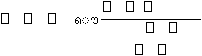
12
Pada
implementasinya
sistem
pengenalan
suara
berbasis
hidden
markov
model
dibagi menjadi beberapa bagian sebagai berikut :
1. Data preparasi : pembentukan parameter vektor (observasi)
2. Training : inisialisasi dan estimasi parameter vector
3. Testing : pengenalan
2.3.1 Observasi
Pemisahaan kata
menjadi
simbol
yang
dilafalkan (phone)
menghasilkan
rangakaian observasi o
untuk setiap kejadian
yang
mungkin pada saat transisi antar state.
Aggap
suara
sebagai
sebuah
rangkaian vektor
suara
atau
observasi,
yang
didefinisikan
sebagai berikut :
O = o1,o2,o3,....,o
T
Dimana
ot
adalah
vektor
suara
yang
diobservasi pada
saat
t.
Observasi
pada
dasarnya
menentukan nilai dari persamaan berikut
Argmax{P(W
i
,O)}
Dimana
W
i
adalah
pengucapan
yang
ke-i,
probabilitas
ini
tidak
dapat
dihitung secara
langsung tetapi dapat dihitung dengan menggunakan aturan Bayes
?
?
|
?
?
|
?
?
?
?
?
?
?
Maka, prioritas kemungkinan P(W
i
) sangat tergantung pada P(O|W
i
).
Dalam
pengenalan
suara
berbasis
hmm,
diasumsikan bahwa
rangkaian
vektor
observasi
berkorespondensi dengan
masing
masing
word
yang
dihasilkan
oleh
markov
model .
Markov
model
adalah
mesin
finite state
yang
mengalami perubahan state
sekali
setiap satuan waktu t pada saat state
j
dimasuki, vektor suara ot dihasilkan berdasarkan