, yaitu data pembersihan, integrasi data,
reduksi data, dan transformasi data. Pembersihan data bekerja untuk
"membersihkan" data dengan mengisi nilai-nilai yang hilang, smoothing
noisy
data, mengidentifikasi atau menghapus outlier, dan menyelesaikan
inkonsistensi . Langkah pre-processing
yang berguna adalah menjalankan
data dengan pembersihan data.
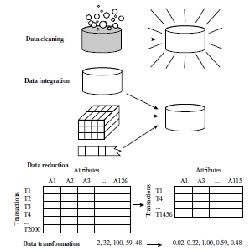
Gambar 2.6 Bentuk Data preprocessing
Sumber: Han dan Kamber, 2011, p87
2.3.2
Data Cleaning
Pembersihan data (atau data cleansing)
ber-upaya untuk mengisi
nilai-nilai yang hilang, menghaluskan noisy data, mengidentifikasi outlier
,
dan inkonsistensi yang benar dalam data.
|
|
13
Missing Values: Banyak tuple
yang tidak memiliki nilai yang tercatat
ke dalam atribut. Cara mengatasi missing values:
1.
Abaikan tuple
: dilakukan ketika label kelas hilang. Metode ini
sangat tidak efektif , kecuali tuple berisi beberapa atribut dengan
nilai-nilai yang hilang. Dengan mengabaikan tuple,
memungkinkan untuk tidak menggunakan nilai-nilai atribut yang
tersisa dalam tuple.
2.
Isikan nilai yang hilang secara manual : Secara umum, pendekatan
ini memakan waktu dan mungkin tidak layak diberi dataset yang
besar dengan banyak nilai-nilai yang hilang
3.
Gunakan konstan global untuk mengisi nilai yang hilang: Ganti
semua nilai atribut yang hilang dengan konstanta yang sama
seperti label "Unknown".
4.
Gunakan ukuran tendensi sentral untuk atribut (misalnya , rata-
rata atau median ) untuk mengisi nilai yang hilang.
5.
Gunakan atribut berarti atau rata-rata untuk semua sampel milik
kelas yang sama seperti tuple yang diberikan.
6.
Gunakan nilai yang paling mungkin untuk mengisi nilai yang
hilang: dapat ditentukan dengan regresi, alat berbasis inferensi
menggunakan formalisme Bayesian atau decision tree.
Noisy Data: Noise adalah kesalahan
acak atau varian dalam variabel
yang diukur. Cara mengatasi Noisy Data:
1.
Binning: pertama-tama melakukan pengurutan data dan partisi ke
dalam (frekuensi yang sama) suatu tempat.
2.
Regression: menghaluskan dengan mencocokkan data ke dalam
fungsi regresi.
3.
Outlier Analysis: Mendeteksi dan menghapus outlier.
Data Cleaning as a Process: Melakukan deteksi perbedaan data
menggunakan metadata (domain, range, ketergantungan, distribusi),
mendeteksi bagian overloading, mendeteksi uniqueness rule, consecutive rule
dan null, menggunakan komersial tools. Data migrasi dan integrasi:
memungkinkan transformasi yang ditentukan dengan data migrasi tools dan
memungkinkan pengguna untuk menentukan transformasi melalui pengguna
grafis dengan ETL tools. Integrasi dari dua proses: Iterative dan Interactive.
|
|
14
2.3.3
Data Integration
Integrasi data merupakan penggabungan data dari berbagai database
ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data
mining
tidak hanya berasal dari satu database
tetapi juga berasal
dari
beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut
yang mengidentifikasikan entitas-entitas yang unik seperti atribut nama, jenis
produk, nomor pelanggan dan lainnya. Integrasi data perlu dilakukan secara
cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang
menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai
contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan
produk dari kategori yang berbeda maka akan didapatkan korelasi antar
produk yang sebenarnya tidak ada.
2.3.4
Data Reduction
Data Reduction
berguna untuk mendapatkan pengurangan
representasi dari kumpulan data yang jauh lebih kecil di dalam volume tetapi
belum menghasilkan hasil yang sama (atau hampir sama) dari suatu hasil
analisis.
Teknik dalam Data Reduction:
a)
Strategi dimensionality reduction pengurangan data meliputi
dimensionality reduction, numerosity reduction, dan kompresi
data.
b)
Wavelet Transform: Data ditransformasikan ke jarak relatif antara
obyek pada berbagai tingkat resolusi.
c)
Principal component Analysis
d)
Attribute Subset Reduction
e)
Regression dan Log linear models
f)
Histogram
g)
Clustering
h)
Sampling
i)
Data cube Agreggation
2.3.5
Data Transformation and Data Discretization
Dalam Data Transformation
dan Data Discretization, data diubah
atau dikonsolidasikan sehingga proses mining yang dihasilkan mungkin lebih
efisien, dan pola yang ditemukan mungkin lebih mudah untuk dipahami.
|
|
15
Strategi Data Transformation:
1.
Smoothing, yang bekerja untuk menghilangkan noise
dari dana
data.
2.
Atribut konstruksi (konstruksi atau fitur), di mana atribut baru
dibangun dan ditambahkan oleh himpunan atribut untuk
membantu proses mining.
3.
Agregasi, dimana ringkasan atau agregasi operasi diterapkan pada
data.
4.
Normalisasi, dimana data atribut adalah skala sehingga jatuh
dalam kisaran yang lebih kecil.
5.
Discretization,
dimana nilai-nilai baku dari atribut numerik
(misalnya , usia) akan diganti dengan label Interval (misalnya , 0-
10 , 11-20 , dll) atau label konseptual (misalnya , remaja , dewasa
,senior).
6.
Generasi hirarki konsep untuk data nominal , di mana atribut dapat
digeneralisasi untuk konsep-tingkat yang lebih tinggi , seperti kota
atau negara.
2.4
Teknik Data Mining
Teknik data mining terbagi menjadi tiga, yaitu: Association Rule Mining,
Classification, Clustering dan Regretion.
2.4.1
Association Rule Mining
Menurut Olson dan Shi (2013), Association Rule Mining
merupakan
teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi
item atau untuk menemukan hubungan hal tertentu dalam suatu transaksi data
dengan hal lain di dalam transaksi, yang digunakan untuk memprediksi pola.
Sedangkan menurut Han dan Kamber (2011, p246), Association Rule Mining
terdiri dari itemset yang sering muncul. Association Rule Mining
dapat
dianalisa lebih lanjut untuk mengungkap aturan korelasi
untuk
menyampaikan korelasi statistik antara itemsets A dan B.
2.4.2
Classification
Menurut Olson dan Shi
(2013),
Klasifikasi (Classification),
metode-
metodenya
ditunjukan untuk pembelajaran
fungsi-fungsi berbeda yang
memetakan masing-masing data terpilih ke dalam salah satu dari kelompok
kelas yang telah ditetapkan sebelumya.
Menurut Han dan Kamber (2011,
|
 16
327), Classification adalah proses untuk menemukan model atau fungsi yang
menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk
dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui.
dasar pengukuran untuk mengukur kualitas dari penemuan teks, yaitu:
Precision: tingkat ketepatan hasil klasifikasi terhadap suatu kejadian.
Recall: tingkat keberhasilan mengenali suatu kejadian dari seluruh
kejadian yang seharusnya dikenali.
F-Measure
adalah nilai yang didapatkan dari pengukuran precision
dan
recall
antara class
hasil cluster
dengan class
sebenarnya yang terdapat
pada data masukan.
Precision dan recall bisa didapatkan dengan rumus sebagai berikut :
Gambar 2.7 : Rumus Precision dan Recall
Sumber: (Wicaksana & Widiartha, 2012)
Rumus untuk menghitung nilai F-Measure:
Gambar 2.8: Rumus F-Measure
Sumber: (Wicaksana & Widiartha, 2012)
Keterangan nya adalah ni adalah jumlah data dari kelas i yang
diharapkan sebagai hasil query, nj adalah jumlah data dari cluster
j yang
dihasilkan oleh query, dan nij adalah jumlah elemen dari kelas i yang masuk
di cluster j. Untuk mendapatkan pembobotan yang seimbang antara precision
dan recall, digunakan nilai b = 1.
Untuk mendapatkan nilai F-Measure dari
dataset
dengan jumlah data n, maka rumus yang digunakan adalah sebagai
berikut :
|
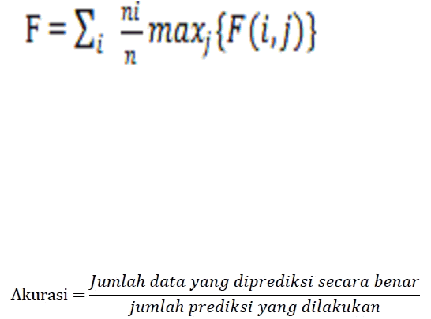 17
Gambar 2.9: Rumus F-Measure Dataset
Sumber: (Wicaksana & Widiartha, 2012)
Salah satu pengukur kinerja klasifikasi adalah tingkat akurasi. Sebuah
sistem dalam melakukan klasifikasi diharapkan dapat mengklasifikasi semua
set data dengan benar, tetapi tidak dipungkiri bahwa kinerja suatu sistem
tidak bisa 100% akurat. (Prasetyo, 2012).
Untuk menghitung akurasi digunakan formula :
Gambar 2.10 : Rumus Akurasi
Sumber: (Prasetyo,2012)
2.4.3
Clustering
Menurut Han dan Kamber (2011), Clustering
adalah proses
pengelompokkan kumpulan data menjadi beberapa kelompok sehingga objek
di dalam satu kelompok memiliki banyak kesamaan dan memiliki banyak
perbedaan dengan objek dikelompok lain. Perbedaan dan persamaannya
biasanya berdasarkan nilai atribut dari objek tersebut dan dapat juga berupa
perhitungan jarak. Clustering
sendiri juga disebut Unsupervised
Classification, karena clustering
lebih bersifat untuk dipelajari dan
diperhatikan. Cluster analysis merupakan proses partisi satu set objek data ke
dalam himpunan bagian. Setiap himpunan bagian adalah cluster, sehingga
objek yang di dalam cluster
mirip satu sama dengan yang lainnya, dan
mempunyai perbedaan dengan objek dari cluster
yang lain. Partisi tidak
dilakukan dengan manual tetapi dengan algoritma clustering. Oleh karena itu,
Clustering
sangat berguna dan bisa menemukan group
yang tidak dikenal
dalam data.
Teknik clustering
umumnya berguna untuk merepresentasikan data
secara visual, karena data dikelompokkan berdasarkan kriteria-kriteria umum.
Dari representasi target tersebut, dapat dilihat adanya kecenderungan lebih
|
|
18
tingginya jumlah lubang pada bagian-bagian atau kelompok-kelompok
teretentu dari target tersebut.
2.4.4
Regresi
Menurut Han dan Kamber (2011, p245), Regresi merupakan fungsi
pembelajaran yang memetakan sebuh unsur data ke sebuah variabel prediksi
bernilai nyata.
2.5
Metode Data Mining
Menurut Han dan Kamber (2011, p327), metode data mining terdiri dari:
2.5.1
Naïve Bayes
Naïve Bayes merupakan pengklasifikasian dengan metode probabilitas
dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes.
Menurut Olson dan Delen (2008, p102) menjelaskan Naïve bayes
untuk
setiap kelas keputusan, menghitung probabilitas dengan syarat bahwa kelas
keputusan adalah benar, mengingat vektor informasi obyek. Algoritma ini
mengasumsikan bahwa atribut obyek adalah independen. Probabilitas yang
terlibat dalam memproduksi perkiraan akhir dihitung sebagai jumlah
frekuensi dari "master"
tabel keputusan. Sedangkan menurut Han dan
Kamber (2011, p351) Proses dari The Naïve Bayesian classifier, atau Simple
Bayesian Classifier, sebagai berikut:
1.
Variable D menjadi pelatihan set tuple dan label yang terkait dengan
kelas. Seperti biasa, setiap tuple
diwakili oleh vektor atribut n-
dimensi, X = (x1, x2, ..., xn), ini menggambarkan pengukuran n
dibuat pada tuple dari atribut n, masing-masing, A1, A2, ..., An.
2.
Misalkan ada kelas m, C1, C2, ..., Cm. Diberi sebuah tuple, X,
classifier
akan memprediksi X yang masuk kelompok memiliki
probabilitas posterior
tertinggi, kondisi-disebutkan pada X. Artinya,
classifier naive bayesian
memprediksi bahwa X tuple
milik kelas Ci
jika dan hanya jika :
Gambar 2.11 Rumus Classifier Naïve Bayesian (1)
Sumber: Han dan Kamber (2011, p351)
|
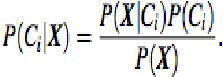 19
Jadi memaksimalkan P (Ci | X). Ci kelas yang P (Ci | X)
dimaksimalkan disebut hipotesis posteriori maksimal. Dengan teorema
Bayes:
Gambar 2.12: Rumus Classifier Naïve Bayesian (2)
Sumber: Han dan Kamber (2011, p351)
Keterangan :
P(Ci|X) = Probabilitas hipotesis Ci jika diberikan fakta atau record X
(Posterior probability)
P(X|Ci) = mencari nilai parameter yang memberi kemungkinan yang
paling besar (likelihood)
P(Ci) = Prior probability dari X (Prior probability)
P(X) = Jumlah probability tuple yg muncul
1.
Ketika P (X) adalah konstan untuk semua kelas, hanya P (X | Ci) P
(Ci) butuh dimaksimalkan. Jika probabilitas kelas sebelumnya
tidak diketahui, maka umumnya diasumsikan ke dalam kelas yang
sama, yaitu, P (C1) = P (C2) = · · · = P (Cm), maka dari itu akan
memaksimalkan P (X | Ci). Jika tidak, maka akan memaksimalkan
P (X | Ci) P (Ci). Perhatikan bahwa probabilitas sebelum kelas
dapat diperkirakan oleh P (Ci) = | Ci, D | / | D |, dimana | Ci, D |
adalah jumlah tuple pelatihan kelas Ci di D.
2.
Mengingat dataset
mempunyai banyak atribut, maka akan sangat
sulit dalam mengkomputasi untuk menghitung P(X|Ci). Agar
dapat mengurangi
perhitungan dalam mengevaluasi P(X|Ci),
asumsi naïve independensi kelas bersyarat dibuat. Dianggap
bahwa nilai-nilai dari atribut adalah kondisional independen satu
sama lain, diberikan kelas label dari tuple
(yaitu bahwa tidak ada
hubungan ketergantungan diantara atribut ) dengan demikian :
|
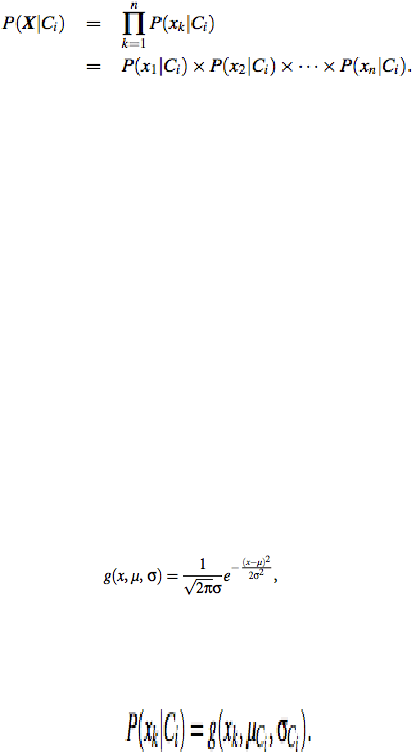 20
Gambar 2.13 : Rumus Classifier Naïve Bayesian (3)
Sumber: Han dan Kamber (2011, p351)
Maka dapat dengan mudah memperkirakan probabilitas P (x1 |
Ci), P (x2 | Ci),. . . , P (xn | Ci) dari pelatihan tuple.
Ingat
bahwa di sini xk mengacu pada nilai atribut Ak untuk tuple X.
Untuk setiap atribut, dilihat dari apakah atribut tersebut
kategorikal atau continuous-valued . Misalnya, untuk
menghitung P (X | Ci) mempertimbangkan hal-hal berikut:
a.
Jika Ak adalah kategorikal, maka P (Xk | Ci) adalah
jumlah tuple kelas Ci di D memiliki nilai Xk untuk atribut
Ak, dibagi dengan | Ci, D |, jumlah tuple kelas Ci di D.
b.
Jika Ak continuous-valued , maka perlu melakukan sedikit
lebih banyak pekerjaan, tapi perhitunganya cukup
sederhana.
Sebuah atribut continuous-valued
biasanya
diasumsikan memiliki distribusi Gaussian dengan rata-rata
µ dan standar deviasi s, didefinisikan oleh:
Gambar 2.14 : Rumus Classifier Naïve Bayesian (4)
Sumber: Han dan Kamber (2011, p351)
sehingga :
Gambar 2.15 : Rumus Classifier Naïve Bayesian (5)
Sumber: Han dan Kamber (2011, p351)
Setelah itu hitung µCi dan sCi, yang merupakan deviasi
mean
(rata-rata) dan standar masing-masing nilai atribut k
untuk tuple
pelatihan kelas Ci. Setelah itu gunakan kedua
|
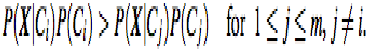 21
kuantitas dalam Persamaan, bersama-sama dengan xk, untuk
memperkirakan P (xk | Ci).
3.
Untuk memprediksi label kelas x, P(X|Ci)P(Ci) dievaluasi untuk
setiap kelas Ci. Classifier
memprediksi kelas
label
dari
tuple
x
adalah kelas Ci, jika
Gambar 2.16 : Rumus Classifier Naïve Bayesian (6)
Sumber: Han dan Kamber (2011, p351)
Dengan kata lain, label kelas diprediksi adalah Ci yang mana P
(X | Ci) P (Ci) adalah maksimal.
Pengklasifikasi Bayesian
memiliki tingkat kesalahan
minimal dibandingkan dengan klasifikasi lainnya. Namun,
dalam prakteknya hal ini tidak selalu terjadi, karena
ketidakakuratan asumsi yang dibuat untuk penggunaannya,
seperti kondisi kelas independen, dan kurangnya data
probabilitas yang tersedia. Pengklasifikasi Bayesian
juga
berguna dalam memberikan pembenaran teoritis untuk
pengklasifikasi lain yang tidak secara eksplisit menggunakan
teorema Bayes.
2.5.2
Decision Tree
Menurut Han dan Kamber (2011, p332),
Decision Tree adalah
top-down pohon rekursif dari algoritma induksi, yang
menggunakan
ukuran seleksi atribut untuk memilih atribut yang diuji.
Algoritma
decision tree mencoba untuk meningkatkan akurasi
dengan
menghapus cabang-cabang pohon yang mencerminkan noise dalam
data. Decision tree merupakan salah satu teknik yang dapat digunakan
untuk
melakukan klasifikasi terhadap sekumpulan objek atau record.
Teknik ini terdiri dari
kumpulan decision node, dihubungkan oleh
cabang, bergerak ke bawah dari root node
sampai berakhir di leaf
node (Yusuf, 2009).
Decision Tree
adalah sistem pendukung
keputusan
yang berupa pohon grafik
keputusan.
Decision Tree
|
 22
digunakan untuk belajar classification
function
yang menyimpulkan
nilai atribut dependen (variabel). (Girja, Bhargava & Mathuria, 2013)
Entropy
Entropy "digunakan dalam proses ini. Entropy
adalah
ukuran dari gangguan (disorder) data. Entropy diukur dalam
bit. Ini
juga disebut pengukuran ketidakpastian dalam setiap
variabel acak. (Girja, Bhargava & Mathuria, 2013)
Gambar 2.17 : Rumus Entropy
Sumber: (Girja, Bhargava & Mathuria, 2013)
Information Gain
Informasi Gain
adalah untuk mengukur input dan
output diantara asosiasi. (Girja, Bhargava & Mathuria, 2013)
Gambar 2.18 : Rumus Information Gain
Sumber: (Girja, Bhargava & Mathuria, 2013)
Confusion Matrix
Confusion Matrix berisi informasi aktual dan klasifikasi
prediksi dilakukan dengan sistem klasifikasi. Kinerja sistem
nya menggunakan data dalam matriks.
(Girja, Bhargava &
Mathuria, 2013)
Confidence
Confidence
adalah ukuran yang menilai tingkat
kepastian asosiasi terdeteksi, ini diambil sebagai probabilitas
bersyarat P (Y | X), yaitu probabilitas bahwa transaksi yang
mengandung X juga Berisi Y (Han dan Kamber,2011,p21).
Support
Support
adalah ukuran yang mewakili persentase
transaksi dari database
transaksi yang diberikan aturan yang
|
|
23
memuaskan, ini diambil untuk menjadi P probabilitas (XUY),
di mana XUY menunjukkan bahwa transaksi berisi baik X dan
Y, yaitu sekumpulan itemset
X dan Y. (Han dan
Kamber,2011,p21)
2.5.3
K-Means
Menurut Aryan (2010) K-Means merupakan algoritma yang
umum digunakan untuk clustering dokumen. Prinsip utama K-Means
adalah menyusun k prototype
atau pusat massa (centroid) dari
sekumpulan data berdimensi n. Sebelum diterapkan proses algoritma
K-means, dokumen akan di preprocessing terlebih dahulu. Kemudian
dokumen direpresentasikan sebagai vektor
yang memiliki term
dengan nilai tertentu. Sedangkan menurut Chen yu (2010), K-Means
merupakan algoritma untuk cluster
n objek berdasarkan atribut
menjadi k partisi, dimana k < n.
Dari teori-teori yang dijabarkan oleh para ahli diatas, bahwa
K-means
merupakan salah satu metode data clustering non hirarki
untuk clustering dokumen yang berusaha mempartisi data yang ada ke
dalam bentuk satu atau lebih cluster/kelompok
berdasarkan atribut
menjadi k partisi, dimana k < n.
Algoritma K-means
Menurut Widyawati, (2010), Algoritma k-means
merupakan algoritma yang membutuhkan parameter input
sebanyak k dan membagi sekumpulan n objek kedalam k cluster
sehingga tingkat kemiripan antar anggota dalam satu cluster tinggi
sedangkan tingkat kemiripan dengan anggota pada cluster
lain
sangat rendah. Kemiripan anggota terhadap cluster diukur dengan
kedekatan objek terhadap nilai mean
pada cluster
atau dapat
disebut sebagai centroid cluster atau pusat massa.
Menurut Kantardzic (2009), teknik data mining
yang
paling umum, antara lain:
Metode statistika klasik yaitu linier, quadratic dan
logistic
discriminate analyses.
|
 24
Teknik statistika modern
yaitu projection pursuit
classification, density estimation, k-nearest neighbor,
Bayesian networks.
Artificial Neural Network (ANN), yaitu model matematis yang
meniru atau mensimulasikan struktur dan aspek fungsi dari
jaringan saraf biologis.
Support Vector Machine (SVM), yaitu rangkaian metode
supervised learning
yang digunakan untuk klasifikasi dan
regresi.
Decision Trees (DT), yaitu
tool pendukung suatu
keputusan yang menggunakan grafik seperti pohon atau
model keputusan yang terdiri dari konsekuensi-konsekuensi.
Association Rules (AR), yaitu suatu metode riset untuk
menemukan hubungan yang menarik antar variabel dalam
suatu database yang besar.
Case Based Reasoning (CBS), yaitu proses untuk
memecahkan suatu masalah baru berdasarkan solusi dari
masalah-masalah masa lalu yang mirip.
Fuzzy Logic System (FLS),
yaitu sebuah bentuk dari logika
nilai ganda yang terkait dengan kesimpulan dari suatu alasan
(reasoning) secara pendekatan. Logika fuzzy mempunyai nilai
kebenaran diantara 0 dan 1.
Genetic Algorithms (GA), yaitu algoritma pencarian heuristic
yang meniru proses evolusi alam (genetika), untuk
mendapatkan solusi yang optimum.
Semakin meningkatnya kompleksitas dari sistem, maka beberapa
teknik data mining digunakan secara bersama-sama dalam suatu penelitian.
Menurut Paton & Amazouz (2009), beberapa peneliti menggunakan
gabungan teknik data mining
untuk mendapatkan kelebihan dari masing-
masing teknik diantaranya :
Hall Barbosa et al (2009) menggunakan Bayesian Neural Network untuk
memprediksi kualitas dari produk destilasi untuk REPAR refinery di
Brazil.
|
|
25
Zhou (2009) mengembangkan model NN untuk memonitor proses,
deteksi kegagalan (fault)
dan skema klasifikasi pada batch
reaktor
polimerisasi dalam proses produksi polymethylmethacrylate. Feedforward
NN digunakan untuk memodelkan proses dan radial basis function (RBF)
NN digunakan untuk klasifikasi. Zhou menggunakan regresi polynomial
untuk mereduksi dimensi dari model NN.
Zamprogna et al (2010) mengembangkan model berdasarkan PCA dan
Partial Least Squares (PLS) untuk memonitor proses dan untuk
mendeteksi ubnormality
pada proses penuangan logam (steel casting).
PCA/PLS digunakan untuk mengidentifikasi korelasi data dalam kondisi
normal. Model memberikan pemahaman yang mendalam mengenai
interaksi antar parameter proses sehingga dapat digunakan untuk
mendeteksi kegagalan (ubnormality) di dalam proses.
Ahvenlamp et al (2010) menggunakan kombinasi NN dan fuzzy logic
untuk memprediksi nomor Kappa dan untuk memonitor perubahan
di dalam variabel proses, untuk mendeteksi kegagalan dan untuk maksud
klasifikasi. Dilaporkan bahwa kombinasi ini mempunyai performa
prediksi yang baik dan dapat mendeteksi perilaku abnormal
bahkan
ketika deviasinya kecil.
2.6
Framework Data Mining
Beberapa framework penerapan data mining telah dikembangkan berdasarkan
proses bisnis industri dan bisnis. Framework tersebut dikembangkan karena kegiatan
data mining
semakin kompleks dengan melibatkan banyak data, kepakaran yang
bervariasi ataupun lingkungan bisnis yang beragam. Karena itu, frameworks data
mining
diharapkan dapat dijadikan sebagai panduan untuk proses koleksi data,
analisis, diseminasi hasil data mining dan pengembangan dari penerapan data mining
tersebut. Beberapa framework yang berkembang saat ini adalah:
1.
CRISP (Cross Industrial Standard Process for Data Mining). Framework
ini diusulkan oleh konsorsium Uni Eropa. Secara umum CRISP terdiri
dari tahapan pemahaman pada proses bisnis dan data, persiapan data,
pemodelan, evaluasi dan penerapan.
2.
DMAIC (Define-Measure-Analyze-Improve-Control).
Framework
ini
berdasarkan pada metodologi Six-Sigma
yang ditujukan untuk
mengeliminasi cacat, pemborosan, berorientasi pada pengendalian
|
|
26
kualitas dalam kegiatan manufaktur, industri jasa, manajemen dan
aktivitas lainnya.
3.
SEMMA (Sample-Explore-Modify-Model-Assess).
Framework
ini
dikembangkan oleh SAS (Statistical Analysis Sistem) Institute.
Framework ini mempunyai tahapan yang mirip dengan Six-Sigma.
2.7
WEKA
WEKA merupakan API Java yang menyediakan API untuk pengolahan
dalam data mining yang berbasis open source (GPL) dan berengine JAVA. WEKA
dikembagkan oleh Universitas Waikato di Selandia Baru dan juga merupakan
perangkat lunak gratis yang tersedia dibawah GNU (General Public License).
WEKA menyediakan penggunaan teknik klasifikasi menggunakan pohon keputusan
dengan algoritma J48. Teknik yang digunakan WEKA adalah classifier.
Menurut situs resmi WEKA (Waikato Environment for Knowledge Analysis),
“WEKA is a collection of machine learning algorithms for data mining tasks. The
algorithms can either be applied directly to a dataset or called from your own Java
code. Weka contains
tools for data pre-processing, classification, regression,
clustering, association rules, and visualization. It is also well-suited for developing
new machine learning schemes.”
The Waikato Environment for Knowledge Analysis (Weka) adalah rangkaian
lengkap perpustakaan kelas Java yang mengimplementasikan banyak state-of-the-art
pembelajaran mesin dan algoritma data mining. Weka tersedia secara bebas di World
Wide Web dan menyertai teks baru pada dokumen data mining dan sepenuhnya
menjelaskan semua algoritma yang dikandungnya. Aplikasi yang ditulis
menggunakan library class pada Weka
yang
dapat dijalankan pada komputer
manapun dengan kemampuan browsing Web, ini memungkinkan pengguna untuk
menerapkan teknik pembelajaran mesin untuk data mereka sendiri terlepas dari
platform komputer. (Witten, Frank & Hall, 2011)
|
 27
Gambar 2.19 : Tampilan Awal GUI WEKA
Sumber: www.cs.waikato.ac.nz/ml/weka/
WEKA mulai dikembangkan sejak tahun 1994 dan telah menjadi software data
mining open source yang paling popular. WEKA mempunyai kelebihan seperti
mempunyai banyak algoritma data mining dan machine learning, kemudahan dalam
penggunaannya, selalu up-to-date dengan algoritma-algoritma yang baru. Software
WEKA tidak hanya digunakan untuk akademik saja namun cukup banyak dipakai
oleh perusahaan untuk meramalkan bisnis dari suatu perusahaan. Ian H. Witten
merupakan latar belakang dibalik kesuksesan WEKA. Beliau merupakan profesor di
Universitas of Waikato, New Zealend, yang menekuni Digital Library, Text Mining,
Machine Learning dan
Information Retrieval. Pada Weka ada beberapa metode
pemilihan variable
dari suatu dataset,
diantaranya BestFirst, ExhautiveSearch,
FCBFSearch, GeneticSearch, GreedyStepwise,
RaceSearch, RandomSearch,
Rankerdan,
RankerSearch.
Metode atau Teknik yang digunakan Weka adalah
Predictive
dan Descriptive
karena Weka mendukung teknik-teknik data
preprocessing, clustering, classification, regression, visualization, dan
feature
Reduction. Semua teknik Weka adalah didasarkan pada asumsi bahwa data tersedia
sebagai flat file
tungggal atau hubungan, dimana setiap titik data digambarkan oleh
sejumlah tetap atribut (biasanya, atribut numeric atau nominal, tetapi beberapa jenis
atribut lain juga didukung).
2.7.1
Format Input WEKA
WEKA mendukung beberapa format file untuk inputnya, yaitu:
Comma Separated Values
(CSV): Merupakan file
teks dengan
pemisah tanda koma (,) yang cukup umum digunakan. File ini
dapat dibuat dengan menggunakan Microsoft Excel atau membuat
sendiri dengan menggunakan notepad.
|
|
28
Format
C45: Merupakan format file
yang dapat diakses dengan
menggunakan aplikasi WEKA.
Attribute-Relation File Format (ARFF): Merupakan tipe file teks
yang berisi berbagai
instance
data yang berhubungan dengan
suatu set atribut data yang dideskripsikan serta di dalam file
tersebut.
SQL Server/MySql Server: Dapat mengakses database
dengan
menggunakan SQL Server/MySql Server.
2.7.2
Algoritma J48 pada WEKA
J48 merupakan implementasi C4.5 pada WEKA.
J48
menangani
himpunan data dalam format ARFF, tidak mengandung kode untuk
mengkonstruksi pohon keputusan. Kelas ini mereferensi kelas-kelas lain,
kebanyakan pada paket Weka. Classifiers J48, yang mengerjakan semua
proses konstruksi pohon.Adapun kelebihan C4.5 antara lain:
C4.5 mampu menangani atribut dengan tipe diskrit atau kontinu
C4.5 mampu menangani atribut yang kosong (Missing Value)
C4.5 telah berkembang menjadi C5. C4.5 merupakan pengembangan
dari ID3 (Iterative Dichotomiser 3).
ID3 merupakan algoritma yang
dipergunakan untuk membuat sebuah decision tree
atau pohon keputusan.
Algoritma ID3 ditemukan oleh J. Ross Quinlan, dengan memanfaatkan teori
informasi milik Shanon. Idenya adalah membuat pohon dengan percabangan
awal yang dapat membagi antara iya dan tidak. Pada WEKA ada pilihan
untuk menggunakan ID3 dengan nama yang sama dan atributnya harus
bertipe nominal dan tidak boleh terdapat atribut yang kosong.
2.7.3
Algoritma Naive Bayes pada WEKA
Proses klasifikasi (classify) menggunakan metode Naïve Bayesian
Classifier
(dalam software Weka disebut sebagai metode NaïveBayes).
WEKA dapat digunakan sebagai perangkat lunak pembelajaran mesin untuk
menghasilkan dan model uji Naive Bayes secara otomatis. Kelas untuk Naive
Bayes classifier
menggunakan kelas estimator. Nilai estimator presisi
Numeric
dipilih berdasarkan analisis data training. Classifier
ini akan
menggunakan presisi default 0,1 untuk atribut numerik ketika buildClassifier
|
|
29
disebut dengan kasus tarining
nol. Naive Bayes
tidak memilih fitur penting.
Hasil dari training Naive Bayes classifier
adalah mean
dan varians untuk
setiap fitur. Klasifikasi sampel baru ke 'Ya' atau 'Tidak' didasarkan pada
apakah nilai-nilai fitur dari sampel test
terbaik dengan rata-rata dan varians
dari fitur yang menjadi training baik untuk 'Ya' atau 'Tidak'.
2.7.4
Test Options WEKA
WEKA memiliki empat jenis test option, yaitu:
Use training set: Classifier
ini dilakukan dengan menggunakan
data training itu sendiri.
Supplied test set: Classifier
ini dievaluasi dengan memprediksi
seberapa baik satu set class
yang diambil dari sebuah file. Test
option
ini dilakukan dengan menggunakan data lain. Cara yang
dilakukan adalah dengan mengklik set tombol yang menampilkan
dialog yang memungkinkan untuk memilih file untuk menguji.
Cross-validation: Classifier
ini dievaluasi oleh cross-validation,
menggunakan jumlah fold yang dimasukkan ke dalam kolom teks
folds. Pada cross-validation akan ada pilihan berapa fold
yang
akan digunakan. Nilai default-nya adalah 10.
Percentage split: Classifier
ini dievaluasi dengan memprediksi
seberapa baik persentase dari data yang digunakan selama
pengujian. Jumlah data tersebut dibagi berdsarkan nilai yang
dimasukkan ke dalam field%.
2.8
Structure Query Language (SQL)
Menurut Connolly & Begg (2010, p221), Structure Query Language atau
SQL adalah non producedural language terdiri dari kata english
standar seperti
SELECT, INSERT, dan DELETE yang digunakan oleh profesional dan non-
profesional. SQL menggunakan bahasa yang standar untuk mendefinisikan dan
memanipulasi hubungan database. Sedangkan, menurut Hall (2011, p787), Structure
Query Language adalah suatu alat pengolahan data untuk pengguna dan programmer
profesional untuk mengakses data dalam basis data secara langsung tanpa
membutuhkan program konvensional.
Dari beberapa teori yang dijabarkan oleh para ahli diatas, bahwa Structure
Query Language atau SQL adalah suatu alat pengolahan data untuk pengguna dan
|
|
30
programmer profesional untuk mengakses data non producedural
language seperti
SELECT, INSERT, dan DELETE.
2.9
Data Warehouse
Menurut Turban (2011, p52), Data Warehouse
adalah kumpulan data yang
dibuat untuk mendukung pengambilan keputusan dan juga merupakan tempat
penyimpanan data sekarang dan lampau. Data warehouse
memiliki bentuk bentuk,
yaitu:
Functional Data Warehouse
Functional Data Warehouse dibuat lebih dari satu dan dikelompokkan
berdasarkan masing-masing fungsinya. Penerapan jenis pengumpulan data
dengan tipe ini dapat beresiko kehilangan konsistensi data diluar lingkungan
bisnis.
Centralized Data Warehouse
Centralized Data Warehouse terlihat seperti bentuk Functional Data
Warehouse,
namun seumber data terlebih dahulu dikumpulkan dan
diintegrasikan secara terpusat pada suatu tempat, dan setelah itu, data dapat
dibagi-bagi berdasarkan fungsi-fungsi yang dibutuhkan. Pada bentuk ini,
pemakai hanya dapat mengambil data dari bagian pengumpulan saja, dan
tidak secara langsung berhubungan dengan pemasok data.
Distributed Data Warehouse
Distributed Data Warehouse
memungkinkan user
untuk berhubungan
secara langsung dengan sumber data dan pusat pengumpul data lain. Pada
bentuk ini mengandalkan keunggulan dari teknologi client-server, untuk
mengambil data dari berbagai sumber.
2.10
OLTP (Online Transaction Processing)
Menurut Kimball (2010, p408), OLTP adalah gambaran pasti dari segala
aktifitas dan asosiasi sistem dengan menginput data yang dapat dipercaya ke dalam
database. OLTP menggambarkan sebuah kebutuhan sistem dalam ruang lingkup
operasional dan merupakan proses yang dapat mendukung kegiatan bisnis sehari –
hari.
Sedangkan, menurut Connolly dan Begg (2010, p1199), OLTP adalah sebuah
sistem yang telah dirancang untuk menangani pemrosesan transaksi tingkat tinggi.
Dari beberapa teori yang dijabarkan oleh para ahli diatas, dapat diambil
kesimpulan bahwa OLTP (Online Transaction Processing),
merupakan sebuah
|
|
31
sistem yang telah dirancang untuk menangani pemrosesan transaksi tingkat tinggi
yang dapat mendukung kegiatan bisnis sehari – hari.
2.11
ETL (Extraction Transformation Loading)
Menurut Vercellis (2009, p53), ETL (Extraction Transformation Loading)
mengacu pada alat piranti lunak yang didedikasikan untuk melakukan ekstraksi,
transformasi, dan load data ke dalam data warehouse.
Menurut Kimball dan Ross (2010, p8) Extract-transform-load
(ETL) adalah
kumpulan dari proses dimana sumber data operational
disiapkan untuk dimasukan
kedalam data warehouse. Proses
ekstraksi
(extracting) data operational dari
sumber aplikasi, mengubah bentuknya (transform), mengeluarkan (loading) dan
membuat index dari data itu, menjamin kualitas dari data tersebut, dan menerbitkan
data tersebut.
1.
Menurut Kimball dan Ross (2010, p8), extraction adalah langkah pertama
dalam proses memasukkan data ke dalam lingkungan data warehouse.
Extracting berarti membaca dan memahami sumber data dan menyalin data
yang dibutuhkan untuk data warehouse ke dalam staging area untuk
manipulasi lebih jauh.
2.
Data Transforming
Menurut Kimball dan Ross (2010, p8), setelah data di–ekstrak ke staging
area, ada banyak perubahan yang mungkin dilakukan, seperti cleansing data
(memperbaiki kesalahan ejaan, mengatasi konflik domain, menangani bagian
yang hilang, atau parsing ke dalam format standar), menggabungkan data dari
berbagai sumber, menghilangkan data berulang, dan memberikan warehouse
keys.
3.
Data Loading
Menurut Kimball dan Ross (2010, p8),setelah melakukan transformasi
maka data dapat dimuat ke dalam data warehouse.
Sedangkan, menurut
Connolly dan Begg (2010, 1208), loading data ke dalam data warehouse
dapat terjadi setelah semua transformasi telah terjadi atau sebagai bagian dari
proses transformasi.
Trigger
yang akan aktif pada saat dilakukan loading
data, juga berkontribusi pada kualitas seluruh kinerja data pada proses ETL.
Dari beberapa teori yang dijabarkan oleh para ahli diatas, dapat diambil
kesimpulan bahwa ETL (Extraction Transformation Loading) mengacu pada
alat
|
|
32
piranti lunak dimana sumber data operational disiapkan untuk dimasukan kedalam
data warehouse. Proses ekstraksi (extracting) data operational dari sumber aplikasi,
mengubah bentuknya (transform), mengeluarkan (loading) dan membuat index dari
data itu, menjamin kualitas dari data tersebut, dan menerbitkan data tersebut.
2.12
Star Schema
Menurut Turban (2011, p75), Skema Bintang (Star Schema) adalah sebuah
dimensional modeling yang menampilkan satu atau beberapa table
fakta yang
terhubung dengan beberapa table
dimensi, dimana table
fakta mengandung atribut
deskriptif dan table dimensi menandung klasifikasi dan kumpulan informasi tentang
nilai dari table
fakta. Sedangkan, menurut Connolly dan Begg (2010, p1227), star
schema adalah struktur logikal
yang memiliki tabel fakta yang memuat data faktual
di pusat dan dikelilingi oleh tabel dimensi yang memuat data referensi (yang dapat
didenormalisasi).
Fact table
Menurut Connolly dan Begg (2010, p1227), tabel fakta merupakan tabel
yang memiliki sebuah composite primary key dimana tabel tersebut akan
membentuk sebuah model dimensional.
Dimention Table
Menurut Connolly dan Begg (2010, p1227), tabel dimensi merupakan
sekumpulan dari tabel-tabel yang lebih kecil yang memiliki sebuah
primary key sederhana yang merespon secara benar terhadap salah satu
komponen dari composite key yang ada dari tabel fakta.
Dari beberapa teori yang dijabarkan oleh para ahli diatas, dapat diambil
kesimpulan bahwa Skema Bintang (Star Schema) adalah struktur logikal
yang
menampilkan satu atau beberapa table
fakta yang terhubung dengan beberapa table
dimensi.
2.13
Rumah Sakit
Rumah sakit adalah suatu badan usaha yang menyediakan dan memberikan
jasa pelayanan medis jangka pendek dan jangka panjang yang terdiri atas tindakan
observasi, diagnostik, terapeutik dan rehabilitative
untuk orang-orang yang
menderita sakit, terluka dan untuk yang melahirkan (World Health Organization).
Rumah sakit merupakan sarana upaya kesehatan serta dapat dimanfaatkan
untuk pendidikan tenaga kesehetan dan penelitian (permenkes no.159b/1988)
|
|
33
UU NO.44 tahun 2009 tentang rumah sakit, rumah sakit adalah institusi
pelayanan kesehatan yang menyelenggarakan pelayanan kesehatan perorangan secara
paripurna yang menyediakan pelayanan rawat inap, rawat jalan dan gawat darurat.
Pelayanan rumah sakit juga diatur dalam KODERSI/kode etik rumah sakit, dimana
kewajiban rumah sakit terhadap karyawan, pasien dan masyarakat diatur.
Berdasarkan Pasal 29 ayat (1) huruf f dalam UU No. 44 Tahun 2009 tentang
Rumah Sakit. Rumah Sakit sebenarnya memiliki fungsi sosial yaitu antara lain
dengan memberikan fasilitas pelayanan pasien tidak mampu/miskin, pelayanan
gawat darurat tanpa uang muka, ambulans
gratis, pelayanan korban bencana dan
kejadian luar biasa, atau bakti sosial bagi misi kemanusiaan. Pelanggaran terhadap
kewajiban tersebut bisa berakibat dijatuhkannya sanksi kepada Rumah Sakit tersebut,
termasuk sanksi pencabutan izin.
2.14
Rekam Medik
Menurut Edna K Huffman, Rekam medik adalah berkas yang menyatakan
siapa, apa, mengapa, dimana,
kapan, dan bagaimana pelayanan yang diperoleh
seorang pasien selama dirawat atau menjalani pengobatan.
Menurut Permenkes No. 79a/Menkes /Per/XII/1989, Rekam medik adalah
berkas yang berisi catatan dan dokumen mengenai identitas pasien, hasil
pemeriksaan, pengobatan, tindakan dan pelayanan lainnya yang diterima pasien pada
sarana kesehatan, baik rawat jalan maupun rawat inap.
Menurut Gemala Hatta, Rekam Medik merupakan kumpulan fakta tentang
kehidupan seseorang dan riwayat penyakitnya, termasuk keadaan sakit, pengobatan
saat ini, dan saat lampau yang ditulis oleh para praktisi kesehatan dalam upaya
mereka membiarkan pelayanan kesehatan kepada pasien.
Berdasarkan pengertian diatas rekam medik adalah suatu catatan dari setiap
orang yang melakukan pengobatan, yang berisi tentang data riwayat penyakit saati
ini dan masa lampau yang ditulis oleh praktisi kesehatan.
2.15
ICD-10
Menurut WHO (2004) ICD-10 merupakan klasifikasi statistik, yang terdiri
dari sejumlah kode alfanumerik yang satu sama lain berbeda (mutually exclusive)
menurut kategori, yang menggambarkan konsep seluruh penyakit.
Menurut WHO (2004), ICD-10 terdiri dari 3 volume yaitu:
1.
Volume 1 berisi klasifikasi utama.
|
|
34
Sebagian besar buku Volume 1 terdiri dari daftar kategori3 karakter
dan daftar tabel inklusi dan subkategori 4 karakter. Inti klasifikasi adalah
daftar kategori 3 karakter yang dianjurkan untuk pelaporan ke
WHO mortality database dan perbandingan umum internasional. Daftar bab
dan judul blok juga termasuk inti klasifikasi. Daftar tabular memberikan
seluruh rincian level 4 karakter dan dibagi dalam 22 bab.
2.
Volume 2 berisi petunjuk pemakaian ICD
3.
Volume 3 berisi alfabet klasifikasi, dibagi dalam 3 bagian:
Bagian 1, terdiri atas indeks tentang penyakit dan luka alami.
Bagian 2, merupakan indeks
penyebab luar morbiditas dan
mortalitas, berisi seluruh term yang diklasifikasi.
Bagian 3, berisi tabel obat dan bahan kimia.
Kode utama untuk penyakit yang mendasari diberi tanda dagger (†) dan
kode tambahan untuk manifestasinya diberi tanda asterisk (*). Kode dagger adalah
kode utama dan harus selalu digunakan. Dalam coding, kode asterisk tidak bisa
digunakan sendiri
|