|
2.1
Pengertian Data
Menurut Inmon (2005, p493) Data adalah suatu pencetakan dari fakta,
konsep, atau instruksi dalam suatu media penyimpanan untuk komunikasi,
pencarian, dan pemprosesan dengan menggunakan alat otomatis dan
presentasi sebagai informasi yang dapat dimengerti oleh manusia.
Menurut O’Brien (2005, p38) Data adalah fakta atau observasi mentah,
yang biasanya mengenai fenomena fisik atau transaksi bisnis.
2.1.2
Pengertian Informasi
Menurut Vercellis (2009, p7), informasi adalah kumpulan dari kegiatan
ekstraksi pengolahan yang dilakukan pada data dan memiliki arti bagi orang
yang menerimanya pada domain yang spesifik.
Menurut O’Brien (2005, p38) informasi adalah data yang telah diubah
menjadi konteks yang berarti dan berguna bagi para pengguna akhir tertentu.
Menurut Brown, DeHayes, Hoffer, Martin, & Perkins (2009, p. 727),
informasi adalah data yang berguna untuk manajemen tingkat atas yang
digunakan untuk mengambil keputusan.
Pengertian Database
Menurut Connolly dan Begg (2005, p14), database adalah sekumpulan
data dan deskripsi dari data yang berhubungan secara logical didesain untuk
menemukan kebutuhan informasi dari organisasi.
Menurut Inmon (2005,p493) database merupakan koleksi data-data
yang saling berhubungan yang tersimpan berdasarkan suatu skema tertentu.
Database dapat digunakan untuk aplikasi tunggal atau berganda.
Menurut Inmon (2005,p493) database merupakan koleksi data-data
yang saling berhubungan yang tersimpan berdasarkan suatu skema tertentu.
Database dapat digunakan untuk aplikasi tunggal atau berganda.
|
|
2.1.4
Pengertian Data warehouse
Menurut Connolly dan Begg (2010,p1197), data warehouse merupakan
sekumpulan data yang berorientasi subjek, terintegrasi, tidak mudah berubah,
dan berdasarkan kepada suatu rentang waktu tertentu yang berguna untuk
mendukung proses pengambilan keputusan. Sebuah data warehouse
merupakan data manajemen dan teknologi analisis data.
Menurut Inmon (2005, p389), data warehouse adalah sekumpulan data
yang terintegrasi, berorientasi pada subjek yang dirancang dan digunakan
untuk mendukung proses pengambilan keputusan dimana setiap unit dari data
bersifat saling berhubungan untuk beberapa waktu tertentu.
Menurut Connolly & Begg (2005,
p. 1152), data warehouse
yang telah dirancang dan diimplementasikan dengan baik dapat
memberikan keuntungan yang besar bagi organisasi, yaitu:
a.
Potensi nilai kembali yang besar pada investasi.
Dalam upaya menghasilkan informasi yang baik, sebuah
organisasi
mengeluarkan biaya dan sumber daya dalam jumlah
yang besar. Ini dilakukan untuk memastikan bahwa data
warehouse
telah diimplementasikan dengan baik dan sukses.
Setelah data warehouse digunakan di dalam organisasi, maka
tingkat pendapatan keuntungan akan lebih baik.
b.
Keuntungan Kompetitif.
Keuntungan ini didapat, ketika organisasi mendapatkan
analisis data yang sebelumnya tidak diketahui, tidak tersedia
seperti informasi tentang trend, dan pelanggan.
c.
Meningkatkan produktivitas para pengambil keputusan.
Dengan adanya data warehouse
di dalam organisasi, ini akan
meningkatkan kemampuan para pengambil keputusan untuk
|
 mampu mengambil keputusan dengan baik. Ini dikarenakan
data warehouse menyediakan database yang saling terintegrasi
satu dengan yang lainnya, sehingga kemudahan pengaliran
data dalam organisasi bias dilakukan dengan mudah. Dengan
begitu manajemen tingkat atas akan lebih mudah dalam
mengambil keputusan.
Sistem OLTP
Data warehouse
Berorientasi aplikasi
Berorientasi objek
Current data
Historical data
Data dinamis
Data besar yang statis
Membantu keputusan perhari
Membantu keputusan strategis
Tidak ada redudancy data
Ada redudancy data
Untuk komunitas karyawan
Untuk kominitas manajer
Jumlah data yang di proses
kecil
Jumlah data yang diproses
besar
2.1.5
Karakteristik Data warehouse
Menurut Inmon (2005, p. 29-32), sebuah data warehouse
memiliki
beberapa karakteristik yaitu subject oriented, integrated, nonvolatile,
dan
time variant. Dimana keempat karakteristik tersebut harus bisa
diimplementasikan di dalam sebuah data warehouse, agar suatu data
warehouse bisa secara efektif membantu mengambil keputusan.
1.
Subject Oriented
Data warehouse
berorientasi subject artinya data warehouse
didesain untuk menganalisa data berdasarkan subject-subject
tertentu dalam organisasi,bukan pada proses atau fungsi aplikasi
tertentu.
Data warehouse diorganisasikan disekitar subjek-subjek utama dari
perusahaan(customers,products dan sales) dan
tidak
diorganisasikan pada area-area aplikasi utama(customer
invoicing,stock control dan product sales). Hal ini dikarenakan
|
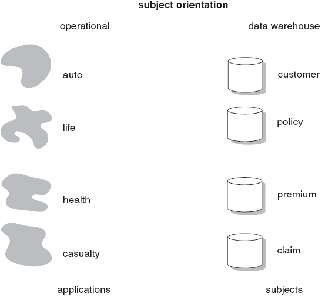 kebutuhan dari data warehouse
untuk menyimpan data-data yang
bersifat sebagai penunjang suatu keputusan, dari pada aplikasi yang
berorientasi terhadap data.
Jadi dengan kata lain, data yang disimpan adalah berorientasi
kepada subjek bukan terhadap proses.
(Sumber Inmon 2005,p30)
2.
Integrated
Organisasi yang menerapkan data warehouse
mempunyai sumber
data yang berbeda-beda dan dimana sumber data ini berasal dari
sistem dan aplikasi yang berbeda juga dimana sumber data berasal
dari bagian-bagian yang ada di dalam organisasi. Dengan
keberagaman sumber data yang ada ini, data yang ada tidak
digunakan secara konsisten di dalam organisasi. Oleh sebab itu
data yang ada harus terintegrasi satu dengan yang lainnya,
sehingga data yang ada dapat digunakan secara konsisten. Ini
bertujuan untuk memudahkan penampilan dari data untuk user.
Data warehouse
dapat menyimpan data-data yang berasal dari
sumber-sumber yang terpisah kedalam suatu format yang
konsisten dan saling terintegrasi satu dengan lainnya. Dengan
demikian data tidak bisa dipecah-pecah karena data
yang ada
|
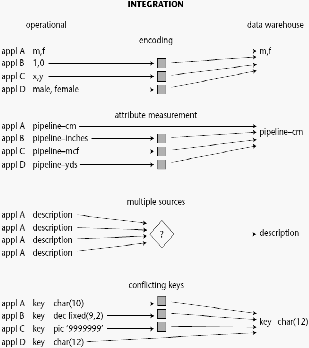 merupakan suatu kesatuan yang menunjang keseluruhan konsep
data warehouse itu sendiri.
Syarat integrasi sumber data dapat dipenuhi dengan berbagai cara
sepeti konsisten dalam penamaan variable,konsisten dalam ukuran
variable,konsisten dalam struktur pengkodean dan konsisten dalam
atribut fisik dari data.
3.
Nonvolatile
Pada karakteristik dari data warehouse
yang satu ini hanya ada
dua operasi data yang terjadi pada data warehouse, yaitu load data
dan access data. Hal ini bertujuan agar tidak terjadinya redudancy
data, karena sebelum dilakukan load
data telah dilakukan
penyaringan atau filterisasi data apa saja yang akan diambil, jadi
pada data warehouse
hanya berisi
data-data penting dan bersifat
read-only atau tidak dapat diubah.
|
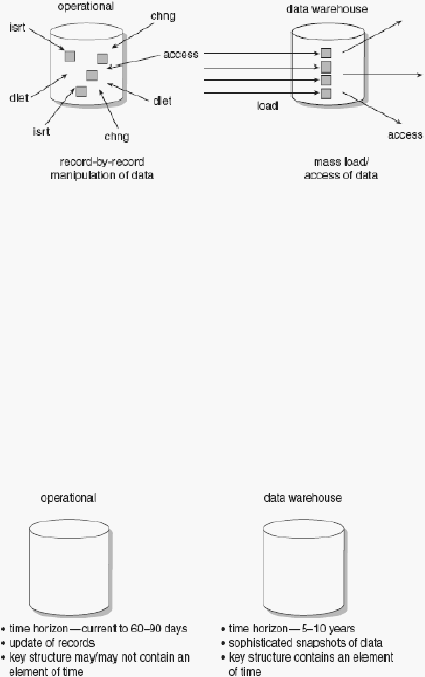 4.
Time Variant
Perbedaan pada karakteristik ini mempengaruhi tiap data dalam
data warehouse
menjadi selalu akurat dalam periode tertentu.
Dalam beberapa kasus, record ditandai. Di sisi lain, sebuah record
memiliki detail tanggal transaksi. Tetapi dalam setiap kasus ada
beberapa bentuk penanda waktu untuk menunjukan record
tersebut selalu akurat.
|
|
2.1.6
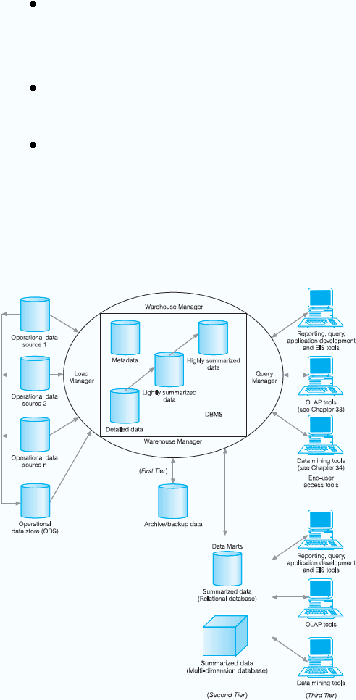
Arsitektur Data warehouse
Menurut Connoly dan Begg terdapat sepuluh komponen didalam Data
warehouse, yaitu :
1.
Operational Data
Mainframe
operasional data memegang kendali di hirarki generasi
pertama dan di jaringan database.
Bagian data memegang kendali pada kepemilikan system file VSAM,
RMS, dan relasional DBMS seperti informix dan oracle.
Private data memegang kendali pada workstation dan private server.
External System seperti internet, database komersial yang tersedia
atau database
yang berhubungan dengan pemasok organisasi atau
konsumen.
2.
Operational Data Store
Operational Data Store
(ODS) adalah tempat penyimpanan data
operasional yang terintegrasi yang digunakan untuk analisa perusahaan.
ODS sangat terstruktur yang berisi data seperti data warehouse. ODS
sering digunakan sebagai pengganti ketika sistem operasional tidak
mampu mendukung penyampaian laporan yang dibutuhkan. Para
pengguna ODS menyediakan kemudahan dalam
menggunakan database
relasional namun tetap jauh dari fungsi pendukung keputusan data
warehouse. Membuat ODS dapat menjadi langkah yang membantu
dalam membangun suatu data warehouse
karena ODS dapat
menyalurkan data yang telah diextract
dari sistem sumber
dan
“dibersihkan”. Ini berarti bahwa sisa pekerjaan untuk mengintegrasikan
dan merekstrurisasi data untuk data ware house menjadi lebih sederhana.
3.
Load Manager
Load manager juga disebut sebagai komponen front-end yang bertugas
melakukan seluruh operasi yang berhubungan dengan ekstrasi dan me-
load data ke warehouse. Operasi yang dilakukan oleh load manager
dapat meliputi perubahan bentuk yang sederhana dari data untuk
dipersiapkan sebelum masuk ke data warehouse.
|
|
4.
Warehouse Manager
Warehouse manager melakukan semua operasi yang berhubungan dengan
pengelolaan data di data warehouse. Komponen ini dibangun
menggunakan alat manajemen vendor data dan program custom-built.
Operasi yang dilakukan oleh manajer gudang meliputi:
Analisis data untuk memastikan konsistensi
Transformasi dan penggabungan sumber data dari penyimpanan
sementara ke tabel data warehouse;
penciptaan indeks dan pandangan tentang tabel dasar;
generasi denormalizations (jika perlu);
generasi agregasi (jika perlu);
backing-up dan pengarsipan data.
Dalam beberapa kasus, manajer gudang juga menghasilkan profil query
untuk menentukan indeks dan agregasi yang sesuai. Sebuah profil
permintaan dapat dihasilkan untuk setiap pengguna,
kelompok pengguna, atau data warehouse dan didasarkan pada informasi
yang menjelaskan karakteristik dari pertanyaan seperti frekuensi, tabel
target, dan ukuran dari hasil set.
5.
Query Manager
Query manager juga disebut komponen back-end, melakukan operasi-
operasi yang berhubungan dengan manajemen user queries. Operasi-
operasi yang dilakukan oleh komponen ini termasuk mengarahkan query
kepada tabel-tabel yang tepat dan menjadwalkan eksekusi dari query
tersebut.
6.
Detail Data
Daerah warehouse
ini menyimpan semua data yang rinci dalam skema
database. dalam kebanyakan kasus, data rinci tidak disimpan secara
online tetapi disediakan untuk menggabungkan data ke tingkat berikutnya
yang lebih detail. Namun, secara teratur, data rinci ditambahkan ke
gudang untuk melengkapi agregat data.
|
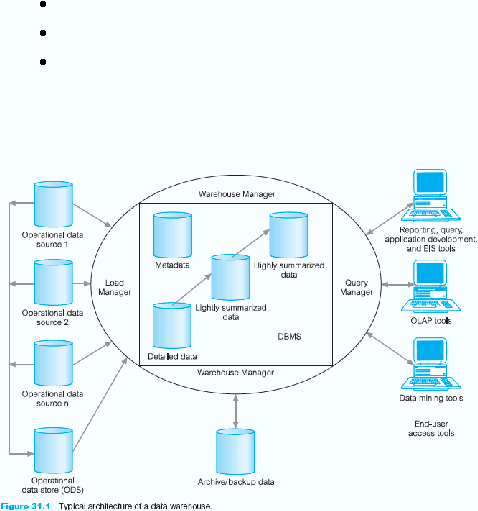 7.
Lightly and Highly Summarized Data
Merupakan tempat penyimpanan sementara data predefinisi yang ringkas
secara lightly dan highly yang dihasilkan warehouse manager. Tujuannya
adalah untuk mempercepat tanggapan atas permintaan user. Ringkasan
ter-update secara berkala sesuai data yang masuk.
8.
Archive / Backup Data
Area ini digunakan untuk menyimpan data secara rinci dan ringkas, untuk
tujuan arsip dan backup. Data ditransfer ke arsip penyimpanan seperti pita
magnetik atau optical disk.
9.
Metadata
Metadata digunakan untuk menyimpan semua definisi tentang metadata
(keterangan tentang data) yang digunakan dalam seluruh proses
warehouse. Tujuan penggunaan metadata yaitu :
Proses pengekstrakan dan loading
Management warehouse
sebagai proses query management
10. End-User Access Tools
Tujuan utama dari data warehouse
adalah untuk memberikan informasi
kepada pengguna bisnis untuk pengambilan keputusan strategis.
|
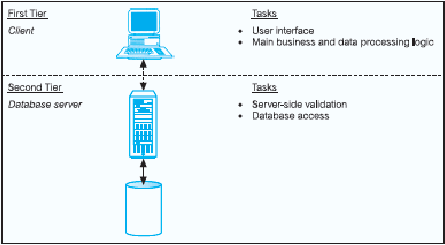 1.
Arsitektur Two-Tier
Pada arsitektur two-tier ini, data operasional ditransformasikan dan
ditransfer ke data warehouse.
Untuk
membantu
proses
transformasi,
sebuah Enterprise Data Model (EDM) dibuat. Enterprise
Data Model
(EDM)
ini menjelaskan
tentang
struktur
data warehouse
dan
berisi
metadata
yang dibutuhkan
untuk
menempatkan
dan
mengakses
database
yang
dihasilkan dan sumber data eksternal. Arsitektur
two-
tier
biasanya
akan
menemukan
kesulitan
performance
bilamana
data warehouse berukuran besar.
Begg (2005,p60)
2.
Arsitektur Three-Tier
Organisasi yang menemukan kesulitan dalam menerapkan arsitektur two-
tier
pada
umumnya
akan
beralih
ke
arsitektur three-tier.
User
pada
departemen
pada
umumnya
hanya
mengakses
sebagian
kecil
dari
porsi
data warehouse. Oleh karena itu digunakanlah data mart.
Pada umumnya data mart ini memiliki server yang terpisah dengan data
warehouse, yang bertujuan untuk performance / kinerja yang lebih baik
dan fault tolerance. Masing-masing departemen bertanggung jawab
untuk
mengawasi data mart departemennya.
|
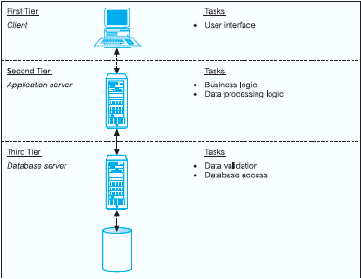 (2005,p61)
3.
Arsitektur Bottom up
Pada
arsitektur
bottom-up,
data
dimodelkan
dalam satu
function
atau
proses dalam satu waktu dan disimpan dalam
data
mart yang terpisah.
Bilamana waktunya tiba, data baru disintesis, disaring
(dibersihkan), dan
di- merge ke dalam data mart yang telah
tersedia dan dapat
juga dengan
membangun ke data mart yang baru.
Reporting And Query Tools
Reporting tools seperti alat pelaporan produksi dan laporan penulisan
adalah alat pelaporan produksi yang digunakan untuk menghasilkan laporan
operasional biasa atau mendukung pekerjaan batch volume.
Alat query
untuk gudang data relasional yang dirancang untuk
menerima SQL atau menghasilkan pernyataan SQL untuk query
data yang
tersimpan di gudang.
1.
Application Development Tools
Persyaratan dari end-user dapat seperti built-in kemampuan pelaporan
dan alat query
tidak memadai baik karena analisis yang diperlukan
tidak dapat dilakukan atau karena interaksi pengguna memerlukan
tingkat keahlian tinggi. Dalam situasi ini, akses pengguna mungkin
memerlukan pengembangan aplikasi dirumah menggunakan alat akses
|
|
data grafis yang dirancang terutama untuk lingkungan client-server.
Beberapa alat pengembangan aplikasi ini terintegrasi dengan populer
yaitu OLAP, dan dapat mengakses semua sistem database utama,
termasuk Oracle, Sybase, dan Informix.
2.
Executive Information System (EIS)
Executive Information System, baru-baru ini disebut sebagai 'sistem
informasi semua orang', awalnya dikembangkan untuk mendukung
tingkat tinggi pengambilan keputusan strategis. Namun, fokus dari
sistem ini diperluas untuk mencakup dukungan untuk semua tingkatan
manajemen. Saat ini, demarkasi antara alat EIS dan alat pendukung
keputusan yang lain bahkan lebih jelas sebagai pengembang EIS
menambah fasilitas permintaan tambahan dan menyediakan aplikasi
yang dibangun untuk area bisnis seperti penjualan,
pemasaran, dan
keuangan.
3.
Online Analytical Processing (OLAP)
Online Analytical Processing
(OLAP) alat didasarkan pada konsep
multi-dimensi database
dan memungkinkan pengguna yang canggih
untuk menganalisis data menggunakan data kompleks dan melihat
secara multidimensional. Alat-alat ini mengasumsikan bahwa data
tersebut akan diatur dalam model multi-dimensi didukung oleh data
multi-dimensi khusus (MDDB) atau dengan database
relasional
dirancang untuk memungkinkan query multi-dimensi.
4.
Data Mining Tools
Data mining adalah proses menemukan korelasi bermakna baru, pola,
dan tren dengan menggali sejumlah besar data menggunakan statistik,
matematika, dan kecerdasan buatan (AI) teknik.
Aliran Data Pada Data warehouse
Menurut Connolly & Begg, 2005 (pp. 1161-1165), data warehouse
berfokus pada manajemen lima arus data primer, yaitu :
|
|
Inflow
Proses terkait dengan ekstraksi, pembersihan, dan pemuatan data dari
sistem sumber ke dalam data warehouse. Inflow
ini berkaitan dengan
mengambil data dari sistem sumber untuk memasukan ke dalam data
warehouse.
Upflow
Suatu proses yang terkait dengan nilai tambah data di gudang melalui
meringkas, kemasan, dan distribusi data.
Aktivitas yang berhubungan dengan upflow meliputi:
1.
Meringkas data dengan memilih, memproyeksikan, bergabung,
dan pengelompokan data relasional ke pandangan yang lebih
nyaman dan berguna bagi pengguna akhir. meringkas meluas
melampaui operasi relasional sederhana untuk melibatkan analisis
statistik yang canggih termasuk kecenderungan mengidentifikasi,
clustering, dan sampling data.
2.
Kemasan data dengan mengubah data rinci atau dirangkum
menjadi lebih berguna format, seperti spreadsheet, dokumen teks,
grafik, presentasi grafis lainnya, database pribadi, dan animasi.
Mendistribusikan data ke kelompok yang tepat untuk
meningkatkan ketersediaan dan aksesibilitas.
Downflow
Merupakan suatu proses yang berhubungan dengan pengarsipan dan
melakukan backup
data di dalam data warehouse. Dimana ketika
terjadi kerusakan pada software atau hardware, tidak terjadi kehilangan
data.
Outflow
Yang terkait dengan membuat data yang tersedia untuk pengguna akhir.
Dalam outflow ada dua aktifitas yang menjadi kunci utama yaitu :
-
Pengaksesan, merupakan bagaimana kepuasan pengguna akhir dalam
menggunakan aplikasi.
|
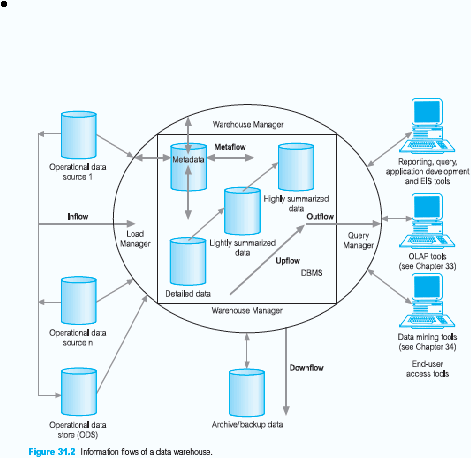 -
Pengiriman, bagaimana proses pengiriman informasi-infromasi yang
ditujukan kepada pengguna akhir.
Metaflow
Metaflow
suatu proses yang terkait dengan pengelolaan metadata.
Metadata merupakan penjelasan dari isi data dari data warehouse.
Begg,2005,p1162)
2.1.9
Granularity
Menurut Connolly and Begg (2005,p602) granularity
adalah ukuran
item data yang dipilih sebagai unit perlindungan oleh protokol.
Granularity
merupakan salah satu faktor yang
terpenting yang harus
diperhatikan dalam pengembangan data warehouse. Karena granularity
mempengaruhi efisiensi dari penggunaan data dalam analisa yang dilakukan.
Menurut Inmon (2005,p41) granularity
mengarah ke level of detail
pada data warehouse. Semakin detil data semakin rendah granularity
nya,
sebaliknya semakin ringkas data semakin tinggi tingkat granularity nya.
|
|
2.1.10
Metadata
Menurut kimball dan Ross(2002,p14) metadataa adalah keseluruhan
informasi yang ada didalam environment data warehouse, bukan secara
aktual itu sendiri, melainkan lebih mengarah pada sebuah ensiklopedia dari
data warehouse.
Sedangkan menurut Inmon (2005,p183) metadata pada lingkungan
operasional biasanya bertindak lebih kearah dokumentasi sehingga pemakai
cenderung optional, namun pada lingkungan data warehouse, metadata
memiliiki peranan yang jauh lebih besar dengan tingkat pemakai yang
meruakan keharusan.
Agregasi
Menurut Inmon (2005, p. 114) terdapat banyak kasus yang mana data di
dalam data warehouse
tidak memenuhi
kriteria stabilitas dan tidak
mengalami perubahan yang terjadi, kasus lainnya dimana jumlah data
menjadi terlalu banyak, sering terjadi perubahan isi data, dan sebagainya.
Dalam kasus-kasus seperti demikian, dapat dilakukan agregasi yang
digunakan untuk mengelompokkan beberapa data detail operational yang
berbeda ke dalam satu record tunggal.
Menurut Mallach (2000,p514) agregasi adalah serangkaian elemen
yang berhubungan deman beberapa dimensi dari basis data.
Perancangan Data warehouse
Menurut Kimball (Conolly 2005, p1187-p1194), ada sembilan tahap
metodologi dalam perancangan data warehouse, yaitu sebagai berikut :
1.
Pemilihan Proses
Proses ini didasarkan pada subjek data mart tertentu. Data mart pertama
yang akan dibangun harus menjadi salah satu yang paling mungkin
dikirimkan tepat waktu, sesuai anggaran, dan menjawab pertanyaan-
pertanyaan bisnis komersial yang paling penting.
2.
Pemilihan Grain
|
|
Pemilihan grain berarti memutuskan dengan tepat mana yang merupakan
record dari tabel fakta. Saat kita memilih grain ke tabel fakta, kita dapat
mengidentifikasi dimensi dari tabel fakta. Ketetapan grain ke tabel fakta
untuk menentukan grain setiap tabel dimensi.
3.
Mengidentifikasi dan Menyesuaikan Dimensi
Dimensi mengatur konteks dari pertanyaan-pertanyaan yang diajukan
tentang fakta-fakta yang terdapat pada tabel fakta. Pembuatan yang baik
dari dimensi membuat data mart menjadi mudah dimengerti dan mudah
untuk digunakan.
Ketika
kita
mengidentifikasi dimensi dengan cukup
detail untuk menggambarkan hal seperti klien dan properti pada grain
yang tepat. Dimensi ini penting untuk menggambarkan fakta-fakta yang
terdapat pada tabel fakta.
4.
Pemilihan Fakta
Grain
pada tabel fakta mengacu pada fakta mana saja yang bisa
digunakan dalam data mart, dimana semua fakta harus menampilkan
tingkat grain yang sama dan harus berupa numeric dan additive.
5.
Menyimpan pra-kalkulasi di Tabel Fakta
Hasil perhitungan dari atribut di database tidak disimpan pada suatu
atribut khusus didalam database. Namun pada tahap ini perlu
dipertimbangkan kembali penyimpanan hasil perhitungan pada suatu
atribut tersendiri di database dengan alasan mengurangi resiko kesalahan
pada program setiap kali melakukan perhitungan.
6.
Melengkapi Tabel Dimensi
Pada tabel dimensi keterangannya harus bersifat intuitif dan mudah
dipahami oleh para pengguna. Kegunaan dari data mart mengacu pada
ruang lingkup dan jenis atribut dari tabel dimensi.
7.
Pemilihan Durasi Database
Pengukuran durasi untuk melihat sejauh mana data history beberapa
tahun
kebelakang dan menentukan batas waktu
dari umur data yang
dapat diambil dan akan dipindahkan ke dalam tabel fakta. Misalkan,
perusahaan asuransi ingin melakukan pengukuran data
selama 10 tahun
atau lebih.
8.
Pelacakan Perubahan Dimensi yang perlahan
|
|
Permasalahan dimensi dapat berubah secara perlahan dapat terjadi sesuai
dengan seiringnya waktu dan kebutuhan perusahaan. Ada tiga tipe
perubahan dimensi yang perlahan, yaitu :
1.
Atribut dimensi yang telah berubah karena ditulis ulang.
2.
Atribut dimensi yang telah berubah dan menghasilkan sebuah dimensi
baru.
3.
Atribut dimensi yang telah berubah menimbulkan alternatif sehingga
nilai atribut yang lama dan yang baru dapat diakses secara bersamaan
pada dimensi yang sama.
9.
Menentukan Prioritas dan Mode Query
Pada tahap terakhir ini mempertimbangkan masalah perancangan fisik.
Masalah perancangan fisik yang paling kritikal mempengaruhi persepsi
dari end-user.
Pertimbangan masalah desain fisik seperti menentukan
urutan fisik dari tabel fakta pada media penyimpanan dan adanya
pengguna agregasi. Selain itu, desain fisik akan mempengaruhi masalah
administrasi, backup, indexing, dan keamanan.
Anatomi Data warehouse
1. Data warehouse Fungsional
Data warehouse
fungsional dibangun berdasarkan kebutuhan
informasi dari tiap bagian fungsi bisnis perusahaan seperti
keuangan, marketing, personalia. Keuntungan dari bentuk data
warehouse
ini adalah sistem mudah dibangun dengan biaya yang
relatif murah sedangkan kerugiannya adalah resiko kehilangan
konsistensi data dan terbatasnya kemampuan pengumpulan data
bagi pengguna.
2. Data warehouse Terpusat
Menurut Inmon(2005, p193), kebanyakan organisasi membangun
dan memelihara lingkungan data warehouse terpusat yang tunggal.
Pengaturan ini masuk akal karena sebagai berikut :
a.
Data di dalam data warehouse terintegrasi antar perusahaan dan
gambaran terintegrasi digunakan hanya pada kantor pusat.
b.
Perusahaan beroperasi pada model bisnis terpusat
|
|
c.
Volume dari data dalam data warehouse
seperti tempat
penyimpanan tunggal yang terpusat
d.
Sekalipun data dapat terintegrasi dan diedarkan antar area lokal
yang beragam, data tersebut akan tidak praktis untuk diakses.
3. Data warehouse Terdistribusi
Pada data warehouse
terdistribusi digunakan gate way
yang
berfungsi sebagai penghubung antara data warehouse
dengan
workstation
yang menggunakan sistem beraneka ragam. Dengan
data warehouse ini perusahaan dapat mengakses sumber data yang
berada diluar lokasi perusahaan.
Keuntungan dari data warehouse ini adalah tetap konsisten, karena
sebelum digunakan data terlebih dahulu di sinkronasi. Kerugiannya
adalah sistem yang kompleks saat penerapannya.
ETL
Menurut Inmon (2005, p497) Extract, Transform, Load (ETL) adalah
proses melakukan pencarian data, mengintegrasikan, dan menempatkan data
ke dalam sebuah data warehouse. Proses-proses dalam data warehouse yang
meliputi:
1.
Mengekstrak data dari sumber-sumber eksternal,
2.
Mentransformasikan data ke bentuk yang sesuai dengan keperluan
bisnis,
3.
Load atau memasukkan data ke target akhir, yaitu data warehouse,
ETL
merupakan proses yang sangat penting, dengan ETL
data dapat
dimasukkan ke dalam data warehouse. ETL
juga dapat digunakan untuk
mengintegrasikan data dengan sistem yang sudah ada sebelumnya. Tujuan
ETL
adalah mengumpulkan, menyaring, mengolah, dan menggabungkan
data-data yang relevan dari berbagai sumber untuk disimpan ke dalam data
warehouse. Hasil dari proses ETL adalah dihasilkannya data yang memenuhi
kriteria data warehouse
seperti data historis, terpadu, terangkum, statis, dan
memiliki struktur yang dirancang untuk keperluan proses analisis.
1.
Extract
|
|
Langkah pertama pada proses ETL
adalah mengekstrak data dari
sumber-sumber data. Kebanyakan proyek data warehouse
menggabungkan data dari sumber-sumber yang berbeda. Pada
hakekatnya, proses ekstraksi adalah proses penguraian, pembersihan
dari data yang diekstrak untuk mendapatkan struktur atau pola data
yang diharapkan.
Proses extract terdiri dari dua tipe, yaitu :
a.
Static extract : metode pengambilan data pada waktu tertentu untuk
mengisi data warehouse untuk pertama kalinya.
b.
Incremental extract
: metode yang hanya mengambil perubahan
yang terjadi pada data sejak data tersebut diambil terakhir kali nya.
2.
Transform
Merupakan
sebuah
proses untuk
mempersiapkan
atau
membersihkan
data
yang
telah
diambil
pada
proses
ekstraksi
sehingga data
tersebut
dapat
sesuai
dengan
struktur
data
warehouse
atau
data mart.
Pada
tahap
ini,
banyak
jenis
fungsi
transformasi
dibutuhkan
sebelum
data
dapat
dipetakan
dan
disiapkan
untuk
dimasukkan (loading)
ke
dalam
tempat
penyimpanan
data
warehouse.
Fungsi fungsi
ini termasuk
penyeleksian
input,
pemisahan
struktur
input, normalisasi,
dan denormalisasi
dari
struktur
sumber,
aggregasi, konversi,
memperbaiki
nilai
yang
hilang,
dan konversi
nama
serta alamat.
3.
Load
Fase load merupakan tahapan yang berfungsi untuk memasukkan data
ke dalam target akhir, yang biasanya ke dalam suatu data warehouse.
Jangka waktu proses ini tergantung pada kebutuhan organisasi.
Beberapa data warehouse
dapat setiap minggu menulis keseluruhan
informasi yang ada secara kumulatif, data diubah, sementara data
warehouse yang lain (atau bagian lain dari data warehouse yang sama)
dapat menambahkan data baru dalam suatu bentuk historikal. Waktu
dan jangkauan untuk mengganti atau menambah data tergantung dari
perancangan data warehouse
pada waktu menganalisis keperluan
informasi.
|
|
2.1.15
Pemodelan Data warehouse
Menurut Conolly dan Begg
(2010, p1227) dimensionality
modeling adalah teknik
logical design
yang bertujuan
untuk
menyajikan
data
standar, bentuk intuitif yang
memungkinkan untuk
mengakses high performance.
Dimensionality modeling
menggunakan konsep dari Entity
Relationship
(ER) dengan beberapa batasan yang penting. Setiap
Dimensional model terdiri dari satu buat tabel yang memiliki banyak
Primary key
(composite Primary key), yang disebut tabel dimensi
(dimensional table). Setiap tabel dimensi memiliki satu buah (non-
composite) primary key yang berhubungan dengan salah satu primary
key
di tabel fakta. Karakteristik ini disebut skema bintang
(strar
schema) atu star join.
Menurut Conolly dan Begg (2010, p1227), Star Schema adalah
model dimensional data
yang memiliki
fact table
di tengah,
dikelilingi oleh denormalized dimension tables. Selain itu star schema
memudahkan end user
untuk memahami struktur database pada
data
warehouse yang di rancang.
Keuntungan dari penggunaan star schema
menurut Connolly
and Begg (2005,1185) :
1.
Efisiensi, Struktur database yang konsisten membuat akses
data lebih efisien dengan menggunakan alat untuk
menampilkan data termasuk laporan tertulis dan query.
2.
Kemampuan untuk mengatasi perubahan kebutuhan, skema
bintang dapat beradaptasi terhadap perubahan kebutuhan,
karena semua tabel dimensi memiliki kesamaan dalam hal
yang menyediakan akses ke tabel fakta.
3.
Extensibility, model dimensional dapat dikembangkan,
contohnya menambahkan fakta selama data masih konsisten,
menambah tabel dimensi selama masih ada nilai tunggal di
|
|
tabel dimensi tersebut yang mendefinisikan setiap record tabel
fakta yang ada.
4.
Kemampuan untuk menggambarkan situasi bisnis pada
umumnya.
5.
Proses query
yang dapat diprediski, aplikasi data warehouse
yang mencari data dari level yang dibawahnya akan dengan
mudah menambah jumlah atribut pada table dimensi dari
sebuah skema bintang.
Didalam skema bintang atau Star Schema terdiri dari dua tabel :
1.
Table Fakta (Fact Table)
Fact table (tabel fakta) adalah tabel yang umumnya
mengandung sesuatu yang dapat diukur (measure),
seperti harga, jumlah barang, dan sebagainya. Fact table
juga merupakan kumpulan foreign key dari primary key
yang terdapat pada masing-masing dimension table. Fact
table juga mengandung data yang historis.
2.
Tabel dimensi (Dimension Table)
Dimension table (tabel dimensi) adalah tabel yang berisi
data detail yang menjelaskan foreign key yang terdapat
pada fact table. Atribut-atribut yang terdapat pada
dimension table dibuat secara berjenjang (hirarki) untuk
memudahkan proses query.
|
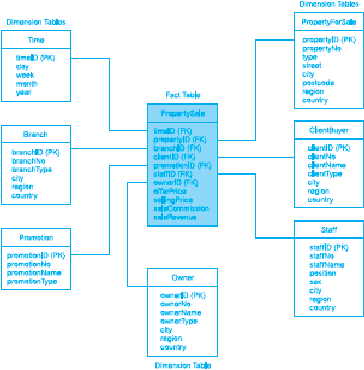 Menurut Conolly dan Begg
(2010, p1229), snowflake schema
adalah model
dimensional data
yang memiliki
fact table di tengah,
dikelilingi oleh normalized dimension tables.
Keuntungan dari skema snowflake:
1.
Kecepatan memindahkan data dari data OLTP ke dalam
metadata.
2.
Sebagai kebutuhan dari alat pengambil keputusan tingkat
tinggi dimana dengan tipe yang seperti ini seluruh struktur
dapat digunakan sepenuhnya.
Banyak yang beranggapan lebih nyaman merancang dalam
bentuk normal ketiga.
|
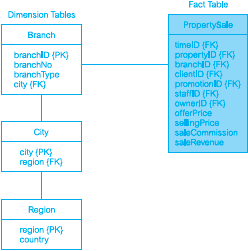 Istilah-Istilah Lain yang Berhubungan dengan Data
Warehouse
OLTP
Menurut Connolly & Begg (2005, p.1149), OLTP adalah
sebuah sistem yang dibangun untuk menangani hasil transaksi yang
tinggi, dengan transaksi kecil yang memberikan pengaruh bagi data
operasional organisasi.
Menurut O'brien (2005, p. 709), OLTP merupakan sistem
pemrosesan transaksi-transaksi yang ada di dalam organisasi yang
terjadi secara real-time.
Menurut Connolly dan Begg (2010, p1205) Online Analytical
Processing (OLAP) merupakan sintesis
dinamis, analisis dan
konsolidasi
volume terbesar dari
multidimensional data. Teknologi
OLAP memungkinkan data warehouse digunakan secara efektif untuk
proses online analysis, memberikan respon yang cepat terhadap
analytical queries yang kompleks.
Menurut Kimball & Ross (2002, p. 408),
OLAP merupakan
aturan yang menyediakan sebuah kerangka dimensional untuk
mendukung keputusan. Berdasarkan definisi tersebut, dapat ditarik
kesimpulan bahwa OLAP adalah proses yang dilakukan untuk
menganalisis data, dimana jumlah data yang besar dan dimensional
|
 yang dikumpulkan menjadi satu yang bisa digunakan untuk
membantu mengambil keputusan.
Multidimensional Modeling
Menurut
Umashanker Sharma dan Anjana Gosain (2009, p2)
multidimensional model terdiri dari 3 konsep kunci yaitu aturan
model bisnis,
cube
dan measure
serta dimensi. Multidimensional
database teknologi adalah factor kunci dalam analisis dalam
banyaknya jumlah data untuk pengambilan keputusan.
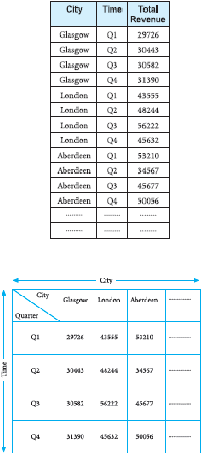
Berikut ini adalah multidimensional data yang dapat dilihat:
|
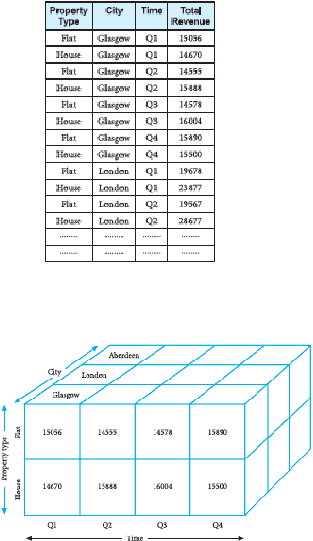 Gambar 2.12 Four-field table (Connlly dan Begg,2005,p.1210)
Begg,2005,p.1210)
Multidimensional umumnya mendukung operasi analitis
seperti consolidation (roll-up), drill-down, slicing and dicing, pivot
table.
Menurut Connolly and Begg (2005,p1171) data mart
adalah
sebuag subset
dari data warehouse yang mendukung persyaratan
departemen tertentu atau fungsi bisnis.
Menurut Inmon (2005,p494) data mart
adalah struktur data
yang terbagi-bagi yang diperoleh dari data warehouse dimana data
|
 tersebut telah di denormalisasi berdasarkan kebutuhan informasi
manajemen.
Karakteristik perbedaan antara data mart dan data warehouse:
Data mart
berfokus pada kebutuhan pengguna yang
berhubungan dengan satu bagian departemen atau fungsi
bisnis.
Data mart
tidak berisi data operasional secara detil, tidak
seperti data warehouse.
Berdasarkan teori diatas dapat disimpulkan bahwa data mart
adalah bagian dari data warehouse
yang mendukung
pembuatan laporan dan analisa data pada suatu unit, bagian,
atau operasi pada suatu perusahaan.
Begg (2005,p1172)
2.1.16.4Surrogate key
Menurut kimball dan Ross (2002,p414) surrogate key adalah
key berupa integer yang secara sequential ditambahkan sesuai
|
|
kebutuhan pada staging area untuk membentuk sebuah tabel dimensi
dan elemen yang menggabungkannya dengan tabel fakta. Pada tabel
dimensi, surrogate key ini bertindak sebagai primary key yang
menspesifikan dimensi, walaupun terkadang tidak dibutuhkan
surrogate key pada tabel fakta juga dapat bertindak sebagai bagian
dari primary key yang dimiliki oleh tabel fakta. Surrogate key
biasanya tidak bisa dijelaskan sendiri hanya melalui nilai yang
terkandung didalamanya. Surrogate key pada data warehouse
dibutuhkan untuk menangani permasalahan yang timbul dari slowly
changing dimension serta data yang hilang ataupun data yang tidak
bisa digunakan.
Teori Khusus
1.2.1
Menurut Leny Sulistiyowati (2010,p270),
penjualan adalah
pendapatan yang berasal dari penjualan produk perusahaan, disajikan setelah
dikurangi potongan penjualan dan retur penjualan.
Menurut Henry Simamora
(2000,p24),
Penjualan adalah pendapatan
lazim dalam perusahaan dan merupakan jumlah kotor yang dibebankan
kepada pelanggan atas barang dan jasa.
1.2.2
Menurut Sofjan Assauri (2004,p11), produksi merupakan proses yang
mengubah masukan-masukan dengan menggunakan sumber-sumber daya
untuk menghasilkan keluaran-keluaran, yang berupa barang atau jasa.
Tiga tingkatan produk yang di beli konsumen menurut Sofjan Assauri
(2004,p202), yaitu:
1.
Produk inti (Core Product), yang merupakan inti atau dasar yang
sesungguhnya dari produk yang ingin di peroleh atau di dapatkan
oleh sorang pembeli atau konsumen dari produk tersebut.
|
|
2.
Produk formal (Formal Product), yang merupakan bentuk, model,
kualitas / mutu, merek dan kemasan yang menyertai produk tersebut.
3.
Produk tambahan (Augemented Product) adalah tambahan produk
formal dengan berbagai jasa yang menyertainya, seperti pemasangan
(instalasi), pelayanan, pemeliharaan dan pengangkutan secara Cuma
–
Cuma.
Jenis Proses Produksi
Menurut Sofjan Assauri (2004,p75), proses dapat dibedakan
menjadi dua jenis, yaitu :
1.
Proses produksi yang terus – menerus (Continuous Processes)
Menurut Sofjan Assauri (2004,p75), proses produksi terus –
menerus adalah proses produksi yang menggunakan mesin dan
peralatan yang dipersiapkan untuk memproduksi produk dalam
jangka waktu yang lama/panjang, tanpa mengalami perubahan
untuk jenis produksi yang sama.
Menurut Sofjan Assauri (2004,p76) ciri –
ciri proses produksi
yang terus – menerus ialah :
a.
Produk yang dihasilkan dalam jumlah besar (produksi masa)
dengan variasi yang sangat kecil dan sudah distandardisasi.
b.
Biasanya menggunakan system atau cara penyusunan
berdasarkan urutan pengerjaan dari produk yang dihasilkan,
yang disebut product lay out
atau departementation by
product.
c.
Mesin –
mesin yang dipakai dalam mesin produksi adalah
mesin –
mesin yang bersifat khusus untuk menghasilkan
produk tersebut, yang dikenal dengan nama special purpose
machines.
d.
Oleh karena mesin-mesinnya yang bersifat khusus dan
biasanya agak
otomatis, maka pengaruh individual operator
terhadap produk yang dihasilkan kecil sekali, sehingga
operatornya tidak perlu mempunyai keahlian atau skill yang
tinggi untuk pengerjaan produk tersebut.
|
|
e.
Jika salah satu mesin atau peralatan terhenti atau rusak, maka
seluruh proses produksi akan terhenti.
f.
Mesinnya bersifat khusus dan variasi dari produksinya kecil
maka job structure-nya sedikit dan jumlah tenaga kerjanya
tidak perlu banyak.
g.
Persediaan bahan mentah dan bahan dalam proses adalah
lebih rendah dari pada intermittent process/manufacturing.
h.
Bahan-
bahan dipindahkan dengan peralatan handling yang
tetap yang menggunakan tenaga mesin seperti ban berjalan.
2.
Proses produksi yang terputus – putus (Intermittent Processes)
Menurut Sofjan Assauri (2004,p75), pengertian dari proses
terputus-putus adalah proses produksi yang menggunakan waktu
yang pendek dalam persiapan peralatan untuk perubahan yang
cepat guna dapat menghadapi variasi produk yang berganti –
ganti.
Menurut Sofjan Assauri ciri –
ciri dari proses produksi yang
terputus – putus adalah :
a.
Produk yang dihasilkan dalam jumlah yang sangat kecil
dengan variasi yang sangat besar (berbeda) dan didasarkan atas
pesanan.
b.
Proses seperti ini biasanya menggunakan sistem, atau cara
penyusunan peralatan berdasarkan atas fungsi dalam proses
produksi atau peralatan yang sama dikelompokkan pada
tempat yang sama, yang disebut dengan process lay out atau
departementation bu equipment.
c.
Mesin yang dipakai dalam proses produksi seperti ini adalah
mesin - mesin yang bersifat umum.
d.
Produk yang dihasilkan sangat besar, sehingga operatornya
perlu mempunyai keahlian atau
skill yang tinggi dalam
pengerjaan produk tersebut.
e.
Proses produksi tidak mudah/akan terhenti walaupun terjadi
kerusakan atau terhentinya salah satu mesin atau peralatan.
|
|
f.
Persediaan bahan mentah biasanya tinggi, karena tidak dapat
ditentukan pesanan apa yang akan dipesan oleh pembeli dan
juga persediaan bahan dalam proses lebih tinggu daripada
continuous process/manufacturing, karena prosesnya terputus
–
putus/terhenti –
henti.
Biasanya bahan-bahan dipindahkan
dengan peralatan handling yang dapat flecible (varied path
equipment) yang menggunakan tenaga manusia seperti kereta
dorong atau forklift.
|