 6
BAB 2
LANDASAN
TEORI
2.1
Proses
Penghasilan dan
Pemahaman Suara pada
Manusia
Proses menghasilkan suara dimulai dari adanya ide atau pesan di dalam otak manusia
yang
ingin
disampaikan kepada
orang
lain. Lalu
pesan
ini
diterjemahkan ke
dalam bahasa,
setelah
menemukan kode
bahasa
yang
tepat,
langkah
berikutnya
otak
akan
memberikan
perintah
kepada
jaringan
saraf
untuk
membuat
pita
suara
manusia
bergetar
dengan
tepat,
selain
itu
juga
untuk
membentuk
bidang
suara,
sehingga
akan
dihasilkan suara
yang
diinginkan serta mewakili pesan yang ingin disampaikan (lihat gambar 2.1).
MACHINE COUNTERPARTS
SPEECH GENERATION
SPEECH
RECOGNITION
MACHINE COUNTERPARTS
PRINTED TEXT
(50BPS)
PHONEMES SEQUENCES,
PROSODY CONVENTION
(200 BPS)
(DISCRETE)
(CONTINUOUS)
ARTICULATORY
MOTION(2000 BPS)
MESSAGE FORMULATION
LANGUAGE CODE
NEURO-MUSCULAR
ACTIONS
ACOUSTIC
SYSTEM
(VOCAL
TRACT)
SOUND SOURCE
(VOCAL CORDS)
TALKER
ACOUSTIC
WAVE
ELECTRICAL
TRANSMISSION
(30000
BPS)
MESSAGE
COMPREHENSION
LANGUAGE
CODE
NEURAL TRANSDUCTION
BASILAR MEMBRANE
MOTION
LISTENER
MEANING SEMANTICS
PHONEMES, WORDS,
SENTENCES,
PROSODY (SYNTAX)
(DISCRETE)
(CONTNUOU
INUOU
S)
FEATURE EXTRACTION
RE-CODING
ACOUSTIC SPECTRUM
ANALYSIS
Gambar 2.1 Diagram
Skematik Dari
Proses
Produksi dan Persepsi
Suara
(Rabiner dan Juang, 1993, p12)
Proses pemahaman suara dimulai saat sinyal suara dari lawan bicara ditangkap oleh
selaput basillar,
kemudian selaput ini menghasilkan analisis spektrum bergerak. Proses pada
|
|
7
neural
transduction
mengubah
sinyal
spektral
yang
tadi
dihasilkan oleh
selaput
basillar
menjadi sinyal aktivitas pada saraf pendengaran. Aktifitas saraf tersebut diubah menjadi kode
bahasa
pada
proses
yang
dilalui
sebelum pesan
tersebut
diolah
oleh
otak
manusia,
pada
akhirnya pemahaman terhadap pesan yang masuk didapatkan.
Pemahaman pada
unsur bunyi yang
mendominasi suatu bahasa akan
menjadi sangat
penting.
Dengan
mengetahui unsur-unsur
apa
saja
yang
terdapat
dalam
suatu
bahasa
diharapkan dapat mengatasi kendala dalam mengenali kata-kata ucapan manusia.
2.1.1 Proses
Penghasilan Ucapan
Untuk
berkomunikasi manusia
menggunakan
ucapan.
Ucapan
yang
dihasilkan
membentuk suatu bunyi
yang dapat dimengerti oleh orang
lain. Bunyi tersebut
merupakan
bahasa dalam kehidupan manusia..
Proses
penghasilan ucapan diawali dengan adanya perintah dari
otak kepada organ-
organ tubuh pernafasan manusia untuk membentuk suatu bunyi tertentu (gambar- 2.2). Udara
masuk
ke
dalam
paru-paru
melalui
proses
pernafasan biasa. Kemudian udara dikeluarkan
melalui tenggorokan
menuju
larinx.
Di
larinx
aliran
udara
yang
timbul
menyebabkan pita
suara bergetar. Bunyi yang dihasilkan akan dikeluarkan bersamaan dengan arus udara melalui
saluran pernafasan. Organ–organ pada
saluran pernafasan seperti pharinx,
lidah, mulut
dan
bibir turut membentuk bunyi yang diinginkan.
Paru-paru
(lungs)
dan
batang
tenggorokan (trachea)
mengatur
arus
udara
yang
diperlukan untuk
berbicara,
sehingga keras
dan
lembutnya ucapan
yang dihasilkan sangat
bergantung pada paru-paru dan batang tenggorokan. Larinx adalah rongga pada ujung
trachea dimana terdapat pita suara, sehingga larinx disebut juga voicebox.
|
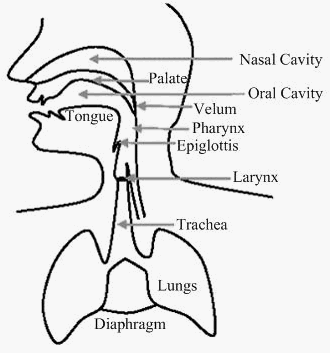 8
Gambar 2.2 Anatomi
Organ Penghasil
Ucapan
Pita
suara
memiliki
fungsi
akustik
sebagai
sumber
pembangkit
ucapan.
Pita
suara
yang membuka dan menutup
membentuk rongga di antara sepasang pita suara yang disebut
glotis.
Pita
suara
berfungsi
juga
sebagai
klep
yang
dapat
membuka,
menutup,
membuka
lebar,
menutup
sebagian,
atau
menutup
habis
arus
udara
yang
melewatinya. Pada
saat
pernafasan
normal
pita
suara
terbuka
lebar
sehingga
arus
udara
dapat
leluasa
masuk
dan
keluar dari sistem pernafasan manusia. Akan
tetapi pada saat
manusia berbicara, pita suara
dapat
menutup rapat arus udara yang ada untuk menghasilkan bunyi sesuai dengan perintah
otak.
Ketika
pita
suara
menegang,
aliran
udara
mengakibatkan pita
suara
bergetar
menghasilkan bunyi
berucapan
(voiced) (Rabiner dan Juang,
1993, p14).
Ketika pita
suara
melonggar untuk menghasilkan suatu bunyi, aliran udara dipaksa melewati celah sempit pada
|
|
9
bidang
ucapan sehingga
dihasilkan
bunyi
tak
berucapan
(unvoiced) (Rabiner
dan
Juang,
1993, p15).
Bidang
ucapan
berfungsi
untuk
pewarnaan
dan
artikulasi
ucapan. Pada
saat
gelombang
akustik
melalui
bidang
ucapan,
frekuensinya dipengaruhi
oleh resonansi
dalam
rongga
bidang
ucapan.
Resonansi
ini
sangat
tergantung
pada
bentuk
dan
ukuran
bidang
ucapan manusia. Bidang ucapan meliputi pharinx (dari esophagus
sampai mulut) dan mulut.
Seluruh
organ bicara
setelah
glotis
merupakan bagian dari
bidang
ucapan.
Pada
laki-laki
dewasa panjang total bidang ucapan mencapai sekitar 17 cm (Rabiner dan Juang, 1993, p14).
Potongan melintang (cross-sectional) bidang ucapan ditentukan dari posisi lidah, bibir,
rahang,
dan langit-langit
lunak (velum), dan biasanya
berkisar
dari nol sampai 20 cm²
(Rabiner dan Juang, 1993, p14 ). Sedangkan rongga hidung (nasal track) dimulai dari velum
dan berakhir pada lubang hidung (nostrils). Ketika velum
menurun/mengendor,
rongga
hidung secara akustik dipasangkan pada bidang ucapan untuk menghasilkan bunyi ucapan.
Bidang suara secara akustik dapat dimodelkan sebagai tabung potongan melintang tak
seragam
sepanjang
±17 cm
pada
lelaki
dewasa;
terbuka
pada
salah
satu
ujungnya,
dan
tertutup
pada
ujung
yang
lain
(Santosa,
2002).
Tabung
utama
ini
bercabang di
tengah
membentuk rongga hidung yang berupa tabung sepanjang ±13 cm, dengan katup (anak tekak)
pada percabangannya sebagaimana pada gambar 2.3.
|
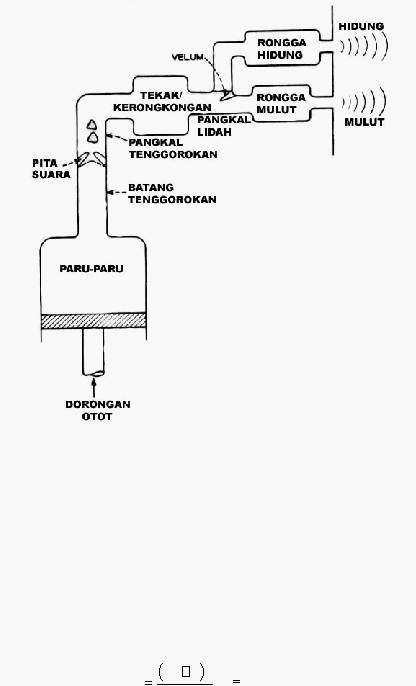 10
Gambar 2.3 Representasi Semantik dari
Mekanisme
Penghasilan Suara
(Rabiner dan
Juang,1993,p17 )
Untuk mempermudah analisis diasumsikan bahwa katup anak tekak tertutup. Tabung
tersebut mempunyai banyak frekuensi alami, yaitu frekuensi pada saat fungsi pindah
(transfer function)
tabung
maksimum.
Jika
potongan
melintang tabung tersebut
seragam,
maka fungsi alami akan terjadi pada :
f
n
2n
1
c
4l
,
n
1,2,3,...
Di
udara
c
=
350 m/detik, untuk
panjang tabung
l
=17
cm, diperoleh frekuensi alami
pada
kelipatan
ganjil
mendekati
500
Hz.
Karena
kenyataannya
daerah
bidang
suara
tak
seragam,
maka
resonansi
terjadi
dengan
spasi
frekuensi
yang
berbeda.
Walaupun demikian
untuk
setiap
lebar
bidang
tetap
sekitar
1
kHz
terjadi
sekali
resonansi. Resonansi
ini
disebut
dengan
formant, yaitu
frekuensi
alami
|
|
11
bidang suara yang merupakan bagian penting dalam modulasi suara. Formant
ditandai
dengan angka,
sesuai dengan bertambahnya frekuensi.
2.1.2 Gangguan Pada
Sinyal
Ucapan
Sinyal
ucapan
yang
masuk ke
dalam
sistem
pengenalan
ucapan,
tidak
selalu
bersih
dari
gangguan yang berupa noise atau derau. Noise merupakan semua bentuk besaran,
yang
bukan merupakan bagian dari besaran atau sesuatu yang diinginkan, misalnya sinyal ucapan.
Ada dua
macam noise yaitu internal
noise dan external noise. Internal
noise dihasilkan oleh
efek panas
pada
penguat sinyal
(amplifier).
Banyaknya
noise
yang
ditambahkan
ke
dalam
sinyal bergantung pada bandwidth amplifier masukan. Salah satu cara untuk menekan
internal
noise
adalah
memilih
amplifier yang
memiliki
bandwidth mendekati
bandwidth
sinyal
masukan. Jenis
kedua
adalah
external
noise.
Noise jenis
ini
masuk ke
dalam
sinyal
ketika sinyal bergerak di dalam kabel. External
noise dapat dihasilkan dari berbagai macam
sumber.
Salah
satu
contohnya, pada
banyak eksperimen penambahan data,
60
Hz noise
dihasilkan oleh jalur tenaga AC. Noise jenis ini muncul sebagai sinyal interferensi sinusoidal
di dalam papan pengukur. Noise yang masuk ke dalam papan pengukur berasal dari sumber-
sumber eksternal. Hal ini terjadi karena sinyal sangat mudah dimasuki oleh sinyal lainnya di
dalam
lingkungan
aktifitas
elektris.
Untuk
menghilangkannya,
dapat
dilakukan
beberapa
cara, misalnya menjauhkan kabel penghantar sinyal dari lingkungan aktivitas elektris.
Filter
dapat
digunakan untuk
menekan
adanya
noise
pada
sinyal.
Untuk
beberapa
aplikasi
penambahan
data
cukup
digunakan
low-pass
filter.
Low-pass filter
melewatkan
komponen frekuensi yang lebih rendah tetapi melemahkan komponen dengan frekuensi lebih
tinggi. Cut-off frekuensi dari filter harus cocok dengan frekuensi sinyal yang diinginkan saat
ini serta sampling
rate yang digunakan
untuk pengubahan sinyal analog ke
sinyal digital.
|
|
12
Antialiasing
filter adalah
low-pass
filter
yang digunakan
untuk
mencegah
frekuensi
yang
lebih tinggi menimbulkan distorsi pada sinyal digital (Matlab, 2002).
2.2
Unsur-Unsur Bunyi pada
Bahasa
Bunyi–bunyi ujar
menurut Samsuri secara
garis besar dapat digolongkan menjadi 2
bagian yaitu vokoid dan kontoid.
Vokoid ialah
bunyi yang
bagi pengucapannya jalan
mulut tidak
terhalang, sehingga
arus udara
dapat
mengalir dari
paru- paru
ke
bibir
dan
keluar
tanpa dihambat, tanpa harus
melalui
lubang
sempit,
tanpa
dipindahkan dari
garis
tengah
pada
alurnya,
dan
tanpa
menyebabkan sebuahpun alat-alat supra glottal bergetar (Samsuri, 1994, p103).
Kontoid
ialah bunyi
yang bagi pengucapannya arus udara dihambat sama sekali oleh
penutupan
larynx
atau
jalan di
mulut,
atau dipaksa
melalui
jalan sempit,
atau
dipindahkan
dari
garis
tengah
daripada
alurnya
melalui
lubang
lateral,
atau
menyebabkan bergetarnya
salah satu alat- alat supra glottal (Samsuri, 1994, p103).
Selain itu masih terdapat unsur-unsur bunyi lain seperti :
Fonem
Vokal
Konsonan
Nasal
Diftong
Frikatif
Morfem
|
 13
2.2.1
Fonem
Ahli ilmu bunyi yang paling pandai sekalipun tidak dapat membedakan semua bunyi
secara objektif. Tidak ada dua orang pendengar, betapapun kecakapannya dalam ilmu
bunyi,
dapat
menghasilkan dua
transkripsi
yang
sama
benar
tentang
bahasa
yang
sama
(Samsuri,1994).
Untuk itu diperlukan pengetahuan tentang fonem. Fonem didefinisikan sebagai :
bunyi-bunyi yang membedakan arti atau pengertian (Samsuri, 1994, p124)
satuan bunyi terkecil yang mampu menunjukan kontras makna (Kamus Besar Bahasa
Indonesia, 2001, p319)
Seperti
juga
bunyi-bunyi,
fonem-fonem
dalam
bahasa
Indonesia
dapat
dibagi
menjadi
dua
kelompok,
yaitu
fonem-fonem
segmen
dan
fonem-fonem
suprasegmen. Fonem-fonem segmen dibagi
lagi
menjadi
dua
kelompok, yaitu
fonem vokal
(/i.
,u,e,a,o/) dan
fonem
konsonan, sedangkan fonem
suprasegmen terdiri atas tekanan, nada, panjang serta jeda.
2.2.2
Vokal
Vokal didefinisikan sebagai :
Bunyi bahasa yang dihasilkan oleh arus udara dari paru- paru melalui pita suara dan
penyempitan pada saluran suara di atas glottis (Kamus Besar Bahasa Indonesia, 2001,
p1263).
Satuan
fonologis
yang
diwujudkan
dalam
lafal
tanpa
pergeseran,
seperti
[a,i,u,e,o]
(Kamus Besar Bahasa Indonesia , 2001, p1263).
2.2.3
Konsonan
Menurut
Kamus
Besar
Bahasa
Indonesia konsonan
diartikan sebagai
bunyi bahasa
yang dihasilkan dengan menghambat aliran udara pada salah satu tempat disaluran suara di
|
|
14
atas
glottis
atau
fonem
yang
mewakili suatu
bunyi
kontoid.
Konsonan
dibagi
menjadi
dua
bagian yaitu ambisilabis dan silabis. Ambisilabis adalah konsonan
yang menjadi transisi dari
dua
suku
kata.
Silabis
adalah konsonan yang
mendukung puncak
kenyaringan dalam
suku
kata (Kamus Besar Bahasa Indonesia, 2001, p589).
2.2.4 Semi vokal
Semi
vokal
adalah
bunyi
bahasa
yang
mempunyai ciri
vokal
ataupun
konsonan,
mempunyai sedikit
geseran
dan
tidak
muncul
sebagai
inti
suku
kata,
missal
[y],
[r],
[w]
(Kamus Besar Bahasa Indonesia, 2001, p1030).
2.2.5 Nasal
Nasal bersangkutan dengan bunyi bahasa yang dihasilkan dengan mengeluarkan udara
melalui hidug yaitu m, n, ng, ny (Kamus Besar Bahasa Indonesia, 2001, p775).
2.2.6 Diftong
Diftong
adalah
suatu
kombinasi vokoid-
vokoid
silabis
(Samsuri,
1994,
p111).
Sedangkan menurut Kamus Besar Bahasa Indonesia diftong adalah bunyi vokal rangkap yang
tergolong dalam satu suku kata. Diftong dapat dikelompokkan menjadi beberapa jenis yaitu :
Lebar
: diftong yang terjadi dengan perubahan letak lidah yang agak banyak, misal ai
pada lantai
Naik
:
diftong yang bagian paling nyaringnya terdapat sesudah peluncurannya
Sempit :
diftong
yang
terjadi
dengan sedikit
perubahan
letak
lidah,
misal
ei
pada
survei
|
|
15
Turun
: diftong
yang
bagian
paling
nyaringnya
terdapat
sebelum
peluncurannya,
misalnya au pada harimau
2.2.7
Frikatif
Frikatif adalah bunyi yang dihasilkan bila udara menggeser alat ucap, misal bunyi [f]
(Kamus Besar Bahasa Indonesia, 2001, p322).
2.2.8
Morfem
Morfem didefinisikan sebagai :
Komposit bentuk-pengertian
yang terkecil yang sama atau mirip yang berulang
(Samsuri, 1994, p170)
Satuan bentuk bahasa terkecil yang punya makna secara relatif
stabil dan tidak dapat
dibagi atas bagian bermakna yang lebih kecil (Kamus Besar Bahasa Indonesia, 2001,
p755).
Menurut Kamus Besar Bahasa Indonesia morfem dibagi menjadi beberapa jenis yaitu
:
Bebas
: morfem
yang
secara
potensial
dapat
berdiri
sendiri
dalam
suatu
bangun
kalimat
Dasar : morfem yang dapat diperluas dengan dibubuhi afiks
Dasar terikat
:
morfem dasar
yang hanya dapat
menjadi kata bila bergabung dengan
afiks atau dengan morfem lain
Gramatikal
:
morfem
yang
jumlahnya
terbatas
dan
berfungsi
sebagai
penghubung
diantara morfem leksikal
|
|
16
Leksikal : morfem yang jumlahnya tidak terbatas dan sangat produktif (mencangkup
kata penuh dan afiks derivatif)
Penyambung : unsusr yang diletakkan antara dua morfem lain
Segmental : morfem yang terjadi dari fonem segmental
Suprasegmental : morfem yang terjadi dari fonem suprasegmental
Terbagi : morfem yang realisasinya dalam bentuk morfem diantarai oleh unsur lain
Terikat : morfem yang tidak mempunyai potensi untuk berdiri sendiri dan yang selalu
terikat dengan morfem lain untuk membentuk ujaran
Unik : morfem yang hanya mampu berkombinasi dengan satu satuan tertentu
2.3
Teknologi
Suara
Ketika
seseorang
berbicara,
udara dari
paru-paru dikeluarkan
melalui bidang suara
dan keluar dari mulut berupa sebuah gelombang. Gelombang akustik yang sampai ke telinga
pendengar dikenali sebagai
ucapan
(speech)
dengan
warna
bunyi
(timbre),
periode (pitch),
frekuensi
resonans
fundamental (formant),
dan
kekerasan
(loudness)
yang
berbeda.
Gelombang
suara
mengandung
banyak
informasi
yang
memungkinkan telinga
dan
otak
manusia
membedakan karakter dan
cirinya, sehingga dapat dikenali
dan
dipahami.
Dengan
teknik
pemprosesan
suara
(speech
processing),
ciri
dan
karakter suara
dapat
dikenali.
Perkembangan
teknologi
yang
pesat
memungkinkan dilakukannya
pemprosesan
suara
menggunakan komputer.
Pemprosesan
suara
dapat
di
bagi
2,
yaitu
analisis
suara
(speech
analysis) dan sintetis suara (speech synthetis).
Analisis
suara adalah bagian dari pemprosesan
suara
yang mengubah suara
manusia
menjadi bentuk digital yang sesuai untuk pengiriman
atau penyimpanan
oleh computer
|
|
17
(Santosa,2002).
Analisis
suara
memainkan
peranan
yang
sangat penting
dalam
pengenalan
ucapan
(speech
recognition),
pemahaman suara
(speech
understading)
dan
identifikasi
pembicara (speaker identification). Sedangkan fungsi sintetis suara merupakan kebalikan dari
analisis suara. Analisis dan sintetis suara dapat dilakukan baik dalam kawasan waktu maupun
kawasan frekuensi, sehingga ciri-ciri dan karakteristik suara dapat ditentukan.
Analisis
suara
menggunakan komputer
diawali
dengan
mengubah
sinyal
analog
menjadi sinyal digital
menggunakan ADC (analog
to digital converter). Sinyal suara analog
yang kontinu akan diubah
menjadi sinyal digital
yang diskret. Dalam hal
ini
terjadi proses
pencuplikan (sampling) dan kuantisasi (quantizing). Pencuplikan menjadi sinyal suara diskret
dalam
waktu,
dan
kuantisasi membuat
amplitudo sinyal
suara
menjadi
diskret.
Teori
pencuplikan
(sampling teorem) menyatakan
bahwa sinyal digital dapat mewakili sinyal
analog secara unik jika kecepatan cuplik sekurang-kurangnya 2 kali frekuensi tertinggi sinyal
analog
yang
dicuplik(Santosa, 2002). Dengan demikian
jika
frekuensi
cuplik F
s
Hz,
maka
frekuensi tertinggi
untuk
menyatakan sinyal analog
tidak dapat
melebihi
frekuensi Nyquist
F
s
/2 Hz.
Frekuensi
cuplik
yang kurang
dari
2
kali
frekuensi
Nyquist akan
menyebabkan
aliasing. Pencuplikan yang benar tidak akan menghilangkan informasi. Komponen frekuensi
sinyal suara bervariasi kurang lebih dari 80 Hz sampai 8 kHz, tetapi sebagian besar
komponen
yang berarti
terkonsentrasi di
bawah
4
kHz.
Oleh
karena
itu
pencuplikan
suara
dapat dilakukan pada frekuensi 8 kHz (Santosa, 2002).
2.3.1 Sejarah
Perkembangan Pengenalan Ucapan
Pemprosesan
sinyal suara telah dirintis sejak tahun
1779
dengan ditemukannya alat
pensintesa
ucapan secara
mekanis, namun
perkembangannya baru terlihat 143
tahun
|
|
18
kemudian yaitu pada tahun 1922 dengan ditemukannya
pensintesa ucapan elektris dan
selanjutnya ditemukannya spectogram pada tahun 1946 (Nugroho, 2001, p1) .
Penelitian
mengenai
pengenalan suara secara
otomatis
oleh
mesin
telah
dilakukan
selama
hampir 5 dekade. Ide
mengenai sistem pengenalan suara oleh
mesin muncul
sekitar
pada
tahun
1950-an. Pada
tahun 1950-an para
peneliti
mencoba
mengeksploitasi
ide dasar
tentang
acoustic-phonetics.
Pada
tahun
1952,
di
Bell
Laboratories, Davis,
Biddulp,
dan
Balashek
membangun sebuah
sistem
pengenalan digit
tertutup
untuk
seorang
pembicara.
Sedangkan
pada tahun
1956,
Oslon
dan
Belar
di
RCA
Laboratories
mencoba
membangun
sistem
yang
dapat
mengenali
10 kata
untuk
seorang
pembicara
dengan setiap
kata
dari 10
kata-kata tersebut memiliki bunyi yang sangat berbeda dan monosyllabic. Pada tahun 1959 di
Universitas
Colegge,
Inggris,
Fry
dan
Denes
mencoba
membuat
sebuah
pengenal
fonem
untuk mengenali 4 buah vokal dan 9 konsonan. Mereka menggunakan analisis spectrum dan
pembanding
pola
untuk
menganalisa suara.
Pada
tahun
yang
sama,
Forgie
dan
Forgie
membangun
sebuah
sistem
pengenalan
vokal
pada
MIT
Lincoln
Laboratories.
Pada
percobaan
tersebut
metode
yang
digunakan
untuk
analisis
spectral
adalah
filter
bank
dan
untuk menentukan vokal mana yang diucapkan digunakan estimasi waktu terhadap resonansi
vokal track.
Pada tahun
1960-an,
Jepang
turut serta mengambil
bagian
dalam
pengembangan
sistem
pengenalan
suara.
Beberapa
laboratorium di
Jepang
membangun
perangkat
keras
dengan tujuan khusus
untuk pengenalan suara sebagai bagian dari sistem mereka. Salah satu
perangkat
keras
yang
dikembangkan pada
tahap
awal
penelitian
dibuat
oleh
Suzuki
dan
Nakata dari
Radio
Reseach
Lab,
Tokyo,
untuk
mengenali suara
vokal.
Pada
tahun 1962,
Doshita dan Sakai dari Kyoto University berhasil membuat sebuah perangkat keras pengenal
|
|
19
fonem. Sumbangan lainnya diberikan oleh Nagata dan pekerja dari NEC Laboratories pada
tahun 1963, yaitu berupa perangkat keras pengenal digit.
Pada
tahun
1960-an
terdapat
3
penelitian
penting
yang
mempengaruhi penelitian
sistem pengenalan suara untuk masa-masa mendatang. Yang pertama dibuat oleh Martin dan
rekannya
dari
RCA Laboratories.
Mereka
membangun
sebuah
dasar
metode
normalisasi
waktu
(time-normalization
method) yang
memiliki kemampuan
untuk
mendeteksi awal
dan
akhir
ucapan.
Martin
terus
mengembangkan metode
tersebut
dan
mendirikan
sebuah
perusahaan
yang
bernama
Threshold Company,
yang
pertama kali
membuat,
memasarkan
dan
menjual produk
pengenal suara.
Pada
saat
yang
sama,
di
Rusia, Vintsyuk
mengajukan
penggunaan
metode
pemograman
dinamis
yang
sejalan
dengan
waktu
untuk
pengenalan
suara. Ini
merupakan dasar dari Dynamic Time Warping, yang penggunaannya tidak
diketahui oleh dunia barat sampai pada tahun 1980-an. Pada waktu itu metode formal lainnya
sudah
lama
diajukan
dan
digunakan. Penelitian
lainnya
dilakukan
oleh
Reddy
yang
menitikberatkan pada
pengenalan
suara
kontinu
(continuous
speech
recognition)
dengan
penelusuran dinamis terhadap fonem. Program penelitiannya di Carnegie Mellon
University
berkembang dan membuahkan hasil yang memuaskan.
Pada tahun 1970-an, terdapat sejumlah penelitian penting mengenai sistem
pengenalan suara. Untuk
pertama kalinya isolated
word
atau discrete
utterance
recognition
menjadi teknologi yang berguna berkat penelitian fundamental yang dilakukan oleh Velichko
dan
Zagoruyko di
Rusia,
Sakoe
dan
Chiba
di
Jepang,
dan
Itakura
di
Amerika
Serikat.
Penelitian
oleh
Rusia
membantu
penguasaan metode
pattern
recognition
untuk
sistem
pengenalan suara. Penelitian di Jepang menunjukan bagaimana metode pemograman dinamis
berhasil diterapkan. Sedangkan penelitian Itakura menunjukan
bagaimana ide mengenai
Linear
Predictive
Coding (LPC) berhasil diterapkan pada low-bit-rate
speech coding, yang
|
|
20
dapat
dikembangkan
menjadi
sistem
pengenalan
suara
dengan
menggunakan pendekatan
pengukuran jarak (distance measure) berdasarkan parameter spectral LPC.
Penelitian
penting
lainnya
pada
tahun
1970-an
dilakukan oleh
IBM
yang
berhasil
membangun
sebuah
sistem
dengan
menggunakan
pengenalan
suara
kosa
kata
besar
(large
vocabulary speech recognition). Peneliti mempelajari 3 fungsi utama sistem selama hampir 2
dekade.
Fungsi
pertama diberi
nama
New Raleigh
language
yang berfungsi sebagai simple
database
queries. Yang
kedua
adalah
laser
patent
text
language
yang
bertugas
menerjemahkan laser patents. Sedangkan yang ketiga, Tangora merupakan sistem
pendiktean pada memo sederhana.
Jika pada tahun 1970-an penelitian difokuskan pada isolated word recognition, maka
pada tahun 1980-an penelitian lebih difokuskan pada connected word recognition. Pada tahun
1980-an
terjadi
perubahan metode
penelitian
dari
template-based
approach
ke
metode
pemodelan statistik (statistical modeling method). Metode pemodelan statistik
yang terkenal
adalah
hidden
Markov
model (HMM).
HMM
sebenarnya
telah
digunakan
oleh
beberapa
laboratorium
seperti IBM,
Institute
for Defense Analyses (IDA), dan Dragon
System. Akan
tetapi
penggunaan HMM
baru
tersebar
luas
pada
pertengahan
tahun
1980-an.
Teknologi
lainnya yang
muncul pada akhir tahun 1980-an adalah penggunaan Neural Network. Neural
Network pertama
kali
diperkenalkan
pada
tahun
1950-an,
tetapi
tidak
berkembang
karena
terdapat banyak masalah
pada implementasinya.
Akhirnya pada tahun 1980-an perhatian tertuju pada sistem pengenalan suara kontinu
dan kosa kata besar
yang penelitiannya didukung oleh Defense Advanced Research Projects
Agency
(DARPA). Penelitian mentargetkan pengenalan 1000 kata dengan pembicaran
kontinu dan fungsi
managemen database.
Program penelitian DARPA terus berlanjut hingga
tahun 1990-an.
Penelitian
lainnya
yang berperan
serta antara lain diberikan
oleh CMU
|
|
21
dengan sistem SPHINX, BBN dengan sistem BYBLOS, Lincoln Lab, SRI, MIT, dan AT&T
Bell Labs.
2.3.2
Speech to Text
Speech
to
Text merupakan
aplikasi
yang
dikembangkan
dari
pengenalan
ucapan,
sehingga
bila
kita
membicarakan
aplikasi
speech
to
text tidak
mungkin
terlepas
dari
pengenalan ucapan
itu
sendiri. Pengenalan
ucapan
atau
lebih tepatnya
disebut
Automatic
Speech
Recognition
(ASR)
telah
dikembangkan
selama
lebih
dari
lima
dekade.
Berbagai
percobaan telah dilakukan sejak timbulnya ide untuk menciptakan mesin yang dapat mengerti
ucapan
manusia dan studi
terhadap acoustic-phonetics
sejak awal
1950-an. Tetapi tingkat
kerumitan
pengucapan bahasa
pada
tiap
manusia
yang
berbeda
membuat
percobaan-
percobaan tersebut memiliki tingkat kesalahan yang cukup tinggi.
Salah
satu
aspek
tersulit
dalam
melakukan
penelitian
pengenalan
ucapan
dengan
mesin adalah hubungannya dengan cabang-cabang ilmu alam dan kecenderungan para
peneliti
menerapkan
pendekatan
monolitis
untuk
masalah
perseorangan .
Berikut
adalah
beberapa cabang ilmu yang telah digunakan pada satu atau lebih masalah pengenalan ucapan
(Rabiner dan Juang, 1993, p2) :
Pemrosesan sinyal, proses
mengambil informasi yang dibutuhkan dari sinyal ucapan
secara efisien dan tepat. Termasuk dalam pemprosesan sinyal adalah analisis spektral
yang
digunakan
untuk
menggambarkan properti sinyal
ucapan
yang
berubah-ubah
terhadap waktu.
Fisik
(akustik),
ilmu
yang
mempelajari
hubungan antara bentuk fisik
sinyal ucapan
dengan
mekanisme fisiologis (mekanisme bidang suara manusia) dalam
|
|
22
menghasilkan suara dan bagaimana suara ucapan ditangkap (mekanisme pendengaran
manusia).
Pattern
recognition,
sebuah algoritma
yang digunakan
untuk
mengelompokkan data
untuk
menghasilkan
satu
atau
lebih
pola
prototype dari
data
yang
ada,
dan
untuk
membandingkan dua buah pola dengan dasar pengukuran yang sama.
Teori informasi dan komunikasi,
prosedur untuk memperkirakan
parameter dari
model
statistik. Metode
untuk
mendeteksi keberadaan sebagian pola sinyal
ucapan.
kumpulan algoritma coding dan
decoding
modern (termasuk pemograman dinamis,
algoritma
stack, dan
Viterbi
decoding)
untuk
mencari
kata
yang paling
tepat
pada
data yang besar tapi terbatas melalui jalur yang terbaik.
Linguistik, hubungan antara suara (phonology), kata dalam bahasa (sintax), arti dari
kata ucapan(semantic), dan perasaan yang timbul dari arti(pragmatic).
Fisiologi, memahami sistem saraf utama manusia dalam menghasilkan dan menerima
suara ucapan.
Ilmu
komputer,
mempelajari
algoritma
yang
efisien
untuk
implementasi,
baik
itu
perangkat lunak, perangkat keras, dan berbagai
metode yang akan digunakan dalam
sistem pengenalan ucapan.
Fisikologi, ilmu yang mempelajari faktor yang memungkinkan
manusia
menggunakan teknologi dalam
kehidupannya.
Keberhasilan sistem pengenalan ucapan memerlukan pengetahuan dan keahlian pada
banyak
bidang
ilmu.
Pada
tahun
1980-an,
DARPA
berhasil
membuat sistem pengenalan
ucapan
kontinu
(continuous-speech-recognition
systems) dengan
kosa
kata
yang
besar,
memiliki ketepatan
hingga seribu kata. Dengan adanya sistem pengenalan ucapan kontinu,
|
|
23
mesin dapat
mengenali
ucapan
manusia
secara
lebih
alami, tanpa
harus
mengucapkan kata
demi kata secara terpotong-potong. Sistem ini juga yang akhirnya melahirkan aplikasi speech
to text. Dengan speech
to text komputer diharapkan dapat langsung
mencatat setiap ucapan
manusia yang dikenalinya secara otomatis.
Speech to text adalah sebuah aplikasi berbasis komputer yang dapat mengenali ucapan
manusia dan
memberikan respon balik berupa teks. Speech to text memiliki cara kerja
yang
berlawan dengan text to speech. Text
to speech mengadopsi cara kerja manusia menghasilkan
suara sedangkan speech to text mengadopsi cara kerja persepsi pendengar.
2.3.3 Cara Kerja Speech to Text
Pada dasarnya cara kerja dari speech to text sama dengan cara kerja sistem
pengenalan ucapan ( lihat gambar 2.4 ).
|
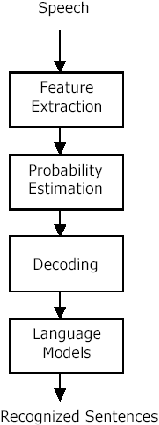 24
Gambar 2.4 Proses
Pengenalan Suara
Pertama–tama suara
yang dihasilkan oleh
manusia akan
ditangkap oleh
microphone
untuk kemudian diubah
menjadi sinyal
digital.
Jika
memungkinkan suara
pengganggu
dan
suara utama dipisahkan dan diubah menjadi bentuk yang lebih sederhana. Pada tahap feature
extraction, prosesor sinyal mengubah sinyal digital yang didapat dengan transformasi fourier,
menghitung tingkat energi
yang
ada
dalam berbagai
frekuensi untuk
menghasilkan bagian-
bagian yang disebut frames.
Teknik
sampling
ini
menghasilkan sederet
vector
yang
digunakan
untuk
proses
pengenalan. Dengan adanya teknik ini, memori yang dibutuhkan untuk menyimpan data yang
akan
diproses
menjadi
lebih
kecil.
Hal
ini
akan
menghemat
memori
yang
digunakan.
Algoritma untuk menghasilkan sederet vector ini lebih dikenal sebagai vector quantization.
|
|
25
Selanjutnya pada
tahap probability
estimation dan
decoding,
vektor
yang
dihasilkan akan
dibandingkan dengan data yang ada dan mengarahkannya ke data yang terdekat untuk diubah
menjadi
serangkaian
simbol
tertentu
sesuai
dengan
language
model yang
ada.
Tahap
berikutnya
adalah
pattern recognition.
Pada
tahap
ini
sinyal
yang
sudah
diproses
dibandingkan dengan model akustik yang sudah ada. Model akustik yang ada disimpan dalam
bentuk serangkaian frames.
Jadi ketika sistem pengenalan ucapan menerima masukan baru,
sistem
akan mengolahnya dan membandingkannya dengan data yang ada
untuk
menemukan
kata yang
terdekat. Metode
ini terbatas
pada
sedikitnya jumlah
kata
yang
dapat digunakan
dan pengucapan yang terpotong-potong. Secara umum terdapat beberapa metode pendekatan
untuk pengenalan ucapan (Rabiner dan Juang, 1993, p42), antara lain :
Pendekatan Akustik Fonetik
Pendekatan Statistical Pattern-Recognition
Pendekatan Intelegensia Semu
2.3.3.1 Pendekatan Akustik
Fonetik
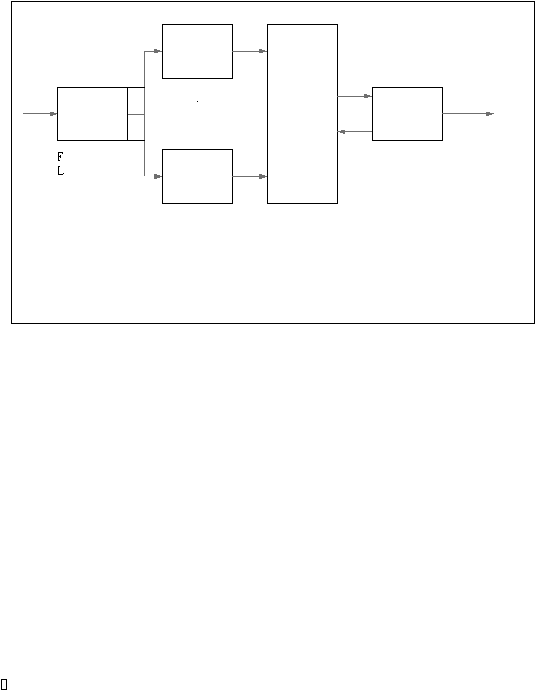
Blok diagram sistem pengenalan
ucapan
akustik
fonetik ditunjukkan oleh gambar
2.5.
langkah
pertama
adalah
speech
analysis
system atau
sistem
analisis
ucapan
yang
menghasilkan representasi spektral dari sinyal ucapan. Di dalam sistem ini terdapat beberapa
metode yang dapat dipakai yaitu bank of filter dan LPC. Langkah berikutnya adalah feature-
detection.
Ide
dasarnya
adalah
mengubah besaran
spektral
menjadi
serangkaian
fitur
yang
menggambarkan properti akustik secara luas dari unit fonetik yang berbeda. Fitur-fitur yang
termasuk
di
dalamnya antara
lain:
nasality
(ada
tidaknya
resonansi nasal),
frication
(ada
tidaknya penekanan dalam ucapan), Formants
locations
(frekuensi dari tiga resonansi
|
 26
SPEECH
ANALYSIS
SYSTEM
ILTER BANK
PC
pertama),
Voiced/Unvoiced
classification
(penekanan
secara
periodik
maupun
tidak
periodik),
high/low-energi ratio.
FEATURE
DETECTOR 1
s(n)
SEGMENTATION
.
AND
LABELING
.
CONTROL
ENERGY
RECOGNIZED
SPEECH
FEATURE
DETECTOR Q
FORMANTS
PITCH
VOICED/
UNVOICED
ENERGY
NASALITY
FRICATION
PHONEME LATTICE
SEGMENT LATTICE
PROBABILISTIC
LABELING
DECISION TREES
PARSING STRATEGIES
Gambar 2.5 Blok Diagram
Sistem Pengenalan
Ucapan
Akustik
Fonetik
(Rabiner dan
Juang, 1993, p45)
Langkah ketiga adalah fase segmentation and labeling. Pada fase ini sistem mencoba
menemukan daerah
yang
stabil,
yaitu
pada
daerah
yang
hanya
terjadi
sedikit
perubahan
maupun
pergeseran
fitur. Kemudian,
memberikan label pada area
yang tersegmen
menurut
seberapa cocok fitur di dalam area tersebut dengan unit fonetik individual. Keluaran terakhir
adalah kata-kata yang memiliki pasangan paling cocok pada referensi kata.
Akan
tetapi
banyak
masalah
yang
terkait
dengan
pendekatan ini,
sehingga
menyebabkan kurang suksesnya praktik sistem pengenalan ucapan, diantaranya :
Metodenya
memerlukan pengetahuan
yang
luas
tentang
properti
akustik
dari
unit
fonetik.
|
|
27
Pemilihan fitur didasarkan pada pemikiran yang tidak terencana. Pada banyak sistem,
pemilihan fitur didasarkan pada intuisi serta tidak optimal dalam logika berpikir.
Desain pengklasifikasi suara
juga tidak optimal. Metode yang tidak terencana
biasanya digunakan untuk membangun suatu pohon keputusan binary. Pada akhirnya
CART
(Classification
And Regression
Tree)
digunakan
untuk
membuat
pohon
keputusan menjadi lebih baik.
Tidak ada cara yang ideal untuk memberikan
label pada pelatihan
ucapan
yang
diterima dan disetujui oleh pakar linguistik secara luas.
2.3.3.2 Pendekatan Statistical Pattern-Recognition
Dalam pendekatan ini terdapat 4 langkah dasar yaitu :
Feature Measurement : adalah hasil dari beberapa tipe teknik analisis spektral seperti
LPC, Filter-Bank Analyzer.
Pattern Training : test pattern
untuk menghasilkan bentuk atau pola yang memiliki
fitur-fitur (keistimewaan) dari suatu kelas, kemudian hasilnya akan dijadikan
reference pattern (berupa template / model statistik).
Pattern Classification : membandingkan masing-masing test pattern
yang
dimasukkan, dengan reference pattern
yang ada di dalam kelas-kelas atau basis data.
Decision Logic : hasil perbandingan dari pattern classification, digunakan untuk
menentukan reference pattern
yang paling mendekati atau mirip dengan test pattern
yang dimasukkan.
Salah satu metode yang sudah digunakan secara luas untuk aplikasi continuous speech
recognition
adalah Hidden Markov Model (HMM). HMM
merupakan model statistik yang
|
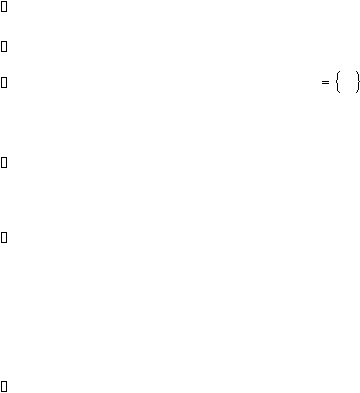 28
ij
menggambarkan distribusi
kemungkinan
transisi
dari
model
bahasa
yang
ada.
HMM
mengandung suatu proses
stokastik
tambahan dengan proses
stokastik tersembunyi sebagai
dasarnya, tetapi proses tambahan ini dapat dipelajari melalui rangkaian proses stokastik lain,
proses ini menghasilkan urutan-urutan pengamatan.
Probabilistic
Pattern
Recognition Model yang digunakan di dalam sistem pengenalan
suara
untuk membantu mendeterminasi kata-kata mana saja
yang dipresentasikan oleh suara
yang
ditangkap
oleh
komputer.
HMM merupakan
algoritma
dasar
yang
digunakan
pada
sistem pengenalan suara (Atwell, 1999).
Elemen-elemen yang terdapat dalam HMM sebagai berikut :
N, banyaknya state dalam satu model
M, banyaknya simbol pengamatan dalam satu state
Distribusi kemungkinan perpindahan state,
A
a
dengan :
a
ij
=
P[ q
t+1
=
j | q
t
=
i ],
1 = i,j = N
Distribusi kemungkinan observasi simbol, B = {b
j
(k)} dengan :
b
j
(k) = P[ ot
=
vk | qt
=
j ],
1 = k = M
Distribusi initial state, p = { pi } dengan :
p
i
=
P[ q¹ = i ],
1 = i = N
Model
statical pattern-recognition
tentu
saja
memiliki
kelebihan
dan
kelemahan.
Beberapa kelebihan dan kelemahan model statical pattern-recognition, sebagai berikut:
Kinerja sistem sensitif terhadap sejumlah data latihan yang ada untuk membuat pola
referensi kelas suara. Biasanya semakin sering berlatih, kinerja sistem semakin tinggi.
|
|
29
Pola-pola
referensi
sensitif
terhadap
lingkungan
pembicara
dan
karakteristik
media
transmisi
yang
digunakan
dalam
menghasilkan ucapan.
Hal
ini
menyebabkan
karakteristik spektral ucapan dipengaruhi oleh transmisi dan noise.
Tidak
ada
pengetahuan
ucapan
khusus yang
digunakan
secara
eksplisit
di
dalam
sistem,
sehingga
metode
ini
kurang
sensitif
untuk
memilih
kosa-kata, penugasan
sintak, dan penugasan semantik.
Perhitungan yang digunakan pada pelatihan pola dan klasifikasi pola umumnya cocok
terhadap sejumlah pola yang telah dilatih maupun dikenali.
Karena sistem kurang peka terhadap kelas suara, sehingga serangkaian teknik
pengembangan
untuk
satu
kelas
suara
dapat
langsung
digunakan
pada
kelas
suara
yang lain tanpa mengganti maupun memodifikasi algoritma yang dipakai.
Model pengenalan pola secara relatif menggabungkan batasan sintaks kedalam
struktur
pengenalan
pola,
sehingga
meningkatkan keakuratan
sistem
pengenalan
sekaligus menurunkan proses penghitungan.
2.3.3.3 Pendekatan Intelegensia
Semu
Ide dasarnya adalah
mengumpulkan dan menggabungkan berbagai
macam
informasi
dari berbagai sumber pengetahuan kemudian digunakan
untuk
menyelesaikan masalah
yang
ada.
Dalam hal ini terdapat beberapa sumber informasi :
Pengetahuan akustik : keterangan dari mana suara berasal untuk menentukan spectral
measurement serta ada tidaknya fitur-fitur.
|
|
30
Pengetahuan leksikal : merupakan kombinasi dari akustik untuk memetakan atau
mengubah dari bentuk suara menjadi bentuk kata menggunakan leksikon.
Pengetahuan sintaksis : merupakan kombinasi dari kata-kata untuk membentuk
kalimat yang benar sesuai aturan penulisan.
Pengetahuan semantik : pemahaman terhadap tugas utama sehingga dapat
menentukan apakah sebuah kalimat sudah tepat dan sesuai aturan bahasa.
Pengetahuan pragmatik : kemampuan menyimpulkan arti dari suatu kata berdasarkan
aturan bahasa suatu daerah yang menggunakan bahasa/kata-kata tersebut.
Ada
beberapa
cara
untuk
menggabungkan sumber
pengetahuan
kedalam
sistem
pengenal
ucapan. Cara
yang
pertama
adalah
dengan
pemrosesan
bottom up,
yaitu
tingkat
proses paling bawah mendahului proses pada tingkat yang lebih tinggi secara berurutan, jadi
cara
ini
akan
memberikan
batasan
yang
bertujuan
untuk
mendapatkan proses
sesedikit
mungkin. Top down merupakan pemroses kedua yang dapat dipakai. Pada proses
ini
model
bahasa
menghasilkan hipotesis
kata
yang
sesuai
dengan
sinyal
ucapan,
selain
itu
akan
terbentuk kalimat yang secara sintak dan semantik benar pada nilai kata yang dicocokkan.
Pendekatan blackboard
merupakan cara
lain
yang
dapat
digunakan. Pada
teknik
ini
semua sumber pengetahuan dianggap berdiri sendiri. Hipotesa dan tes paradigma digunakan
sebagai media komunikasi dasar diantara sumber-sumber pengetahuan.
Berbagai
macam
sumber
pengetahuan perlu
dimasukkan
kedalam
pendekatan
intelegensia semu.
Dua
konsep
kunci
dalam
intelegensia semu
adalah
mempelajari
pengetahuan yang ada dan beradaptasi. Salah satu jalan untuk mengimplementasikan konsep
ini adalah dengan menggunakan pendekatan neural network.
|
|
31
Konsep
pemahaman
ucapan
berdasarkan pada
persepsi
manusia.
Sinyal
masukan
pertama kali
dianalisis oleh
suatu
model
yang
disebut
“ear
model”,
model
ini
memberikan
informasi
spektral
dan
menyimpannya ke dalam
penyimpanan
informasi sensor.
Informasi
sensor
yang
lain
juga
tersedia
di
dalam
penyimpanan informasi
sensor,
informasi
ini
digunakan
untuk
menghasilkan beberapa
tingkat
fitur
dari
deskripsi
ucapan. Selain
media
penyimpanan informasi
sensor
pada
konsep
ini
terdapat
pula
long-term
dan
short-term
memory yang
tersedia untuk berbagai macam pendeteksi fitur.
2.3.4
Masalah Fundamental pada Sistem Pengenalan
Ucapan
Seperti
halnya
masalah
pada
pengenalan
pola
lainnya,
masalah
fundamental pada
pengenalan ucapan adalah variabilitas dari pola ucapan manusia. Kesalahan pada pengenalan
ucapan
dikarenakan terjadinya
tumpang
tindih
unit
ucapan
yang
berbeda
pada
realisasi
distribusi akustik (Anonim,2001). Secara umum variabilitas ucapan dapat dijabarkan sebagai
berikut (Anonim, 2001) :
Variabilitas durasi. Dua kali pengucapan sebuah kata tidak mungkin memiliki durasi
yang sama, walaupun diucapkan oleh orang yang sama.
Variabilitas spektral. Dua kali pengucapan sebuah kata tidak mungkin memiliki
lintasan waktu spektral yang sama.
Variabilitas pembicara. Suara
ucapan dipengaruhi oleh
karakteristik anatomi, jenis
kelamin, kesehatan, dan emosi dari si pembicara.
Logat.
Logat
pembicara
dapat
memberikan pengaruh yang cukup
besar
pada
karakteristik suara ucapan dan pada kinerja sistem pengenalan suara.
|
|
32
Variabilitas kontekstual. Karakteristik
unit
ucapan
dipengaruhi oleh
hubungan
unit
kata-kata sebelum dan sesudahnya.
Co-articulation. Hampir sama dengan
variabelitas kontekstual, hanya saja co-
articulation
juga dipengaruhi oleh kecepatan berbicara, logat, dan faktor psikologis.
Noise.
Pengenalan
ucapan
dipengaruhi
oleh
noise,
echo,
distorsi
pada
saluran
dan
keadaan lingkungan.
2.4
Sinyal
Sinyal didefinisikan sebagai :
besaran
fisik
yang
berubah-ubah
menurut
waktu, ruang
atau
variabel
bebas
atau
variabel-variabel lainnya.
Secara
matematis,
kita
mendeskripsikan sinyal
sebagai
fungsi dari satu atau lebih variabel bebas (Proakis dan Manolakis, 1997, p2)
informasi,
pesan
(berita),
atau
efek
yang
perlu
dibawa
lewat
sistem
komunikasi;
Gelombang isyarat, perwujudan fisik suatu berita (IEEE); Kejadian (event) atau gejala
(fenomena) yang membawa data dari satu titik ke titik lainnya (Wasito, 1987)
2.4.1
Klasifikasi
Sinyal
Menurut Proakis dan Manolakis (1997) sinyal dibedakan menjadi 4 golongan yaitu :
Sinyal-sinyal Multikanal dan Multidimensi
Sinyal
multikanal
adalah
sinyal yang
nilai
fungsinya
dapat
berupa
vektor
sinyal
dengan sinyal-sinyal elektrik sensor ke-k sebagai fungsi
waktu. k dapat bernilai dari
satu sampai tak terhingga.
|
|
33
Sinyal
multidimensi
adalah
sinyal
yang merupakan
suatu
fungsi dari m variabel
bebas.
Sinyal waktu-kontinu versus sinyal waktu-diskrit
Sinyal
waktu-kontinu (sinyal analog) didefinisikan sebagai
sinyal
yang
untuk
setiap
nilai
waktu
diambil
pada
nilai-nilai
dalam
selang
kontinu
(a,
b) dengan
a
dapat
menjadi -8 dan b dapat menjadi 8.
Sinyal waktu-diskrit adalah sinyal yang diambil hanya pada nilai-nilai waktu khusus
tertentu.
Sinyal
waktu
diskrit
dapat
digambarkan secara
matematis
dengan
suatu
barisan bilangan real atau bilangan kompleks.
Sinyal bernilai kontinu versus sinyal bernilai diskrit
Jika
suatu
sinyal
diambil
dengan
seluruh
nilai
yang
mungkin baik
pada
interval
terbatas atau tidak terbatas, hal ini dikatakan sinyal bernilai kontinu.
Jika sinyal diambil pada nilai-nilai dari suatu himpunan terbatas nilai yang mungkin,
hal ini dikatakan sinyal bernilai diskrit.
Sinyal
waktu diskrit
yang
mempunyai himpunan
nilai-nilai diskrit dinamakan sinyal
digital. Agar suatu sinyal dapat diproses secara digital, sinyal
itu
harus didiskritkan
waktunya dan nilainya harus diskrit.
Sinyal deterministik versus sinyal acak
Setiap
sinyal
yang
dapat
dideskripsikan secara
unik
dengan
suatu
pernyataan
matematis eksplisit, suatu tabel data, atau suatu aturan yang didefinisikan dengan baik
dinamakan deterministik. Istilah
ini digunakan
untuk menegaskan fakta bahwa
seluruh nilai
sinyal sebelum, sekarang, dan
yang akan datang diketahui secara pasti,
tanpa adanya ketidakpastian.
|
|
34
Namun
dalam
banyak
aplikasi
praktis,
terdapat
sinyal-sinyal yang
tidak
dapat
dideskripsikan terhadap
setiap
alasan
derajat
keakuratan
dengan
formula-formula
matematis eksplisit,
atau
suatu
deskripsi
seperti
itu
terlalu
sukar
untuk
setiap
penggunaan praktis.
Kekurangan hubungan
seperti
itu
menyatakan bahwa
sinyal-
sinyal
seperti
itu
dibatasi
waktu
dengan
cara
yang
tidak
dapat
diramalkan. Kita
mengacu sinyal-sinyal ini sebagai acak
2.4.2
Pemrosesan Sinyal pada
Sistem Pengenalan Ucapan
Pemrosesan
sinyal
merupakan bagian
terpenting
dari
sistem
pengenalan
suara.
Berbagai parameter dapat
digunakan
untuk
menggambarkan
sinyal
suara
seperti
short
time
energy, zero crossing rates,
level crossing rates, dan berbagai parameter lainnya. Akan tetapi
short time spectral envelope dirasakan sebagai parameter yang paling cocok bagi sinyal suara
(Proakis
dan Dimitris, 1997).
Pada spektral analisis
terdapat dua
metode
utama
yaitu filter-
bank spectrum analysis model dan linear predictive coding (LPC ) spectral analysis model.
2.5
Filter
Filter
merupakan suatu
fungsi
yang
secara
selektif
mengubah bentuk
gelombang,
karakteristik
amplitudo-frekuensi dan
frasa
frekuensi
sebuah
sinyal
menjadi
bentuk
yang
diinginkan. Filter mempunyai tujuan untuk menekan adanya derau dan meningkatkan kualitas
sinyal, mengekstraksi informasi yang dibutuhkan dari sinyal.
Filter
digital
merupakan
algoritma
matematis, bertujuan
untuk
memroses
sinyal,
misalnya sinyal analog
yang didigitalisasi kemudian menyimpan hasilnya ke dalam
memori
komputer.
|
 35
Ada dua
macam
filter digital
yang
umum dikenal
yaitu, FIR (Finite
Impulse
Response) dan IIR (Infinite Impulse Response).
n
1
s(n)
h(k ) x(n
k )
k
0
s(n)
h(k ) x(n
k )
k
0
persamaan
pertama
adalah
persamaan
untuk
FIR,
sedangkan
filter
IIR
ditunjukkan pada
persamaan kedua
(Nugroho,
2001,
p4).
Salah
satu
teknik
didalam
Filter
IIR
yang
dapat
mendeteksi perubahan dalam sinyal suara adalah parametrik.
Parametrik
bekerja
dengan
cara
menemukan parameter
untuk
model
matematika,
menggambarkan sinyal,
sistem,
atau
proses.
Teknik
ini
memanfaatkan informasi
yang
diketahui tentang sistem
untuk
membuat
modelnya. (Matlab, 2002).
Salah satu teknik
yang
dipakai dalam parametrik modeling adalah LPC.
LPC
merupakan teknik
yang telah umum dipakai dalam sistem pengenalan ucapan.
LPC
memiliki beberapa keunggulan dibandingkan dengan
metode
lain, yang
menyebabkan
LPC banyak digunakan dalam sistem pengenalan ucapan, diantaranya, sebagai berikut :
LPC menyediakan pemodelan yang baik dari sinyal ucapan.
Ketika LPC ditempatkan pada analisis sinyal ucapan, LPC akan mengarah ke sumber
yang
masuk
akal,
hasilnya adalah
representasi
karakteristik vocal
tract
yang
sesuai
dengan kebutuhan.
LPC
adalah model
yang
dapat
menentukan area
ucapan dengan
menganalisis sinyal
tersebut.
Model
LPC bekerja
sangat baik pada aplikasi pengenalan
ucapan. Pengalaman telah
menunjukkan
bahwa
kinerja
sistem
pengenalan
ucapan
yang menggunakan
LPC,
|
 36
Bandpass filter
Q
hasilnya lebih baik daripada sistem pengenal yang menggunakan teknik lain, misalnya
teknik filter-bank (Rabiner dan Juang, 1993, p98).
2.5.1
Deret
“Bank
of Filter”
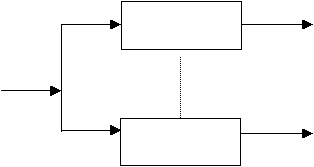
Pada
metode
ini,
sinyal
suara
dianalogikan
sebagai sinyal
digital, s(n),
dilewatkan
pada bandpass
filter Q
yang
memilah
frekuensi sinyal
yang dilewatkan (lihat
gambar 2.6
).
Misalnya 100-3000 Hz untuk sinyal telepon dan 100-8000 Hz untuk sinyal pemancar. Setiap
filter
dapat
melakukan penyaringan
sendiri dan
umumnya saling melengkapi. Keluaran dari
bandpass
filter ke i adalah X
n
(e
i?i
), dimana ?
i
adalah frekuensi yang sudah dinormalisasikan
dengan 2pf
i
/ F
s
dan F
s
adalah frekuensi percobaan.
Bandpass filter
1
X
n
(e
i?1
)
speech
s(n)
X
n
(e
i?Q
)
Gambar 2.6 Model
Analisis Bank Filter
(Rabiner dan
Juang, 1993, p72)
2.5.2
Linear Predictive
Coding
(LPC)
Metode
ini
membagi sinyal
suara
menjadi
bagian-bagian kecil
yang disebut
speech
frames
untuk
dianalisis (lihat
gambar
2.7).
LPC
menghasilkan
koefisien
bagi
filter
suara.
Pada proses blok into frame, N menunjukkan ukuran dari
frame sedangkan M menunjukkan
jarak antar frame yang berdekatan.
|
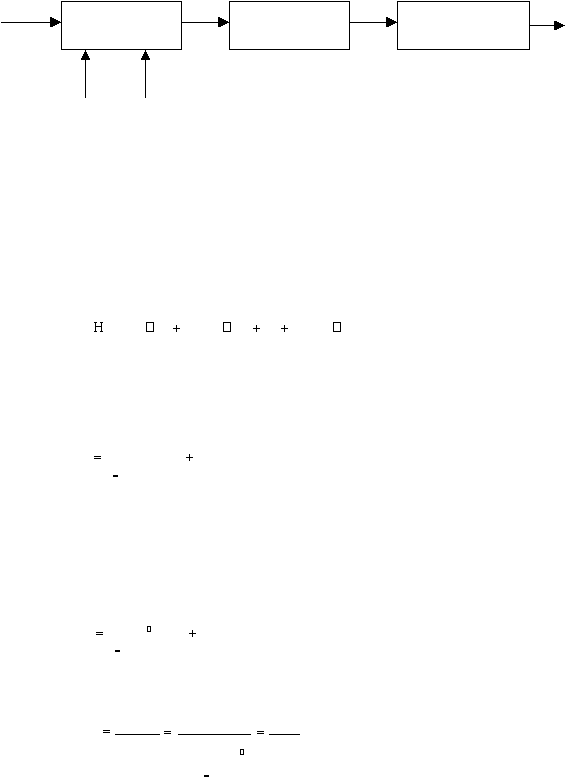 37
i
Speech
s(n)
Block into
frames
LPC Spectral
Analysis
a
n
LPC Parameter
Conversion
N
M
Gambar 2.7 model analisis
LPC (Rabiner dan
Juang, 1993, p72)
2.5.2.1 Model
LPC
Ide dasar dalam model LPC adalah contoh ucapan dalam waktu n dinyatakan dengan
persamaan :
s(n)
a
1
s(n
1)
a
2
s(n
2)
K
a
p
s(n
p)
dimana koefisien
a1
,
a
2,…,
a
p
dianggap konstan. Bila ekspresi pemacu G
u(n) dimasukkan
kedalam persamaan di atas akan didapatkan persamaan :
p
s(n)
a
i
s(n
i)
Gu(n)
i
1
dimana u(n) adalah ekspresi pemacu yang dinormalisasi,
sedangkan G didapatkan dari
pemacu
tersebut.
Dengan
mengekspresikan persamaan
tersebut
ke
dalam
domain
z
maka
akan didapatkan relasi :
p
S
(
z)
a
z
i
S z)
( z)
GU ( z)
i
1
mengarah ke fungsi transfer :
H z)
( z)
S
(
z)
GU ( z)
1
1
p
a
z
i
1
A( z)
i
i
1
Interpretasi dari persamaan di atas dapat dilihat pada gambar 2.8.
|
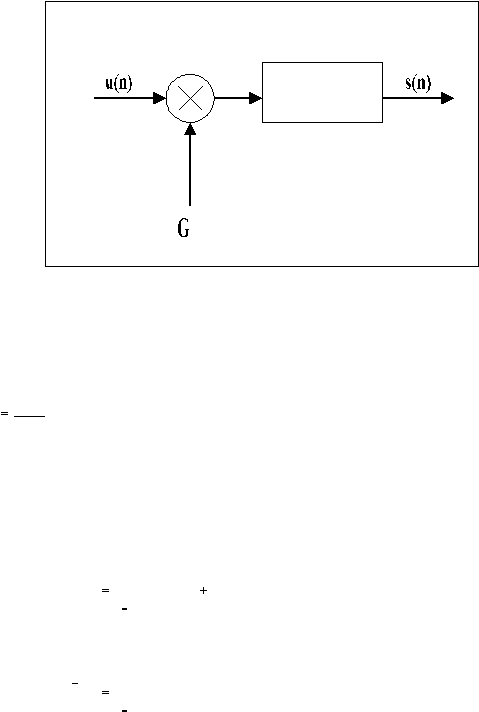 38
A(z)
Gambar 2.8 Model
Linear Prediction
(Rabiner dan
Juang, 1993, p100)
Dimana
u(n),
diskalakan oleh
G,
dan
berperan
sebagai
input
untuk semua kutub
sistem,
H
(
z)
1
A( z)
, untuk menghasilkan sinyal ucapan s(n).
2.5.2.2 Persamaan
Analisis
LPC
Berdasarkan gambar 2.8, hubungan antara s(n) dan u(n) adalah :
p
s(n)
a
k
s(n
k )
Gu(n)
k
1
Kombinasi linier dari sample ucapan yang terakhir diandaikan sebagai :
p
s(n)
a
k
s(n
k )
k
1
2.5.2.3 LPC
Processor
LPC processor memiliki beberapa langkah dasar pemrosesan sebagai berikut (gambar 2.9) :
|
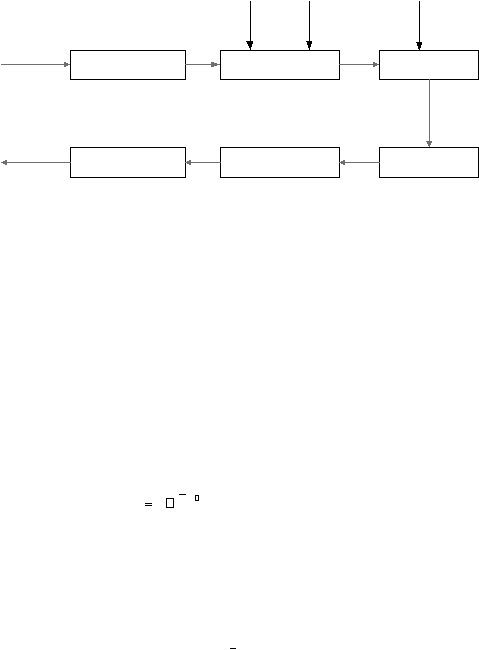 39
N
M
P
S
(n)
preemphasis
Frame Blocking
Windowing
C(m)
LPC
Parameter
Conversion
LPC Analysis
Autocorrelation
Analysis
Gambar 2.9 LPC
Processor
a.
Preemphasis
Preemphasis
merupakan tahap pertama dari LPC
yang memfilter
sinyal suara
masukan dari mikrofon. Pada tahap ini, sinyal dengan frekuensi tinggi dilemahkan sehingga
sinyal lebih tahan terhadap efek presisi atau pergeseran. Sistem digital yang digunakan oleh
fungsi
preemphasis adalah
fixed atau slowly adaptive.
Sistem
yang
paling
umum dipakai
adalah
fixed
first-order,
H
(
z)
1
az
1
.
Dengan
a = 0.95
merupakan
nilai
yang paling
umum dipakai (Rabiner dan Juang, 1993, p113 )
.
b.
Frame Blocking
Sinyal ucapan hasil preemphasis,
s(n)
, kemudian diblok kedalam frame-frame
sebanyak N sample, frame-frame yang saling berhubungan dipisahkan oleh M sample.
c.
Windowing
|
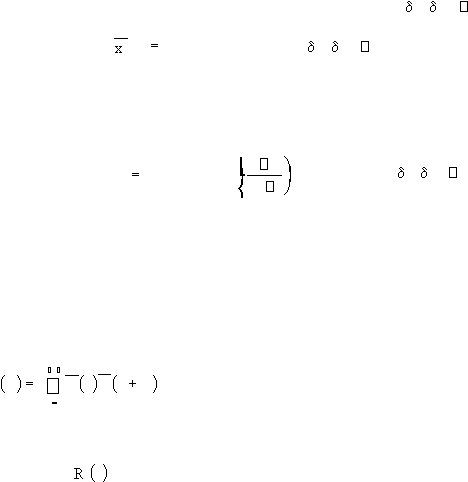 40
l
l
l
l
l
l
Langkah
selanjutnya adalah
pemberian window pada
individual
frame.
Windowing
memiliki tujuan
untuk
meminimalisasi diskontinuitas sinyal pada
awal
dan
akhir
masing-
masing frame. Jika window didefinisikan sebagai w(n), dengan 0
n
N
1 hasil akhir dari
, hasil akhir dari
windowing adalah
(n)
x (n)w(n) , dengan
0
n
N
1 Hamming window, merupakan
. Hamming window, merupakan
teknik
windowing yang paling
umum
dipakai pada
sistem
pengenalan
ucapan.
Hamming
window dirumuskan :
w(n)
0.54
0.46 cos
2
n
,
0
n
N
1
N
1
d.
Analisis
otokorelasi
Masing-masing frame dari
sinyal yang
telah di-window,
dilakukan otokorelasi.
N
1
m
r
m
x
n
x
n
m
,
dengan
m = 0,1,…,p. Nilai p
adalah
nilai
tertinggi pada
n
0
otokorelasi.
Nilai
p
akan digunakan
pada
langkah berikutnya
yaitu
analisis
LPC.
Zeroth
otokorelasi,
0
,
merupakan
energi
dari frame ke-l.
Energi
ini merupakan
parameter
penting pada sistem pengenalan ucapan.
e.
Analisis
LPC
Analisis LPC merupakan proses yang mengubah masing-masing
frame dari
otokorelasi p+1
kedalam
bentuk
set
parameter
LPC,
dimana
set
tersebut
mungkin
saja
koefisien LPC, koefisien refleksi, kofisien log area ratio, koefisien cepstral, atau transformasi
ke
bentuk
set
yang
diinginkan. Metode
umum
yang
biasa
digunakan untuk
mengubah
koefisien hasil otokorelasi menjadi perameter LPC adalah Metode Levinson-Durbin.
|
|
41
f.
Pengubahan Parameter
LPC
Menjadi Koefisien Cepstral
Koefisien cepstral LPC, c(m), dapat diturunkan secara langsung dari parameter LPC.
Koefisien cepstral
merupakan koefisien
hasil representasi transformasi
fourier terhadap
log
magnitude spectrum.
2.6
Perbandingan Sinyal
Suara
Untuk
suatu sistem pengenalan suara dapat digunakan
metode
template,
yaitu suara
yang
dimasukkan
kemudian
dibandingkan dengan
suara
referensi
(template)
yang
sudah
tersedia di dalam basisdata. Untuk perbandingan terdapat banyak cara, sehingga
perbandingan bentuk
suara
merupakan bagian penting
dari
suatu sistem
pengenalan
suara,
agar
didapatkan sinyal
suara
yang
baik
(jernih)
serta
dapat
mendukung
keakuratan hasil
perbandingan,
sinyal suara
yang dimasukkan
terlebih dahulu
harus
dipisahkan dari
sinyal-
sinyal lain yang dapat mengganggu.
Pendeteksian
suara
bertujuan
agar
sinyal
suara
yang
dimasukkan
dapat
dipisahkan
dari sinyal-sinyal lain
yang tidak berguna.
Untuk memperoleh kualitas suara
yang baik dan
jernih,
sehingga dapat digunakan untuk
membentuk speech pattern
atau sering disebut juga
template.
Menurut
Rabiner
dan
Juang,
dalam
pendeteksian
suara
ada
beberapa
metode
yang
dapat
digunakan,
metode-metode ini
digolongkan
menjadi tiga
macam pendekatan, sebagai
berikut :
The
Explicit Approach
:
pendekatan
ini
didasarkan
atas
premis bahwa pendeteksian
suara
dapat
dilakukan
tanpa
tergantung kepada operasi-operasi
pencocokan bentuk
lain pada langkah berikutnya dalam proses pengenalan suara.
|
|
42
The
Implicit
Approach
:
pendekatan
ini
mempertimbangkan
masalah
pendeteksian
suara
secara
simultan dengan pattern-matching
dan
proses
recognition-decision,
dianggap bahwa
dalam
sinyal
suara
yang
dimasukkan
selalu
terdapat
sinyal-sinyal
lain.
The
Hybrid
Approach
:
pendekatan
ini
memiliki
perhitungan
yang
sama dengan
metode explicit namun tingkat keakuratannya sebanding terhadap metode implicit.
|