|
Teori yang berkaitan dengan database
Menurut (Indrajani, 2011, p. 2),
data adalah fakta atau
observasi mentah yang biasanya mengenai fenomena atau transaksi
bisnis. Menurut tinjauan yang lebih khusus lagi,data adalah ukuran
objektif atribut (karakteristik) dari entitas seperti orang orang,
tempat,benda, atau kejadian.
Menurut(Connolly & Begg, 2010, p.70), data adalah
komponen terpenting dalam DBMS, dilihat berdasarkan sudut
pandang end user.
Menurut(Connolly & Begg, 2010, p.68), data bertindak
sebagai jembatan yang menghubungkan mesin dengan pengguna.
Basis data adalah kumpulan file yang saling terkait. Basis data
tidak hanya merupakan kumpulan file. Record pada setiap file harus
memperbolehkan hubungan-hubungan untuk menyimpan file lain
(Whitten, Bentley, & Dittman, 2007, p. 518).
Keuntungan basis data (Whitten, Bentley, & Dittman, 2007, p. 520):
1)
Memiliki kemampuan untuk berbagi dan menggunakan data
yang sama di banyak aplikasi dan sistem.
2)
Penyimpanan data dalam format yang fleksibel. Basis data
didefinisikan secara terpisah dari sistem informasi dan program-
program aplikasi yang akan menggunakan basis data.
3)
Teknologi basis data menyediakan skalabilitas superior. Basis
data dan sistem yang menggunakannya dapat ditingkatkan atau
dikembangkan untuk menemukan kebutuhan-kebutuhan
perubahan pada sebuah organisasi.
4)
Kemajuan independensi data. Hal ini mengurangi redudansi data
dan meningkatkan fleksibilitas.
5)
Sangat mendukung penggunaan jangka panjang.
|
|
Berdasarkan pengertian di atas, dapat disimpulkan basis
data adalah sekumpulan data yang terintegrasi dan dirancang
untuk memelihara informasi supaya tersedia untuk memenuhi
kebutuhan suatu organisasi.
Menurut (Connolly & Begg, 2010, p. 313),
sistem basis data
adalah komponen dasar dari sebuah informasi sistem dalam suatu
organisasi yang besar. Database System Development Lifecycle
secara langsung berhubungan erat dengan siklus dari sistem
informasi.
Berikut adalah bagan dari
Database System Development
Lifecycle :
|
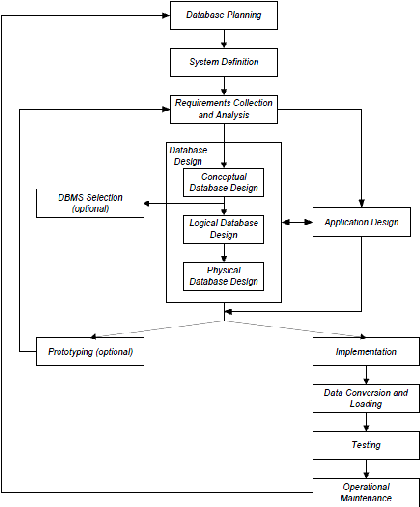 Sumber (Connolly & Begg, 2010, p. 314)
Menurut (Connolly & Begg, 2010, p. 313), database
planning
adalah adalah kegiatan manajemen yang
memungkinan tahap dari siklus hidup pengembangan sistem
basis data dapat terealisasikan secara efisien dan efektif. Ada
tiga isu utama yang berkaitan dalam merumuskan strategi
sistem informasi, yaitu:
1.
Mengidentifikasi rencana dan tujuan dari perusahan, lalu
menentukan kebutuhan sistem.
|
|
2.
Mengevaluasi sistem informasi saat ini untuk menentukan
kekuatan dan kelemahan saat ini.
3.
Penilaian dari peluang sistem informasi yang menghasilkan
keuntungan kompetitif.
Menurut (Connolly & Begg, 2010, p. 316), system
defination adalah mendeskripsikan ruang lingkup dan batas-
batas dari sistem basis data dan pandangan-pandangan
pengguna utama. Sebelum mencoba merancang sebuah
sistem basis data, penting bahwa kita terlebih dahulu
mengenali
batasan –
batasan dari sistem dan bagaimana
kaitannya dengan bagian lain dari sistem informasi dalam
suatu perusahaan yang sedang kita teliti.
Menurut (Connolly & Begg, 2010, p. 316), collection
Analysis adalah proses pengumpulan dan menganalisis
informasi tentang bagian dari perusahaan yang didukung
oleh sistem basis data, dan menggunakan informasi ini untuk
mengidentifikasi persyaratan untuk sistem yang baru.
Tahap ini melibatkan pengumpulan dan analisis informasi
tentang bagian dari perusahaan untuk dilayani oleh database.
Ada banyak teknik untk mengumpulkan informasi “fact
finding”.
Penjabaran dari data yang digunakan atau yang
dihasilkan.
1. Detail tentang bagaimana data digunakan atau dihasilkan
2. Kebutuhan tambahan tentang sistem basis data yang baru
1. Teknik Fact Finding
Menurut (Indrajani, 2011, p. 64), Fact Finding adalah
proses formal menggunakan teknik seperti wawancara dan
daftar pertanyaan untuk mengumpulkan fakta tentang
sistem,kebutuhan,dan pilihan. Setiap tahapan dalam siklus
|
|
basis data membutuhkan teknik pencarian fakta. Ada lima
teknik pencarian fakta yang digunakan seperti :
1.
Menguji dokumentasi
Uji dokumentasi bermanfaat jika kita sedang berusaha
mendalami kebutuhan basis data yang akan datang.
2.
Wawancara
Melakukan tanya jawab secara langsung ( face to face)
kepada nara sumber. Teknik ini paling sering digunakan
dan sangat berguna dibandingkan teknik-teknik pencarian
data lainnya. Terdapat 2 jenis wawancara:
a. Wawancara tidak terstruktur
Wawancara tidak terstruktur dilakukan jika tujuan wawancara
bersifat umum dan memiliki sedikit pertanyaan yang bersifat
spesifik. Pewawancara mengharapkan orang yang sedang
diwawancarai itu untuk menyediakan suatu kerangka dan arah
kepada pewawancara. Wawancara jenis ini banyak menimbulkan
kehilangan fokus dank arena alasan itulah hasil wawancara ini
tidak baik bagi analisa dan perancangan basis data.
b. Wawancara terstruktur
Pewawancara mempunyai banyak pertanyaan. Keberhasilannya
tergantung pada tanggapan orang yang sedang diwawancarai dan
apakah pewawancara dapat mengarahkan pertanyaan tambahan
secara langsung untuk memperoleh klarifikasi atau perluasan.
Ada dua jenis pertanyaan yang dapat diajukan yaitu pertanyaan
terbuka dan pertanyaan tertutup. Perbedaan nya adalah
pertanyaan terbuka memperbolehkan orang yang sedang
diwawancari untuk memberikan respon pada berbagai pertanyaan
yang sesuai dengan apa yang terdapat pada pikiran orang yang
sedang diwawancarai. Sedangkan pertanyaan tertutup membatasi
jawaban pada pilihan tertentu,singkat,dan tanggapan secara
langsung.
3.
Observasi
|
|
Observasi adalah suatu cara pengamatan langsung di lapangan. Ini
adalah salah satu teknik pencarian data yang paling efektif untuk
pemahaman suatu sistem.
4.
Riset
Riset adalah penelitian tentang aplikasi dan masalah, jurnal
computer, buku petunjuk, dan internet
seperti bulletin board
adalah sumber informasi yang baik
dan dapat menyediakan
informasi mengenai bagaimana orang lain telah memecahkan
masalah.
5.
Kuisioner
Kuisioner adalah teknik pencarian data dengan melakukan survey
melalui daftar pertanyaan.Terdapat 2 jenis pertanyaan dalam
kuisioner:
a. Free format
Free format
memberikan kebebasan responden untuk
menjawab pertanyaan.
b. Fix format
Fix format
memerlukan tanggapan spesifik dari individu,
dengan apa pun pertanyaan, responden harus memilih jawaban
yang tersedia.
Setelah informasi didapatkan, Menurut (Connolly & Begg, 2010,
p. 318) ada beberapa
pendekatan utama untuk mengelola
persyaratan sistem basis data dengan beberapa cara pandang
pengguna, yaitu:
1. Centralized Approach, kebutuhan untuk tiap
pandangan pengguna disatukan menjadi satu set
kebutuhan untuk sistem basis data baru. Sebuah model
data yang mewakili semua pandangan pengguna yang
dibuat selama tahap desain database.
|
 2. View Integration Approach, kebutuhan untuk tiap
pandangan pengguna tetap sebagai daftar terpisah. Model
data merepresentasikan setiap tampilan pengguna yang
diciptakan dan kemudian digabungkan kemudian selama
mendekati tahap desain database.
2. Flowchart
Menurut
(Robertson, 2007, p. 264),
flowchart
merupakan logika program dengan serangkaian simbol
geometries standar dan menghubungkan garis.
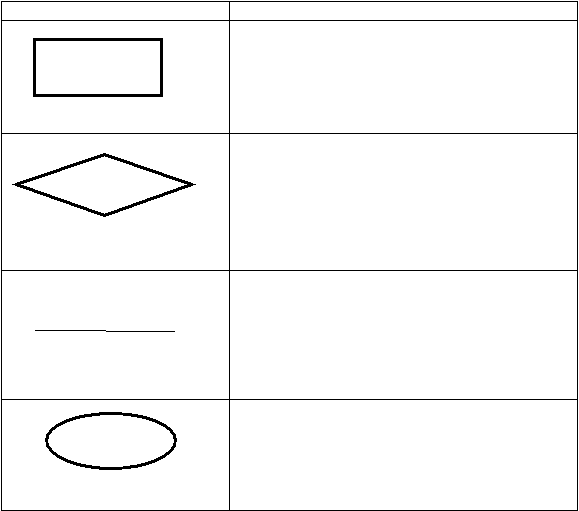
Terdapat enam
simbol flowchart yaitu :
Simbol
Keterangan
Terminal symbol
Simbol terminal menunjukkan untuk memulai atau
menghentikan titik. Setiap flowchart harus dimulai
dan diakhiri dengan simbol terminal.
Input/Output symbol
Simbol input atau output merupakan sebuah proses
dalam algoritma.
Process symbol
Simbol proses merupakan proses tunggal dalam
algoritma seperti menentukan nilai atau melakukan
perhitungan. Aliran kontrol
sekuensial simbol
proses yang telah ditetapkan merupakan modul
dalam algoritma yang merupakan proses standar
yang memiliki alur sendiri
Predefined process symbol
Merupakan sebuah logika yang melibatkan
perbandingan dua nilai, jalur alternatif di ikuti,
tergantung apakah simbol keputusan itu benar atau
|
 Menurut (Connolly & Begg, 2010, p. 320), database
design adalah proses membuat sebuah desain untuk sebuah
sistem basis data yang akan mendukung operasional
dan
tujuan dari suatu perusahaan.
Menurut (Indrajani, 2011, p. 59),
ada 2 pendekatan
dalam mendesain sistem basis data, yaitu:
1. Pendekatan Top-down, diawali dengan membuat data
model. Dapat diilustrasikan dengan membuat entity-
relationship(ER) model dengan high level, kemudian
identifikasi entity,
dan relationship antar entity
organisasi.
Pendekatan ini cocok untuk basis data yang kompleks.
2. Pendekatan bottom-up, dimulai dari level dasar attribute,
menganalisa hubungan antar atribute, mengelompokannya
dalam suatu relasi yang menggambarkan tipe entity dan relasi
antar entity. Pendekatan ini cocok untuk basis data dengan
atribute yang sedikit.
3. Pendekatan
Inside-Out,
mirip seperti perbedaan bottom-
up, hanya saja pada tahap awal mengidentifikasi major entity
salah
Decision symbol
Untuk menunjukkan sebuah langka dalam
pengambilan keputusan.
Flowlines
Menghubungkan berbagai simbol dalam flowchart
dan panah control ke bawah atau kiri kekanan
|
|
lalu mengurainya menjadi entity-entity relasi dan atribute-
atribute yang berhubungan dengan major enitity.
4. Pendektan mixed, gabungan antara pendekatan bottom-up
dan pendekatan Top-down.
Menurut (Connolly& Begg, 2010, p.322),
perancangan sistem basis data dibagi menjadi 3 bagian utama
yaitu conceptual database design, logical database design,
dan physical database design.
1). Metodologi database design
a). Conceptual Database Design
Menurut (Connolly & Begg, 2010, p. 467), conceptual
database design adalah proses membangun suatu model data
yang digunakan didalam suatu perusahaan, yang bersifat
independen dari semua pertimbangan fisikal.
1. Membangun model data konseptual
Tujuan: membangun sebuah model data konseptual dari
kebutuhan yang ada pada perusahaan conceptual data model
terdiri dari :
-
Entity types
-
Relationship types
-
Attributes and attribute domains
-
Primary keys and akternate keys
-
Integrity constraints
Langkah-langkah yang terlibat dalam step 1 ini adalah:
Langkah 1. Mengidentifikasi tipe entitas
Tujuan dari langkah ini untuk mengindentifikasikan tipe
entitas yang dibutuhkan oleh user.
Langkah pertama yang
dilakukan adalah mendefinisikan objek atau entitas yang user
inginkan. Salah satu metode untuk mengidentifikasi entitas
adalah untuk menguji kebutuhan spesifikasi user.Dari spesifikasi
ini, kita mengidentifikasi kata benda atau frase kata benda yang
|
 disebutkan. Seteah tipe entitas di ketahui, lakukan pemberian
nama yang jelas kepada user.
Catat nama dan deskripsi dari
entitas dalam kamus data. Jika entitas dikenal dengan nama yang
berbeda,
nama
tersebut
menunjuk
kepada
sinonim atau
alias
yang dicatat dalam kamus data.
Langkah 2. Mengidentifikasi tipe relationship
Tujuan dari langkah ini untuk mengidentifikasi hubungan
penting antara tipe entitas. Di sini menggunakan ER diagram
untuk mewakili entitas dan bagaimana mereka berhubungan satu
sama lain dengan mudah.
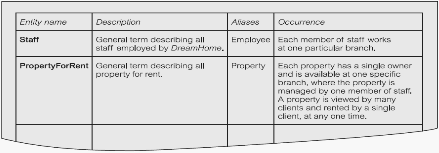
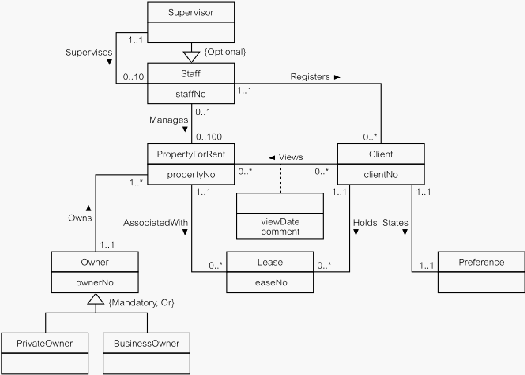
mendeskripsikan entity untuk staff user view dreamhome
Sumber (Connolly & Begg, 2010, p. 472)
Relasi
yang paling umum adalah
relasi binary.
Yang
artinya
relasi antar entitas yang persis antara dua entitas
saja.
Bagaimanapun,
relasi kompleks
yang
melibatkan
lebih
dari
dua
entitas dan relasi rekursif yang hanya melibatkan satu
entitas harus diperhatikan.
Langkah-langkah dalam
mengidentifikasi
tipe
relasi :
a. Menggunakan Entity-Relationship (ER) Diagram
Sering terjadi bahwa lebih mudah dan lebih cepat
dimengerti suatu perancangan apabila basis data
divisualisasikan daripada menguraikan deskripsi tekstual
|
 panjang kepada user.
Kami menggunakan Entity-
Relationship
(ER) diagram untuk mewakili entitas dan
bagaimana mereka berhubungan satu sama lain dengan
lebih mudah. Sepanjang tahap perancangan sistem basis
data, kami merekomendasikan bahwa diagram ER harus
digunakan bila diperlukan untuk membantu membangun
sebuah gambaran dari bagian dari perusahaan yang kita
modelkan.
Simbol
Keterangan
Entitas
Entitas
adalah
suatu
objek
yang
dapat
diidentifikasi dalam lingkungan pemakai.
Relasi
Relasi
menunjukkan
adanya
hubungan
di
antara
sejumlah
entitas
yang berbeda. Simbol
yang digunakan adalah :
Garis
Garis
sebagai
penghubung
antara
relasi
dengan
entitas,
relasi
dan
entitas dengan atribut.
Atribut
Atribut
berfungsi
mendeskripsikan
karakter
entitas
(atribut
yang
berfungsi sebagai key diberi
garis bawah).
b. Menentukan multiplicity constraint dari tipe relasi
Setelah mengidentifikasi selasi model selanjutnya
kita multplicity tiap relasi.
Multiplicity
constraints
digunakan
untuk
mengecek
dan
memelihara kualitas
data.
|
 c. Mengecek Fan Traps dan Chasm Traps
Setelah
relasi
yang
dibutuhkan
antar entitas
didefinisikan,
maka
langkah berikutnya
adalah
mengecek
fan
traps
dan
chasm traps.
Definisi dari fan traps adalah
suatu model yang merepresentasikan suatu relasi antar
entitas. Tetapi alur
relasinya
memperlihatkan
ambiguitas.
Chasm
traps
adalah
suatu
model dimana terdapat
hubungan antar entitas yang satu dengan yang lain, tetapi
tidak ada relasi antar kedua entitas yang utama.
d. Mendokumentasikan tipe relasi
Setelah tipe relasi diidentifikasi, langkah berikutnya
adalah
memberikan nama
yang
mempunyai
makna
dan
jelas
kepada user.
Selain
itu,
juga
me-
record deskripsi
relasi dan multiplicity constraints pada kamus data.
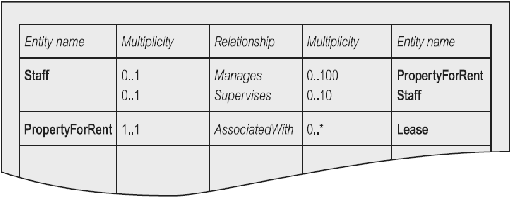
mendeskripsikan relationship untuk staf user view
dreamhome
Sumber (Connolly & Begg, 2010, p. 475)
Langkah 3. Mengidentifikasi atribut pada tiap entitas
Tujuan dalam langkah ini adalah untuk mengidentifikasi
dan mengasosiasikan atribut dengan entitas dan tipe relationship
yang sesuai. Atribut dibagi 3 yaitu :
a.
Simple atau Composite Atribut
|
|
adalah suatu hal yang penting untuk mengetahui sebuah
atribut itu adalah simple atau composite. composite attribute
adalah atribut yang terbuat dari simple attribute. Contoh,
atribut alamat bisa saja dibuat simple dan menyimpan beberapa
detail dari alamat sebagai suatu nilai.
Contohnya, ‘115 Dumbarton Road, Glasgow, G11 6YG’.
Bagaimanapun
juga,
atribut
alamat
dapat pula
merepresentasikan sebuah composite
atribut,
yang
dibuat
dari
simple
atribut
yang
terdiri
dari
beberapa detail
alamat
yang
mempunyai
nilai
terpisah
pada
atribut
street
(‘115
Dumbarton
Road’),
city (‘Glasgow’),
dan
postcode
(‘G11
6YG’).
Atribut alamat
dapat
dijadikan
simple atribut
atau
composite atribut tergantung dengan kebutuhan user.
b.
Single atau Multi-valued Atribut
Suatu
atribut dapat menjadi pula single / multi
attribute atau satu atau lebih nilai, selain dapat
menjadi
single
atau composite, dapat pula mempunyai satu atau lebih nilai,
contohnya yaitu atribut nomor telepon. Seseorang bisa saja
mempunyai nomor telepon lebih dari satu, keadaan seperti itu
dapat
disebut multi-valued
atribut.
Tetapi
apabila
atribut
tertentu hanya mempunyai satu nilai maka disebut
single
atribut.
c.
Derived Atribut
Atribut
yang
nilainya
tergantung dengan
nilai atribut
yang
lain disebut juga sebagai derived attributes.
Contoh,
umur
seorang staff,
banyaknya
properti
yang dikelola
oleh
seorang
staff.
Langkah 4. Menentukan domain atribut
Tujuan dari langkah ini adalah untuk menentukan domain
untuk atribut di model data konseptual.
Contoh :
Domain
atribut
dari
nomor
staff
(staffNo)
terdiri
dari
lima
karakter string dimana dua karakter awal berupa huruf,
|
|
sedangkan tiga karakter berikutnya berupa angka yang berkisar
dari 1-999.
Langkah
5.
Mengidentifikasi
candidate
key, primary
dan
alternative key
tiap atribut
Untuk mengidentifikasi candidate
key(s) untuk setiap entity
types dan jika ada lebih dari 1 candidate key, maka harus memilih
satu sebagai primary key dan yang lain sebagai alternate key.
Memilih primary key dari candidate key :
-
Candidate key dengan atribut yang sedikit
-
Candidate key yang paling memungkinkan memiliki nilai yang
berubah – ubah
-
Candidate key dengan karakter yang paling sedikit
-
Candidate key yang mudah digunakan dari segi pandang user
Langkah 6. Mempertimbangkan penggunaan konsep
pemodelan enhance (langkah optional)
Tujuan dalam langkah ini adalah untuk
mempertimbangkan peningkatan konsep modeling, seperti
pecialization /generalization, aggregation dan composition. Jika
kita memilih pendekatan specialization, kita mencoba untuk
menonjolkan perbedaan antara entitas dengan mendefinisikan satu
atau lebih subclass
dari superclass
entitas. Jika kita memilih
pendekatan generalization, kita berusaha untuk mengidentifikasi
fitur-fitur umum. Entitas untuk menentukan entitas superclass
generalisasi. Kita dapat menggunakan aggregation
untuk
mewakili sebuah 'has-a'
atau 'is-part-of'
hubungan antara tipe
entitas, di mana satu mewakili 'seluruh' dan
satu lagi mewakili
'bagian'. Kita dapat menggunakan composition (jenis khusus dari
agregasi) untuk mewakili hubungan antara jenis entitas di mana
ada kepemilikan yang kuat dan kebetulan seumur hidup antara
'seluruh' dan 'bagian'.
Langkah 7. Mengecek model dari redundansi
|
|
Tahap ini bertujuan untuk memeriksa adanya redundansi
yang ada di dalam model.
Ada 3 kegiatan pada tahap ini :
-
Memeriksa kembali one-to-one relantionship
contoh: client dan renter
-
Menghilangkan rendundant relantionship
Suatu relasi berlebihan jika informasi yang sama dapat diperoleh
melalui hubungan lainnya.
-
pertimbangkan time dimension
Langkah
8.
Memvalidasi
model
konseptual
lokal
terhadap
transaksi user.
Langkah ini bertujuan untuk memastikan bahwa model data
konseptual mendukung transaksi yang diperlukan.
Terdapat dua pendekatan yang mungkin untuk memastikan bahwa
model konseptual data telah mendukung transaksi yang
diperlukan,yaitu:
a.
Mendeskripsikan transaksi.
b.
Menggunakan jalur transaksi.
Langkah
9.
Me-review
model
data
konseptual
terhadap
kebutuhan user.
|
 Sumber (Connolly & Begg, 2010, p. 474)
b. Logical Database Design
Menurut (Connolly & Begg, 2010, p. 467), Logical
Database Design adalah proses membangun model data yang
digunakan didalam suatu perusahaan berdasarkan model data
tertentu, bersifat independen terhadap DBMS tertentu dan
segala pertimbangan fisik lainnya.
2. Membangun model data logical
Tujuan:untuk menerjemahkan data model konseptual
kedalam data model logikal lalu menvalidasi model ini untuk
mengecek apakah secara srtuktur benar dan dapat mendukung
transaksi yang dibutuhkan.
Langkah-langkah yang terlibat dalam step ini adalah:
a. Turunkan hubungan untuk logikal data model
|
 Tujuan dari langkah ini untuk membuat hubungan
model data logikal untuk mewakili entitas, hubungan dan
atribut yang telah diidentifikasi. Deskripsi dari relasi
yang
mungkin terjadi penurunan
/ derived dalam konseptual data
model :
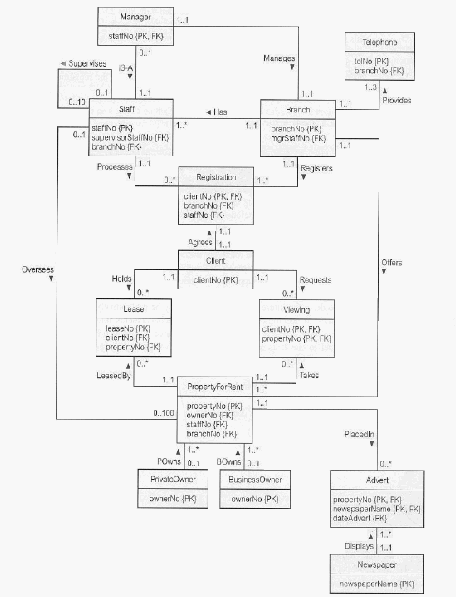
1.Tipe entitas kuat (Strong Entity Type)
2.Tipe entitas lemah (Weak Entity Type )
3.Tipe relasi binary one-to-many (1:*)
4.Tipe relasi binary one-to-one (1:1)
5.Tipe relasi rekursif one-to-one (1:1)
6.Tipe relasi superclass atau subclass
7.Tipe relasi binary many-to-many
8.Tipe relasi kompleks
9.Atribut multi-valued
dan relasi ke relasi
Sumber (Connolly & Begg, 2010, p. 500)
|
|
b. Validasi relasi menggunakan normalisasi
Tujuan dari langkah ini adalah untuk memvalidasi relasi
dalam data model logical menggunakan normalisasi.
c. Validasi relasi menggunakan transaksi user
Langkah ini bertujuan untuk memastikan relasi dalam
data model logical
mendukung kebutuhan transaksi. Pada
langkah ini, dilakukan pengecekan relasi yang telah dibuat pada
langkah sebelumnya agar dapat mendukung
transaksi
ini, dan
memastikan
bahwa
tidak
ada error
dalam
relasi yang
telah
dibuat.
d. Memeriksa kendala integritas:
Tujuan dalam langkah ini adalah untuk memeriksa apakah
integritas constrain terwakili dalam data model logical.
Tipe-tipe integritas constrain :
a. required data : harus berisi nilai, tidak boleh null.
b. attribute domain constrains
: setiap atribut harus memiliki
domain.
c. multiplicity
: constrain yang ditempatkan pada relasi antara
data dalam database.
d. entity integrity : primary key dari sebuah entitas tidak boleh
null.
e. referencial integrity : jika foreign key berisi nilai, maka nilai
tersebut haru merujuk pada suatu tupel dalam relasi parent.
f. general constrains : mengatur constrain pemerintahan dalam
transaksi “dunia nyata” yang di representasikan pada
updates.
e. Melakukan review logical data model dengan user
Langkah ini
bertujuan
untuk meninjau model data
logikal dengan pengguna untuk memastikan bahwa mereka
mempertimbangkan model menjadi true representation
dari
persyaratan data perusahaan. Apabila user merasa tidak puas
|
|
dengan model tersebut maka dilakukan pengulangan kembali
langkah-langkah sebelumnya jika diperlukan.
f. Menggabungkan model data logikal kedalam data global
(langkah optional)
Tujuan dalam langkah ini adalah untuk menggabungkan
data model logikal lokal ke dalam suatu data model logikal
global yang merepresentasikan semua tampilan pengguna
database. Langkah
ini hanya diperlukan untuk desain basis
data dengan pandangan beberapa pengguna yang dikelola
dengan menggunakan pendekatan integrasi tampilan.
Untuk memfasilitasi gambaran proses penggabungan,
digunakan model
data
logikal
lokal
dan
model
data
logikal
global. Model data logikal lokal
merepresentasikan
satu
atau
lebih
tetapi
tidak
semua
sudut
pandang user terhadap basis
data. Sedangkan model data logikal global merepresentasikan
semua sudut pandang user terhadap basis data. Dalam langkah
ini, dilakukan penggabungan dua atau lebih model data logikal
lokal kedalam satu
model
data
logikal
global.
Aktivitas
penggabungan tersebut meliputi :
1. Penggabungan
model
data
logikal
lokal
kedalam
model global
Tujuan dari
langkah
ini adalah untuk menggabungkan model
data logikal
lokal
kedalam satu
model
data logikal
global.
Beberapa tugas di pendekatan ini :
a. Review nama dan isi dari entitas/relasi dan candidate keys
b. Review nama dan isi dari relasi/foreign keys
c. Menggabungkan entitas/relasi dari model data lokal
d.Mencakupkan
(tanpa menggabungkan) keunikan
entitas/relasi pada setiap model data lokal
e. Menggabungkan relasi/foreign keys dari model data lokal
f.Mencakupkan (tanpa menggabungkan) keunikan
relasi/foreign keys pada setiap model data lokal
|
|
g. Mengecek entitas atau relasi dan relasi atau foreign
key yang hilang
Mengecek foreign keys
Mengecek intergrity constraints
Menggambar ER/relasi global diagram
Meng-update dokumentasi
2. Memvalidasi model data logikal global
Tujuan dalam langkah ini adalah untuk
menvalidasi
relasi yang dibuat dari model data logikal global
menggunakan teknik dari normalisasi dan untuk
memastikan bahwa relasi
yang dibuat mendukung
transaksi yang dibutuhkan.
3. Mereview model data logikal global dengan user
Tujuan dalam langkah ini adalah untuk untuk
mereview model data logikal global dengan user untuk
memastikan model data yang dibuat merupakan
representasi yang benar terhadap kebutuhan data
perusahaan.
g. Mengecek untuk pengembangan di masa depan
Tujuan dalam langkah ini adalah untuk menentukan
apakah ada kemungkinan perubahan yang signifikan di masa
akan datang dan untuk menilai apakah model data logikal
dapat mengakomodasikan perubahan ini.
|
 Sumber (Connolly & Begg, 2010, p. 516)
c) Physical Database Design
Menurut (Connolly & Begg, 2010, p. 467), Physical Database
Design adalah proses untuk menghasilkan deskripsi implemetasi dari
database
pada penyimpanan sekunder (secondary storange) yang
|
|
menggambarkan hubungan dasar desain data organisasi, dan indeks
yang digunakan untuk mendapatkan akses yang cepat terhadap data
dan setiap integrity constraints terkait dan langkah langkah keamanan
yang ada.
Langkah 3. Menterjemahkan model data logikal untuk
DBMS
yang dituju
Tujuan : untuk menghasilkan skema basis data rasional dari
model data logikal yang dapat di implementasikan dalam target DBMS.
1. Mendesain relasi dasar
Tujuan dari langkah ini adalah untuk memutuskan
bagaimana merepresentasikan relasi dasar yang diidentifikasi dalam
model data
logikal pada DBMS yang dituju. Untuk memulai proses
desain fisikal, pertama-tama dengan menyatukan dan
mengasimilasikan informasi mengenai relasi yang dirancang selama
perancangan basis data logikal. Informasi yang diperlukan dapat
berasal dari kamus data dan definisi relasi yang didefinisikan
menggunakan Database Design Language (DDL). Untuk tiap relasi
yang diidentifikasi di logikal data model, dapat didefinisikan berisi :
Nama dari relasi
Sebuah daftar dari simple atribut didalam tanda kurung
Primary key (PK), alternate key (AK), dan foreign key (FK)
Batasan integritas referensial untuk
setiap
foreign key yang
diidentifikasi
Dari kamus data, kita juga dapat mengetahui setiap atribut :
Domain atribut
tersebut
terdiri
dari
tipe
data, panjang,
dan
berbagai constraint pada domain tersebut
Suatu optional nilai default untuk atribut
Apakah atribut dapat diisi dengan nilai null
Apakah atribut dapat
diturunkan dan jika demikian bagaimana
perhitungannya.
|
 Sumber (Connolly & Begg, 2010, p. 526)
2. Mendesain representasi dari data turunan (derived data)
Tujuan dari langkah ini adalah untuk menentukan bagaimana
untuk merepresentasikan apapun derived data sekarang dalam model
data logikal di target DBMS.
Atribut
yang
nilainya didapatkan dengan
mengevaluasi
atribut
lain
dikenal sebagai atribut turunan(derived attribute)
atau atribut
kalkulasi(calculated attribute).
Contoh:
Jumlah dari staff yang bekerja pada suatu cabang
Total gaji bulanan untuk semua staff
Jumlah dari properti yang di urus oleh anggota staff
|
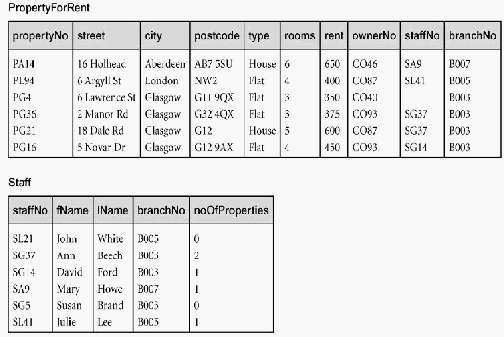 turunan no OfProperties
Sumber (Connolly & Begg, 2010, p. 527)
3. Mendesain general constrant
Tujuan dalam langkah ini adalah untuk membuat general
constrains pada target DBMS. Meng-update suatu relasi yang mungkin
dibatasi oleh batasan integritas yang mengatur transaksi ‘real world’
yang direpresentasikan oleh peng-update-an tersebut. Perancangan
batasan tersebut
sekali
lagi
tergantung
pada DBMS
yang
dipilih.
Beberapa
sistem menyediakan
beberapa fasilitas dibandingkan yang
lainnya untuk mendefinisikan
kendala
umum.
Seperti langkah
sebelumnya, jika sistem tersebut mempunyai aturan sesuai aturan
standar SQL, beberapa batasan dapat dengan mudah diterapkan.
4. Mendesain organisasi file dan indeks
Tujuan dalam langkah ini adalah untuk menentukan organisasi file
yang optimal untuk menyimpan relasi dasar dan indeks yang
|
|
dibutuhkan untuk mencapai kinerja yang yang dapat diterima, yang
dimana relasi dan tuples akan diadakan di secondary storange.
Langkah 4.
4.1 Analisa transaksi
Tujuan dalam langkah ini adalah untuk mengerti fungsi
dari transaksi yang akan berjalan di database dan untuk
menganalis transaksi yang penting.
4.2 Memilih organisasi file
Tujuan dalam langkah ini adalah untuk menentukan
organisasi file yang efisien untuk setiap relasi dasar. Tujuan utama
dari langkah ini adalah untuk memilih organisasi file yang optimal
untuk tiap relasi, jika target dari DBMS memperbolehkan. di
banyak kasus, sebuah relasi dari DBMS bisa memberi sedikit atau
tidak sama sekali pilihan untuk memilih organisasi file walaupun
beberapa memliki indeks yang spesifik.
Jenis dari organisasi file yang ada adalah :
a.
Heap
b.
Hash
c.
Indexed Sequential Office Access Method (ISAM).
d.
B*-three
e.
Clusters.
Jika DBMS yang dituju tidak memperbolehkan adanya pemilihan
organisasi file, maka langkah ini dapat dihilangkan.
4.3 Memilih indeks
Tujuan dalam langkah ini adalah untuk menentukan index
yang di masukkan untuk meningkatkan kinerja sistem. Pendekatan
untuk memilih organisasi file yang tepat untuk tiap relasi adalah
dengan cara tetap menjaga agar tuples
tidak berurutan dan
membuat terlalu banyak secondary indexes.
Pendekatan lainnya
yaitu untuk membuat tuples di relasi terurut dengan spesifikasi
|
|
primary atau cluestering index. Dikasus ini,
pemilihan atribut
untuk terurut atau cluestering di tuples sebagai berikut:
Suatu
atribut
yang
digunakan
paling
sering
untuk
operasi
penggabungan(join), yang akan membuat operasi
penggabungan itu lebih efisien
Suatu
atribut
yang
digunakan
paling
sering
untuk
mengakses
suatu
tuple
didalam
relasi yang ada.Apabila
pengurutan atribut yang dipilih adalah kunci
dari relasi,
indeks
tersebut
akan
menjadi
primary
index.
Sedangkan
jika
pengurutan atribut
yang
dipilih
bukan
merupakan
kunci dari
relasi,
indeks tersebut akan menjadi clustering
index. Setiap
relasi hanya
dapat
mempunyai primary
index atau clustering index
4.4 Estimasi Kapasitas penyimpanan
Tujuan dalam langkah ini adalah untuk mengestimasi
jumlah dari ruang disk yang diperlukan oleh sistem basis data.
Mungkin diperlukan bahwa implementasi physical database bisa
di atur dengan konfigurasi hardware yang ada saat ini. Walaupun
ini bukan suatu kasusnya perancang
tetap harus mengestimasi
jumlah dari ruang disk yang diperlukan untuk menyimpan basis
data, jika ternyata hardware perlu untuk
didapatkan. Seperti
sebelumnya, estimasi pemakaian disk juga tergantung pada DBMS
yang dituju dan hardware yang digunakan untuk mendukung basis
data.
Secara
umum
estimasi
tersebut dilakukan berdasarkan
ukuran tiap tuple dan jumlah tuple dalam relasi.
Langkah 5 Merancang Tampilan untuk User
Tujuan : untuk mendesain tampilan user yang diidentifikasi selama
tahap pengumpulan kebutuhan dan alasisis tahap dari pengembangan sistem
basis data.
|
|
Langkah 6 : Merancang Mekanisme Keamanan
Tujuan: untuk mendesain mekanisme keamanan untuk sistem basis data
yang telah dispesifikasikan oleh user selama tahap analisis dan pengumpulan
kebutuhan dari pengembangan sistem basis data. Selama tahap analisis dan
kebutuhan dari pengembangan sistem basis data, security secara spesifik
harus didokumentasikan didalam spesifikasi dari kebutuhan sistem. Tujuan
utama dari tahap ini adalah untuk memutuskan bagaimana kebutuhan
security ini akan direalisasikan. Beberapa sistem menawarkan fasilitas
keamanan yang berbeda. Dan sekali lagi ditegaskan bahwa perancang basis
data harus hati-hati terhadap fasilitas yang ditawarkan oleh DBMS yang
dituju.
2). Normalisasi
Menurut (Connolly & Begg, 2010, p. 416), normalisasi adalah
teknik untuk memproduksi satu set hubungan dengan sifat yang
diinginkan untuk kebutuhan data suatu perusahaan.
a) Proses Normalisasi
Menurut (Connolly & Begg, 2010, p. 428), normalisasi
adalah teknik formal untuk menganalisis hubungan berdasarkan
primary key (atau calon kunci) dan ketergantungan fungsional (Codd,
1972b). Teknik ini melibatkan serangkaian aturan yang dapat
digunakan untuk menguji hubungan individu sehingga database dapat
dinormalisasi untuk tingkat apapun. Ketika persyaratan tidak terpenuhi,
hubungan melanggar persyaratan harus didekomposisi menjadi relasi
yang secara individual memenuhi persyaratan normalisasi. Berikut ini
tahap-tahap dalam normalisasi:
1. Unnormalized form (UNF)
Merupakan suatu tabel yang berisi satu atau lebih kelompok
yang berulang
2. First normal form (1NF)
|
|
Merupakan suatu relasi di mana terdapat persimpangan setiap
baris dan kolom terdapat satu nilai
3. Second normal form (2NF)
Merupakan relasi yang berada dalam bentuk normal pertama dan
setiap atribut kunci non primary sepenuhnya fungsional tergantung
pada primary key
4. Third normal form (3NF)
Merupakan hubungan yang di dalam bentuk normal pertama
dan kedua dan di mana tidak ada atribut kunci non primer transitif
tergantung pada primary key
3). Entity Relationship Modeling
Menurut (Connolly & Begg, 2010, p. 371), ER-modeling adalah
pendekatan top-down untuk mendesain
suatu sistem basis data yang
diawali dengan mengidentifikasi entitas data penting yang disebut
entitas dan hubungan antara data yang harus direpresentasikan dalam
model.
Beberapa konsep dasar dalam model E-R yaitu :
1. Entity type
Entity type adalah kumpulan objek-objek dengan sifat (property)
yang sama, yang diindentifikasi oleh enterprise mempunyai eksistensi
yang independen.
Konsep dasar dari ER Modeling adalah tipe entitas dimana
merepresentasikan sebuah
grup dari “object” di dunia nyata dengan
propertis yang sama. Sebuah
tipe entitas memiliki keberadaan yang
bebas dan bisa menjadi object yang “nyata” .
Sedangkan entity occurance adalah sebuah objek dari suatu tipe
entitas yang dapat diidentifikasikan secara unik. Setiap objek dapat
diidentifikasi secara unik dari suatu tipe entitas dan dengan mudah
disebut entity occurance. Keberadaan objek-objeknya secara fisik
|
 atau nyata (physical existance) seperti entitas pegawai, rumah, dan
pelanggan, atau secara konseptual atau abstrak (conceptual
existance)
seperti
entitas
penjualan,
pembelian,
dan peminjaman.
Setiap tipe entitas dilambangkan dengan
sebuah
persegi
panjang
yang diberi
nama dari
entitas
tersebut.
Nama tipe entitas biasanya
adalah
kata
benda tunggal.
Huruf
pertama
dari
setiap
kata
pada
nama tipe entitas ditulis dengan
huruf.
Sumber (Connolly & Begg, 2010, p. 373)
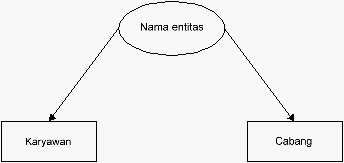
2. Relationship Type
Relationship Type
merupakan kumpulan keterhubungan
yang mempunyai arti antara tipe entitas yang ada. Sedangkan
Relationship occurrence adalah merupakan keterhubungan yang
diidentifikasikan secara unik yang meliputi keberadaan tiap tipe
entitas yang berpartisipasi.
Derajat relationship
Merupakan jumlah entitas yang
berpartisipasi dalam suatu
relationship terdiri atas:
|
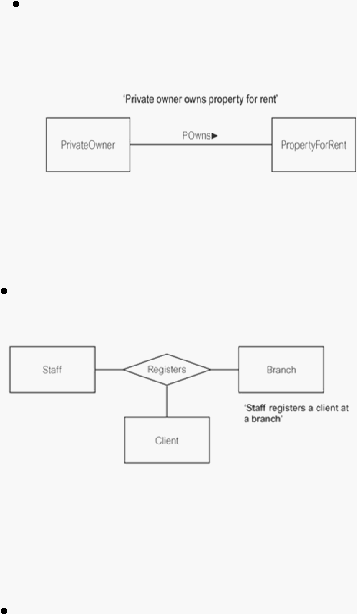 Binary Relationship
Merupakan keterhubungan antar dua tipe entitas.
Sumber (Connolly & Begg, 2010, p. 376)
Ternaty Relationship
Merupakan keterhubungan antar tiga tipe entitas.
Sumber (Connolly & Begg, 2010, p. 377)
Quaternaty Relationship
Merupakan keterhubungan antar empat tipe entitas.
|
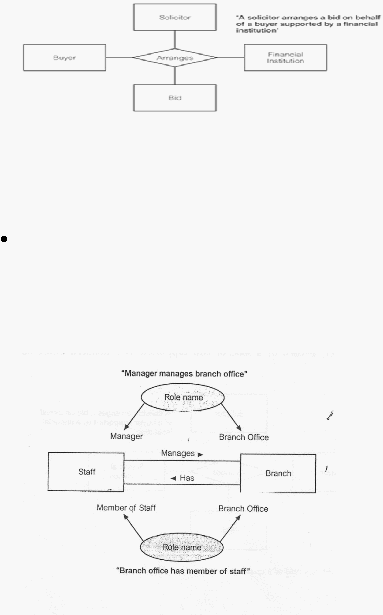 Sumber (Connolly & Begg, 2010, p. 377)
Reqursive Relationship
Merupakan keterhubungan antar satu tipe entitas, dimana tipe
entitas tersebut berpartisipasi lebih dari satu kali dengan peran
yang berbeda.
Sumber (Connolly & Begg, 2010, p. 378)
3. Attributes
Atribut merupakan sifat-sifat(property) sebuah entity
atau
tipe relationship. Adapun tipe-tipe atribut terdiri atas :
Adapun tipe-tipe atribute terdiri atas:
|
|
1. Simple Attribute
, yang terdiri atas satu komponen tunggal
dengan keberadaan yang independen dan tidak dapat dibagi
menjadi bagian yang lebih kecil lagi. Contoh: nim ,
nomer_ktp , nomer_sim.
2. Composite Attribute, yang terdiri atas beberapa komponen,
dimana masing-masing komponen memiliki keberadaan yang
independen. Misalnya atribut address yang terdiri atas street,
city, postcode.
3. Single-valued Attribute, yang mempunyai nilai tunggal untuk
setiap kejadian. Misalnya entitas branch memiliki satu nilai
untuk atribut branchNo pada setiap kejadian.
4. Multi-valued attribute, yang mempunyai beberapa nilai untuk
setiap kejadian. Misalnya entitas branch memiliki beberapa
nilai atribut telpNo pada setiap kejadian.
5. Derived Attribute, yang memiliki nilai yang dihasilkan dari satu
atau beberapa atribut lainnya dan tidak harus berasal dari datu
entitas.
Keys terbagi dari tiga jenis yaitu:
Candidate key, yaitu jumlah minimal atribut-atribut yang dapat
mengindentifikasikan setiap kejadian atau record secara unik.
Primary key, yaitu candidate key
yang dipilih untuk
mengindentifikasikan setiap kejadian atau record
suatu entitas
secara unik.
Composite key, yaitu candidate key yang terdiri atas dua atau lebih
atribut.
|
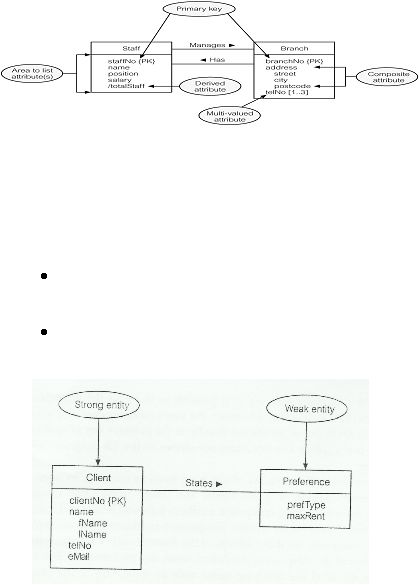 Sumber (Connolly & Begg, 2010, p. 382)
4. Strong and Weak Entity Type
strong entity type adalah entitas yang keberadaannya tidak
tergantung pada entitas lain.Disebut juga client.
week entity type adalah entitas yang keberadaannya
bergantung pada entitas lain. Disebut juga preference.
Sumber (Connolly & Begg, 2010, p. 384)
5. Structural Constraint
Yaitu jumlah atau range dari kejadian yang mungkin terjadi
pada suatu entitas yang terhubung ke satu kejadian dari entitas lain
yang berhubungan melalui suatu relationship.
|
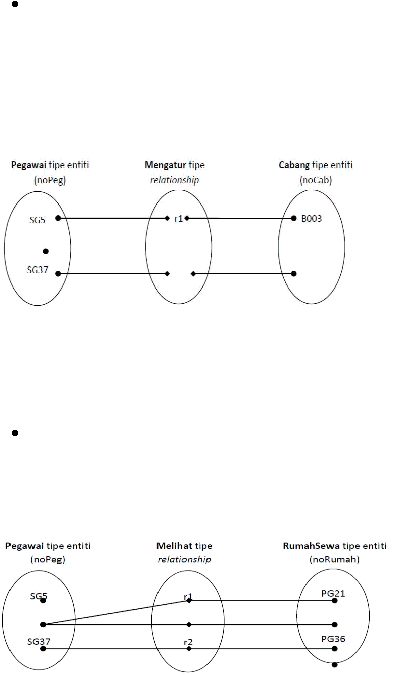 Hubungan yang paling umum adalah binary relationship.
Yang
terdiri atas :
One to One (1:1) Relationships
Gambar
di
bawah
ini
menggambarkan
relationship
one-to-one
antara entitas Staff dan entitas Branch, dimana satu orang staff
hanya
mengontrol satu cabang dan satu cabang hanya dikontrol
oleh satu orang staff.
Sumber (Connolly & Begg, 2010, p. 386)
One to Many (1:*) Relationships
Gambar berikut ini menggambarkan anggota staff
dapat
mengawasi nol atau
lebih properti untuk disewakan dan properti
untuk disewakan diawasi oleh nol atau satu anggota staff.
Relationships
Sumber (Connolly & Begg, 2010, p. 387)
|
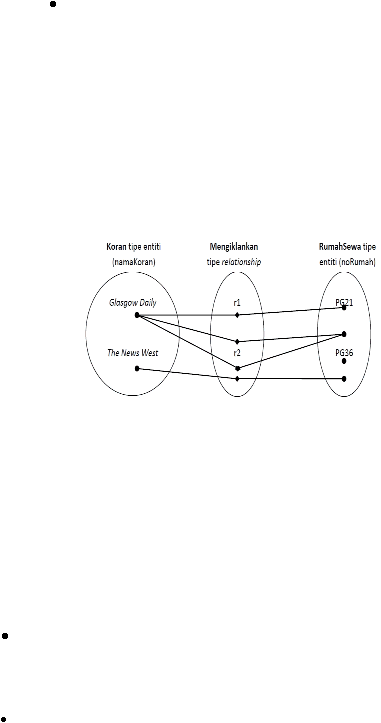 Many to many (*:*) Relationships
Gambar berikut menggambarkan satu koran mengiklankan satu
atau lebih properti untuk disewakan
dan satu properti untuk
disewakan diiklankan di nol atau lebih surat kabar. Oleh karena itu,
untuk surat kabar ada banyak properti untuk disewakan, dan untuk
setiap properti untuk disewakan berpartisipasi dalam hubungan ini
ada banyak surat kabar.
Relationships
Sumber (Connolly & Begg, 2010, p. 388)
4). Enhanced Entity- Relationship
1. Specialization/Generalization
Superclass adalah sebuah tipe entitas yang mengandung satu atau
lebih kelompok kejadian dimana dibutuhkan untuk
menggambarkan sebuah model data.
Subclass Penjelasan kelompok kejadian sebuat tipe entitas,dimana
dibutuhkan untuk menggambarkan sebuah model data.
Beberapa hal ketentuan superclass dan subclass:
|
 -
Hubungan antara superclass dan subclass adalah 1:1.
-
superclass mungkin berisi pengulangan atau memiliki
perbedaan dengan subclass.
-
tidak seluruh anggota superclass memerlukan anggota dari
subclass.
Attribute Inheritance adalah suatu entitas dalam subclass yang
benar-benar menggambarkan objek nyata yang terdapat
dalam superclass.
Specialization Process adalah proses pembedaan secara
maksimum antara anggota suatu entitas yang
diidentifikasikan oleh perbedaan karakteristik.
Generalization Process adalah proses pembedaan secara
maksimum antara entitas yang diidentifikasikan oleh
karakterisitik umum.
Sumber (Connolly & Begg, 2010, p. 401)
|
 Terdapat 2 batasan dalam menerapkan specialization dan generalization
yaitu:
participation constraints
batasan yang menentukan setiap anggota superclass harus menjadi
bagian dalam subclass yang bersifat optional.
disjoint constraints
batasan yang menjelaskan hubungan antara anggota subclass,dimana
anggota tersebut merupakan bagian superclass yang menjadi anggota
satu subclass atau lebih.
2.
Aggregation
Aggregation adalah gambaran yang diwakili oleh kata ’memiliki’
atau ‘bagian dari’ suatu hubungan antara tipe entitas, dimana gambaran
tersebut dapat merupakan bagian atau keseluruhan dari yang lain.
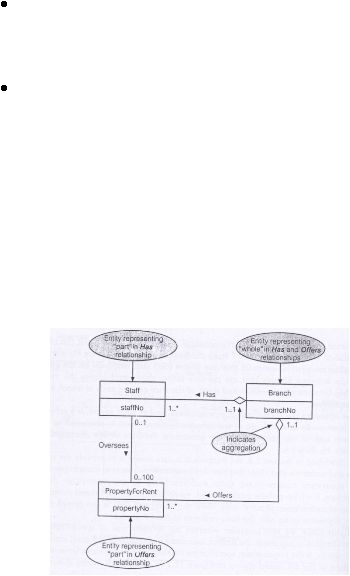
Sumber (Connolly & Begg, 2010, p. 412)
3.
Composition
Composition adalah bentuk khusus aggregation yang
menggambarkan hubungan asosisasi antar entitas, dimana terdapat
hubungan yang kuat dan kebetulan dalam seluruh atau sebagian siklus.
|
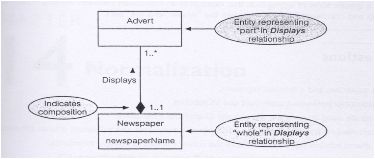 Sumber (Connolly & Begg, 2010, p. 413)
Menurut (Connolly & Begg, 2010, p. 66), Database Management
System
(DBMS)
adalah sebuah sistem perangkat lunak
menciptakan,
membuat mendefinisikan dan mengontrol akses ke database.
1.
Paralel DBMS
Menurut (Indrajani, 2011, p. 267), Paralel DBMS Merupakan
sebuah DBMS yang dijalankan melalui processor dan disk yang banyak,
yang dirancang untuk mengeksekusi operasi-operasi yang dijalankan
secara paralel kapanpun sehingga memungkinkan untuk meningkatkan
kemampuan
a. Berdasarkan pada alasan bahwa sistem processor tunggal tidak dapat
memenuhi syarat-syarat untuk skala biaya yang efektif, kendalanya,
dan kemampuan.
b. Paralel DBMS menghubungkan banyak mesin-mesin kecil untuk
mencapai hasil sama seperti tunggal,mesin-mesin yang besar dengan
scalability
dan realiability
yang lebih bagus dari single
processor
DBMS.
2. Fasilitas DBMS
Menurut (Connolly & Begg, 2010, p. 66).
DBMS menyediakan
fasilitas sebagai berikut:
|
|
a. Data Definition Language (DDL)
Digunakan untuk mendefiniskan, mengubah, serta menghapus
basis data serta objek-objek yang diperlukan dalam database.
Contoh: create table, drop table, alter table.
b. Data Manipulation Language (DML)
Bahasa basis data yang berguna untuk melakukan modifikasi dan
pengambilan data isi pada database.
Contoh: insert, update, delete.
c. Pengendalian akses basis data
d. Mekanisme View
3. Komponen DBMS
Terdapat 5 komponen utama dalam lingkungan DBMS yaitu
(Connolly & Begg, 2010, p. 68):
1. Hardware (Perangkat Keras)
2. Software (Perangkat Lunak)
3. Data
4. Prosedur
5. Manusia
Menurut (Roth, Dennis, & Wixom, 2013, p. 14) Tahap-tahap sistem
desain:
1. Strategi desain harus ditentukan. Ini menjelaskan apakah sistem akan
di kembangkan oleh programmer perusahaan itu sendiri, apakah
perusahaan akan membeli paket perangkat lunak.
2. Mengarah pada pengembangan desain arsitektur dasar untuk sistem
yang menggambarkan perangkat keras, perangkat lunak dan
infrastruktur jaringan yang akan digunakan.
|
 3. Database dan spesifikasi file
harus dikembangkan. Ini menjelaskan
dengan pasti data apa yang akan disimpan dan dimana data itu akan
disimpan.
4. Tim analisa mengembangkan disain program, yang mendefinisikan
program apa yang harus ditulis dan apa yang akan dilakukan program.
1). Data Flow Diagram (DFD)
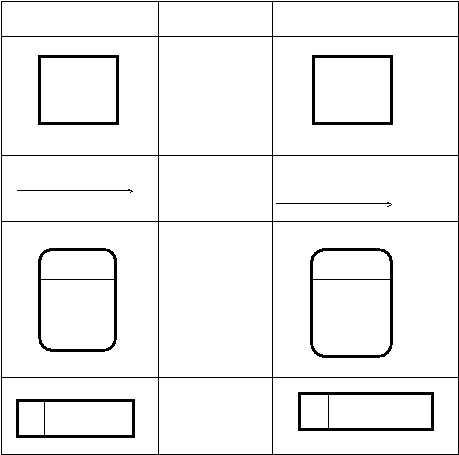
Menurut (Kendall, 2005, p. 192) elemen pada DFD yaitu :
Symbol
Meaning
Example
Entity
Data Flow
New Student Information
Process
Data Store
2.1
Create
Student
Record
Student
|
 1. Context diagram
Membuat context diagram dengan pendekatan top-down ke pergerakan
data diagram, diagram bergerak dari general ke spesifik.
Meskipun
diagram pertama membantu analisa sistem memahami gerakan dasar
data, itu bersifat umum yang membatasi penggunaannya. Gambaran
dasar pada diagram context adalah input dasar, general
sistem, dan
output. Diagram ini akan menjadi yang paling umum, pandangan luas
data dari dalam sistem dan
kemungkinan konseptualisasi luas dari
sistem. Diagram context
adalah level tertinggi pada DFD dan hanya
mengandung 1 proses, merepresentasikan seluruh sistem. Proses diberi
angka nol. Semua entitas luar ditampilkan pada diagram context,
seluruh aliran data utama ke dan dari mereka. Diagram context tidak
terdapat data penyimpanan dan cukup mudah untuk dibuat, setelah
entitas luar dan data mengalir dari ke dan dari mereka diketahui oleh
analis.
Sumber (Kendall, 2005, p. 210)
|
|
2. Diagram nol
Lebih detail daripada diagram context dimana izin dicapai oleh
"ledakan diagram". Spesifikasi input dan output pada diagram 1 tetap
konstan di semua diagram berikutnya. Sisa pada diagram asli, dipisah
menjadi close-up yang melibatkan tiga sampai sembilan proses dan
menunjukkan penyimpanan data dan data flow low-level
yang baru.
Setiap diagram yang dipisah seharusnya hanya menggunakan 1 lembar
kertas.
Dengan memisah DFD menjadi beberapa proses, sistem analisis
memulai untuk mengisi rincian tentang pergerakan data. Diagram 0
adalah pecahan dari diagram context dan memungkinan terdapat sampai
9 proses. Banyaknya proses pada tingkat ini akan menghasilkan
diagram yang berantakan yang sulit untuk dimengerti. Setiap proses
diberi nomor dengan integer, biasanya dimulai dari bagian kiri atas dan
bekerja menuju ke bagian kanan. Data utama disimpan di
sistem(merepresentasikan master file) dan semua entitas external
termasuk diagram 0
|
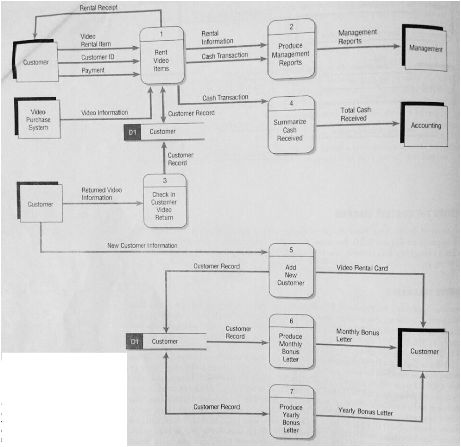 Sumber (Kendall, 2005, p. 210)
3. Child diagaram
Menggambarkan proses-proses yang lebih rinci (child diagram).
Menggambarkan proses-proses yang lebih rinci dari diagram proses
yang lebih rinci dari diagram nol mengenai sistem yang di analisis dan
yang akan di rancang.
|
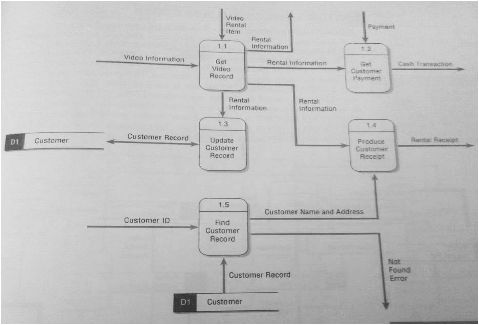 Sumber (Kendall, 2005, p. 210)
2). User Interface
Menurut
(Roth, Dennis, & Wixom, 2013, p. 311)
User interface
adalah bagian dari sistem yang berinteraksi dengan pengguna. Termasuk
menampilkan layar yang menyediakan navigasi melalui sistem, layar dan
bentuk yang menangkap data dan laporan sistem.
Dasar-dasar user interface :
1. layout
: antarmuka harus serangkaian area pada layar yang digunakan
secara konsisten untuk tujuan yang berbeda.
2. content awareness : pengguna harus selalu menyadari dimana mereka
berada dalam sistem dan informasi apa yang sedang ditampilkan.
3. aesthetics : antarmuka harus fungsional dan mengajak pengguna untuk
berhati-hati menggunakan white space, warna dan fonts.
4. user experience
: meskipun kemudahan penggunaan dan kemudahan
belajar sering menyebabkan keputusan desain yang sama, terkadang
|
 ada nya trade-off di antara keduanya.pengguna pemula dan pengguna
tidak tetap perangkat lunak akan lebih mudah mempelajarinya.
Sedangkan pengguna tetap akan lebih memilih menggunakan yang
mudah.
5. consistency : memungkinkan pengguna untuk memprediksi
apa yang akan terjadi sebelum mereka melakukan fungsi.
6.
minimize user effort
: antarmuka haruslah mudah digunakan.
Kebanyakan desainer berencana untuk merancang tidak lebih tiga kali
klik mouse dari menu mulai sampai pengguna melakukan pekerjaan.
3). State transition diagram
Sumber (Whitten & Bentley, 2007, p. 635)
Menurut (Whitten & Bentley, 2007, p. 635), State transition
diagram merupakan sebuah alat yang dilakukan untuk menggambarkan
urutan dan variasi layar yang biasa
terjadi selama sesi pengguna.
Digunakan agar diagram mudah di baca dan di pahami.
Menurut
(Connolly & Begg, 2010, p. 333), Membangun
sebuah model kerja sistem database. Prototype adalah model kerja
|
|
yang biasanya tidak memiliki semua fitur yang diperlukan dan
menyediakan
semua fungsi dari
sistem final. Ada dua strategi
prototyping umum digunakan saat ini yaitu :
a. Persyaratan prototyping
Persyaratan
prototyping
menggunakan
prototype
untuk
menentukan persyaratan sistem database yang diusulkan dan
saat persyaratan nya lengkap prototipe tersebut dihilangkan.
b. Prototyping evolusioner
Prototyping evolusioner
digunakan untuk
tujuan yang
sama, perbedaan penting adalah bahwa prototype
tidak
dihilangkan, tetapi dengan
pengembangan lebih lanjut
menjadi sistem database.
1). PHP
Menurut
(Sebesta, 2011, p. 374) php dikembangkan oleh
Rasmus Lerdorf, anggota kelompok apache, pada tahun 1994.
Tujuan awal adalah untuk menyediakan alat untuk membantu
pengunjung melacak Lerdorf ke situs web pribadinya.
Pada tahun 1995 ia mengembangkan sebuah paket bernama
alat website
pribadi, yang menjadi versi didistribusikan secara
terbuka pertama pada php. Awalnya, php adalah singkatan website
pribadi. Kemudian, komunitas pengguna yang mulai menggunakan
nama rekursif php.
Hypertext preprocessor, yang kemudian
memaksa nama asli untuk menanggapi ketidakjelasan tersebut.
Dalam waktu dua tahun dari di rilisnya, php telah
digunakan pada sejumlah besar situs web. Saat itu, tugas untuk
mengelola perkembangannya telah tumbuh melampaui
kemampuan satu orang dan tugas yang dipindahkan ke sekelompok
kecil relawan setia. Hari ini php dikembangkan didistribusikan dan
|
|
didukung sebagai produk open source. Prosesor php sekarang pada
kebanyakan.
2). My Sql
MySQL menurut situs MySQL(2014), MySQL adalah software
database open source yang paling populer di dunia, dengan lebih dari
100 juta kopi dari software download atau didistribusikan sepanjang
sejarah itu. Dengan kecepatan superior, kehandalan, dan kemudahan
penggunaan, MySQL telah menjadi pilihan yang lebih disukai untuk
Web, Web 2.0, SaaS, ISV, perusahaan Telecom dan berpikiran maju
Manajer TI perusahaan karena menghilangkan masalah utama yang
terkait dengan downtime, pemeliharaan dan administrasi untuk
modern, aplikasi online.Banyak organisasi terbesar dan dunia yang
tumbuh. Menggunakan MySQL untuk menghemat waktu dan uang
powering situs Web volume tinggi, sistem bisnis penting, dan paket
perangkat lunak - termasuk pemimpin industri seperti Yahoo !, Alcatel-
Lucent, Google, Nokia, YouTube,
Wikipedia,
dan Booking.com.
Unggulan MySQL menawarkan adalah MySQL Enterprise,
seperangkat produksi diuji software,
alat monitoring
proaktif, dan
layanan dukungan premium tersedia dalam langganan tahunan yang
terjangkau.
Menurut (Connolly & Begg, 2010, p. 334),
pada tahap ini
dibutuhkan
hanya ketika
sistem database
baru menggantikan
sistem
lama. Saat ini umum
untuk
dbms
memiliki
utilitas
yang
memuat file
yang ada
ke dalam
database baru. Utilitas
biasanya membutuhkan
spesifikasi
file
sumber
dan
target database
dan kemudian secara
otomatis
mengkonversi
data
ke format
yang diperlukan
dari
file
database baru. Yang berlaku dan dimungkinkan bagi pengembang untuk
mengkonversi
dan
menggunakan
program aplikasi
dari sistem lama
untuk digunakan oleh konversi
system
baru dan pemuatan diperlukan
|
|
proses
yang harus
direncanakan
dengan baik
untuk
memastikan
kelancaran transisi untuk beroperasi penuh.
1). Database Testing
Menurut (Roth, Dennis, & Wixom, 2013, p. 535) Dabatase testing
digunakan untuk mengungkap beberapa error
yang ada pada webApps.
Salah 1 contohnya yaitu pada servis finansial webApps yang dapat
menghasilkan informasi grafik tentang enkuitas spesifik(stok, reksa
dana). Konten objek komposit yang menampilkan informasi ini dibuat
secara dinamis setelah user me-request informasi tersebut. Untuk
mencapainya, dibutuhkan beberapa tahap:
1. meminta database enkuitas besar
2. data yang relevan diambil dari database
3. data yang diambil harus di organisir sebagai konten objek
4. konten objek ini di transmisi ke layar user
Error
dapat dan dan memang terjadi sebagai konsekuensi pada
setiap tahap. database testing
digunakan untuk mengungkap dipersulit
dengan faktor berikut :
1. permintaan asli dari sisi klien untuk informasi jarang disajikan dalam
bentuk yang dapat menjadi input untuk DBMS.
2. database
mungkin berada jauh dari server pada rumah WebbApps
tersebut.
3. data mentah yang diperoleh dari database harus ditransmisi ke server
WebbApps dan diformat untuk pengiriman selanjutnya ke klien.
4. konten objek dinamik harus ditransmisi ke klien dalam bentuk yang
dapat ditampilkan ke end user. error tersebut. tapi database testing.
Sesuai dengan faktor di atas,
metode desain test-case
harus
diterapkan pada setiap interaksi layer pada gambar di bawah testing harus
memastikan bahwa :
|
|
1. Informasi yang valid harus dikirim antara klien dan server dari layer
interface.
2. Script proses WebApps yang benar dan data yang diambil atau format
data user.
3. Data user
harus dikirim dengan benar ke server data dan fungsi
transformasi data sisi server yang format permintaan nya sesuai.
4. Query dikirim ke manajemen data.
2). Software Testing
Menurut Software testing
merupakan salah satu unsur dari topik
yang lebih luas yang sering disebut sebagai verifikasi dan validasi.
Verifikasi mengacu pada kumpulan tugas yang memastikan bahwa
software mengimplementasi sebuah fungsi spesifik. Validasi mengacu
pada satu kumpulan yang berbeda dari tugas-tugas yang memastikan
bahwa software yang telah dibangun dapat dilacak dengan kebutuhan
pelanggan.
Strategi software testing :
1.
Unit testing
dimulai pada pusaran spiral dan berkonsentrasi pada setiap unit
perangkat lunak seperti yang diterapkan dalam kode sumber
2.
Integration testing
berfokus pada desain dan pembangunan pada arsitektur software
3. Validation testing
persyaratan yang ditetapkan sebagai bagian dari kebutuhan
pemodelan di validasi terhadap software yang telah dibangun
4. System testing
software dan elemen sistem lainnya diuji secara keseluruhan
|
|
3). User Interface Testing
Menurut (Shneiderman 2005, p. 74),
ada 8 prinsip yang disebut
delapan aturan emas dalam mendesain sistem interaktif, di antaranya
sebagai berikut :
1. Mengupayakan untuk konsistensi
Konsistensi di sini artinya konsisten dalam urutan tindakan diminta
dalam situasi yang sama,
terminologi yang sama harus digunakan
dalam petunjuk, menu, dan layar bantuan, serta konsisten warna,
tata letak, huruf besar, huruf, dan sebagainya harus digunakan di
seluruh halaman.
2. Menyediakan usability universal
Perbedaan
pemula dan ahli, rentang usia, cacat, dan
keanekaragaman teknologi masing-masing
memperkaya spektrum
persyaratan yang memandu desain. Menambahkan fitur untuk
pemula, seperti penjelasan, dan fitur untuk para ahli, seperti cara
pintas dan mondar-mandir lebih cepat, bisa
memperkaya desain
antarmuka dan meningkatkan kualitas sistem yang dirasakan.
3. Memberikan umpan balik yang informatif
Untuk setiap tindakan pengguna, harus ada umpan balik sistem.
Untuk tindakan sering dan sederhana, respon dapat menjadi
sederhana, sedangkan untuk tindakan jarang dan besar, respon harus
lebih substansial.
4.Merancang dialog yang memberikan penutupan(keadaan akhir)
Urutan
tindakan harus diatur ke dalam kelompok dengan awal,
tengah, dan akhir. Umpan balik yang informatif pada penyelesaian
sekelompok tindakan
memberikan operator kepuasan pencapaian,
rasa
lega, sinyal untuk menghentikan rencana darurat dari pikiran
mereka, dan sinyal untuk mempersiapkan tindakan berikutnya.
5.
Mencegah kesalahan
Sebisa mungkin, merancang sistem sedemikian rupa sehingga
pengguna tidak membuat kesalahan serius.
Jika pengguna
|
|
membuat kesalahan, antarmuka harus mendeteksi kesalahan dan
menawarkan instruksi sederhana, konstruktif, dan khusus untuk
pemulihan.
6. Memungkinkan pembalikkan tindakan yang mudah.
Sebisa mungkin, tindakan harus dapat dibalikkan.
Fitur ini
mengurangi kecemasan,
karena pengguna tahu bahwa kesalahan
dapat dibatalkan, sehingga mendorong eksplorasi opsi asing.
7. Mendukung pusat kendali internal
Operator yang berpengalaman sangat menginginkan mereka dapat
bertanggung jawab atas antarmuka
dan antarmuka merespon
tindakan mereka. Urutan membosankan entri data, ketidakmampuan
atau kesulitan untuk memperoleh informasi yang diperlukan, dan
ketidakmampuan untuk menghasilkan tindakan yang diinginkan
mengakibatkan ketidakpuasan.
8. Mengurangi beban ingatan jangka pendek
Keterbatasan pemrosesan informasi manusia dalam ingatan jangka
pendek mensyaratkan bahwa
tampilan akan dibuat sederhana,
beberapa halaman yang ditampilkan dapat digabung, frekuensi
window-motion
dikurangi, dan waktu pelatihan yang cukup
dialokasikan untuk kode, cara menghafal, dan urutan tindakan.
Apabila diperlukan, akses online ke bentuk perintah sintaks,
singkatan, kode, dan informasi lainnya harus disediakan.
4). UAT (User Acceptance Testing)
Menurut (Roth, Dennis, & Wixom, 2013, p. 453), Tujuan UAT
adalah untuk memastikan sistem itu selesai dan diterima oleh
pengguna. Tipe pengujian pada UAT :
-
Alpha testing
: dipimpin oleh pengguna untuk memastikan mereka
menerima sistem tersebut.
Sumber rencana uji : uji sistem.
|
|
Digunakan saat pengujian biasa yang dapat diterima. Alpha test sering
kali mengulang penngujian sebelumnya, tetapi dipimpin oleh
pengguna untuj memastikan mereka menerima sistem tersebut.
-
Beta testing : menggunakan data asli, bukan uji data.
Sumber rencana uji : tidak ada rencana.
Digunakan apabila sistem itu penting. Pengguna dengan teliti
memantau sistem dari error.
Menurut
(Connolly & Begg, 2010, p. 336), yang
melibatkan kegiatan-kegiatan berikut sebagai berikut :
a. Memantau performance of sistem
b. Mempertahankan dan meningkatkan sistem database (bila
diperlukan)
Teori yang terkait tema penelitian (tematik)
Menurut (Press, 2005, p. 988), Monitoring adalah untuk melihat
dan mengecek pada periode waktu yang ditentukan dan bagaimana untuk
melihatnya berkembang.
Reporting adalah deskripsi lisan
atau non-lisan pada sesuatu yang mengandung informasi yang perlu
diawasi.
|
|
|