19
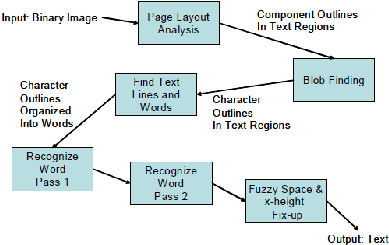
2.5.1 Artitektur Tesseract
Gambar 2.3 Arsitektur tesseract
Tesseract OCR
mengasumsikan
input
yang diterima berupa sebuah binary
image. Pertama, analisis dilakukan pada komponen terhubung/Connected Component
(CC)
untuk
menemukan
di
mana
outline
komponen
disimpan.
Pada
tahap
ini
outlines
dikumpulkan
bersama
menjadi blob.
Blob
disusun
menjadi
baris teks, sedangkan garis
dan region dianalisis untuk pitch tetap dan teks proporsional. Baris teks dipecah menjadi
kata-kata
berbeda
menurut
jenis
spasi
karakter.
Teks
dengan pitch tetap
dibagi
menjadi
sel-sel
karakter.
Teks
proporsional
dipecah menjadi
kata-kata
dengan menggunakan
ruang
pasti
dan
ruang
fuzzy.
Pengenalan
kata
pada
image
dilakukan
pada
dua
tahap
proses yang disebut pass-two (Smith, 2009).
Pada pass pertama dilakukan untuk mengenali masing-masing kata pada
gilirannya.
Kata-kata
yang
sukses
pada
pass
pertama
yaitu
kata-kata
yang
terdapat
di
kamus
dan
tidak
ambigu
kemudian
diteruskan
ke adaptive
classifier sebagai data
pelatihan. Begitu adaptive classifier
memiliki sampel
yang cukup, adaptive classifier ini
dapat
memberikan
hasil klasifikasi bahkan pada pass pertama. Proses pass kedua