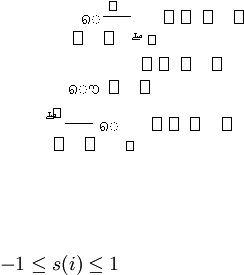
58
s(i) =
1
???
,
?
?
?
?
?
?
?
?
0,
?
?
?
?
(2.23)
???
1,
?
?
?
?
?
?
?
?
?
Dari definisi di atas jelas bahwa
(2.24)
Untuk
s(i)
untuk
dekat
dengan
1
kita
memerlukan
a(i)
<<
b(i).
Sebagai
a(i)
adalah
ukuran bagaimana i
berbeda dengan klaster sendiri,
nilai kecil artinya serasi. Selain
itu,
besar b(i)
menyiratkan bahwa
i
sangat cocok
untuk klaster tetangganya. Jadi sebuah
s(i)
yang
dekat
dengan
salah
satu berarti
bahwa
data
yang
tepat
berkumpul. Jika s(i)
dekat
dengan
negatif,
maka
dengan
logika
yang
sama
kita
melihat
bahwa
i
akan
lebih
tepat
kalau itu berkumpul dalam klaster
tetangganya. Sebuah s(i)
mendekati
nol berarti bahwa
data berada di perbatasan dua kelompok.
Rata-rata
s(i)
dari
sebuah
klaster
adalah
ukuran
dari
bagaimana erat
dikelompokkan
semua
data
di
klaster
tersebut.
Jadi
rata-rata s(i)
seluruh
dataset
adalah
ukuran
dari
seberapa
tepat
data
yang
telah
dikumpulkan. Jika
terlalu
banyak
atau
terlalu
sedikit
klaster, seperti pilihan k yang buruk dalam algoritma K-Means, beberapa kelompok akan
menampilkan silhouette jauh
lebih sempit dari
yang
lain. Jadi silhoutte plot dan rata-rata
adalah alat yang ampuh untuk menentukan jumlah klaster alam dalam dataset.