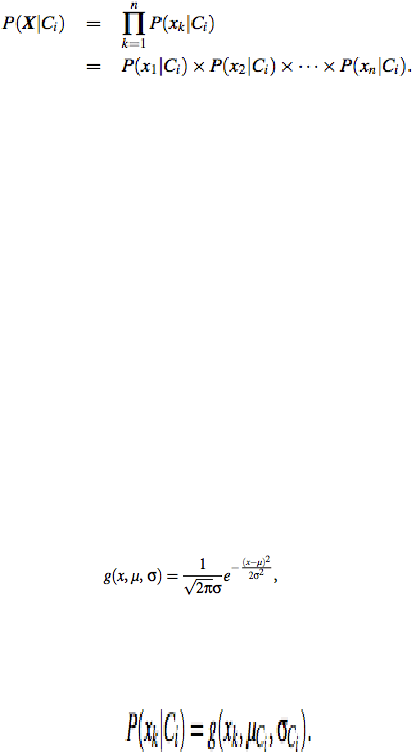
20
Gambar 2.13 : Rumus Classifier Naïve Bayesian (3)
Sumber: Han dan Kamber (2011, p351)
Maka dapat dengan mudah memperkirakan probabilitas P (x1 |
Ci), P (x2 | Ci),. . . , P (xn | Ci) dari pelatihan tuple.
Ingat
bahwa di sini xk mengacu pada nilai atribut Ak untuk tuple X.
Untuk setiap atribut, dilihat dari apakah atribut tersebut
kategorikal atau continuous-valued . Misalnya, untuk
menghitung P (X | Ci) mempertimbangkan hal-hal berikut:
a.
Jika Ak adalah kategorikal, maka P (Xk | Ci) adalah
jumlah tuple kelas Ci di D memiliki nilai Xk untuk atribut
Ak, dibagi dengan | Ci, D |, jumlah tuple kelas Ci di D.
b.
Jika Ak continuous-valued , maka perlu melakukan sedikit
lebih banyak pekerjaan, tapi perhitunganya cukup
sederhana.
Sebuah atribut continuous-valued
biasanya
diasumsikan memiliki distribusi Gaussian dengan rata-rata
µ dan standar deviasi s, didefinisikan oleh:
Gambar 2.14 : Rumus Classifier Naïve Bayesian (4)
Sumber: Han dan Kamber (2011, p351)
sehingga :
Gambar 2.15 : Rumus Classifier Naïve Bayesian (5)
Sumber: Han dan Kamber (2011, p351)
Setelah itu hitung µCi dan sCi, yang merupakan deviasi
mean
(rata-rata) dan standar masing-masing nilai atribut k
untuk tuple
pelatihan kelas Ci. Setelah itu gunakan kedua