|
BAB 2
TINJAUAN PUSTAKA
2.1 Teori-Teori yang Digunakan
2.1.1 Bahasa Indonesia
Bahasa Indonesia merupakan bah asa yang penting
wilayah Asia Tenggara.
Menurut Sneddon (2003:225), meskipun bahasa Indone
tidak digunakan di seluruh
dunia, bahasa ini tetap menjadi bahasa nasional terpopul
ke-4 di dunia dan n egara
tetangga lainn ya.
2.1.1.1 Sifat Bahasa Indonesia
Menurut Tucker (2010:75) kebanyakan bahasa secara morfologi bisa
diklasifikasikan menjadi tiga kategori. Pengkategorian merupakan dasar dari bahasa
alami. Ketiga kategori itu disusun secara ascending. Kategori pertama yaitu
monosyllabic, terisolasi, atau bah asa radikal, seperti bahasa Cina atau Mandarin. Bahasa
dalam kategori ini tidak mampu mengakomodasikan segala bentuk perubahan kata
seperti penggunaan sufiks, prefiks, dan lain-lain.
Kategori kedua adalah agglutinating language, seperti bahasa Turki dan bahasa
Jepang. Agglutinating maksudnya kata-kata dalam sebuah kalimat bisa disisipkan dan
dilepas dengan bebas. Beberapa bisa diubah ke bentuk afiks atau berimbuhan, tetapi
tidak akan mengubah bentuk katan ya. Hal tersebut bisa dilekatkan dengan cara
diaglutinasi atau agglutinated. Tidak h anya afiks, tetapi kata-kata bisa dilekatkan dengan
yang lainnya. Tucker (2010:78) memberikan contoh seperti ini. Aulisariartorasuarpok
yang artinya “dia buru-buru pergi memancing” dalam bahasa Greenland. Kata
Aulisariartorasuarpok merupakan gabungan d ari kata aulisar yang artinya“untuk
memancing”, peartor yang artinya “sed ang melakukan”, pinnesuarpok yang artinya
“dengan cepat”. Konstruksi kata ini hanya memungkinkan dalam agglutinative language
tingkat tinggi.
Kategori terakhir adalah inflexional, organic, dan amalgamating language,
seperti Semitic dan keban yakan bahasa di negara-negara Eropa. Pada kategori ini, kata-
7
|
|
8
kata bisa berub ah bentuknya menjadi fungsi yang lebih spesifik dalam kalimat, seperti
irregular verb atau past particular dalam bahasa In ggris.
Bahasa Indonesia merupakan transisi antara agglutinating dan inflexional. Kata-
kata dalam bahasa Indonesia tidak bisa direkatkan seperti bahasa Greenland, tetapi bisa
direkatkan den gan beberapa afiks. Jika dalam agglutinative language tingkat tinggi
penambahan afiks tidak akan mempengaruhi bentuk kata, dalam bahasa Indonesia,
beberapa afiks akan mengubah bentuk kata. Hal ini merupakan karakteristik dari bahasa
inflexional. Jadi bahasa Indonesia mengandung inflexional d
agglutinative, tapi tidak
dalam bentuk ekstrim. Hal ini juga disebutkan oleh Tucker (2010:8
bahwa sebagian
besar bahasa Indo-Eropa dalam bentuk modern merupak
karakteristik semi-
infleksional.
2.1.1.2 Pentingnya Bahasa Indonesia di Dunia
Bahasa Indonesia telah menghadapi banyak masal
dan pengemban gan sosial-
politik sejak 1997. Gejolak tersebut menarik perhati
banyak oran g, termasuk dalam
bidang akademis seperti sejarah, politik, sosiolo
junalis, dan orang-orang
yang
memiliki minat dalam masalah internasional (Snedd
2003:1). Bahasa Indonesia
sebagai bahasa nasional erat kaitannya dengan sebu
bangsa dan merupakan cara yang
unik untuk mencerminkan suatu bangsa se
merupakan hal yang
menarik bagi dunia
internasional.
Meskipun bahasa Indonesia aslinya digun akan han
di Indonesia, namun tetap
menjadi salah satu bahasa dengan pembicara d
pengguna terbanyak di dunia
(Sneddon, 2003:1). Hal ini dikarenakan Indone
merupakan negara den gan populasi
terban yak ke-4 di dunia. Bahasa itu penting di ma
dunia bukan hanya karena
digunakan oleh banyak orang, tetapi juga kare
banyak aspek yang terbatas p ada
bangsa dan bahasan ya yang cukup signifikan unt
dunia, seperti halnya Indonesia
merupakan negara muslim terbesar di dun
|
|
9
2.1.2 Algoritma
Pengertian algoritma menurut Levitin (2012:3-4) adalah suatu u rutan instruksi
yang jelas untuk memecahkan masalah, yaitu untuk memperoleh output yang dip erlukan
untuk setiap input yang sah dalam jumlah waktu yang terbatas. Berikut adalah poin
penting dari algoritma:
a. Setiap langkah dari algoritma tidak boleh ambigu.
b. Wilayah input untuk algoritma yang bekerja harus ditentukan dengan hati-hati.
c. Algoritma yang sama dapat direpresentasikan dalam beberapa cara yang berbeda.
d. Ada beberapa algoritma untuk memecahkan masalah yang sama.
e. Algoritma untuk masalah yang sama d apat didasarkan p ada ide-ide yang sangat
berbeda dan dapat memecahkan masalah dengan kecepatan yang berbeda secara
dramatis.
Algoritma, menurut Edmonds (2008:1), merupakan prosedur langkah-langkah
yang dimulai dengan instansi input dan menghasilkan output yang sesuai. Hal ini
dijelaskan pada tingkat detail dan abstraksi paling cocok untuk dipahami manusia.
Sebaliknya, kode adalah implementasi dari algoritma yang
bisa dieksekusi oleh
komputer. Pseudocode berada di antara keduanya.
Menurut Cormen, Leiser son, Rivest, Stein (2009:5) secara informal, algoritma
adalah prosedur komputasi yang terdefinisi dengan baik yang mengambil beberap a nilai,
atau mengatu r nilai-nilai, sebagai input dan menghasilkan beberapa nilai, atau mengatur
nilai-nilai, sebagai output. Dengan demikian algoritma merupakan urutan langkah
komputasi yang mengubah input menjadi output.
Algoritma juga dap at diartikan sebagai alat untuk memecahkan masalah
komputer yang tidak jelas atau bahkan masalah komputer yang didefinisikan dengan
baik. Secara umum, pernyataan masalah menentukan hubungan antara data input dan
data output yang diinginkan. Algo ritma itu sendiri menjelaskan prosedur komputasi
spesifik untuk mencapai hubungan antara input dan output.
Sebagai contoh yaitu penyortiran sekelompok angka dalam urutan terkecil
hingga terbesar. Masalah ini seringkali ditemukan dalam kehidupan nyata dan
memberikan ‘fertile gro und’ untuk memperkenalkan berbagai jenis alat analisis dan
|
|
10
teknik perancangan standar. Secara formal, masalah
pen yortiran dapat didefinisikan
sebagai berikut:
Input: string angka n {a1, a2, …, an}.
Output: permutasi (re-ordering) {a’1, a’2, …, a’n} dari urutan input seperti ini
a’1 a’2 … a’n.
Sebagai contoh, diberikan urutan input (31, 41, 59, 26, 41, 58), algoritma
penyortiran menghasilkan urutan output (26, 31, 41, 41, 58, 59). Urutan input disebut
instansi masalah pen yortiran. Secara umum, instansi masalah terdiri dari input
(memenuhi kendala apapun yang dikenakan dalam pern yataan masalah) diperlukan
untuk menghitung solusi dari masalah ini.
Algoritma dikatakan benar jika, untuk setiap input berhenti den gan hasil output
yang ben ar. Dapat dikatakan, algoritma yang benar adalah algoritma yang dapat
mengatasi masalah komputasi. Algoritma yang salah adalah algoritma yang tidak
memberikan jawaban atau memberikan jawaban yang tidak tepat untuk beberapa atau
seluruh input. Tetapi perlu diingat bahwa algoritma yang salah terkadang
bergunasebagai acuan apabila sewaktu-waktu kesalahan-kesalahan yang ada bisa
diperbaiki. Serin g k ali, algoritma yang salah bisa digunakan kembali jika memiliki
performa yang lebih baik dibandingkan dengan rata-rata kesalahannya.
2.1.3 Artificial Intelligence
AI merupakan salah satu bidang terbaru dalam sains dan teknik. Pengembangan
AI benar-benar dimulai setelah Perang Dunia II. Bersamaan dengan biologi molekular,
AI disebutkan sebagai “b idang yan g san gat in gin digeluti” oleh p ara ilmuwan.
AI saat ini meliputi berbagai macam sub-bidang, mulai dari yang umum (belajar
dan berpersepsi) kepada hal yang spesifik, seperti bermain catur, membuktikan teorema
matematika, menulis puisi, mengend arai mobil di jalan ramai, dan mendiagnosis
penyakit. AI sangat berhubungan dengan pekerjaan intelektual. (Russell dan Norvig,
2010:1)
Pada dasarnya, banyak pandan gan serta pengertian men genai AI, dan secara
garis besar, menurut Russell dan Norvig (2010:1-2) definisi AI bisa terbagi menjadi
|
|
11
empat kategori, yaitu: Berpikir Manusiawi, Berpikir Rasional, Bertingkah Manusiawi,
dan Bertingkah Rasional.
1. Berpikir Manusiawi
Pada kategori ini, AI dijelaskan suatu usaha baru untuk dapat membuat komputer
dapat berpikir, suatu komputer yang memiliki pemikiran dan rasa, atau dengan
kata lain dapat juga disebut sebagai kegiatan mengadopsi cara berpikir manusia,
seperti pen gambilan keputusan, penyelesaian masalah, pembelajaran, dan
sebagainya.
2. Berpikir Rasional
Pada kategori ini, AI dijelaskan sebagai su atu studi melalui pemodelan
komputasi, dimana studi AI ini dapat membuat segala sesuatu mungkin untuk
dapat dipersepsikan dan memiliki alasan untuk dilakukan.
3. Bertingkah Manusiawi
Pada kategori ini, AI dijelaskan sebagai suatu seni untuk membuat mesin dapat
menampilkan fungsi yang membutuhkan kecerdasan ketika digunakan oleh
manusia.
4. Bertingkah Rasional
Pada kategori ini, AI dijelaskan sebagai st
tentang perancan gan agen-agen
kecerdasan dan AI terfokus pada perilaku cerdas.
|
 12
Tabel 2.1 Definisi AI
Berpikir Manusiawi
Berpikir Rasional
“Upaya baru yang menarik untuk membuat
komputer berpikir … mesin dengan pikiran
dalam artian sesungguhnya dan literal.”
(Hau geland, 1985)
“Otomatisasi kegiatan yang dikaitkan
dengan pemikiran manusia, pengambilan
keputusan, pemecahan masalah,
pembelajaran …” (Hellman, 1978)
“Studi mengenai kemampuan mental
melalui penggunaan model komputasi.”
(Charniak dan McDermott, 1985)
“Studi mengenai komputasi yang
memungkinkan untuk melihat, berakal,
dan bertindak.” (Winston, 1992)
Bertingkah Manusiawi
Bertingkah Rasional
“Seni membuat mesin yang
melakukan
fungsi yan g dilakukan oleh manusia.”
(Kurzweil, 1990)
“Studi mengenai bagaimana membuat
komputer melakukan hal-hal yang pada
saat ini dilakukan lebih baik oleh manusia”
(Rich dan Knight, 1991)
“Kecerdasan komputasi adalah studi
mengenai perancangan agen cerdas.”
(Poole et al., 1998)
“AI berkaitan dengan perilaku cerdas
dalam artefak.” (Nilsson, 1998)
Tes Turing yang diajukan oleh Alan Turing pada tahun 1950, dirancang untuk
memberikan definisi dari AI. Sebuah komputer dianggap berhasil jika interogator
manusia setelah mangajukan pertan yaan tertulis, tidak dapat membedakan ap akah
tanggapan atau jawaban tertulis tersebut ber asal dari seseorang atau dari komputer.
Berdasarkan tes Turing, untuk memenuhi kriteria AI komputer perlu memiliki
kemampuan sebagai berikut:
a. Natural Language Processing / Pengolahan Bahasa Alami
Memungkinkan untuk berkomunikasi dengan sukses dalam bahasa
In ggris.
b. Knowledge Representation / Representasi Pengetahuan
Mampu menyimpan p engetahuan ataupun mendengar.
c. Automated Reasoning / Penalar an Otomatis
|
|
13
Mampu menggunakan informasi yan g tersimpan untuk menjawab
pertanyaan dan untuk menarik kesimpulan baru.
d. Machine Learning / Mesin Belajar
Mampu beradaptasi dengan keadaan baru dan untuk mendeteksi dan
ekstrapolasi sebuah pola.
2.1.3.1 Sejarah
Pada tahun 1950, Alan Turing menanyakan apakah sebuah mesin bisa berpikir.
Tidak lama sebelumnya, Turing telah memperkenalkan konsep dari mesin universal
abstrak (yang disebut Mesin Turing) yang sederhana dan mampu memecahkan semua
masalah matematika (dengan kompleksitas yan g sama). Hasil penelitian ini disebut Tes
Turing.
Pada tes Turin g, jika mesin membuat manusia berpikir bahwa mesin tersebut
adalah manusia, maka mesin tersebut lulus tes kecerdasan. Satu cara dalam tes Turing
adalah dengan berkomunikasi dengan agen lain melalui keyboard. Pertanyaan-
pertanyaan ditanyakan oleh pakar melalui teks tertulis, dan tanggap an diberikan melalui
terminal. Tes ini memberikan jalan untuk menentukan bahwa kecerdasan tersebut
merupakan AI. Dengan mempertimban gkan tugas tersebut, tidak han ya pakar yang
cerdas menguasai pengetahuan yang diperlukan untuk membuat sebuah
percakapan
cerdas, dan h al tersebut harus mampu untuk mengurai dan mengerti bahasa alami dan
menanggapi dengan bahasa alami. Pertan yaan tersebut dapat melibatkan kemampuan
pertimbangan (seperti pemecahan masalah), sehingga mesin yang mampu meniru
manusia dianggap sebuah prestasi (Jones, 2008:3)
Pada tahun 1956, Konferensi Dartmouth AI melibatkan beberapa orang dalam
riset AI, yaitu: John McCarthy, Marvin Minsky, Nathaniel Rochester, dan C laude
Shannon. Merek a dibawa untuk melakukan riset pada komputer, pemrosesan bahasa
alami, dan jaringan neuron.
Selain untuk menciptakan istilah AI dan melakukan riset besar dalam bidang AI,
McCarth y membuat bahasa pemrograman AI pertama yaitu LISP. (Jones, 2008: 5-6)
|
|
14
Pada tahun 1970, pengembangan AI terus berlanjut tetapi lebih terfokus.
Aplikasi yang memberikan harapan, seperti sistem pakar, naik sebagai salah satu kunci
pengembangan di era saat itu.
Salah satu sistem pakar pertama untuk menunjukkan kekuatan dari arsitektur
rule-based yang disebut MYCIN, dan dikemban gkan oleh Ted Shortliffe ya
mengikuti
penelitian ketika berada di Stanford pada tahun 1974. MYC
dioperasikan di bidang
diagnosis medis, dan menunjukkan repr esentasi pengetahuan d
kesimpulan.Kemudian
pada dekade ini, penelitian lainnya di Stanford oleh Bill Van Mel
yang membangun
arsitektur MYC IN dan berfungsi sebagai model untuk kerangka sist
pakar yang
digunakan hingga saat ini. (Jones, 2008:8)
2.1.3.2 Aplikasi AI
Menurut Russell dan Norvig (2010:28) ada beberapa aplikasi AI, seperti:
1. Robotika
Robot adalah perangkat mekanik yang dapat bertindak sendiri dan
menggantikan aktivitas manusia. Robot mampu menguran gi waktu dan proses
yang perlu dilakukan oleh manusia.
2. Pengenalan Suara
Pengenalan suara adalah kemampuan komputer untuk menganalisa suara
manusia dan mengintepretasikann ya dalam bentuk teks, yang biasa diketahui
sebagai “sp eech to text”.
3. Perencanaan dan Penjadwalan Otomatis
Kemampuan komputer untuk membuat rencana dan jadwal secara
otomatis.
4. Permainan Game
Komputer bisa diprogram untuk berprilaku seperti seorang pemain dalam
game, memungkinkan oran g untuk memainkan game yang membutuhkan
interaksi manusia tanpa manusia.
5. Memeran gi Spam
Memeran gi spam adalah kemampuan komputer untuk mengh apus pesan
yang diklasifikasikan sebagai spam secara otomatis.
|
|
15
6. Perencanaan Logistik
Melakukan perencanaan logistik dan penjadwalan untuk transportasi
otomatis.
7. Mesin Penerjemah
Mesin penerjemah adalah kemampuan komputer untuk menerjemahkan
dari satu bahasa ke bahasa lain.
2.1.4 Natural Language Processing
Menurut Pustejovsky dan Stubbs (2012:4), Natural Language Processing (NLP)
merupakan bidang dari ilmu komputer dan teknik yang telah dikembangkan dari stu
bahasa dan komputasi linguistik dalam bidang AI. Tujuan dari NLP adalah untuk
merancang dan membangun aplikasi yang memfasilitasi interaksi manusia dengan mesin
dan peran gkat lainnya melalui penggunaan bahasa natural. Beberapa area utama
penelitian pada bidang NLP, diantaranya:
1. Question Answering Systems
Question Answering Systems (QAS) atau dalam bahasa Indonesia yaitu
Sistem Tanya Jawab adalah kemampuan komputer untuk menjawab pertanyaan
yang diberikan oleh user. Dibandingkan memasukkan keyword ke dalam
browser pencarian, dengan QAS, user bisa langsung bertanya dalam bahasa
natural yang digunakannya, baik itu Inggris, Mandarin, ataupun Indonesia.
2. Summarization
Pembuatan ringkasan d ari sekumpulan konten dokumen atau e-mail.
Dengan menggunakan aplikasi ini, user bisa dibantu untuk mengubah dokumen
teks yang ke dalam bentuk slide presentasi.
3. Machine Translation
Produk yang dihasilkan adalah aplikasi yang dapat memahami bahasa
manusia dan menerjemahkannya ke dalam bahasa lain. Termasuk di dalamnya
adalah Google Translate yang apabila dicermati semakin membaik dalam
penerjemahan bahasa. Contoh lain lagi adalah BabelFish yang menerjemahkan
bahasa secara real time.
4. Speech Recognition
|
|
16
Bidang ini merupakan cabang ilmu NLP yang paling sulit. Proses
pemban gunan model pengenalanbahasa yang diucapkan bisa digunakan pada
telepon atau komputer sudah ban yak dikerjak an. Pengenalan ucapan yang sering
digunakan adalah berupa pertan yaan dan perintah.
5. Document Classification
Ini adalah salah satu area paling sukses dari NLP, di mana tugasnya
adalah untuk mengidentifikasi dalam kategori mana dokumen harus ditempatkan.
Hal ini sangat berguna pada aplikasi penyarin gan spam, klasifikasi artikel berita,
dan ulasan film.
2.1.4.1 Aspek Utama NLP
Berdasarkan Poole dan Mackworth (2010:520), pen gemban gan pemrosesan
bahasa natural memberikan kemungkinan interface
1. Syntax
Syntax menjelaskan bentuk dari bahasa. Biasa dispesifikasikan oleh
grammar. Bahasa alami jauh lebih rumit dibanding bahasa formal yang
digunakan untuk logika bahasa buatan dan program komputer.
2. Semantics
Semantic memberikan pengertian dari ungkapan dan kalimat suatu
bahasa. Meskipun teori semantic secara umum sudah ada, k etika membangun
sistem natural language understanding untuk aplikasi tertentu, maka akan
digunakan representasi yang paling sederhana.
3. Pragmatics
Komponen pragmatic menjelaskan bagaimana ungkapan berhubungan
dengan dunia.
2.1.5 Morfologi
Pengertian morfologi menurut Jurafsky dan Martin (2000:59-65) merupakan
pengetahuan mengenai pembentukan suatu kata dari unit-unit lebih kecil yang
mengandun g makna. Unit-unit terkecil dan mengandung makna itu sendiri disebut juga
morfem. Morfem dapat dibagi menjadi kata dasar dan imbuhan (afiks) yang selanjutnya
|
|
17
imbuhan itu dapat dibagi lagi menjadi prefiks, sufiks, dan kon fiks. Penggabungan k ata
imbuhan dan kata dasar disebut concatenative morphology. Dikarenakan penggabungan
tersebut akan menghasilkan suatu kata yang merupakan hasil penggabungan dua atau
lebih morfem yang dikonkatenasikan secara bersama-sama.
Proses morfologi dapat dibagi menjadi dua jenis menurut pembentukan kelas
kata yang dihasilkan. Dua jenis morfologi tersebut yaitu:
1. Morfologi Infleksional
Morfologi infleksional merupakan pemb entukan yang menghasilkan kata dengan
kelas kata yan g sama dengan kelas kata dari kata dasar pembentukn ya. Ciri-ciri
dari morfologi infleksional yaitu sistematis dalam artian polan ya teratur dan
memiliki maksud dan hasil yang jelas serta produktif dalam artian dapat
diterapkan pada semua kata dengan kelas kata yang sesuai. Contoh: “menulis”
yang merupakan
kata kerja dihasilkan dari kata dasar “tulis” yang juga
merupakan kata kerja.
2. Morfologi Derivasional
Morfologi derivasional merupakan pembentukan yang menghasilkan kata dengan
kelas kata yang berbeda den gan kelas kata dari kata dasar pembentuknya.
Kebalikan dari infleksional, morfologi derivasional ini justru memiliki ciri-ciri
tidak sistematis dan tidak produktif. Contoh: “penulis” yang merupakan kata
benda dihasilkan dari kata dasar “tulis” yang merupakan kata kerja.
Menurut Jurafsky dan Martin (2000:65), untuk membangun sebuah morphological
analyzer dibutuhkan:
1. Lexicon
Suatu daftar yang memuat semua kata dasar, imbuhan, dan semua informasi yang
dibutuhkan mengenai kata dasar dan imbuhan tersebut.
2. Morphotactics
Seluruh aturan yang mengatur urutan dan memodelkan penggabun gan morfem
dalam sebuah kata. Contoh: imbuhan meN- jika diletakkan di depan kata dasar
“makan” dari kelas kata kerja akan menghasilkan kata “memakan” yang
merupakan kata kerja. Aturan ini juga memastikan agar tidak menghasilkan kata
“makanme”.
|
|
18
3. Orthographics
Seluruh aturan pengejaan yang digunakan untuk bentuk perubah
yang terjadi
dalam kata, biasanya ketika morfem-morfem tersebut digabungk
Serin g juga
disebut morphophonemic. Contoh: imbuhan meN- digabungk
dengan kata
dasar “tulis” akan men gh asilkan kata “menulis”.
2.1.6 Pengertian B asis Data
Menurut Connolly d an Begg (2005:15) basis d ata merupak
suatu kumpulan
data dan deskripsi data yang saling terhubung satu sama la
secara logis dan dirancang
untuk memenuhi kebutuhan informasi dari suatu organisasi. Ba
data merup akan
entitas, atribut, dan hubungan logis antar entitas. Dengan ka
lain, basis data
menyimpan data yan g terkait secara lo gis.
2.1.6.1 Database Management System (DBMS)
Berdasarkan Connolly dan Begg (2005:16-17) DBMS adalah sistem peran gkat
lunak yang memungkinkan pengguna untuk mendefinisikan, membuat, memelihara, dan
mengontrol akses ke basis data. DBMS adalah perangkat lunak yang berinteraksi dengan
pengguna program aplikasi dan basis data. Biasan ya DBMS memberikan fasilitas
meliputi:
a. Data Definition Language (DDL)
Memungkinkan pengguna untuk menentukan tipe data dan struktur dan kendala
pada data yan g akan disimpan dalam basis data.
b. Data Manipulating Language (DML)
Memungkinkan pen ggu na untuk memasukkan, memperbaharui, menghapusm
dan mengambil data dari basis data. Memiliki sebuah pen yimpanan pusat untuk
semua data dan deskripsi data yang memungkinkan DML untuk memberikan
fasilitas penyelidikan data, disebut bahasa query. Query yang paling umum
digunakan adalah Structured Query Language (SQL).
c. Akses Kontrol ke Basis Data
i. Sistem keamanan, yang mencegah pen gguna yang tidak sah mengakses
basis data.
|
|
19
ii. Sistem integritas, yang mempertahankan konsistensi data yang tersimpan.
iii. Sistem kontrol konkurensi, yang memungkinkan berbagi akses basis data
secara bersamaan.
iv. Sistem kontrol pemulihan, yang mengembalikan basis data ke keadaan
yang konsisten sebelumn ya setelah terjadi kegagalan perangkat keras atau
perangkat lunak.
v. Katalog user-accessible, yang berisi deskripsi dar data dalam basis data.
2.1.6.2 MySQL
MySQL merupakan Relational Database Management System (RDBMS) yang
sangat cepat dan kuat. Basis data memungkinkan secara efisien untuk men yimpan,
mencari, mengurutkan, dan mengambil data. Kontrol server MySQL dapat men gakses
data untuk memastikan bahwa beberapa pengguna dapat bekerja secara bersamaan,
untuk memberikan akses cepat, dan untuk memastikan bahwa hanya penggun a yang
berwenang yang dapat memperoleh akses.
Oleh karena itu, MySQL adalah multiuser dan multithreaded server. MySQL
menggunakan Structured Query Language (SQL), standar bah asa query basis data.
MySQL tersedia untuk umum sejak tahun 1996 tetapi dibuat pada tahun 1979. (Welling
dan Thomson, 2008: 2-3).
Kompetitor utama MySQL adalah PostgreSQL, Microsoft SQL Server , dan
Oracle. Menurut Welling dan Thomson (200 8:4-6) MySQL mempunyai beberapa
kelebihan, yaitu:
1. Kinerja tinggi
Kecepatan MySQL tidak perlu diragukan lagi. Pada tahun 2002, eWeek
mengeluarkan perbandingan antara lima basis data aplikasi web. Hasil terbaik
didapatkan oleh MySQL dan kategori termahal adalah Oracle.
2. Biaya rendah
MySQL tersedia tanpa biaya dengan lisensi open source atau tersedia
dengan biaya murah untuk lisensi komersial. Dibutuhkan lisensi jik a ingin
mendistribusikan MySQL sebagai bagian dari aplikasi dan jika tidak aplikasi
|
|
20
berada di bawah lisensi open source. Jika aplikasi tidak ingin didistribusikan
maka tidak diperlukan membeli lisensi.
3. Mudah digunakan
Kebanyakan b asis data saat ini menggunakan SQL. Jika menggunakan
RDBMS lain, tidak akan menghadapi masalah untuk beradaptasi pada yang satu
ini. MySQL juga lebih mudah dalam pengaturannya dibanding beberapa produk
yang sama.
4. Portabilitas
MySQL bisa digunakan pada beberapa sistem Unix yang berb eda d engan
baik seperti pad a Microsoft Windows
5. Ketersediaan source cod e
Seperti PHP, source code MySQL bisa diperoleh dan dimodifikasi. Hal
ini tidak penting bagi sebagian besar pengguna, tetapi bisa memberikan
ketenangan pikiran yang baik, menjamin kelangsungan yan g akan datang, dan
memberikan pilihan saat keadaan darurat.
6. Ketersediaan dukungan
Tidak semua produk open source memiliki perusahaan induk yang
menawarkan dukungan, pelatihan, konsultasi, dan sertifikasi.
2.1.7 Hypertext Preprocessor (PHP)
Hypertext Preprocessor (PHP) adalah bahasa pemrograman server-sideyang
dirancang k husus untuk web. Dalam halaman HTML, dapat ditulis dengan kode PHP
yang akan dijalankan setiap kali halaman dikunjungi.Kode PHP tersebut akan
diinterpretasikan di web server dan menghasilkan HTML atau output lain yang dapat
dilihat oleh pengunjun g web.
PHP dibuat pada tahun 1994 dan awalnya merupakan kar ya satu orang yaitu
Rasmus Lerdorf. Kemudian hal ini diadopsi oleh orang-orang berbakat lainnya dan telah
melalui four major rewrite untuk menjadi seperti sekarang ini.
PHP adalah sebuah proyek open source, yang berarti
bisa mengakses ke source
code dan dapat digunakan, diubah, dan didistribusikan ulang tanpa biaya. PHP awalnya
diketahui sebagai Personal Home Pag e tetapi diubah sesuai d engan konvensi penamaan
|
|
21
rekursif GNU dan sekarang dikenal sebagai Hypertext Preprocessor. (Welling dan
Thomson, 2008:2-3).
Menurut Welling dan Thomson (2008:4-6) kelebihan menggunakan bahasa
pemrograman PHP, yaitu:
1. Kinerja tinggi
PHP sangat cepat, menggunakan server tunggal yang murah dan dapat
melayani jutaan hit per hari.
2. Skalabilitas
PHP sering mengacu sebagai arsitektur “shared-nothing”. Maksudnya
PHP secara efektif dan murah dapat menerapkan skala mendatar dengan
sejumlah besar server komoditas.
3. Integrasi basis data
PHP men yediakan kon eksi yang banyak ke berbagai sistem basis data.
Selain MySQL dapat terhubung secara langsung dengan basis data PostgreSQL,
Oracle, dbm, FilePro, DB2, Hyperwave, Informix, Inter Base, dan Sybase. PHP 5
juga memiliki built-ininterface SQL untuk flat file, disebut SQLite.
Menggunakan Open Database Connectivity Standard (ODBC), PHP
dapat terhubung ke basis data yan g menyediakan ODBC driver yang mencakup
produk Microsoft dan lain-lain. Selain libraries asli, PHP dilengkapi dengan
lapisan abstraksi akses basis data yang disebut PHP Database Objects (PDO),
yang memungkinkan akses yang konsisten dan meningkatkan keamanan kode.
4. Built-in Libraries
Karena PHP diran cang untuk digunak an pada web, maka PHP memiliki
banyak fungsi built-in untuk melakukan beberapa tugas web-relatedyan g
berguna. PHP dapat menghasilkan gambar dengan cepat, terhubung ke layanan
web dan layanan jarin gan lainn ya, mengurai XML, mengirim email, mengolah
cookies, menghasilkan dokumen den gan fo rmat PDF, dan semua itu hanya
memerlukan beberapa baris coding.
5. Biaya murah
|
|
22
PHP dapat diperoleh secara gratis. Bahasa pemrograman ini dap at
diunduh kapanpun dengan versi terbarunya di http://www.php.net tanpa
dikenakan biaya.
6. Mudah untuk dipelajari
Sintaksis dari PHP merupakan dasar dari bahasa pemrograman lainnya,
terutama bahasa C dan Perl. Jika sudah pernah menggunakan C atau Perl, atau
bahasa sep erti C++ atau Java, maka dengan segera akan dapat menggunakan
PHP.
7. Mendukung o rientasi objek
PHP versi 5 dirancang untuk mendukung fitur berorientasi objek. Mirip
dengan program pada Java atau C++, terdapat fitur seperti penurunan sifat,
atribut dan metode private dan protected, kelas abstrak, interface, constructor,
dan destructor. Bahkan terdapat juga fitur yang kurang umum seperti iterator.
Beberap a fungsi tersedia dalam PHP versi 3 dan 4, tetapi dukungan untk
orientasi objek pada versi 5 jauh lebih lengkap.
8. Portabilitas
PHP tersedia untuk banyak sistem operasi yan g berbeda-beda. PHP dapat
dijalankan di sistem operasi free Unix seperti Linux dan FreeBSD, dapat juga
dijalankan di versi Unix yang dikomersilkan seperti Solaris dan IR IX, OS X,
atau di Microsoft Windows yan g memiliki versi yan g berbeda-beda. Kode PHP
yang ditulis akan b ekerja tanpa perlu modifikasi pada sistem yan g berbeda.
9. Fleksibel
PHP memungkinkan untuk melakukan tugas-tugas sederhana dan mudah
beradaptasi terhadap aplikasi besar menggunakan framework berdasarkan
rancangan pola seperti M odel-View-Controller (MVC).
10. Ketersediaan source cod e
Source code dari PHP dapat diakses. Tidak sep erti produk yang komersial
yang men yembunyikan source code, jika ada yang ingin diubah atau
ditambahkan, maka d apat dilakukan secara bebas.
11. Ketersediaan dukungan dan dokumentasi
|
|
23
Dokumentasi dan komunitas PHP merupakan sumber daya yang matang
dan kaya dengan informasi untuk berbagi.
2.1.8 Hypertext Markup Language 5 (HTML5)
Menurut Clark, Studholme, Murphy, Manian (20 12:8) HTML5 merup akan salah
satu titik dalam sejarah panjang perkembangan HTML yang telah melewati berbagai
aspek dengan spesifikasi yan g berbeda. Walaup un berbed a, setiap spesifikasi HTML
memiliki satu kesamaan yan g paling mendasar, yaitu HTML meru pakan markup
language. HTML5 memiliki semua fitur yan g dimiliki oleh HTML4, dengan beb erapa
perubahan dan pengembangan. HTML5 juga memiliki banyak tambahan untuk membuat
web aplikasi yang dinamis dan membuat markup dengan kualitas yang lebih baik.
Adapun prinsip desain dari HTML5 menurut Clark, Studholme, Murphy, Manian
(2012:11) adalah sebagai berikut:
1. Memastikan dukungan untuk konten yang sudah ada
2. Mendegradasi fitur baru secara anggun di browser tua
3. Membuka jalan yang baru bagi pengembangan-pengembangan HTML
selanjutnya
4. Evolusi, bukan revolusi
2.1.9 Cascading Style Sheet (CSS)
Menurut Meyer (2006:1-3) Cascading Style Sheet (CSS) merupakan sebuah cara
untuk memberi pengaruh terhadap sebuah dokumen. Tentunya, CSS pada dasarnya tidak
berguna tanpa adan ya dokumen, karena CSS tidak memiliki konten untuk
dipresentasikan. Pastinya, definisi dari “dokumen” disini sangatlah luas. Sebagai contoh,
Mozilla dan beberapa browser terkait menggunak an CSS untuk mempengaruhi
presentasi dari brow ser yang digunakan. Namun , tanpa adanya konten pada browser
(button, textbox, windows, etc) maka CSS tidak perlu digunakan.
Pada tahun 1990-1993 (saat internet baru mulai dikenal oleh masyarakat), HTML
merupakan bahasa
yang cukup ramping. Ia terbentuk hampir seluruhnya oleh elemen
struktural yang berguna untuk mendeskripsikan paragraf, hyperlink, list, dan heading.
|
|
24
HTML tidak memiliki fungsi-fungsi seperti table, frames, atau lainnya yang berperan
penting dalam pembentukan halaman web.
Kemudian muncul Mosaic. Kemudian secara mendadak, World Wide Web
menjadi terkenal. Perpindahan antar satu dokumen ke dokumen lain tidak lebih sulit dari
mengarahkan kursor pada teks yang memiliki warna khusus atau bahkan gambar,
kemudian klik pada mouse.
Website menjadi terkenal dimanapun. Ada ban yak jurnal-jurnal pribadi, website
universitas, website perusahaan, dan lainn ya. Seiring bertambahnya jumlah website,
begitu juga dengan permintaan terhadap HTML baru yang dapat menjalankan fungsi
yang lebih spesifik. Pencipta mulai menginginkan HTML bisa membuat teks menjadi
tebal atau cetak mirin g. Namun pada saat itu HTML belum dapat menangani kasus
seperti itu.
Bertahun-tahun kemudian, muncullah HTML 3.2 dan HTML 4.0. HTML mulai
dapat menangani kasus-kasus yang lebih kompleks. Penggantian warna dan ukuran
tulisan, mengganti warna background dan image pada dokumen dan tabel, untuk
membuat tabel, dan membuat teks muncul-hilang mulai dapat ditangani HTML.
Namun masalah-masalah yang masih muncul dalam HTML adalah :
1. Halaman yang tidak terstruktur membuat penomor an konten menjadi sulit.
2. Struktur yang buruk membuat akses menjadi lebih sulit
3. Presentasi page yang lebih kompleks membutuhkan sesuatu struktur dari
dokumen pagar dapat ditampilkan den gan baik.
4. Markup yang terstruktur lebih mudah dikelola.
Kemudian muncul C SS dengan kelebihan :
1. Style yang lebih ban yak daripada HTML
2. Penggunaannya lebih mudah
3. Lebih mudah did esain mengikuti kein ginan prib adi
4. Cascadin g
5. Ukuran file yang lebih kecil sehingga membuka halaman web lebih cepat
|
|
25
2.1.10 Stemming
Menurut Kowalski (201 1:76), stemming adalah proses yang bertujuan untuk
mengurangi jumlah v ariasi dalam representasi dari sebuah konsep menjadi morfologi
standar atau representasi resmi. Resiko dari proses stemming adalah informasi dari suatu
konsep mungkin hilang dalam proses, sehingga akurasi atau presisi menurun, dan
mengurangi performa. Keuntungan dari proses stemming adalah untuk meningkatkan
kemampuan men gingat. Tujuan utama dari stemming adalah meningkatkan performa
dan menguran gi penggunaan sumber daya sistem, dengan men gur angi jumlah kata
unique yang seharusnya ditampung oleh sistem. Jadi, secara keseluruhan algoritma
stemming mengubah kata menjadi sebuah representasi morfologi standar yang disebut
stem.
2.1.11 Lemmatization
Lemmatization menurut Ingason, Helgadóttir, Loftsson, Rögnvaldsson (2008:1)
adalah proses men cari bentuk dasar atau lemma (bentuk kamus) suatu bentuk kata
tertentu. Proses ini mirip tapi tidak sama dengan proses stemming yang menghapus afiks
dari sebuah kata dan mengembalikan kata dasar . Lemmatization dan stemming adala
teknik normalisasi yang digunakan untuk menciptakan hubungan dan bentuk kata.
Nirenburg (2009:31) memperkuat teori ini dengan menjelaskan bahwa
lemmatization adalah proses yang ditujukan untuk normalisasi teks, sesuai hubungan
pasangan dari bentuknya berdasarkan lemma. No rmalisasi pada konteks ini merupakan
proses mengidentifikasi dan menghapus prefiks dan sufiks dari sebuah kata. Masalah
umum pada analisis morf ologi meliputi proses derivasi yang sangat berhubungan dengan
bahasa aglutinatif. Selain itu, bentuk dari kata prefiks dan sufiks mungkin memiliki
banyak interpretasi, jadi algoritma lemmatization harus menentukan konteks dari bentuk
katanya, yang menganalisis kemungkinan atau kesesuaian dengan konteks.
Manning, Raghavan, Schütze (2009:32) mengatakan bahwa tujuan stemming dan
lemmatization adalah untuk mengurangi bentuk infleksional dan terkadang bentuk
hubungan derivasi suatu kata pada bentuk umumnya. Sebagai contoh:
a. Input: “The bo y’s cars are different colors”
|
|
26
b. Transformation: am, is, are => be
c. Transformation: car, cars, car’s, cars’ => car
d. Result: “The boy car be differ color”
Namun tetap terdapat perbedaan diantara keduanya. Stemming mengacu pada
proses heuristik dengan memenggal ujung-ujung kata dengan harapan mencap ai tujuan
dengan benar. Lemmatization biasanya melakukan proses mengacu pada kosa kata dan
analisis morfologi kata, biasanya bertujuan untu k mengh apus akhiran infleksional saja
dan mengembalikan hasiln ya sesuai bentuk k ata dalam kamus atau lemma. Perbed aan
yang lain terletak pada bentuk derivasi. Metode stemming biasanya akan memotong
kata-kata derivasi yang bersangkutan, sedangkan lemmatization hanya menghapus
bentuk-bentuk infleksional dari sebuah lemma.
2.2 Penelitian-penelitian Terkait
2.2.1 Jurnal A Two-Level Morphological Analyzer for Indonesian Language
Berdasarkan dari jurnal A Two-Level Morphological Analyzer for Indonesian
Language (Pisceldo, Mahendra, Manurung, 2008), rancangan morphological analyzer
untuk Bahasa Indonesia disini dibagi menjadi dua komponen, yaitu aturan morphotactic
dan aturan morphophonemic. Aturan-aturan pad a tiap komponen biasanya diterapkan
secara parallel. Selain itu aturan ini dikombinasikan dengan kosa kata dalam untuk
melengkapi rancan gan.
Sebuah kata yang akan dianalisis, akan men gikuti jalurkosa kata aturan
morphotactic aturan morphophonemic surface. Sebelum hasil d
morphological
analyzer muncul pada surface, hasil tersebut akan mengikuti jal
kosa kata untuk
menentukan morfem yang sebenarn ya pada kata tersebut. Setelah mela
kosa kata, kata
tersebut akan dianalisis oleh aturan morphotactic d
morphophonemic. Apabila sudah
menyelesaikan proses dalam aturan morphotactic dan morphophonem
hasil analisis
dari morphological analyzer untuk kata tersebut akan disampaikan.
2.2.1.1.1 Rancangan Kosa Kata
Kosa kata disini disamakan dengan set kata dasar dari kata-kata dalam bahasa
Indon esia. Afiks tidak disimpan pada kosa kata karena n antinya akan diperhitungkan
|
|
27
untuk aturan morphotactic. Untuk rancangan awal, kosa kata dibagi menjadi empat kelas
yaitu verb, noun, adjective, dan ‘etc’, yang mencakup semua kata dasar, contohnya
pronoun, adverb, numb er, dan particles. Men gelompokkan kel
kata merupakan
penyederhanaan yang besar, dan menjadi salah satu yang diharapk
untuk direvisi pada
penelitian di masa depan.
2.2.1.1.2 Rancangan Tag
Rancangan tag menjadi sangat penting karena tag ak
mengantarkan informasi
linguistik yang terjadi pada sebuah kata yang dianalisis. Pa
penelitian ini, tag-tag yan g
akan dirancang dibagi menjadi tag normal dan tag speci
Tag normal bisa menjadi
output dengan komponen morphotactic tanpa kondisi apap
sementara tag special
hanya terjadi jika kata dasar yang terlibat berhubung
dengan penanda yang spesifik
pada kosa kata.
2.2.1.1.3 Aturan Morphotactic
Dalam perancangan morphological analyzer, aturan morphotactic merupakan
aturan yang krusial untuk memodelkan bagaimana dua atau lebih morfem bisa digabung.
Berdasarkan (Alwi, 2003), atur an morphotactic untuk bahasa Indonesia bisa
diklasifikasikan menjadi 13 kelas. Sepuluh dari kelas-kelas ini ditentukan berdasarkan
sufiks yang digabung dengan kosa kata, sementar a tiga lainnya adalah kasus reduplikasi.
Sepuluh kelas p ertama bisa diidentifikasi sebagai concatenative morphology sedangkan
tiga kelas lainnya nonconcatenative morphology.
Selama tingkat atu ran morphotactic, ada beberapa langkah yang harus diikuti
untuk menyelesaikan proses. Langkah tersebut termasuk penambahan prefix dan
preprefiks, penambahan sufiks dan proses akhir penambahan tag. Setelah menyelesaikan
semua langkah tersebut, selanjutnya pindah ke proses morphophonemic.
2.2.1.1.4 Aturan Morphophonemic
Seluruh aturan-aturan yang menjelaskan bagaimana dua atau lebih morfem bisa
digabung sudah dirancang dalam aturan morphotactic. Namun proses pen ggabungan ini
masih belum selesai, oleh sebab itu masih harus dijelaskan perubahan apa yang har
|
|
28
dilakukan setelah morfem-morfem tersebut bergabung. Untuk masalah ini, didefinisikan
aturan morphophonemic yang menentukan p erubahan fonetik yang terjadi.
Di Indonesia, aturan ini secara general bisa dibagi menjadi dua bagian. Bagian
pertama terdiri dari empat aturan yang memodelkan perubahan fonetik dalam kata dasar,
sedangkan bagian kedua terdiri dari tujuh aturan yang memodelkan perubahan fonetik
dalam afiks.
Setelah semua subproses dipakai oleh aturan-aturan dalam bagian pertama dan
bagian kedua secara paralel, kemudian seluruh proses morphophonemic selesai.
Rancan gan aturan morphophonemic untuk reduplikasi sangat mirip seperti di
afiksasi, karena pada dasarnya proses morphophonemic dalam reduplikasi terjadi pada
bagian afiksasi dari reduplikasi.
Namun, beberapa aturan tersebut, model proses morphophonemic yang mana
keduanya afiks dan kata dasar mengalami perubahan, harus direvisi untuk
memperhitungk an sifat aturan tersebut ketika diterapkan pada bentuk reduplikasi.
2.2.1.2 Implementasi
Pada morphological analyzer bahasa Indonesia ini mengimplementasikan xfst
dan lexc. Aturan morphotactic diimplementasikan dalam xfst kemudian aturan
morphophonemic diimplementasikan dalam lexc.
2.2.1.2.1 Implementasi Aturan Morphotactic
Aturan morphota ctic bisa diilustrasikan sebagai finite-state automata. Kata-kata
bahasa Indonesia yang valid, yaitu kata-kata yang dibentuk melalui proses
morphological diterima oleh automata, sebaliknya kata-kata yang invalid ditolak.
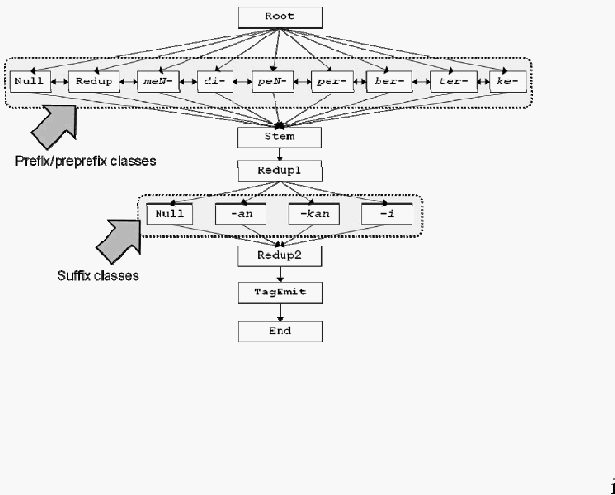
Dimulai dari Root, tiap state menjelaskan state selanjutnya yang memungkinkan
sambil menunjukkan (atau mengkonsumsi) simbol tertentu. Pada lexc, state-state ini
disebut kelas lanjutan. Seluruh kelas lanjutan dicapai dari Root menunjukkan prefiks dan
pre-prefiks. Perb edaan antara keduan ya ad alah diperlukan untuk mengodekan variasi
morfologi yan g memungkinkan yang mengandung dua prefiks, seperti memper-, diper-.
Dari sana kelas lanjutan selanjutnya adalah Stem, dimana akar kata diproses. Hal ini
kemudian diikuti oleh beberapa kelas yan g mewakili sufiks yang mungkin, tapi ada juga
|
 29
kelas Redup1 dan Redup2 yang muncul sebelum dan sesudah sufiks. Fungsi keduanya
adalah untuk mengatasi reduplikasi. Terakhir, kelas TagEmit memproses seluruh tag-tag
yang belum ditangani dengan mendahului kelas.
Gambar 2.1 Ilustrasi Alur Proses
(Sumber: Pisceldo, Mahendra, Manurung. 2008:5)
Selama proses morphotactic ini, digunakan pen anda diakri
secara ekstensif,
fitur penting dari lexc yang mendekati kekuatan fitur struktur, ya
mamp u menentukan
batasan tertentu untuk memastikan bahwa hanya jalur yang va
dari jaringan d apat
dilalui. Satu keuntungan dari pendekatan ini ad alah pemeli
aan representasi compact
network. Ada tiga penanda diakritik yang digun akan: pengaturan pos
(@P.feat.val@),
diperlukan uji (@R.feat.val@), melarang uji (@D.feat.val
Menggunakan diakritik ini
dapat ditetapkan nilai-nilai dan kendala dari aspek-aspek terte
yang harus konsisten
sepanjang jalur.
2.2.1.2.2 Proses Reduplikasi
Morfologi Indonesia meliputi proses reduplikasi non-concatenative. Penanganan
ini dengan tata bahasa regular murni seperti yang diterapkan oleh finite state automoata
sangat sulit. Dengan demikian, digunakan fitur compile-replace pada xfst. Fitur ini
|
|
30
memungkinkan pengulangan sub-bahasa kompleks semaunya dengan men etapkan tanda
kurung “^[“ dan “^]” untuk menandai domain d ari reduplikasi. Kurung siku kanan juga
ditambah dengan ^2 untuk menunjukkan duplikasi, dengan demikian menjadi “^[“ dan
“^2^]”. Mengingat ini, xfst mengkompilasi dan memproses anotasi ini untuk
menghasilkan jaringan baru di
mana reduplikasi yang sesuai telah dilakukan. Contoh,
“^[ buku^2^]” akan dikompilasi menjadi bukubuku. Jadi idenya adalah untuk
memasukkan “^[” dan “^2^]” di tempat yang tepat. Karena berbagai jenis reduplikasi
dalam bahasa Indonesia, aturan reduplikasi dapat ditemukan pada bagian Redup
(pre)prefiks juga pada bagian Redup1 dan Redup2. Redup bagi
prefiksmengemisikan
pembukaan tand a kurung “^[” dan menetapkan penanda atau fl
yang tepat sebagai
pengingat bahwa kurung tutup diperlukan. Redup1 bertanggung jaw
untuk menutup
reduplikasi sebagian dan afiks, yaitu di mana akh iran tidak termas
dalam reduplikasi,
sementara Redup2 bertanggung jawab untuk menutup reduplik
penuh, yaitu di mana
sufiks merupakan bagian dari proses reduplikasi. Baik Redup1 d
Redup2 memeriksa
nilai flag REDUP yang diset oleh Redup prefiks.
2.2.1.2.3 Implementasi Aturan Morphophonemic
Full transducer menyusun aturan morphotactic dan morphophonemic. Sebagai
hasilnya, output dari implementasi aturan morphotactic berfungsi sebagai input untuk
implementasi aturan morphophonemic.
Implementasi aturan morphophonemic sedikit berbeda dengan implementasi
aturan morphotactic. Untuk aturan morphotactic ada beber apa langkah yang dapat
digambarkan sebagai aliran proses. Namun, pelaksanaan aturan morphophonemic
umumnya mengimplikasikan aturan itu sendiri. Setiap aturan didefinisikan sebagai
aturan pengganti yang akan berkolaborasi dengan aturan lain melalui komposisi atau
paralelisasi.
2.2.1.3 Evaluasi Jurnal A Two-Level Morphological Analyzer for Indonesian
Language
Untuk mengevaluasi sistem yang diterapkan, diuji melalui beberapa tes kasus
dalam bentuk kata-kata yang diambil dari Kamus Besar Bahasa Indonesia versi
|
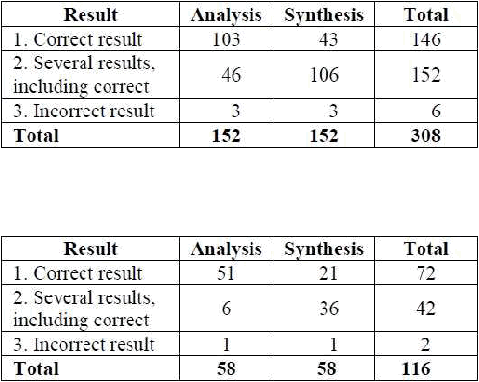 31
elektronik. Pengujian implementasi dari aturan morphotactic d
morphophonemic
dilakukan secara terpisah. Untuk mengevaluasi kemampuan d
analyzer menerima
bentuk valid dan menolak bentuk invalid, dibutuhkan kombinasi
kasus morfem valid
maupun morfem invalid. Setelah mengeksekusi seluruh uji kas
diperoleh hasil yang
ditampilkan pada Tabel, yang menampilkan hasil uji kasus morphotac
dan Tabel yang
menampilkan hasil uji kasus morphophonemic. Pada kol
‘Analysis’ menampilkan
hasil uji kasus dimana bentuk kata bahasa Indon esia diberik
sebagai input, dan sistem
ditugaskan untuk parsing struktur morfologi. Sebagai cont
diberikan kata memukul,
sistem harus memberikan output pukul+Verb+AV. Di sisi la
kolom ‘Synthesis’
memperhatikan situasi sebaliknya, yaitu uji kasus dimana in
adalah string tag-tag
morfologi, dan sistem ditugaskan untuk menghasilkan bentuk infle
secara lengkap.
Tabel 2.2 Hasil Uji Kasus Morphotactic
(Sumber: Pisceldo, Mahendra, Manurung, 2008:8)
T abel 2.3 Hasil Uji Kasus Morphophonemic
(Sumber: Pisceldo, Mahendra, Manurung, 2008:8)
|
|
32
Hasil uji kasus diklasifikasikan menjadi tiga kategori. Kategori pertama
menunjukkan bahwa sistem menghasilkan tepatnya satu analisis atau sintesis yang b enar
untuk uji kasus valid, atau tidak menghasilkan apapun untuk uji kasus invalid. Kategori
kedua adalah ketika diberikan uji kasus valid, sistem menghasilkan beberapa jawaban,
salah satun ya adalah hasil yang diharapkan. Kategori terakhir terlihat saat sistem gagal
untuk menganalisis atau mensintesis uji kasus yang valid, atau salah menghasilkan
jawaban untuk uji kasus yang invalid. Dari table dapat diamati bahwa hasil analisis yang
lebih akurat daripada bentuk
sintesis, dimana sistem cenderung untuk menghasilkan
lebih dari satu hasil.
2.2.1.4 Hasil Jurnal A Two-Level Morphological Analyzer for Indonesi
Language
Hasil dari penelitian ini menyajikan sebuah morphologi
analyzer bahasa
Indon esia yang memb erikan analisis rinci dari proses afiks
menggunakan pendekatan
morfologi dua tingkat, yang diimplementasikan menggun akan x
dan lexc. Pendekatan
ini mampu menangani reduplikasi, proses morfol
non-concatenative. Evaluasi
menunjukkan bahwa implementasi umumnya mampu unt
meng-encodeaturan dari
berbagai proses morfologi.
2.2.2 Jurnal Indonesia Morphology Tool (MorphInd) Towards an Indonesian Corpus
Berdasarkan dari jurnal dari (Larasati, Kubo n, dan Zeman, 2011) ini dijelaskan
tentang finite state morphology tool yang kuat untuk bahasa Indonesia atau bisa
disingkat MorphInd. Penelitian ini menjelaskan mengenai analisis morphological dan
lematisasi dari kata-kata yang diberikan supaya bisa diproses lebih jauh.
2.2.2.1 Perancangan Alat
MorphInd dirancang untuk menangani empat isu yakni kategorisasi lexical yang
dangkal, analisis yang tidak dispesifikan, aturan morphosyntactic serta lisensi software.
MorphInd men ghasilkan analisis yang hanya mencakup fenomena-fenomena morfologi,
syntax-nya tidak ditan gani, namun kelu arannya bisa digunakan
untuk fungsi-fungsi
Natural Language Processing lainnya. MorphInd menganalisa tanda-tanda sebagai
unigrams dan tidak memperhitungkan tanda-tanda yang bersebelahan. MorphInd tidak
|
|
33
mengembalikan fungsi – fungsi yan g berhubungan den g
sintaksis dalam analisanya,
walaupun beberapa fun gsi dengan mudah dikenal oleh kata-k
atau klitik. Sebagai
contoh, kita tidak bisa menandai ‘subjek’ dari suatu kali
dimana kata tersebut dapat
dikenali dengan proklitik yang sudah umum yang menempel
sebuah kata k erja,
namun kenyataannya bahwa kata tersebut memiliki prolitik k
ganti yang disimpan
untuk analisis.
2.2.2.1.1 Perancangan Tagset dan Kategori Leksikal
Morph Ind membagi lek sikal menjadi 17 kategori. Kate
ri-kategori tersebut
pada dasarnya adalah ‘ Noun’, ‘Verb’, ‘Adjective’ seperti
dalam IndMA (mengacu
pada jurnal sebelum ini), dan kategori
‘etc’ dipecah l
menjadi beb erapa kategori
seperti ‘Preposition’ dan ‘Modal’ dimana sebagian besar kateg
ini merupakan kelas
kata tertutup yang sangat mudah untuk didaftarkan secara manual.
Morph Ind juga memiliki tagset yang berjaringan, terinpirasi d
tagset PENN
Treebank dan mengadaptasinya ke dalam morfologi baha
Indonesia. Tagset tersebut
juga mengambil konsep tag posisional dari Prague Dependen
Treebank tagset untuk
menangani sebagian besar perilaku bahasa yang terjadi secara bersamaan
kata dasar.
2.2.2.1.2 Analisis Format
Morph Ind memutuskan untuk membuat output dalam bent
morfem yang
tersegmentasi, dimana hal tersebut akan menunjukkan bagaima
morfem tersebut
dibentuk. Hal ini akan membuat output lebih tepat dan lebih tid
ambigu dalam proses
generasi. Bentuk kata dasar disegmentasi ke morfemn
masing-masing. Lemma diikuti
oleh tag lemma, yang berkorespondensi dalam posisi perta
tag pembentukan kata,
dan dapat dibedakan den gan huruf kecil. Tag lemma da
berb eda dari posisi pertama
dari token yang sama, hal ini disebabkan karena derivasi.
2.2.2.1.3 Morphosyntactic dan Morphoponemic
Bahasa Indonesia bukan merupakan bahasa yang terinfleksi seperti bahasa
Slavia, meskipun demikian beberapa morfem yang membawa fitur-fitur bahasa seperti
konjugasi kata kerja untuk menandai kata aktif dan pasif. Bahasa Indonesia adalah
|
 34
bahasa yang agak aglutinatif jika dibandingkan dengan bahasa Tu
atau Finlandia
dimana perbandingan morfem per kata lebih tinggi. Ada bebera
subjek atau objek
yang bisa direpresentasikan sebagai klitik (proklitik ataupun enklitik).
2.2.2.2 Evaluasi Jurnal Indonesia Morphology Tool (MorphIn
Towards an
Indonesian Corpus
MorphInd dan IndMA dijalankan ke beberapa tulisan ya
telah dikumpulkan
untuk mengukur cakupannya. Ada dua jenis tes yaitu T5K yang terd
dari 5000 kalimat
dan T10K yang terdiri dari 10000 kalimat. Terdapat 9 set T5K d
terdapat 4 set T10K.
Kalimat-kalimat tersebut diambil secara acak tanpa perubah
dari kalimat yang telah
diambil tersebut.
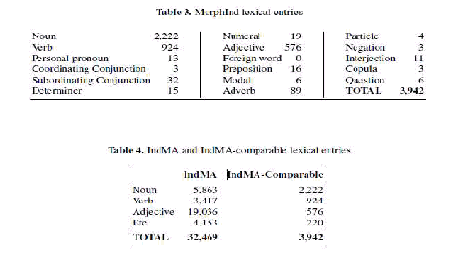
MorphInd terdiri dari 3954 entri kata yang dibagi menjadi
kategori. IndMA
dibuat ulang dengan entri kata yang sama dengan Morph I
agar hasilnya bisa
dibandingkan. Adapun tabel lexical entri d ari MorphInd d
IndMA adalah sebagai
berikut :
Tabel 2.4 MorphInd Lexical Entries
(Sumber: Larasati, Kubo n, Zeman, 2011:10)
MorphInd gagal untuk melampaui performa IndMA dalam cakupan yang unik
karena jumlah entri lexical sangat berbeda dan entri lexical MorphInd tidak mengandung
kata benda dan kata asing. Namun, d engan pilihan yang baik dari entri lexical, dengan
|
|
35
memilih lemma yan g paling sering digunakan dan pali
produktif, caku pan MorphInd
secara keseluruhan akan lebih besar daripada IndMA. Hal
disebabkan karena
Morph Ind meliputi klitik, alternasi angka, dan tambahan parti
morfem yang tidak
dicakup dalam IndMA. Hal ini bisa dilihat dari ha
MorphInd dan IndMA, dimana
Morph Ind memiliki cakupan lebih baik dengan entri lexical yang sama.
2.2.2.3 Kesimpulan Jurnal Indonesia Morphology Tool (MorphInd) Towards an
Indonesian Corpus
Morph Ind membuat informasi morfologikal dalam format output n ya menjadi
segmentasi morfemik, posisi lemma morfem, kategori lexical, dan fitur-fitur
morphological. MorphInd memberikan cakupan yan g lebih b
jika dibandingkan
dengan IndMA.
2.2.3 Jurnal Stemming Indonesian: A Confix-Stripping Approach
Berdasarkan jurnal Stemming Indonesian: A Confix-Stripping Approach
(Adriani, Asian, Nazief, Tahaghoghi, Williams, 2007) dijelaskan bahwa pada tahun
2005, Asian, Williams, dan Tahaghogi berusaha meningkatkan akurasi NAZIEF (1996),
karena pendekeatan dan akurasi stemming untuk bahasa Indonesia pada NAZIEF
merupakan yang terbaik. Berdasarkan analisis mereka, kesalahan yang terdapat pada
NAZIEF sebagian besar disebabkan oleh beberapa aspek: non-root dalam kamus, kamus
tidak lengkap, dan kata ditulis dengan tanda penghubun g kata, sedangkan sisanya
disebabkan oleh aturan yang tidak efektif dan urutan aturan. Pada 2007, Adriani, dkk.
berkolaborasi untuk membuat paper yang menyampaikan “Confix-Stripp ing Stemmer”,
memperbaiki versi dari NAZIEF. Aturan modifikasi dan perubahan algoritma yang
adalah sebagai berikut:
1. Input pertama-tama diperiksa dalam kamus. Jika input ditemukan dalam kamus,
maka input dikembalikan sebagai lemma.
2. Sufiks infleksional partikel (-kah, -lah, -tah, -pun) akan dihapus dari input, dan
sisanya akan disimpan dalam variable string (CURRENT_WORD), lalu cek
dalam kamus. Jika kata ditemukan, proses akan berhenti.
|
|
36
3. Sufiks infleksional kata ganti kepemilikan (-ku, -mu, -nya) akan dihapus dari
CURRENT_WORD, lalu dicek dalam k amus. Jika kata ditemukan, proses akan
berhenti.
4. Sufiks derivasi (-i, -kan,
-an) akan dihapus dari CURRENT_WOR D, lalu dicek
dalam kamus. Jika kata ditemukan, proses akan berhenti.
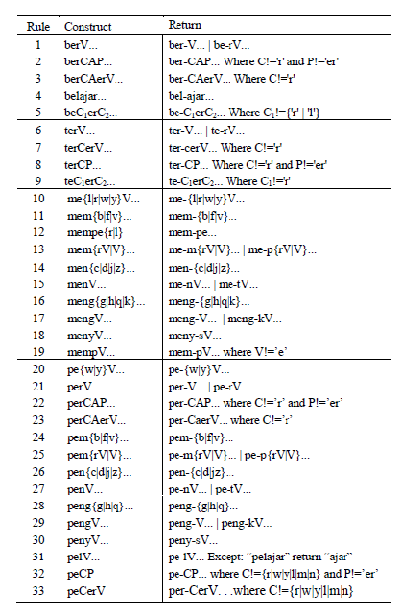
5. Pada tahap ini berfokus pada pen ghapusan prefiks derivasi (beN-, di-, ke-, meN-,
peN-, se-, teN-) dari CURRENT_WORD. Tahap ini terjadi rekursif karena
morfologi prefiks derivasi bahasa Indonesia akan terhambat. Beberapa prefiks
(di-, ke-, se-) dianggap sederhan a, karena pada praktiknya tidak mengubah
lemma. Sebaliknya, prefiks lainnya (beN-, meN-, peN-, teN-) mengubah lemma,
dan berbeda dengan huruf pertama pada lemma. Perubahan tersebutdicantumkan
dalam tabel di bawah.
|
 37
Tabel 2.5 Perubahan Prefiks
(Sumber: Adriani, Asian, Nazief, Tahaghoghi, Williams, 2007:13)
Ada beberapa kondisi terminasi untuk tahap ini:
1. Penghapusan prefiks dan afiks tercantum dalam tabel pasangan afiks
valid di bawah
|
 38
2. Prefiks dihapus secara langsung setara dengan penghapusan prefiks
sebelumnya
3. Batas rekursif untuk tah ap ini sebanyak tiga kali
Tabel 2.6 Pasangan Prefiks dan Afiks yang Tidak Bisa Dikombinasi
(Sumber: Adriani, Asian, Nazief, Tahaghoghi, Williams, 2007:6)
Penghapusan prefiks ak an direkam, dan CURRENT_WORD akan dicek dalam
kamus. Jika CURRENT_WORD tidak terdapat
di dalam kamus dan kondisi
terminasi meyakinkan, maka tahap 5 akan diulang dengan CURRENT_WORD
sebagai input.
6. Jika CURRENT_WORD tetap tidak ditemukan pada tahap 5, maka tabel 2.5
akan memeriksa apakah recoding memungkinkan. Pada aturan yang ditetapkan,
ada beberapa aturan yang menyimpan lebih dari satu output. Gunakan aturan 17
sebagai mengV memiliki dua output: meng-V atau meng-kV. Pada tahap 5,
output pertama (sebelah kiri) akan selalu dipilih pertama dan ini akan
menyebabkan kesalahan. Recoding dilakukan untuk mengembalikan jenis
kesalahan dengan kembali ke tahap sebelum tahap 5 dimana pemilihan output ini
terjadi dan seb agai gantinya memilih output lain.
7. Jika CURRENT_WORD masih tetap tidak ditemukan dalam kamus, maka input
diawal akan dik embalikan.
Untuk mengatasi penyebab kesalahan besar seperti disebutkan di atas (yaitu non-
root dalam pencarian kamus, kamus tidak lengkap, kata-kata yang ditulis dengan
kata penghubung), Adriani menyarankan tiga pen dekatan:
|
|
39
1. Meningkatkan kualitas kamus dengan menggunakan sumber kamus yang
berbeda dan membandingkan tingkat akurasinya dengan kamus sebelumnya.
2. Menambahkan aturan tambahan untuk mengatasi kata yan g ditulis dengan tanda
penghubung yang men gandung reduplikasi (seperti, “bulir-bulir”) kemudian
akan dipotong menjadi “bulir”. Hal ini juga berlaku untuk kata dengan tanda
penghubung den gan afiks (seperti, “seindah-indahnya”), afiks akan dihapus
pertama dan kemudian diperiksa apakah pasangan kata tersebut dapat dipotong.
3. Modifikasi aturan prefiks dan sufiks:
a. Aturan perubahan prefiks (“ter-“, “pe-“, “mem-”, dan “meng-”) dimana
sudah dicantumkan pada tabel 2.5 di atas. Lebih rincinya aturan nomor 9
dan 33 ditambahkan dan aturan nomor 12 dan 16 dimodifikasi dari aturan
sebelumnya.
b. Penghapusan prefiks akan dilakukan sebelum penghapusan sufiks jika
diberikan kata pasangan afiks seperti pada berikut ini:
i. “be-“ and “-lah”
ii. “be-“ and –an”
iii. “me-“ and “-i”
iv. “di-“ and “-i”
v. “pe-“ and “-i”
vi. “ter-“ and “-i”
Dibandingkan dengan NAZIEF dengan dataset yang sama, modifikasi NAZIEF
mencapai tingkat akurasi 2-3% lebih tinggi (kurang lebih 95%).
2.2.4 Jurnal Lemmatization Technique in Bahasa: Indonesian Language
Berdasarkan jurnal Lemmatization Technique in Bahasa Indonesian Language
(Suhartono, Christiandy, Rolando, 2014) dijelaskan mengenai teknik pencarian bentuk
kata dasar
dari kata berimbuhan menggunakan teknik lemmatization yang merupakan
pengembangan dari tekn ik stemming yang sudah pernah diteliti oleh Adriani, Asian,
Nazief, Tahaghoghi, dan Williams (2007) yang juga merupakan pengembangan dari
penelitian sebelumnya oleh Asian, Williams, Tahaghoghi (2005).
|
|
40
2.2.4.1 Algoritma
Algoritma lemmatization dikembangkan b erdasarkan state of the art, Enhanced
Confix Stripping Stemmer (selanjutnya disebut ECS). Penelitian ini tidak bertujuan
untuk mengembangkan ECS, karena memiliki maksud dan tujuan yan g berb eda.
Sebaliknya, algoritma lemmatization bertujuan untuk memodifikasi ECS agar sesuai
dengan konsep lemmatization. Namun, terdapat kesamaan dalam beberapa p roses,
misalnya penghapusan afiks untuk memperoleh bentuk lemma. Diharapkan algoritma
lemmatization mampu menangani b eberapa kasus yang tidak berjalan sempurna pada
ECS.
Algoritma lemmatization meliputi beberapa proses:
A. Pencarian Kamus. Proses ini memeriksa apakah kata tersebut terdapat dalam
kamus. Jika pencarian berhasil maka algoritma akan berhenti dan lemma akan
dikembalikan sebagai hasil.
B. Rule Precedence. Proses ini dilakukan untuk menentukan urutan eksekusi proses
lain. Ada beberapa kombinasi prefiks-sufiks yan g bisa dihasilkan lebih cepat dan
lebih akurat, jika pen gh apusan prefiks dijalankan
sebelum penghapusan sufiks.
Berikut adalah kombinasi aturan-aturan yang terdapat pada rule precedence:
1. be- dan –an
2. me- dan –i
3. di- dan -i
4. pe- dan -i
5. te- dan –i
Jika kata input yan g dimasukkan terdapat kombinasi pasangan prefiks-sufiks
yang sesuai dengan aturan, maka urutan eksekusi akan menjadi penghapusan
prefiks derivasi, recoding, penghapusan sufiks infleksional, dan penghapusan
sufiks derivasi. Sebaliknya, jika pasangan afiks tidak terdapat pada kata input
yang diberikan, maka urutan yan g akan diek sekusi terlebih dahulu adalah
penghapusan sufiks infleksional dan penghapusan sufiks derivasi.
C. Penghapusan Sufiks Infleksional. Sufiks infleksional memiliki dua tipe sufiks,
partikel {‘-lah’, ’-kah’, ’-tah’, dan ‘-pun’} dan k ata ganti kepemilikan {‘-ku’, ’-
mu’, ’-nya’}. Struktur bahasa Indonesia menyatakan b ahwa partikel selalu
|
|
41
ditambahkan pad a sufiks terakhir sebuah kata. Jadi proses ini akan menghapus
sufiks partikel terlebih dahulu sebelum menghapus sufiks kata ganti kepemilikan.
D. Penghapusan Sufiks Derivasi. Proses ini akan menghapus sufiks derivasi {-in -
kan,-an} dari kata yang diberikan. Sufiks derivasi selalu ditambahkan pada kata
sebelum sufiks inflek sional. Jadi proses ini selalu dieksekusi setelah
penghapusan sufiks infleksional.
E. Penghapusan Prefiks Derivasi. Prefiks derivasi terdapat dua jenis, biasa {‘di-‘,
‘ke-’, ‘se-‘} d an komp leks {‘me-‘, ‘be-’, ‘pe-’, ‘te-’}. Prefiks biasa tidak
memerlukan aturan apapun dan tidak mengubah ketika ditambahkan pada kata,
yang berarti proses penghapusan dilakukan secara langsung ketika terdapat
prefiks biasa. Di sisi lain, perubahan prefiks kompleks mengubah kata ketika
ditambahkan. Bahasa Indonesia memungkinkan kombinasi prefiks derivasi pada
sebuah kata. Namun terdapat kendala yang membatasi kemungkinan kombinasi.
Kombinasi yang memungkinkan adalah:
1. ‘di-’, diikuti oleh tipe prefiks ‘pe-’, atau ‘be- ’, contoh “diperlakukan” dan
“diberlakukan”
2. ‘ke-’, diikuti oleh tipe prefiks ‘be-’, atau ‘te-’, contoh “kebersamaan” dan
“keterlambatan”
3. ‘be-’, diikuti oleh tipe prefiks ‘pe-’, contoh “berpengalaman”
4. ‘me-’, diikuti oleh tipe prefiks ‘pe-’, ‘te-’, atau ‘be-’, contoh
“mempersulit”, “menertawakan”, dan “membelajarkan”
5. ‘pe-’, diikuti oleh tipe prefiks ‘be-’, contoh “pemberhentian” dan
pengecualian “penertawaan”
Algoritma lemmatization akan menghapus sampai tiga prefiks d an tiga sufiks,
sementara tiga sufiks terdiri dari tipe sufiks derivasi, kata ganti kepemilikan, dan
sufiks partikel mengikuti aturan kombinasi di atas. Oleh karena itu, proses ini
berulang sampai tiga kali iterasi. Pada akhir setiap iterasi, kata pada saat itu
dilakukan pencarian kamus untuk mencegah overstemming. Penghentian juga
terjadi ketika prefiks saat ini diidentifikasi sudah dihapus pada iterasi
sebelumnya atau kata mengandung konfiks yang dilarang. Berikut adalah aturan
konfiks yang dilarang dalam bahasa Indonesia:
|
 42
Tabel 2.7 Konfiks yang Dilarang dalam Bahasa Indonesia
Prefiks Sufiks
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
te- -an
F. Recoding. Ketika proses penghapusan afiks masih gagal ketika dilakukan
pencarian kamus, masih ada kemungkinan bahwa proses pen ghapusan tidak
mengubah kata yang sesuai. Contoh, kata “menanya” diubah menjadi “nanya”
tidak ditemukan setelah dilakukan pencarian kamus. Hal ini terjadi karena
berasal dari kata “tan ya”. Namun juga terdapat kasus dimana huruf pertama
lemma adalah ‘n’, misalnya “nama” dalam kata “menamai”. Tujuan dari
recoding adalah menjalankan segala macam transformasi yang memungkinkan.
Hal ini dicapai dengan merekam jalur alternatif transformasi. Ambuk aturan satu
misalnya, ada dua kemungkinan output. Pada penghapusan afiks, output yang
dipilih akan selalu yang kiri. Namun ketika proses ini dijalankan, cek algoritma
apakah ada jalur alternative yang direkam ketika menghapus afiks, dan kemudian
menggantikan transformasi saat ini dengan alternatif.
G. Backtracking Sufiks. Proses ini dikerjakan setelah pen gh apusan afiks dan
recodinggagal. Pada setiap langkah, proses penghapusan prefiks, dan
recodingdilakukan. Pertama, prefiks yang telah dihapus akan disambungkan
dengan kata, maka penghapusan prefiks dan recoding dilakukan. Jika hasil
pencarian kamus gagal, prefiks akan disambungkan kembali dan sufiks derivasi
juga akan disambungkan kembali. Jika hasilnya masih gagal, pasang kembali
prefiks, sufiks derivasi, dan kata ganti kepemilikan. Jika hasiln ya masih gagal,
langkah terakhir adalah pasang kembali partikel. Ada kasus tertentu, ketika
|
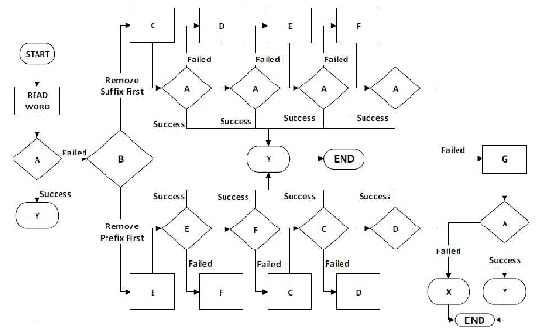 43
sufiks derivasi yang dihapus adalah “-kan”, maka ‘k’ akan dipasang terlebih
dahulu. Jika hasilnya gagal, maka ‘-an’ juga akan ditempel kembali
H. Mengembalikan Kata Asli (direpresentasikan sebagai X)
Maksud dari proses ini adalah proses lemmatization tidak berhasil menemukan
bentuk lemma.
I. Mengembalika Lemma (direpresentasikan sebagai Y)
Maksud dari proses ini adalah proses lemmatization berhasil menemukan bentuk
lemma dari kata yang diberikan.
Gambar 2.2 Flowchart Algoritma Lemmatization
(Sumber: Suhartono, Christiandy, Rolando. 2014:4)
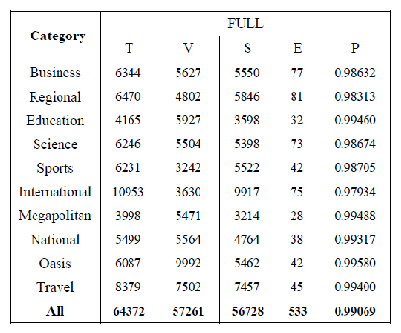
Data yang diformat berisi 57.261 kata valid dengan rata-rata 6,68 karakter per
kata, dan 7.829 kata valid yang unique. Data disimpan dalam tabel MySQL untuk
mempermudah proses pengujian. Dalam menganalisis data uji, ada beberapa batasan
supaya poses lemmatization berhasil, mempertimbangkan kesalahan, dan kasus tertentu
yang berada diluar jangkauan algoritma saat ini. Lemmatization dianggap berhasil, jik
lemma dihasilkan secara benar dari kata input. Ada beberapa kasus yang ketika lemma
yang dihasilkan tidak benar, maka akan masu k kategori error. Kasus-kasus diluar
|
|
44
jangkauan mempertimbangkan invalid dan tidak memenuhi syarat, maka keduanya tidak
dianggap gagal ataupun berhasil. B erikut adalah kasus diluar jangkauan tersebut:
1. Kata Benda Baku dan Singkatan, termasuk nama orang, nama tempat, atau
nama perusahaan (Microsoft, Bandung, PT.KAI, dll.). Alasan utama k ata benda
baku dan singk atan berada di luar jangkauan, k arena tidak terdapat dalam Kamus
Besar Bahasa Indonesia.
2. Kata Asing, maksudnya adalah kata lain di luar bahasa Indonesia. Kata Asing
juga tidak terdapat di dalam Kamus Besar Bahasa Indonesia.
3. Infiks¸ adalah afiks yang terdapat di dalam sebuah kata. Sebagai contoh, infiks ‘-
er-’ untuk “gigi” yang menghasilkan “gerigi”. Kata yang mengandung infiks
sudah termasuk ke dalam lemma. Oleh kar ena itu, prosedur pen ghapusan infiks
tidak didukung oleh algoritma ini.
4. Kata Tidak Standar dan Pengimbuhan Kata Tidak Standar, maksudnya
kata-kata yan g tidak did efinisikan dalam Kamus Besar Bahasa Indonesia, atau
kata-kata slang, dan afiks. Beberapa contoh kata-kata seperti “nggak”, “gu e”,
“bukain” dengan ‘-in’ sebagai sufiks.
Kesalahan lemmatization bisa diklasifikasikan menjadi beberapa kategori:
1. Overlemmatized: Istilah ini sama dengan overstemming. Penghapusan afiks
dilakukan terlalu banyak atau ekstensif, sehin gga lemma yang dihasilkan tidak
seperti yang diharapkan. Sebagai contoh dalam kasus overstemming ECS. Kata
“penyidikan” menjadi “sidi”, di mana kata yang benar seharusn ya menjadi
“sidik”.
2. Underlemmatized: Istilah ini sama dengan understemming. Penghapusan afiks
dilakukan terlalu sedikit, sehingga lemma yang dihasilkan tidak seperti yang
diharapkan. Pada kasus ECS, kata “mengalami” menjadi “alami” di mana kata
yang benar seharusn ya menjadi “alam”.
3. Kesalahan Aturan: Pada kasus ini, afiks yang dihapus tidak benar karena
ketidakefektifan atau kesalahan aturan. Sebagai cont
“mengatakan” mungkin
bisa menjadi “katak”, dengan men ghapus sufiks ‘-an’, dan prefiks ‘meng-
|
 45
2.2.4.2 Hasil dan Evaluasi Jurnal Lemmatization Techniq
in Bahasa: Indonesian
Language
Algoritma pada penelitian ini diimplementasikan pa
aplikasi web sederhana,
dibuat menggunakan PHP, dan untuk database menggunak
MySQL. Pen gujian
algoritma ini menggunakan 25 artikel dalam 10 kategori yan g diam
dari Kompas.com.
Hasilnya dapat dilihat pada table berikut:
Tabel 2.8 Hasil Uji untuk Kata Non-unique
(Sumber: Suhartono, Christiandy, Rolando, 2014:7)
|
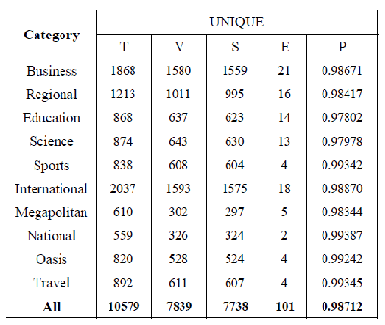 46
Tabel 2.9 Hasil Uji untuk Kata Unique
(Sumber: Suhartono, Christiandy, Rolando, 2014:8)
Dimana ‘T’ merupakan total data yang diuji, ‘V’ merupakan perhitungan uji data
valid, ‘S’ merupakan jumlah data uji lemmatization yang berhasil, ‘E’ merupakan
jumlah data uji yang gagal atau error, dan ‘P’ merupakan presentase tingkat presisi.
Dilihat pada hasil pada tabel, bisa ditarik kesimpulan bahwa algoritma
lemmatization bisa beker ja den gan baik p ada bahasa Indonesia.
2.2.4.3 Kesimpulan Jurnal Lemmatization Technique in Bahasa: Indonesian
Language
Berdasarkan hasil uji, penelitian menggunakan metode lemmatization ini
mencapai persentase presisi yang cukup tinggi yaitu kurang lebih 99%. Meskipun masih
ada beb erapa yang tidak akurat, namun hasil penelitian ini masih cukup layak untuk
diimplementasikan pada morphological analysis, grammar analyzer, dan aplikasi bahasa
lainnya dalam konteks bahasa Indonesia. Adapun beberapa saran untuk perbaikan p ada
penilitian selanjutnya:
|
|
47
1. Meningkatkan algoritma dengan beberapa kata-kata pengecualian. Tidak semua
kata dalam bahasa Indonesia bisa mengikuti aturan-aturan. Terkadang, beb erapa
pengecualian perlu dilakukan karena konteks kata dan bahasa transisi.
2. Meningkatkan algoritma supaya bisa menerima kalimat sebagai input, karena
untuk saat ini hanya bisa menerima sebuah kata sebagai input.
3. Gunakan metode lemmatization ini sebagai dasar untuk membuat algoritma
morphological analyzer, karena metode in i merupak an kunci untuk
mengaktualisasikan berbagai aplikasi yang berguna
4. Meningkatkan algoritma untuk mengatasi kata u lang, kata dengan infiks, kata
benda baku, singkatan, dan kata asing atau serapan.
|
|
48
|