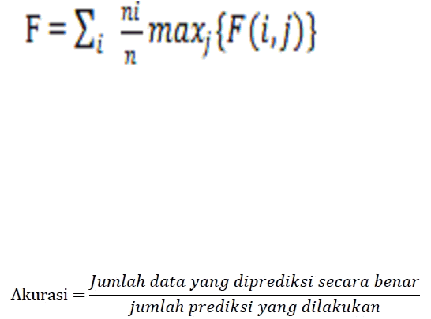
17
Gambar 2.9: Rumus F-Measure Dataset
Sumber: (Wicaksana & Widiartha, 2012)
Salah satu pengukur kinerja klasifikasi adalah tingkat akurasi. Sebuah
sistem dalam melakukan klasifikasi diharapkan dapat mengklasifikasi semua
set data dengan benar, tetapi tidak dipungkiri bahwa kinerja suatu sistem
tidak bisa 100% akurat. (Prasetyo, 2012).
Untuk menghitung akurasi digunakan formula :
Gambar 2.10 : Rumus Akurasi
Sumber: (Prasetyo,2012)
2.4.3
Clustering
Menurut Han dan Kamber (2011), Clustering
adalah proses
pengelompokkan kumpulan data menjadi beberapa kelompok sehingga objek
di dalam satu kelompok memiliki banyak kesamaan dan memiliki banyak
perbedaan dengan objek dikelompok lain. Perbedaan dan persamaannya
biasanya berdasarkan nilai atribut dari objek tersebut dan dapat juga berupa
perhitungan jarak. Clustering
sendiri juga disebut Unsupervised
Classification, karena clustering
lebih bersifat untuk dipelajari dan
diperhatikan. Cluster analysis merupakan proses partisi satu set objek data ke
dalam himpunan bagian. Setiap himpunan bagian adalah cluster, sehingga
objek yang di dalam cluster
mirip satu sama dengan yang lainnya, dan
mempunyai perbedaan dengan objek dari cluster
yang lain. Partisi tidak
dilakukan dengan manual tetapi dengan algoritma clustering. Oleh karena itu,
Clustering
sangat berguna dan bisa menemukan group
yang tidak dikenal
dalam data.
Teknik clustering
umumnya berguna untuk merepresentasikan data
secara visual, karena data dikelompokkan berdasarkan kriteria-kriteria umum.
Dari representasi target tersebut, dapat dilihat adanya kecenderungan lebih